【缓存】CPU高速缓存 之MESI 性协议 Gif 动画
CPU缓存架构
不同的CPU厂商的架构也有些不同,在这里只介绍流行的缓存架构

缓存一致性可以分为三个点:
- 在进程每个写入运算时都立刻采取措施保证资料一致性
- 每个独立的运算,假如它造成资料值的改变,所有进程都可以看到一致的改变结果
- 在每次运算之后,不同的进程可能会看到不同的值(这也就是没有一致性的行为)
缓存一致性协议有哪些:
缓存一致性协议有MSI,MESI,AMD Opteron:MOESI 协议,Synapse,Firefly及DragonProtocol等等
inter采用MESI协议。inter i7采用MESIF
注意编程中Valotile关键 的可见性是基于缓存一致原则的,不是基于MESI协议的。
MESI(梅西)协议:
在线体验 MESI 协议状态转换」过程的网站,地址如下: https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
VivioJS 动画旨在帮助您了解 MESI 缓存一致性协议。
描述了一个多处理器系统,包括3个CPU,具有本地缓存和主内存。为简单起见,主存储器包括4个位置a0,a1,a2和a3。缓存是直接映射的,包含两组。偶数地址(a0 和 a2)映射到设置 0,而奇数地址(a1 和 a3)映射到设置 1。
注意:为了简化此动画,缓存行的大小和 CPU 读/写操作的大小是相同的。但是,在写操作未命中时,CPU 会读取内存,即使它将完全覆盖缓存行。这模拟了实际缓存的行为,其中缓存行的大小通常大于 CPU 读/写操作的大小。
MESI 协议消息类型
想协调处理必然需要先和各个处理器进行通信。所以MESI协议定义了一组消息机制用于协调各个处理器的读写操作。
我们可以参考HTTP协议来进行理解,可以将MESI协议中的消息分为请求和响应两类。处理器在进行主内存读写的时候会往总线(Bus)中发请求消息,同时每个处理器还会嗅探(Snoop)总线中由其他处理器发出的请求消息并在一定条件下往总线中回复响应得响应消息。
针对于消息的类型,有如下几种:
-
Read : 请求消息,用于通知其他处理器、主内存,当前处理器准备读取某个数据。该消息内包含待读取数据的主内存地址。
-
Read Response: 响应消息,该消息内包含了被请求读取的数据。该消息可能是主内存返回的,也可能是其他高速缓存嗅探到Read 消息返回的。
-
Invalidate: 请求消息,通知其他处理器删除指定内存地址的数据副本。其实就是告诉他们你这个缓存条目内的数据无效了,删除只是逻辑上的,其实就是更新下缓存条目的Flag.
-
Invalidate Acknowledge: 响应消息,接收到Invalidate消息的处理器必须回复此消息,表示已经删除了其高速缓存内对应的数据副本。
-
Read Invalidate: 请求消息,此消息为Read 和 Invalidate消息组成的复合消息,作用主要是用于通知其他处理器当前处理器准备更新一个数据了,并请求其他处理器删除其高速缓存内对应的数据副本。接收到该消息的处理器必须回复Read Response 和 Invalidate Acknowledge消息。
-
Writeback: 请求消息,消息包含了需要写入主内存的数据和其对应的内存地址。
了解完了基础的消息类型,那么我们就来看看MESI协议是如何协助处理器实现内存读写的,看图说话:
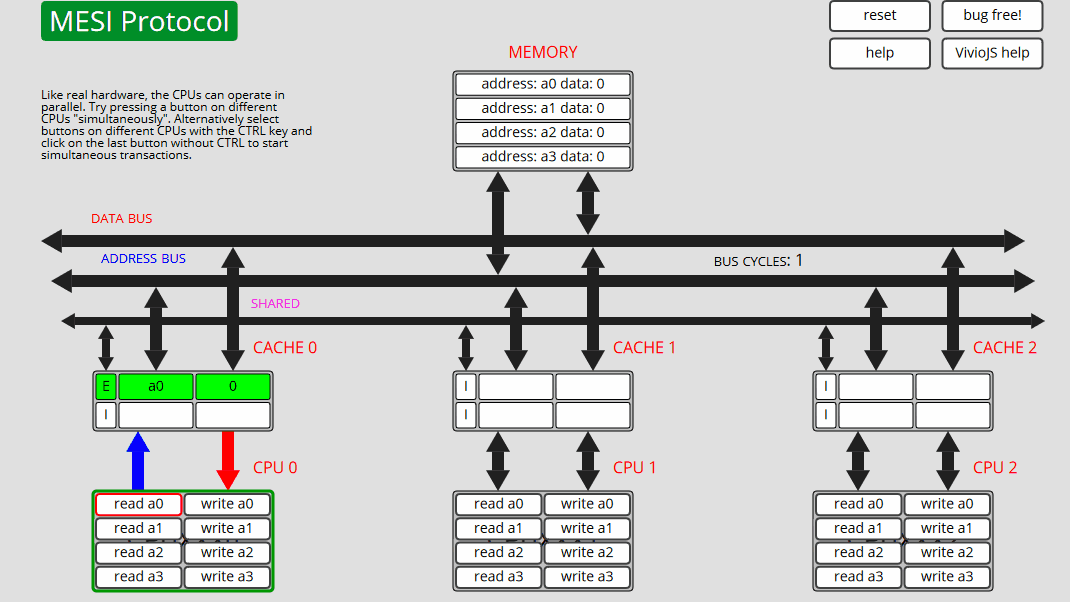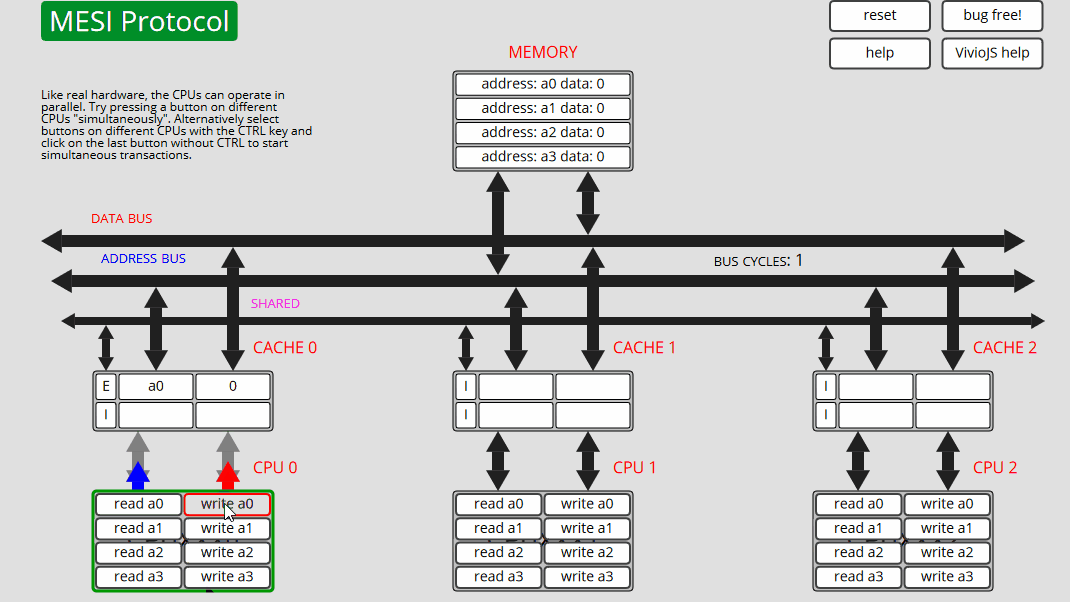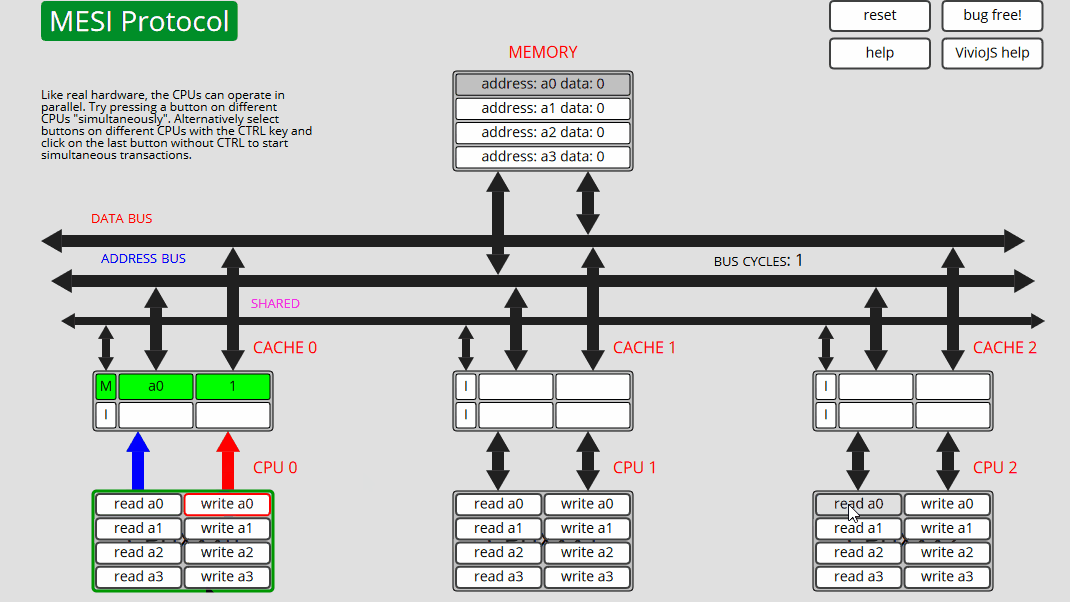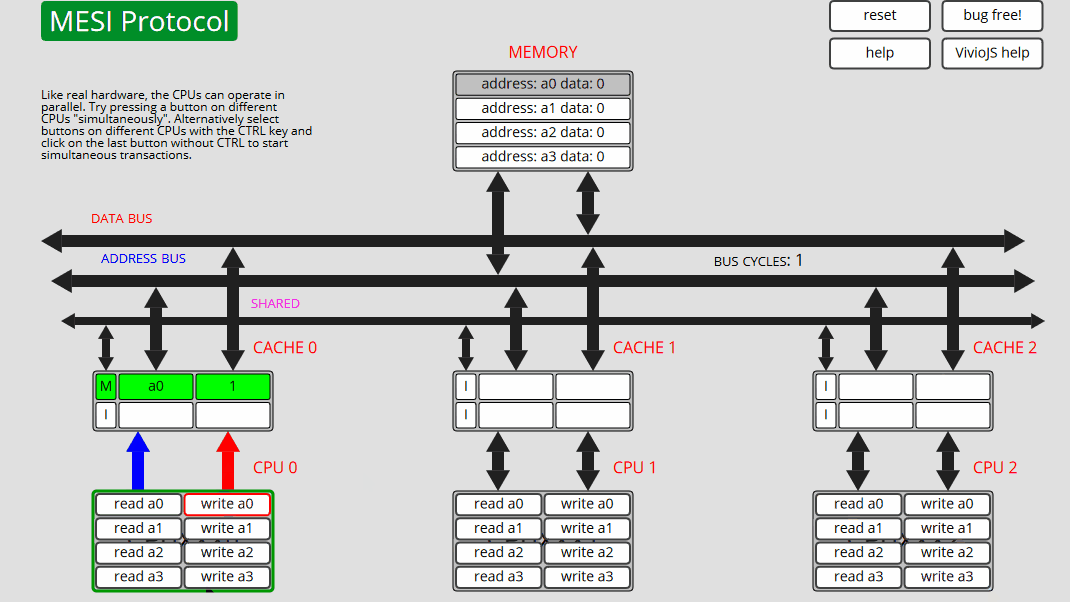
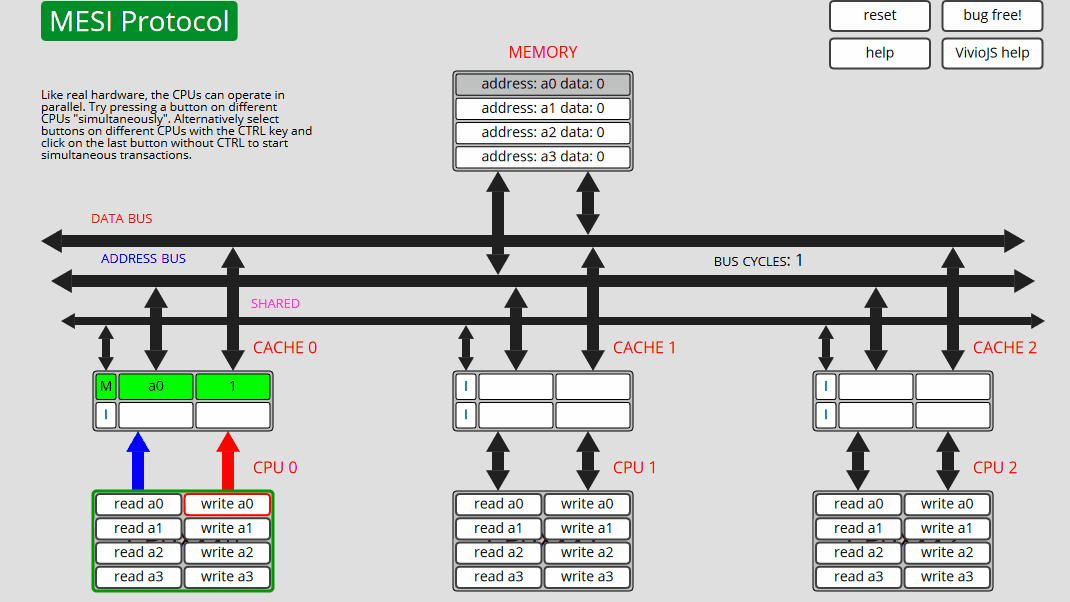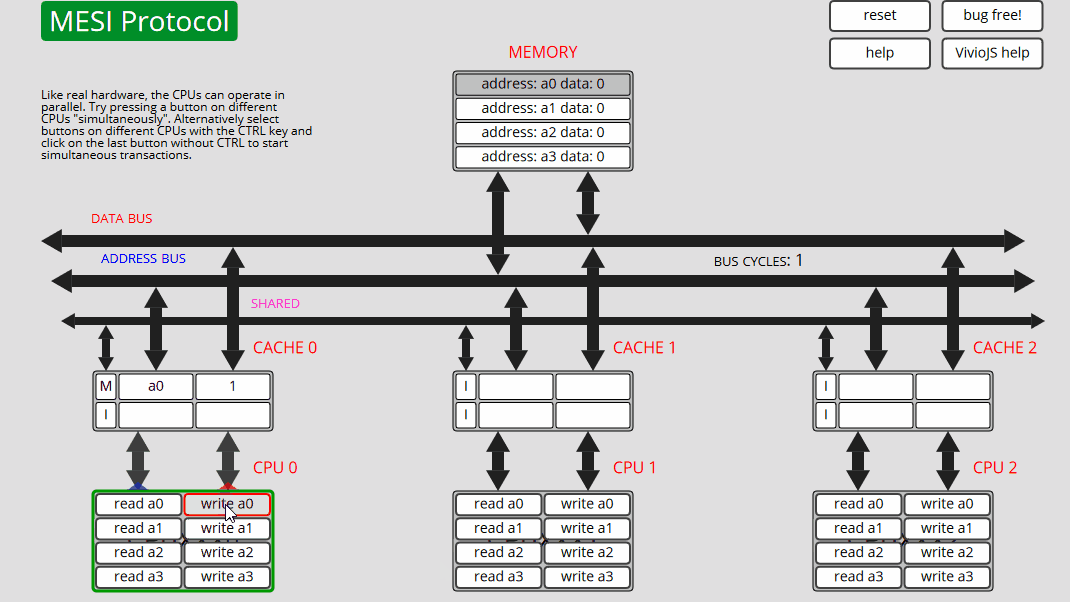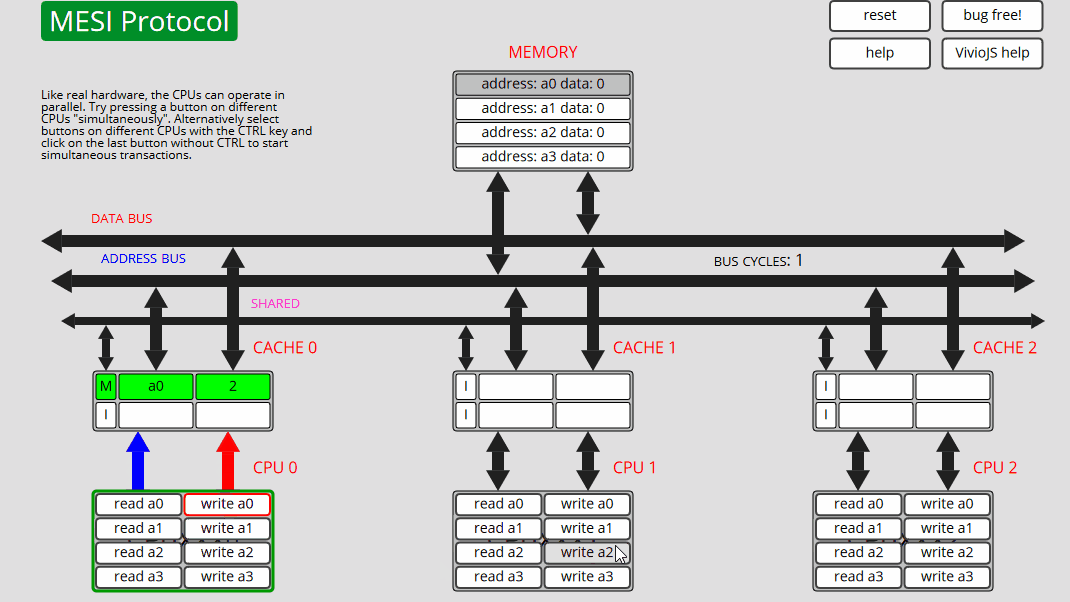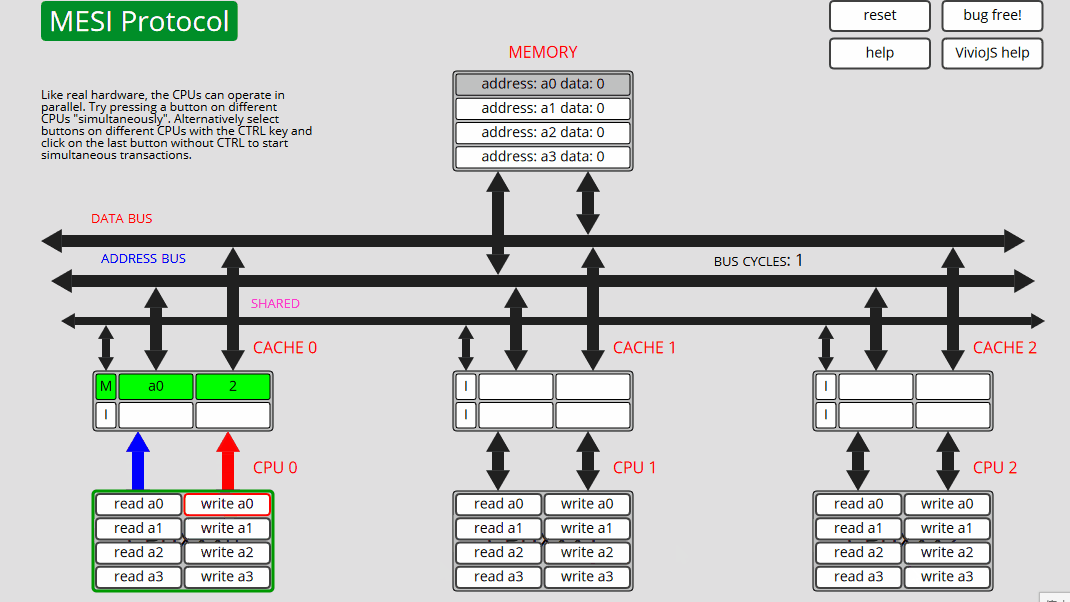
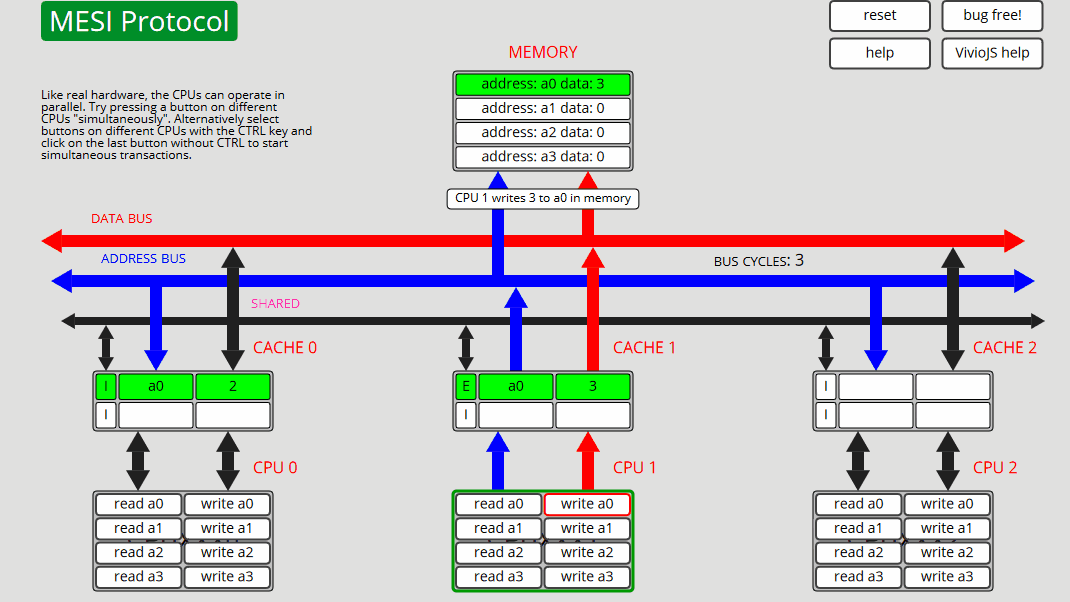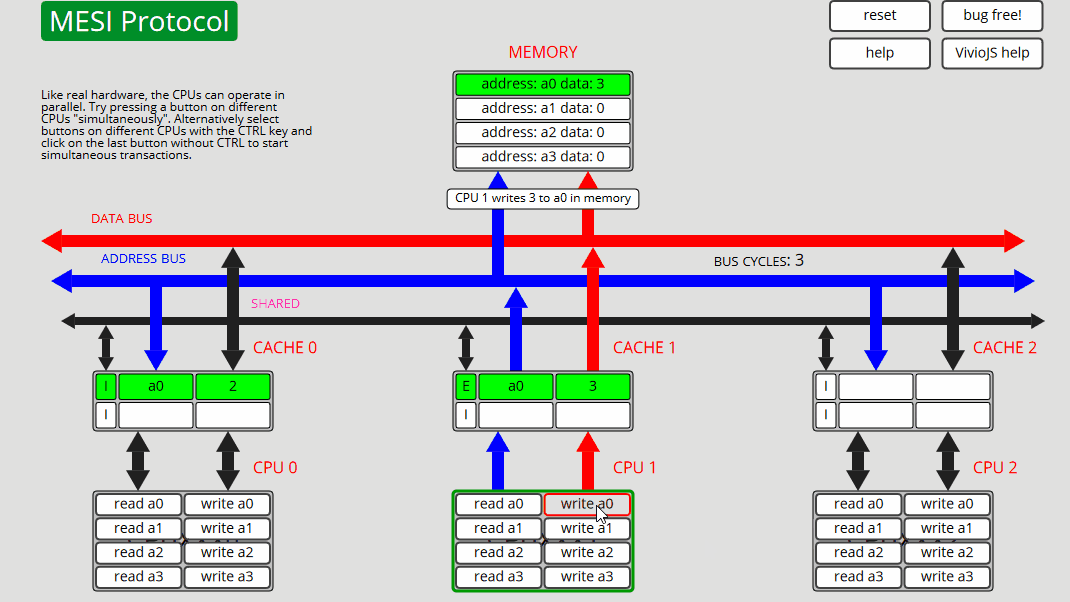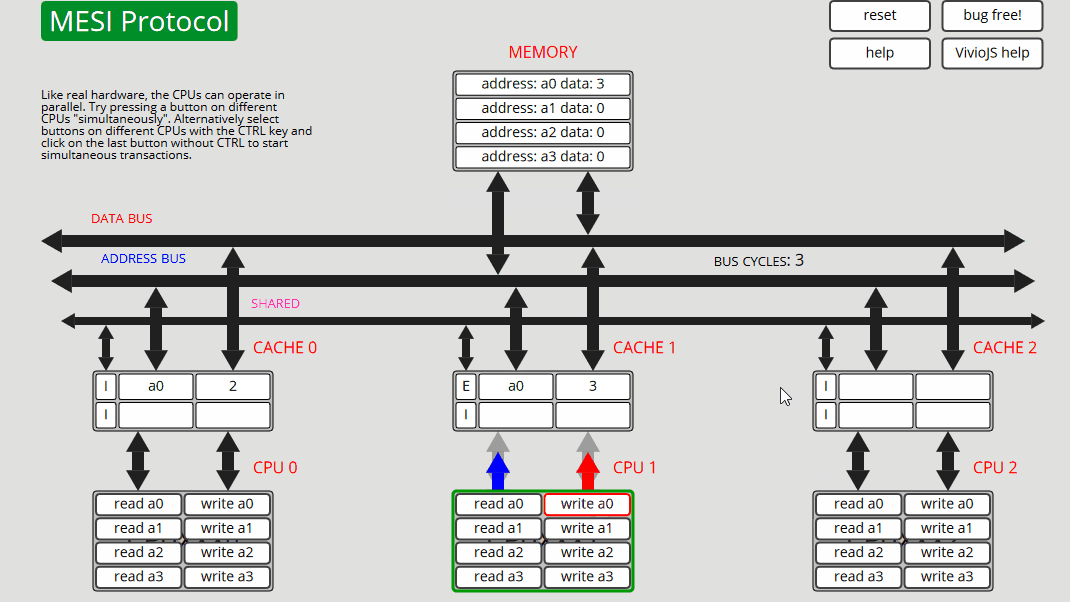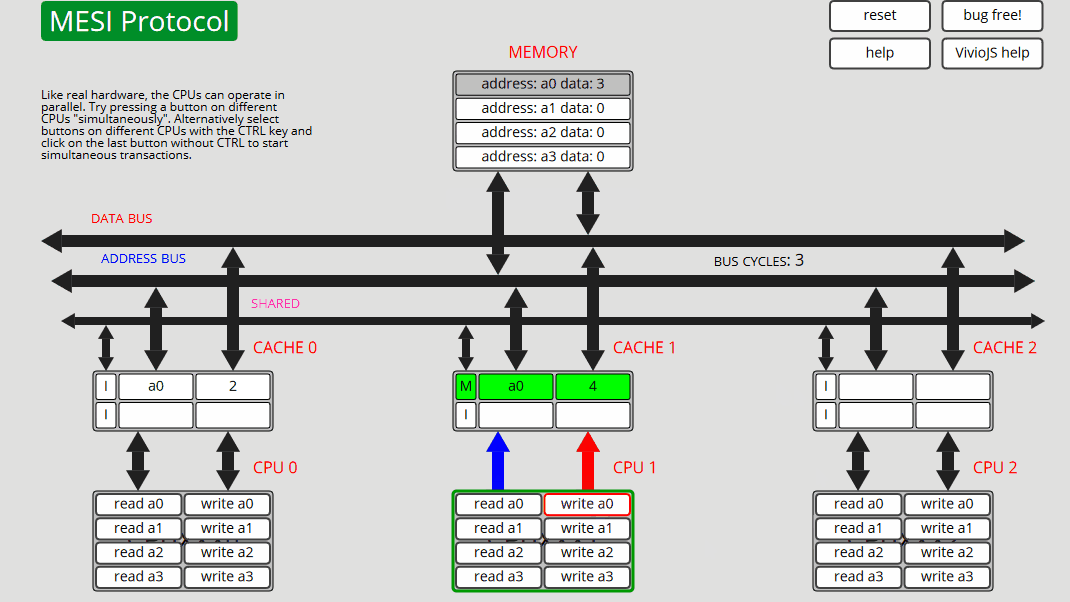
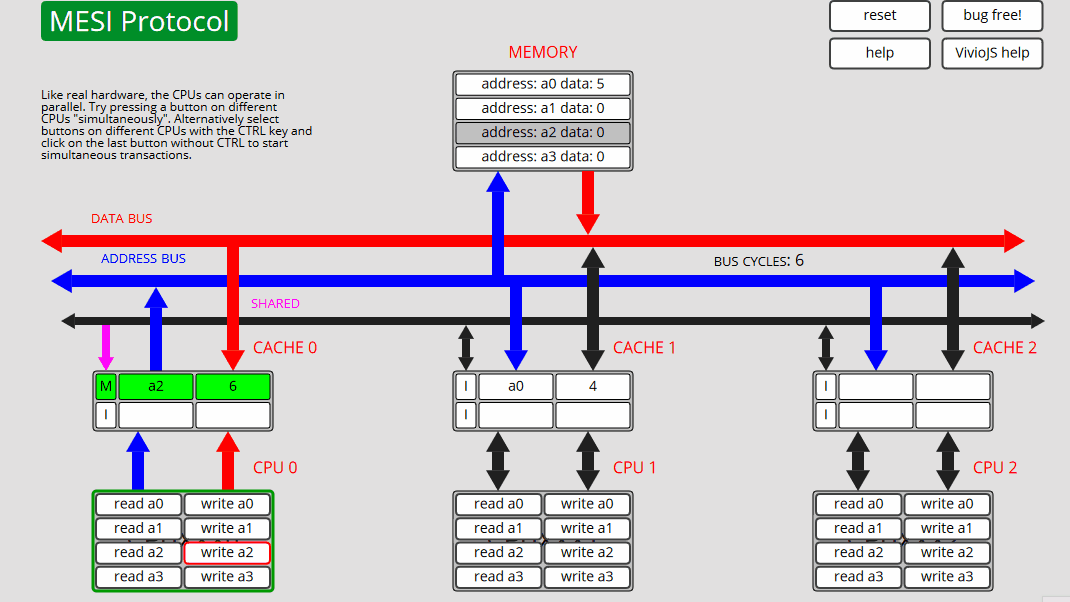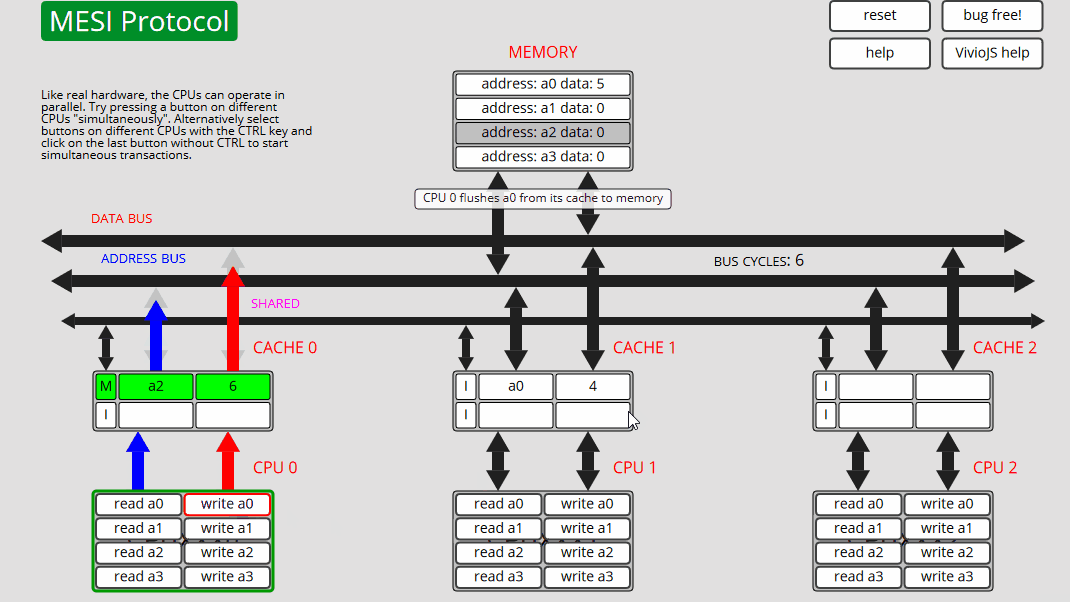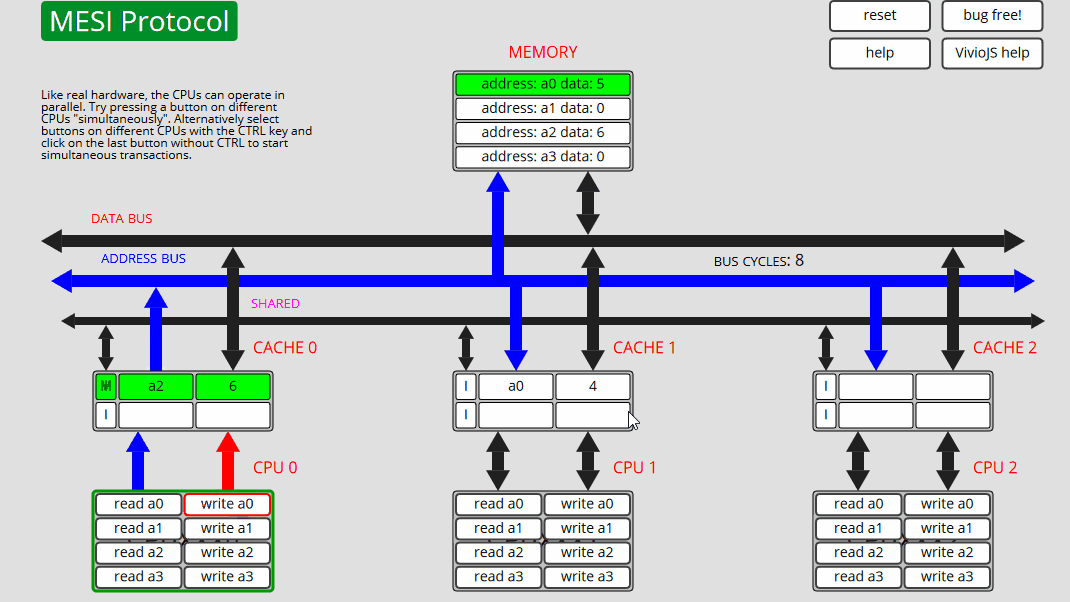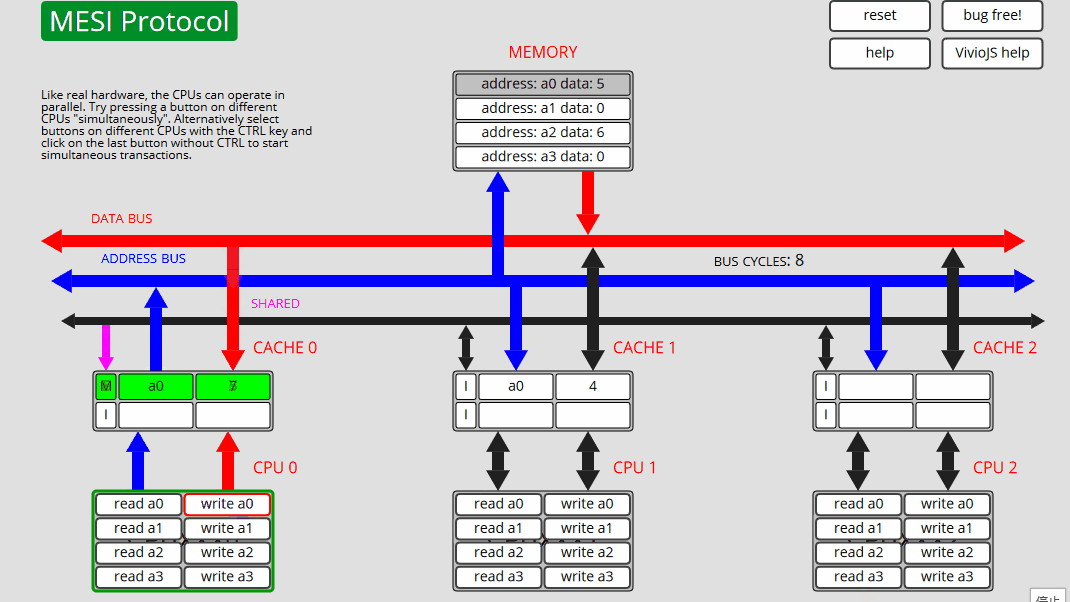
每个 CPU 都包含一些按钮,这些按钮在指定的内存位置上启动读取或写入事务。"CPU 写入"将递增值(最初为 1)写入"内存"。
我们的想法是按下按钮,看看是否可以遵循发生的操作和状态转换。可以通过按右上角的"无错误"按钮将错误引入动画中。看看你是否能确定错误是什么!
地址和数据总线上的流量方向分别由蓝色和红色箭头指示。事务中涉及的缓存行和内存位置显示为绿色。陈旧的内存位置显示为灰色。
缓存行可以处于以下 4 种状态之一。无效:缓存中不存在缓存行。EXCLUSIVE:仅此缓存中存在的缓存行,并且与内存中的副本相同。已修改:仅此缓存中存在缓存行,并且内存副本已过期(过时)。SHARED:此缓存中的缓存行以及可能的其他缓存,所有副本都与内存副本相同。对共享高速缓存行的写入是通过写来写的,而对EXCLUSIVE高速缓存行的写入是回写。如果缓存观察它所包含的地址的总线事务,它将断言 SHARED 总线行。MESI 是一种无效的缓存一致性协议。下面是缓存行的状态转换图:
1 CPU0:读取 a0 CPU0 从内存[非共享]读取 a0 - 状态 E
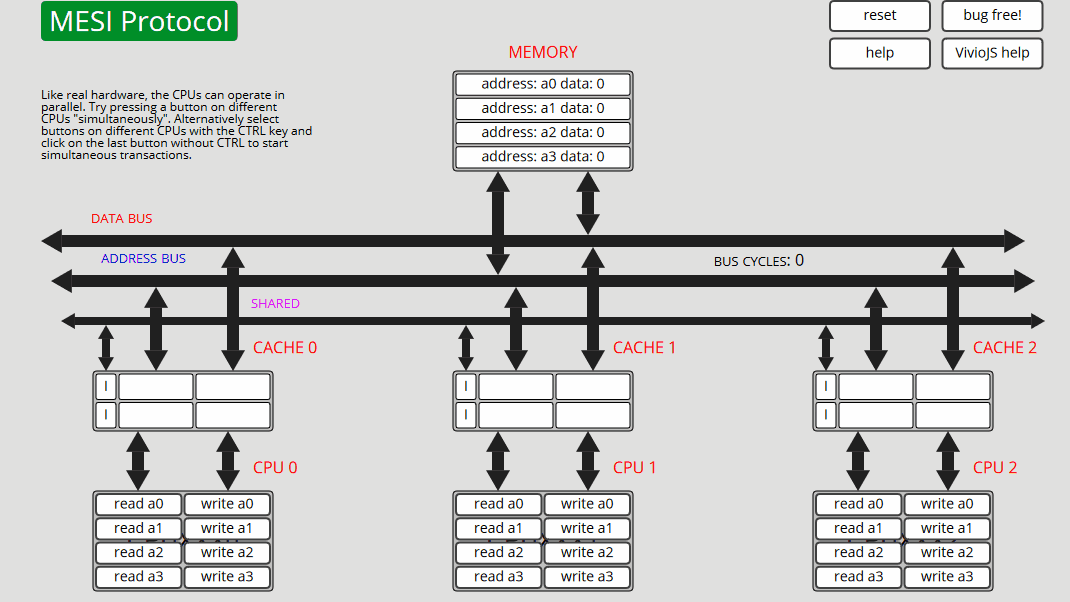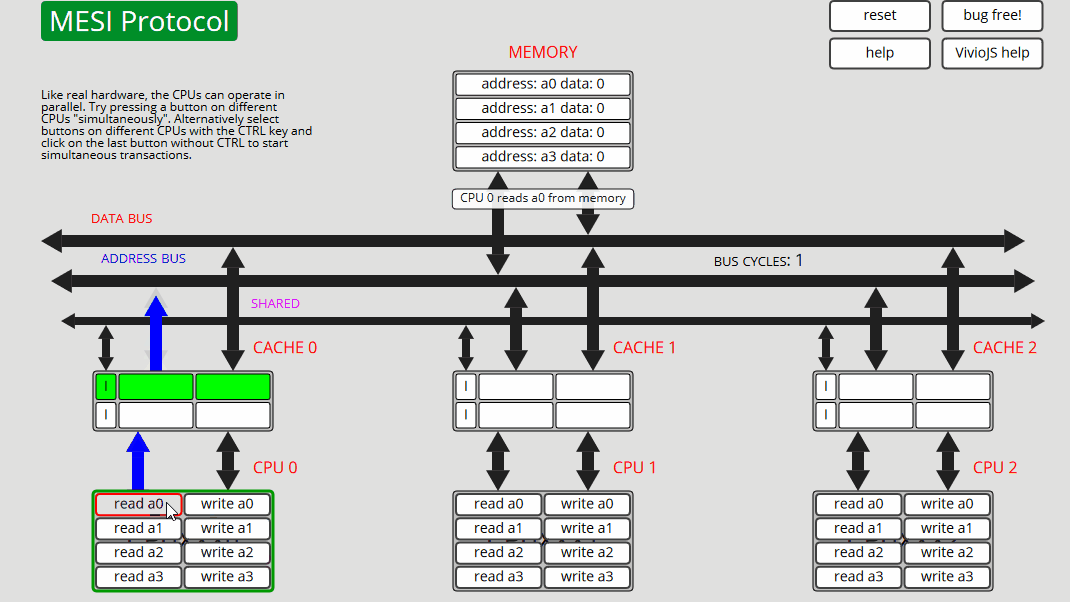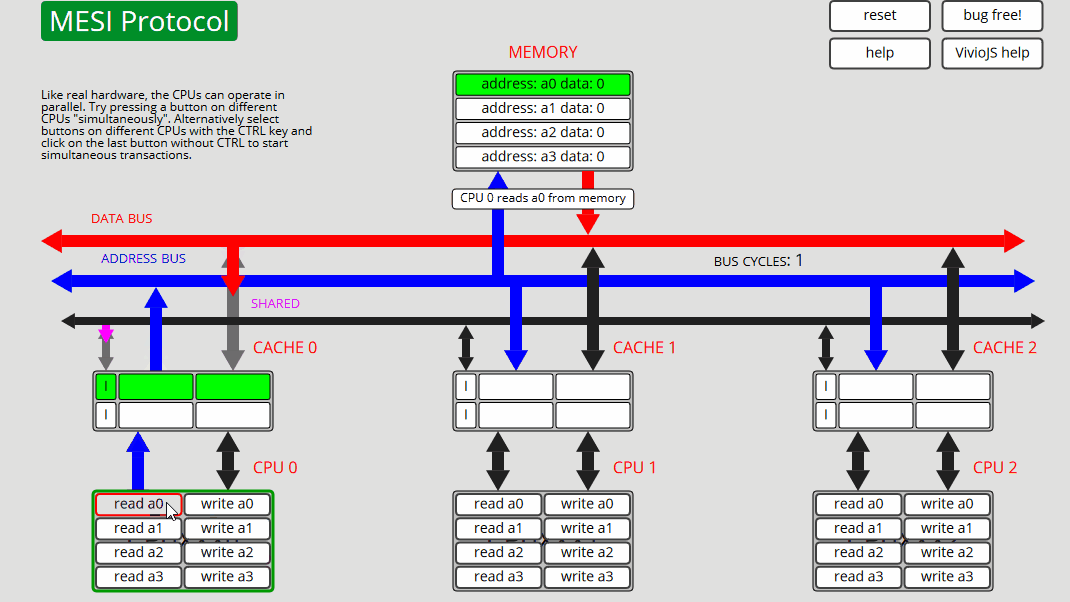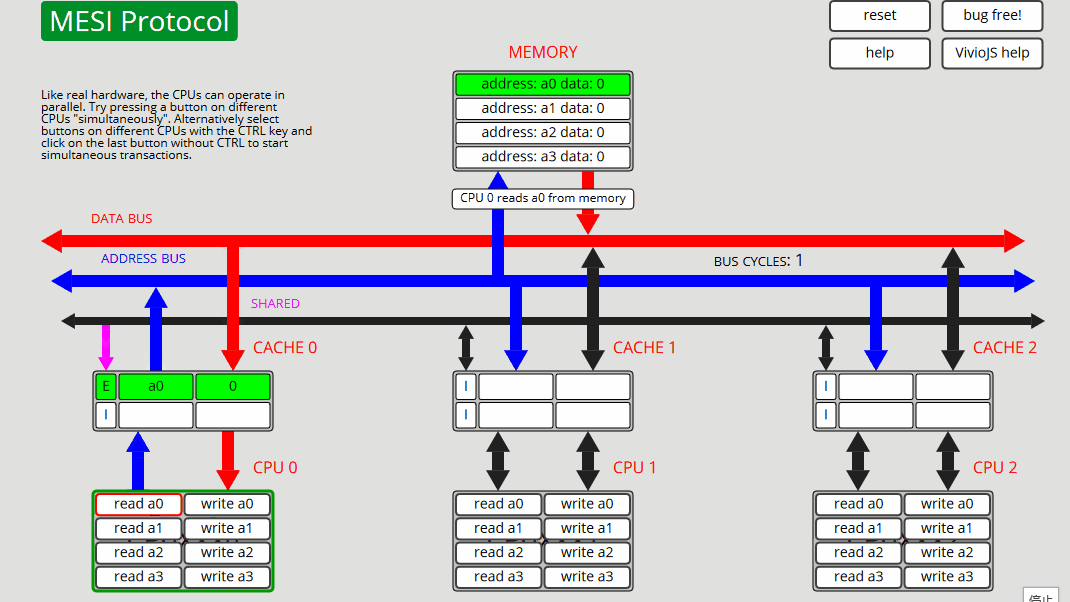
2 CPU0:读取 a0 CPU0 从缓存读取 a0 - 状态 E

3 CPU0: 写入 a0 CPU0 仅在缓存中更新 a0 - 状态 M
4 CPU0: 写入 a0 CPU0 仅在缓存中更新 a0 - 状态 M
5 CPU1: 读取 a0 CPU1 读取 a0,CPU0 高速缓存干预并向高速缓存和内存提供数据 - 状态 S

6 CPU1: 写入 a0 CPU1 更新缓存和内存中的 a0,并使地址为 a0 - 状态 E 的所有其他缓存失效

7 CPU1: 写入 a0 CPU1 仅在缓存中更新 a0 - 状态 M
8 CPU0: 写入 a0 CPU0 读取 a0,CPU1 缓存干预并向缓存和内存 (S) 提供数据,然后 CPU0 写入缓存和内存中的 a0,使地址为 a0 的所有其他缓存失效 - 状态

9 CPU0: 写入 a2 CPU0 从内存 (E) 读取 a2,然后写入 a2 - 状态 M

10 CPU0: 写入 a0 CPU0 将 a2 刷新到内存,从内存 (E) 读取 a2,然后写入 a0 - 状态 M
状态转换和cache操作
下面是缓存行的状态转换图:

素材来源:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
如上文内容所述,MESI协议中cache line数据状态有4种,引起数据状态转换的CPU cache操作也有4种,因此要理解MESI协议,就要将这16种状态转换的情况讨论清楚。
初始场景:在最初的时候,所有CPU中都没有数据,某一个CPU发生读操作,此时必然发生cache miss,数据从主存中读取到当前CPU的cache,状态为E(独占,只有当前CPU有数据,且和主存一致),此时如果有其他CPU也读取数据,则状态修改为S(共享,多个CPU之间拥有相同数据,并且和主存保持一致),如果其中某一个CPU发生数据修改,那么该CPU中数据状态修改为M(拥有最新数据,和主存不一致,但是以当前CPU中的为准),其他拥有该数据的核心通过缓存控制器监听到remote write行文,然后将自己拥有的数据的cache line状态修改为I(失效,和主存中的数据被认为不一致,数据不可用应该重新获取)。
(1)modify
场景:当前CPU中数据的状态是modify,表示当前CPU中拥有最新数据,虽然主存中的数据和当前CPU中的数据不一致,但是以当前CPU中的数据为准;
LR:此时如果发生local read,即当前CPU读数据,直接从cache中获取数据,拥有最新数据,因此状态不变;
LW:直接修改本地cache数据,修改后也是当前CPU拥有最新数据,因此状态不变;
RR:因为本地内存中有最新数据,当本地cache控制器监听到总线上有RR发生的时,必然是其他CPU发生了读主存的操作,此时为了保证一致性,当前CPU应该将数据写回主存,而随后的RR将会使得其他CPU和当前CPU拥有共同的数据,因此状态修改为S;
RW:同RR,当cache控制器监听到总线发生RW,当前CPU会将数据写回主存,因为随后的RW将会导致主存的数据修改,因此状态修改成I;
(2)exclusive
场景:当前CPU中的数据状态是exclusive,表示当前CPU独占数据(其他CPU没有数据),并且和主存的数据一致;
LR:从本地cache中直接获取数据,状态不变;
LW:修改本地cache中的数据,状态修改成M(因为其他CPU中并没有该数据,因此不存在共享问题,不需要通知其他CPU修改cache line的状态为I);
RR:本地cache中有最新数据,当cache控制器监听到总线上发生RR的时候,必然是其他CPU发生了读取主存的操作,而RR操作不会导致数据修改,因此两个CPU中的数据和主存中的数据一致,此时cache line状态修改为S;
RW:同RR,当cache控制器监听到总线发生RW,发生其他CPU将最新数据写回到主存,此时为了保证缓存一致性,当前CPU的数据状态修改为I;
(3)shared
场景:当前CPU中的数据状态是shared,表示当前CPU和其他CPU共享数据,且数据在多个CPU之间一致、多个CPU之间的数据和主存一致;
LR:直接从cache中读取数据,状态不变;
LW:发生本地写,并不会将数据立即写回主存,而是在稍后的一个时间再写回主存,因此为了保证缓存一致性,当前CPU的cache line状态修改为M,并通知其他拥有该数据的CPU该数据失效,其他CPU将cache line状态修改为I;
RR:状态不变,因为多个CPU中的数据和主存一致;
RW:当监听到总线发生了RW,意味着其他CPU发生了写主存操作,此时本地cache中的数据既不是最新数据,和主存也不再一致,因此当前CPU的cache line状态修改为I;
(4)invalid
场景:当前CPU中的数据状态是invalid,表示当前CPU中是脏数据,不可用,其他CPU可能有数据、也可能没有数据;
LR:因为当前CPU的cache line数据不可用,因此会发生读内存,此时的情形如下。
A. 如果其他CPU中无数据则状态修改为E;
B. 如果其他CPU中有数据且状态为S或E则状态修改为S;
C. 如果其他CPU中有数据且状态为M,那么其他CPU首先发生RW将M状态的数据写回主存并修改状态为S,随后当前CPU读取主存数据,也将状态修改为S;
LW:因为当前CPU的cache line数据无效,因此发生LW会直接操作本地cache,此时的情形如下。
A. 如果其他CPU中无数据,则将本地cache line的状态修改为M;
B. 如果其他CPU中有数据且状态为S或E,则修改本地cache,通知其他CPU将数据修改为I,当前CPU中的cache line状态修改为M;
C. 如果其他CPU中有数据且状态为M,则其他CPU首先将数据写回主存,并将状态修改为I,当前CPU中的cache line转台修改为M;
RR:监听到总线发生RR操作,表示有其他CPU读取内存,和本地cache无关,状态不变;
RW:监听到总线发生RW操作,表示有其他CPU写主存,和本地cache无关,状态不变;
MESI协议带来的问题
1、MESI协议的消息在cpu的多core之间通信需要消耗时间,导致内核在此期间将无事可做。甚至一旦某一个内核发生阻塞,将会导致其他内核也处于阻塞,从而带来性能和稳定性的极大消耗。

2、MESI协议状态切换需要时间。
为了解决这两个问题,引入了store buffer和invalidate queue
- store buffer:将cpu的写入先保存这个堆栈中。等到得到其他cpu已经更新缓存行的消息后,再将数据写入缓存。
- invalidate queue:当前cpu的缓存收到其他cpu缓存行状态变更的消息时就回复Acknowledge 消息,不用等当前缓存行更新完后在回复其他cpu缓存信息、并且当前cpu的缓存下设置一个invalidate queue。用户存储其他cpu的缓存发过来的信息,等到有空再处理。
Store Buffere---存储缓存
store buffer即存储缓存。位于内核和缓存之间。当处理器需要处理将计算结果写入在缓存中处于shared状态的数据时,需要通知其他内核将该缓存置为 Invalid(无效),引入store buffer后将不再需要处理器去等待其他内核的响应结果,只需要把修改的数据写到store buffer,通知其他内核,然后当前内核即可去执行其它指令。当收到其他内核的响应结果后,再把store buffer中的数据写回缓存,并修改状态为M。(很类似分布式中,数据一致性保障的异步确认)
Invalidate Queue---失效队列
简单说处理器修改数据时,需要通知其它内核将该缓存中的数据置为Invalid(失效),我们将该数据放到了Store Buffere处理。那收到失效指令的这些内核会立即处理这种失效消息吗?答案是不会的,因为就算是一个内核缓存了该数据并不意味着马上要用,这些内核会将失效通知放到Invalidate Queue,然后快速返回Invalidate Acknowledge消息(意思就是尽量不耽误正在用这个数据的内核正常工作)。后续收到失效通知的内核将会从该queue中逐个处理该命令。(意思就是我也不着急用,所以我也不着急处理)。
再解决这两个问题后,指令重排开始发挥它的价值。想想这种等待有时是没有必要的,因为在这个等待时间内内核完全可以去干一些其他事情。即当内核处于等待状态时,不等待当前指令结束接着去处理下一个指令。
但是这时候有带来另一个问题。指令乱序执行。这边就不继续探讨了。
当cpu0要写数据到本地cache的时候,如果不是M或者E状态,需要发送一个invalidate消息给cpu1,只有收到cpu1的acknowledgement才能写数据到cache中,在这个过程中cpu0需要等待,这大大影响了性能。一种解决办法是在cpu和cache之间引入store buffer,当发出invalidate之后直接把数据写入store buffer。当收到acknowledgement之后可以把store buffer中的数据写入cache。现在的架构图是这样的:

总结。
MESI协议为了保证多个CPU cache中共享数据的一致性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号