Linux内核分析期中总结
linux内核分析期中总结
标签(空格分隔): 20135328陈都
陈都 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
1.1冯诺依曼体系结构:即具有存储程序的计算机体系结构
目前大多数拥有计算和存储功能的设备其核心构造均为冯诺依曼体系结构
1.函数调用堆栈
1.1小结
三把宝剑:
- 存储程序计算机
- 函数调用堆栈
- 中断机制
1.2堆栈
堆栈是C语言程序运行时必须的一个记录调用路径和参数的空间
- 函数条用框架
- 传递参数
- 保存返回地址
- 提供局部变量空间
C代码中嵌入汇编代码的写法
0. 内嵌汇编语法
asm(汇编语句模板: 输出部分: 输入部分: 破坏描述部分)
- 各部分使用“:”格开
1. 汇编语句模板
2. 输出部分
3. 输入部分
4. 破坏描述部分
5. 限制字符
构造一个简单的Linux系统MenuOS
上周回顾:
-
计算机三大法宝
-
存储程序计算机
-
函数调用堆栈
-
中断
-
操作系统两把宝剑
-
中断上下文的切换
-
进程上下文的切换
Linux内核源码简介
我们关注的部分
- arch/x86目录下的代码
- init/main.c中start_kernel函数就相当于普通C程序的main函数
- kernel目录:存放linux内核最核心的代码,用于实现系统的核心模块,包括进程管理、进程调度器、中断处理、系统时钟管理、同步机制等
README
提供内核的各种编译方法、生成文件的查看方法。
- installing 如何安装内核源代码
- make mrproper 清理安装时生成的中间代码
启动Linux内核的三个参数:
- kernel
- initrd
- root所在分区、目录
需要知道的一行代码:qemu -kernel (文件名) -initrd (rootfs.img)
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S

使用gdb跟踪调试内核
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s
-S # 关于-s和-S选项的说明:
-S freeze CPU at startup (use ’c’ to start execution)
-s shorthand for -gdb tcp::1234 若不想使用1234端口,则可以使用-gdb
tcp:xxxx来取代-s选项
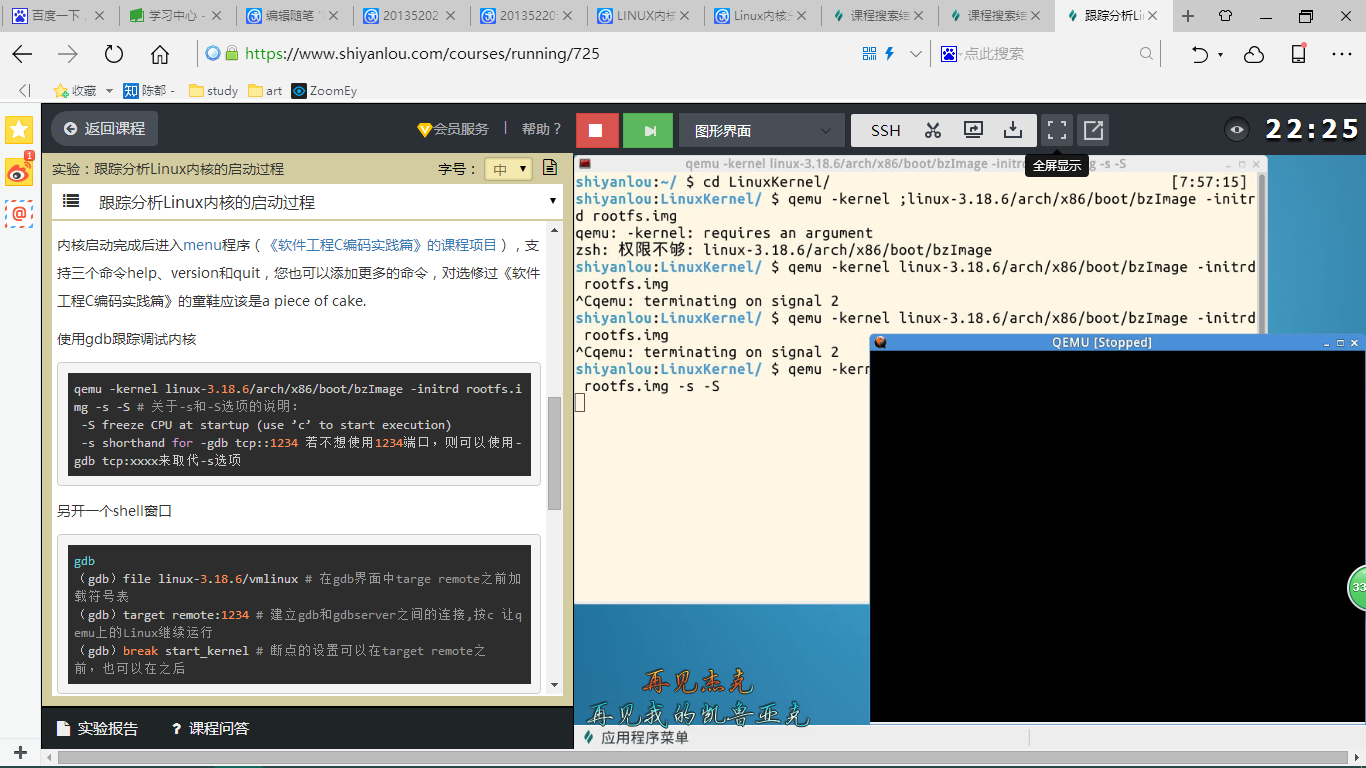
另开一个shell窗口
gdb (gdb)file linux-3.18.6/vmlinux # 在gdb界面中targe remote之前加载符号表
(gdb)target remote:1234 # 建立gdb和gdbserver之间的连接,按c 让qemu上的Linux继续运行
(gdb)break start_kernel # 断点的设置可以在target remote之前,也可以在之后
通过查询了解和使用man查看open的说明我了解到
open系统调用的服务例程是sys_open()函数,它接受三个参数:要打开文件的路径名filename, 访问模式的表示flags和文件权限掩码mode。在内核中,sys_open实际调用do_sys_open函数来完成所有操作。
do_sys_open主要执行如下操作:
1,通过getname()从进程地址空间获取该文件的路径名
2,调用get_unused_fd_flags(flags)函数从current->files结构中分配一个空闲的fd。
3,调用do_filep_open(dfd, pathname, flags, mode, 0)找到文件对象的指针struct file* f。
4,调用fd_install(fd, f),将f与fd关联起来。实际是将f保存在current->files->fdtab->fd数组的第fd位置处。
do_filep_open函数的主要功能,就是通过路径名来分配并填充这个文件对应的文件对象。
do_filep_open(dfd, pathname, flags, mode, acc_mode)函数主要执行如下操作:
1,设置一堆访问模式标志
2,调用get_empty_filep()函数从名为filp_cachep的slab缓存中分配一个struct file*的文件对象。
3,如果flags中有O_CREATE标志,跳到,否则到4
4,调用do_path_lookup(dfd, pathname, flags, &nd)做目录查找,将查找结果填充到struct nameidata *nd中。还记得目录查找么?见这里
5,调用finish_open(nd, flags, mode)做一些合法性验验证并从nd->intent.open.file中获取到struct file* filep
6,调用release_open_intent(nd)做一些清理工作。主要是减少nd->intent.open.file中的一些引用计数。
7,返回filep
8,到这一步说明flags中有O_CREATE标志,需要在目录查找过程中逐级创建对应的目录和文件,这一步依次调用path_init_rcu(), path_walk_rcu()和path_finish_rcu()完成创建文件的目录查找工作,最终依然是将查找结果填充到struct nameidata *nd中。(在标准的目录查找do_path_lookup()的实现中,主干流程也是依次调用着三个函数做查找工作)
9,调用do_last(&nd, &path, flags, acc_mode, mode, pathname)函数获取最终的struct file filep结构。在这个函数中,内核会根据nd->last_type做不同的处理,对于普通文件,会调用finish_open(nd, flags, mode)做一些合法性验验证并从nd->intent.open.file中获取到struct file filep
10,调用release_open_intent(nd)做一些清理工作。主要是减少nd->intent.open.file中的一些引用计数。
11,返回filep
内核源代码中涉及到sys_open实现的文件主要有fs/open.c fs/namei.c fs/compat.c fs/file.c fs/file_table.c等
一、给MenuOS增加time和time-asm命令
- 把menu删除;
rm menu -rf 强制删除
-
重新克隆一个新的Menu;
-
进入Menu,用makerootfs自动编译生成根文件系统,同时还自动启动MenuOS
-
增加了两个命令:time和time_asm,说明扩展了功能。
二、使用gdb跟踪系统调用内核函数sys_time
-
一直按n单步执行会进入schedule函数
-
Sys_time返回后进入汇编代码处理gdb无法继续跟踪
-
执行int 0x80之后执行system_call对应的代码
-
让系统停在system_call的位置进行调试
-
执行int 0x80之后执行system_call对应的代码
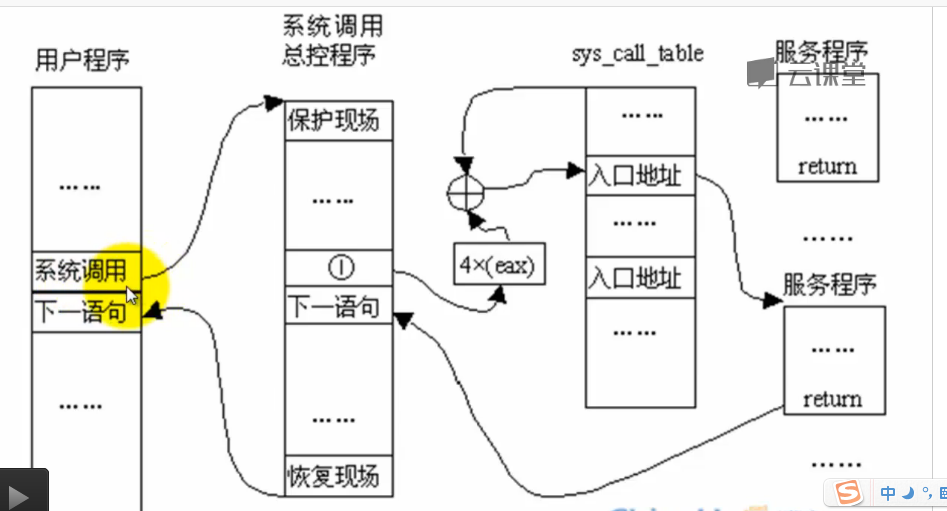
三、系统调用在内核代码中的处理过程
1.系统调用在内核代码中的工作机制和初始化
(1)进程调度的时机要分析一下
-
sys_call_table是系统调用分派表
-
syscall_after_all,需要先保存返回值
-
sys_exit_work
-
没有这个就restore_all,返回用户态。
-
一旦进入sys_exit_work:会有一个进程调度时机
2.简化后便于理解的system_call伪代码:
(1)系统调用的工作机制一旦在start kernel初始化好之后,在代码中一旦出现inter 0x80的指令,它就会立即跳转到system_call这个位置
call *sys_call_table(,%eax,4)调用了系统调度处理函数,eax存的是系统调用号
(2)定义的宏SAVE_ALL和RESTORE_ALL
(3)当一个系统调用发生的时候,它进入内核处理这个系统调用,内核提供了一些服务,在这个服务结束返回到用户态之前,它可能会发生
进程调度,就会发生进程上下文的切换和中断上下文的切换。
3.system_call到iret之间的主要代码分析:
SAVE_ALL:保存现场;
syscall_call:调用了系统调用处理函数;
restore all:恢复现场(因为系统调用处理函数也算是一种特殊的“中断”);syscallexitwork:同上一条i;
INTERRUPT RETURN:也就是iret,系统调用到此结束;
\arch\x86\kernel\traps.c中有一个函数,将SYSCALL_WECTOR(系统调用中断向量)和system_call汇编代码的入口绑定。完成初始化
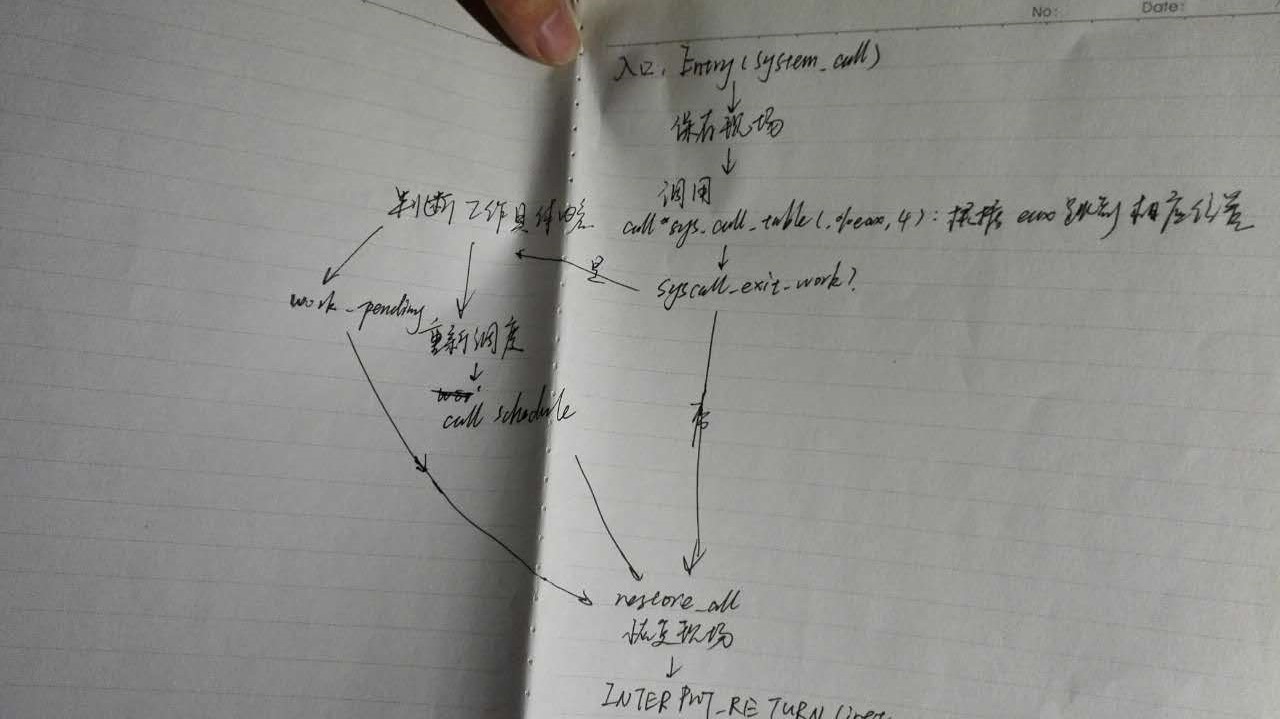
简化汇编伪代码
Save_all保存现场
Sys_call_table:绑定系统调用函数
Interrupt_return:结束
韩玉琪同学总结得很到位,在此冒昧引用
系统调用就是特殊的一种中断
- 保存现场 在系统调用时,我们需要SAVE_ALL,用于保存系统调用时的上下文。 同样,中断处理的第一步应该也要保存中断程序现场。 目的:在中断处理完之后,可以返回到原来被中断的地方,在原有的运行环境下继续正确的执行下去。
- 确定中断信息 在系统调用时,我们需要将系统调用号通过eax传入,通过sys_call_table查询到调用的系统调用,然后跳转到相应的程序进行处理。
同样,中断处理时系统也需要有一个中断号,通过检索中断向量表,了解中断的类型和设备。- 处理中断 跳转到相应的中断处理程序后,对中断进行处理。
- 返回 系统调用时最后要restore_all恢复系统调用时的现场,并用iret返回用户态。 同样,执行完中断处理程序,内核也要执行特定指令序列,恢复中断时现场,并使得进程回到用户态。
一、进程的描述
1.操作系统三大功能
- 进程管理
- 内存管理
- 文件系统
最核心的是进程管理
2、进程的作用
将信号、进程间通信、内存管理和文件系统联系起来
3.进程控制块PCB——task_struct
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大
Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING,为什么呢?
进程的标示pid
所有进程链表struct list_head tasks;
内核的双向循环链表的实现方法 - 一个更简略的双向循环链表
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,那为什么PCB中没有用户态堆栈?用户态堆栈是怎么设定的?
内核控制路径所用的堆栈很少,因此对栈和Thread_info来说,8KB足够了
struct thread_struct thread; //CPU-specific state of this task
文件系统和文件描述符
内存管理——进程的地址空间
分析:
pid_t pid又叫进程标识符,唯一地标识进程
list_head tasks即进程链表
——双向循环链表链接起了所有的进程,也表示了父子、兄弟等进程关系
struct mm_struct 指的是进程地址空间,涉及到内存管理(对于X86而言,一共有4G的地址空间)
thread_struct thread 与CPU相关的状态结构体
struct *file表示打开的文件链表
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
4.进程状态转换图
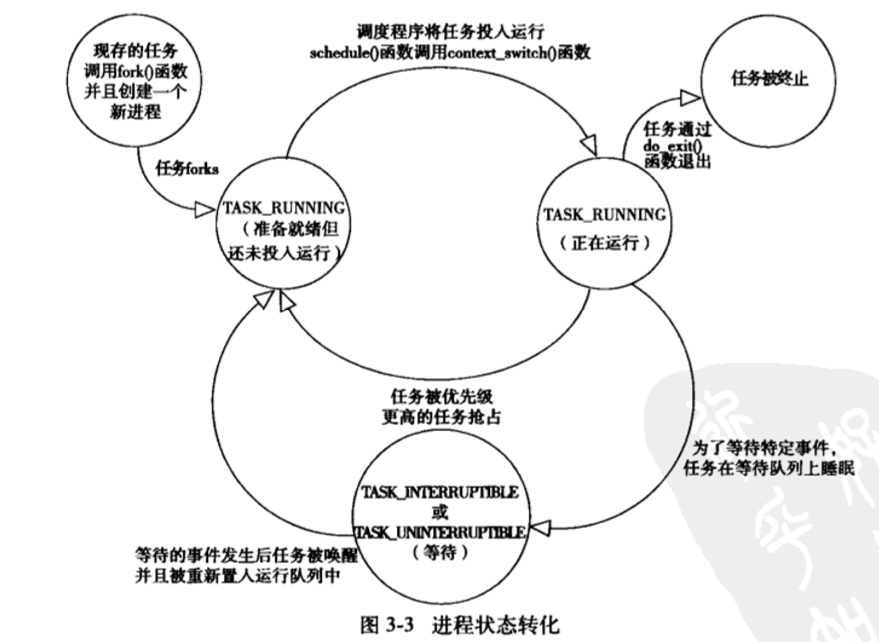
Linux进程的状态与操作系统原理中的描述的进程状态有所不同,比如就绪状态和运行状态都是TASK_RUNNING
一般操作系统原理中描述的进程状态有就绪态,运行态,阻塞态,但是在实际内核进程管理中是不一样的。
struct task_struct数据结构很庞大
二、进程的创建
1.进程的创建概览及fork一个进程的用户态代码
道生一(start_kernel....cpu_idle),一生二(kernel_init和kthreadd),二生三(即前面0、1和2三个进程),三生万物(1号进程是所有用户态进程的祖先,0号进程是所有内核线程的祖先),新内核的核心代码已经优化的相当干净,都符合中国传统文化精神了
0号进程,是代码写死的,1号进程复制0号进程PCB,再修改,再加载可执行程序。
系统调用进程创建过程:
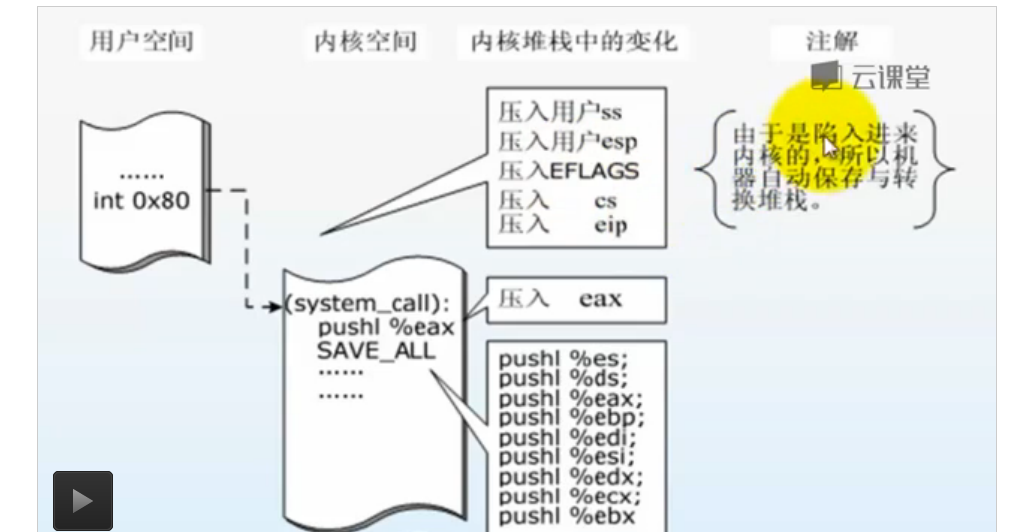
iret与int 0x80指令对应,一个是弹出寄存器值,一个是压入寄存器的值
如果将系统调用类比于fork();那么就相当于系统调用创建了一个子进程,然后子进程返回之后将在内核态运行,而返回到父进程后仍然在用户态运行。
进程的父子关系直观图:
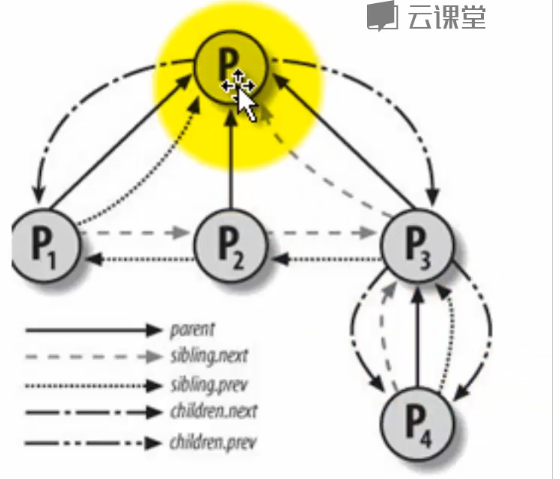
2.分析内核处理过程
do_fork
- 调用copy_process,将当前进程复制一份出来给子进程,并且为子进程设置相应地上下文信息。
- 调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中运行。
fork代码:fork、vfork和clone这三个函数最终都是通过do_fork函数实现的
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0) //pid == 0和下面的else都会被执行到(一个是在父进程中即pid ==0的情况,一个是在子进程中,即pid不等于0)
{
/* child process */pid=0时 if和else都会执行 fork系统调用在父进程和子进程各返回一次
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
创建新进程的框架do_fork:dup_thread复制父进程的PCB
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
}
copy_process:进程创建的关键,修改复制的PCB以适应子进程的特点,也就是子进程的初始化
- 创建进程描述符以及子进程所需要的其他所有数据结构,为子进程准备运行环境
- 调用dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。
- 复制所有的进程信息
- 调用copy_thread,设置子进程的堆栈信息,为子进程分配一个pid。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
// 分配一个新的task_struct
p = dup_task_struct(current);
// 检查该用户的进程数是否超过限制
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
// 检查该用户是否具有相关权限
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
retval = -EAGAIN;
// 检查进程数量是否超过 max_threads
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// 初始化自旋锁,挂起信号,定时器
retval = sched_fork(clone_flags, p);
// 初始化子进程的内核栈
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
// 这里为子进程分配了新的pid号
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
/* ok, now we should be set up.. */
// 设置子进程的pid
p->pid = pid_nr(pid);
// 如果是创建线程
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
// 线程组的leader设置为当前线程的leader
p->group_leader = current->group_leader;
// tgid是当前线程组的id,也就是main进程的pid
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
// 创建的是进程,自己是一个单独的线程组
p->group_leader = p;
// tgid和pid相同
p->tgid = p->pid;
}
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
//同一线程组内的所有线程、进程共享父进程
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
// 如果是创建进程,当前进程就是子进程的父进程
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
dup_ task_ struct
- 先调用alloc_task_struct_node分配一个task_struct结构体。
- 调用alloc_thread_info_node,分配了一个union。这里分配了一个thread_info结构体,还分配了一个stack数组。返回值为ti,实际上就是栈底。
- tsk->stack = ti将栈底的地址赋给task的stack变量。
- 最后为子进程分配了内核栈空间。
- 执行完dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
copy_thread:
- 获取子进程寄存器信息的存放位置
- 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
- 如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出
- 将父进程的寄存器信息复制给子进程。
- 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0.
- 子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
// 如果是创建的内核线程
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
// 内核线程开始执行的位置
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
// 复制内核堆栈,并不是全部,只是regs结构体(内核堆栈栈底的程序)
*childregs = *current_pt_regs();
childregs->ax = 0;
if (sp)
childregs->sp = sp;
// 子进程从ret_from_fork开始执行
p->thread.ip = (unsigned long) ret_from_fork;//调度到子进程时的第一条指令地址,也就是说返回的就是子进程的空间了
task_user_gs(p) = get_user_gs(current_pt_regs());
return err;
}
#ifdef CONFIG_SMP //条件编译,多处理器会用到
struct llist_node wake_entry;
int on_cpu;
struct task_struct *last_wakee;
unsigned long wakee_flips;
unsigned long wakee_flip_decay_ts;
int wake_cpu;
#endif
int on_rq;
int prio, static_prio, normal_prio;
unsigned int rt_priority; //与优先级相关
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
……
struct list_head tasks; //进程链表
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
3.创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
-
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
- 复制一个PCB——task_struct
$ err = arch_dup_task_struct(tsk, orig); //在这个函数复制父进程的数据结构 - 要给新进程分配一个新的内核堆栈
$ ti = alloc_thread_info_node(tsk, node); - 复制一个PCB——task_struct
$ tsk->stack = ti; //复制内核堆栈
$ setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
```
- 要修改复制过来的进程数据,比如pid、进程链表等等都要改
- 从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回。那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
```
$ *childregs = *current_pt_regs(); //复制内核堆栈
$ childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因
$ p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
$ p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
```
-
Linux通过复制父进程来创建一个新进程,通过调用do_ fork来实现并为每个新创建的进程动态地分配一个task_ struct结构。不论是使用 fork 还是 vfork 来创建进程,最终都是通过 do_fork() 方法来实现的。PS:当子进程获得CPU控制权的时候,它的ret_ from_ fork可以把后面堆栈从iret返回到用户态,这里的用户态是子进程的用户态
-
fork创建的新的子进程是从ret_from_fork开始执行的,然后跳转到syscall_exit,从系统调用中返回。
-
Linux中的线程,又是一种特殊的进程。
-
为了把内核中的所有进程组织起来,Linux提供了几种组织方式,其中哈希表和双向循环链表方式是针对系统中的所有进程(包括内核线程),而运行队列和等待队列是把处于同一状态的进程组织起来
-
fork()函数被调用一次,但返回两次
-
新进程如何开始的关键:
copy_thread()中:
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
将子进程的ip设置为ret_ form _ fork的首地址,因此子进程是从ret_ from_ fork开始执行的。
在设置子进程的ip之前:
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
*childregs = *current_ pt_ regs();
将父进程的regs参数赋值到子进程的内核堆栈,*childregs的类型为pt_regs,其中存放了SAVE ALL中压入栈的参数。
可执行程序的装载
1.可执行程序时如何产生的
- 编译器预处理
gcc -E -o XX.cpp XX.c (-m32)//.cpp是预处理文件
- 汇编器编译成汇编代码
gcc -x cpp-output -S -o hello.s hello.cpp (-m32)//.s是汇编代码
- 汇编代码编译成二进制目标文件(不可读,含有部分机器代码但不可执行)
gcc -x assembler -c hello.s -o hello.o (-m32)
- 链接成可执行文件
gcc -o hello.static hello.c (-m32) -static
2.目标文件格式ELF
目标文件三种形式
- 可重定位文件(用来和其他object文件一起创建下面两种文件)——.o文件
- 可执行文件(指出了应该从哪里开始执行)
- 共享文件(主要是.so文件,用来被链接编辑器和动态链接器链)
ELF格式:

左半边是ELF格式,右半边是执行时的格式
其中,ELF头描述了该文件的组织情况,程序投标告诉系统如何创建一个进程的内存映像,section头表包含了描述文件sections的信息。
当系统要执行一个文件的时候,理论上讲,他会把程序段拷贝到虚拟内存中某个段
装载可执行程序之前的工作
可执行程序的执行环境
一般我们执行一个程序的Shell环境,我们的实验直接使用execve系统调用。
Shell本身不限制命令行参数的个数,命令行参数的个数受限于命令自身
例如,int main(int argc, char *argv[])
又如, int main(int argc, char argv[], char envp[])//envp是shell的执行环境
Shell会调用execve将命令行参数和环境参数传递给可执行程序的main函数
int execve(const char * filename,char * const argv[ ],char * const envp[ ]);
装载时动态链接和运行时动态链接应用
动态链接分为可执行程序装载时动态链接和运行时动态链接(一般使用前者)
半期总结:
mooc快学完了,但感觉还是什么都没学到,虽然视频内容不多,但每个星期进程管理、内存管理、设备驱动、文件系统,从分析内核了解到整个系统是如何工作的,如何控制管理资源分配,进程切换并执行。内容复杂繁多,自成一体又相互联系,我这种学得不扎实的同学在这几周的学习中已经感受到了其中的压力。
我还有很多不足,也会在今后的学习中更加努力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号