


102302134陈蔡裔数据采集第三次作业
第一题
核心代码和运行结果
import os
import requests
from bs4 import BeautifulSoup
import threading
from urllib.parse import urljoin
class MiniCrawler:
def __init__(self):
self.downloaded = 0
self.visited = set()
self.lock = threading.Lock()
os.makedirs('images', exist_ok=True)
def save_image(self, img_url):
if self.downloaded >= 134: # 图片数量限制
return False
try:
r = requests.get(img_url, timeout=3)
filename = f"images/img_{self.downloaded + 1}.jpg"
with open(filename, 'wb') as f:
f.write(r.content)
with self.lock:
self.downloaded += 1
print(f"下载 {self.downloaded}/134: {img_url}")
return True
except:
return False
def crawl_page(self, url):
if url in self.visited or len(self.visited) >= 34: # 页面数量限制
return []
self.visited.add(url)
print(f"页面 {len(self.visited)}/34: {url}")
try:
r = requests.get(url, timeout=3)
soup = BeautifulSoup(r.text, 'html.parser')
# 下载图片
for img in soup.find_all('img'):
src = img.get('src')
if src and self.downloaded < 134:
full_url = urljoin(url, src)
if any(full_url.lower().endswith(ext) for ext in ['.jpg', '.png', '.gif']):
self.save_image(full_url)
# 收集链接
links = []
for a in soup.find_all('a', href=True):
full_url = urljoin(url, a['href'])
if 'weather.com.cn' in full_url and full_url not in self.visited:
links.append(full_url)
return links[:5] # 每页只取5个链接
except:
return []
# 单线程版本
def single_thread():
crawler = MiniCrawler()
queue = ['http://www.weather.com.cn']
while queue and crawler.downloaded < 134 and len(crawler.visited) < 34:
url = queue.pop(0)
new_links = crawler.crawl_page(url)
queue.extend(new_links)
print(f"完成! 下载了 {crawler.downloaded} 张图片")
# 多线程版本
def multi_thread():
crawler = MiniCrawler()
queue = ['http://www.weather.com.cn']
def worker():
while queue and crawler.downloaded < 134 and len(crawler.visited) < 34:
with crawler.lock:
if not queue:
return
url = queue.pop(0)
new_links = crawler.crawl_page(url)
with crawler.lock:
queue.extend(new_links)
threads = []
for _ in range(3): # 3个线程
t = threading.Thread(target=worker)
threads.append(t)
t.start()
for t in threads:
t.join()
print(f"完成! 下载了 {crawler.downloaded} 张图片")
if __name__ == "__main__":
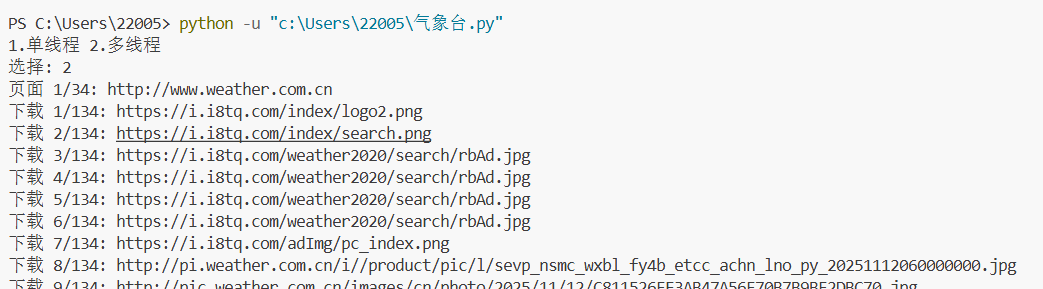
print("1.单线程 2.多线程")
choice = input("选择: ")
if choice == "1":
single_thread()
else:
multi_thread()
作业心得
通过本次爬虫实验,我深刻理解了单线程与多线程的运作差异,掌握了网页解析、资源限制和并发控制等核心技术。实践中不仅学会了应对反爬机制,还培养了工程化思维,认识到在保证功能完整性的同时代码简洁的重要性,为后续数据处理项目打下了坚实基础。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业3
第二题
核心代码和运行结果
import scrapy
import json
from stock_spider.items import StockItem
from datetime import datetime
import time
class EastmoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
def start_requests(self):
# 使用东方财富API接口
base_url = "http://82.push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '50', # 获取50条数据
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18',
'_': str(int(time.time() * 1000))
}
# 构建完整的URL
url = base_url + '?' + '&'.join([f'{k}={v}' for k, v in params.items()])
yield scrapy.Request(
url=url,
callback=self.parse_stock_data,
headers={
'Referer': 'http://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
)
def parse_stock_data(self, response):
try:
data = json.loads(response.text)
if data['data'] and 'diff' in data['data']:
stocks = data['data']['diff']
for index, stock in enumerate(stocks, 1):
item = StockItem()
item['id'] = index
item['stock_code'] = stock.get('f12', '') # 股票代码
item['stock_name'] = stock.get('f14', '') # 股票名称
item['current_price'] = stock.get('f2', 0) # 最新价
item['change_percent'] = stock.get('f3', 0) # 涨跌幅
item['change_amount'] = stock.get('f4', 0) # 涨跌额
item['volume'] = self.format_volume(stock.get('f5', 0)) # 成交量
item['amplitude'] = stock.get('f7', 0) # 振幅
item['high'] = stock.get('f15', 0) # 最高
item['low'] = stock.get('f16', 0) # 最低
item['open'] = stock.get('f17', 0) # 今开
item['previous_close'] = stock.get('f18', 0) # 昨收
item['crawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
yield item
else:
self.logger.error("未获取到股票数据")
except Exception as e:
self.logger.error(f"解析数据失败: {e}")
def format_volume(self, volume):
"""格式化成交量"""
try:
volume = float(volume)
if volume >= 100000000:
return f"{volume/100000000:.2f}亿"
elif volume >= 10000:
return f"{volume/10000:.2f}万"
else:
return str(volume)
except:
return "0"
数据模型
import scrapy
class StockItem(scrapy.Item):
# 定义数据库表字段
id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open = scrapy.Field() # 今开
previous_close = scrapy.Field() # 昨收
crawl_time = scrapy.Field() # 爬取时间
数据管道
import pymysql
from itemadapter import ItemAdapter
class MySQLPipeline:
def __init__(self, mysql_uri, mysql_db, mysql_user, mysql_pass):
self.mysql_uri = mysql_uri
self.mysql_db = mysql_db
self.mysql_user = mysql_user
self.mysql_pass = mysql_pass
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_uri=crawler.settings.get('MYSQL_URI', 'localhost'),
mysql_db=crawler.settings.get('MYSQL_DATABASE', 'stock_db'),
mysql_user=crawler.settings.get('MYSQL_USER', 'root'),
mysql_pass=crawler.settings.get('MYSQL_PASSWORD', 'password')
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.mysql_uri,
user=self.mysql_user,
password=self.mysql_pass,
database=self.mysql_db,
charset='utf8mb4'
)
self.cursor = self.connection.cursor()
# 创建表
self.create_table()
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INT PRIMARY KEY,
stock_code VARCHAR(20) NOT NULL,
stock_name VARCHAR(50) NOT NULL,
current_price DECIMAL(10,2),
change_percent DECIMAL(6,2),
change_amount DECIMAL(10,2),
volume VARCHAR(20),
amplitude DECIMAL(6,2),
high DECIMAL(10,2),
low DECIMAL(10,2),
open DECIMAL(10,2),
previous_close DECIMAL(10,2),
crawl_time DATETIME,
UNIQUE KEY unique_stock (stock_code)
)
"""
self.cursor.execute(create_table_sql)
self.connection.commit()
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
# 使用INSERT ... ON DUPLICATE KEY UPDATE 避免重复数据
sql = """
INSERT INTO stock_data (
id, stock_code, stock_name, current_price, change_percent,
change_amount, volume, amplitude, high, low, open, previous_close, crawl_time
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
current_price = VALUES(current_price),
change_percent = VALUES(change_percent),
change_amount = VALUES(change_amount),
volume = VALUES(volume),
crawl_time = VALUES(crawl_time)
"""
self.cursor.execute(sql, (
item['id'],
item['stock_code'],
item['stock_name'],
item['current_price'],
item['change_percent'],
item['change_amount'],
item['volume'],
item['amplitude'],
item['high'],
item['low'],
item['open'],
item['previous_close'],
item['crawl_time']
))
self.connection.commit()
return item
class JsonWriterPipeline:
def open_spider(self, spider):
self.file = open('stocks.json', 'w', encoding='utf-8')
self.file.write('[\n')
def close_spider(self, spider):
self.file.write('\n]')
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.file.write(line)
return item
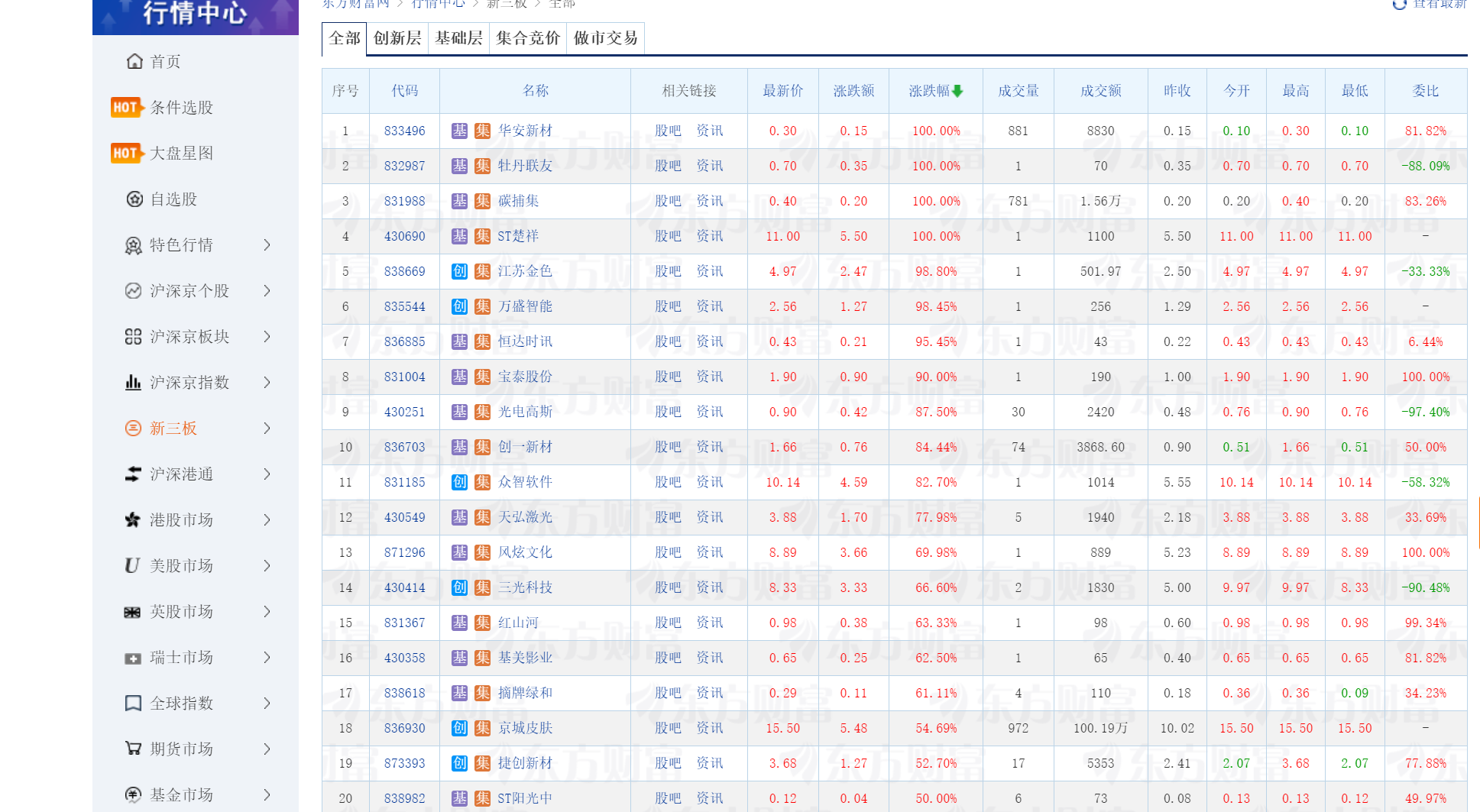
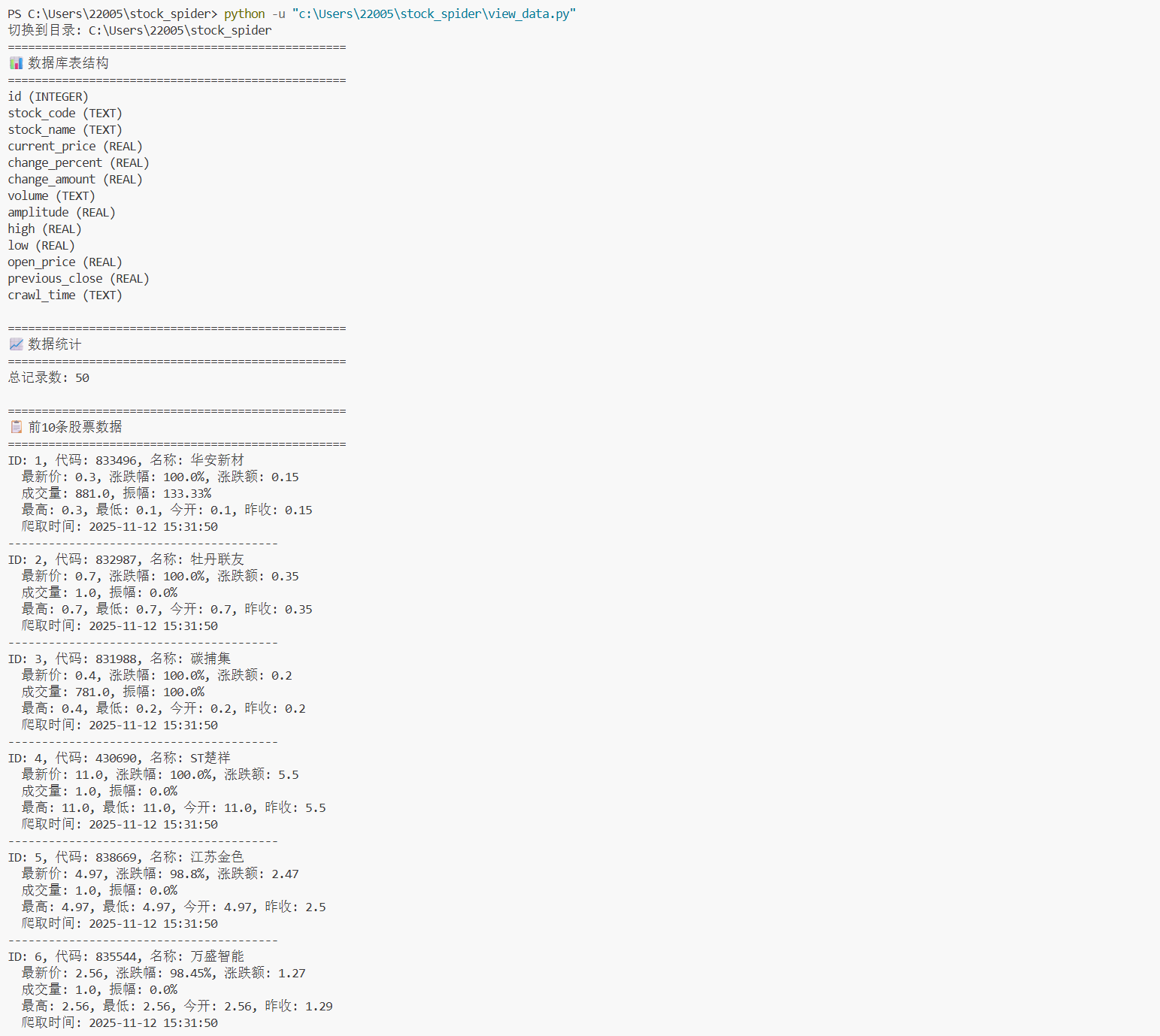

作业心得
通过本次Scrapy股票数据爬取实践,我深刻体会到框架化爬虫的高效与严谨。Item和Pipeline的配合不仅实现了数据的结构化存储,更展现了工程化的数据处理流程。面对反爬机制和数据库连接问题,学会了灵活调整策略,选择SQLite作为替代方案,体现了在实际开发中解决问题的重要性。这次经历让我认识到,掌握工具只是基础,根据实际情况灵活应变才是真正的能力提升。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业3
第三题
核心代码和运行结果
import scrapy
import re
from datetime import datetime
from forex_crawler.items import ForexItem
class BocForexSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
}
def parse(self, response):
self.logger.info("🚀 启动中国银行外汇数据爬虫...")
self.logger.info(f"目标网站: {response.url}")
self.logger.info("=" * 50)
# 保存页面内容用于调试
page_content = response.text
self.logger.info(f"✅ 成功访问页面,URL: {response.url}")
self.logger.info(f"📄 页面大小: {len(page_content)} 字符")
with open('debug_page.html', 'w', encoding='utf-8') as f:
f.write(page_content)
self.logger.info("📁 页面内容已保存到 debug_page.html")
# 查找所有表格
tables = response.xpath('//table')
self.logger.info(f"🔍 找到 {len(tables)} 个表格")
# 调试表格信息
for i, table in enumerate(tables):
table_class = table.xpath('./@class').get()
self.logger.info(f"📊 表格 {i+1} 的类: {table_class}")
# 选择包含外汇数据的表格(通常是第一个或第二个表格)
target_table = tables[1] if len(tables) > 1 else tables[0]
# 提取数据行(跳过表头)
rows = target_table.xpath('.//tr[position()>1]')
self.logger.info(f"✅ 使用选择器: //table/tr[position()>1]")
self.logger.info(f"📊 找到 {len(rows)} 行数据")
successful_count = 0
error_count = 0
for i, row in enumerate(rows, 1):
columns = row.xpath('./td//text()').getall()
columns = [col.strip() for col in columns if col.strip()]
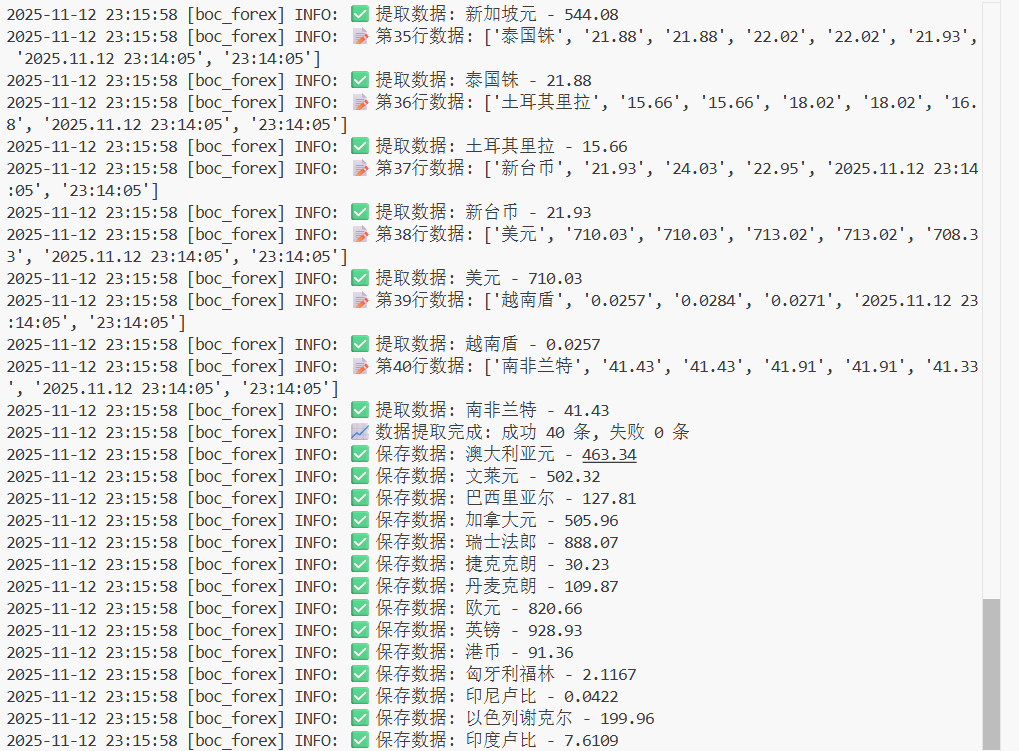
self.logger.info(f'📝 第{i}行数据: {columns}')
if len(columns) >= 2: # 至少需要货币名称和一个价格
currency_name = columns[0]
# 智能查找价格字段
selling_price = self.find_price(columns)
publish_time = self.find_publish_time(columns)
if selling_price is not None:
self.logger.info(f'✅ 提取数据: {currency_name} - {selling_price}')
item = ForexItem(
currency_name=currency_name,
selling_price=selling_price,
publish_time=publish_time or datetime.now().strftime('%Y.%m.%d %H:%M:%S')
)
successful_count += 1
yield item
else:
self.logger.warning(f'⚠️ 无法解析价格数据: {currency_name}')
error_count += 1
else:
self.logger.warning(f'⚠️ 数据列数不足: {len(columns)}列')
error_count += 1
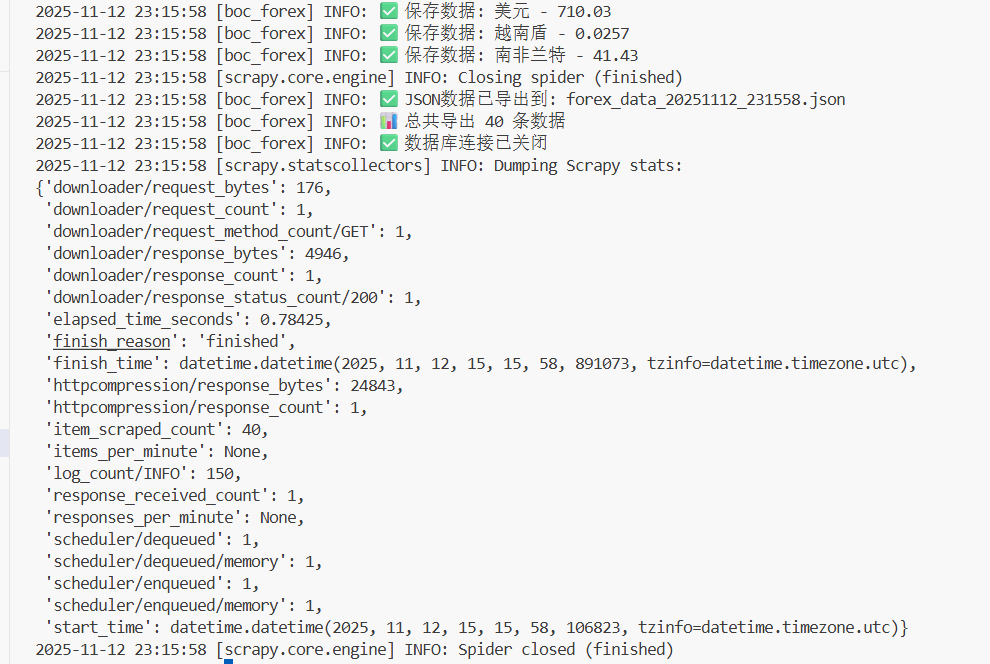
self.logger.info(f"📈 数据提取完成: 成功 {successful_count} 条, 失败 {error_count} 条")
def find_price(self, columns):
"""智能查找价格字段"""
# 尝试前几列,跳过货币名称
for i in range(1, min(6, len(columns))):
price_str = columns[i]
try:
# 尝试转换为浮点数
price = float(price_str)
# 验证价格合理性(排除明显错误的值)
if 0.0001 < price < 10000:
return price
except ValueError:
continue
return None
def find_publish_time(self, columns):
"""查找发布时间字段"""
for col in columns:
# 匹配时间格式: YYYY.MM.DD HH:MM:SS
if re.match(r'\d{4}\.\d{2}\.\d{2} \d{2}:\d{2}:\d{2}', col):
return col
# 匹配时间格式: HH:MM:SS
elif re.match(r'\d{2}:\d{2}:\d{2}', col):
return f"{datetime.now().strftime('%Y.%m.%d')} {col}"
return None
数据模型
import scrapy
class ForexItem(scrapy.Item):
currency_name = scrapy.Field()
selling_price = scrapy.Field()
publish_time = scrapy.Field()
crawl_time = scrapy.Field()
数据管道中的关键类
def process_item(self, item, spider):
"""处理每个数据项"""
try:
# 数据验证和清洗
if not self.validate_item(item):
spider.logger.warning(f"⚠️ 数据验证失败: {item.get('currency_name')}")
return item
# 添加爬取时间
item['crawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# 如果MySQL可用,保存到数据库
if self.use_mysql:
success = self.save_to_database(item, spider)
if success:
spider.logger.info(f"✅ 保存数据: {item['currency_name']} - {item['selling_price']}")
else:
spider.logger.warning(f"⚠️ 数据库保存失败: {item['currency_name']}")
else:
spider.logger.info(f"📊 处理数据: {item['currency_name']} - {item['selling_price']}")
return item
except Exception as e:
spider.logger.error(f"❌ 数据处理失败: {str(e)}")
return item
def save_to_database(self, item, spider):
"""保存数据到数据库"""
if not self.use_mysql:
return False
try:
# 转换发布时间格式
publish_time = self.parse_publish_time(item['publish_time'])
sql = """
INSERT INTO forex_rates
(currency_name, selling_price, publish_time, crawl_time)
VALUES (%s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
selling_price = VALUES(selling_price),
crawl_time = VALUES(crawl_time)
"""
values = (
item['currency_name'],
float(item['selling_price']),
publish_time,
item['crawl_time']
)
self.cursor.execute(sql, values)
self.connection.commit()
return True
except Exception as e:
self.connection.rollback()
spider.logger.error(f"❌ 数据库保存失败: {str(e)}")
return False
def parse_publish_time(self, time_str):
"""解析发布时间字符串"""
try:
# 处理格式: YYYY.MM.DD HH:MM:SS
if '.' in time_str and ':' in time_str:
time_str = time_str.replace('.', '-')
return datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
# 处理格式: HH:MM:SS
elif ':' in time_str:
today = datetime.now().strftime('%Y-%m-%d')
return datetime.strptime(f"{today} {time_str}", '%Y-%m-%d %H:%M:%S')
else:
return datetime.now()
except Exception:
return datetime.now()
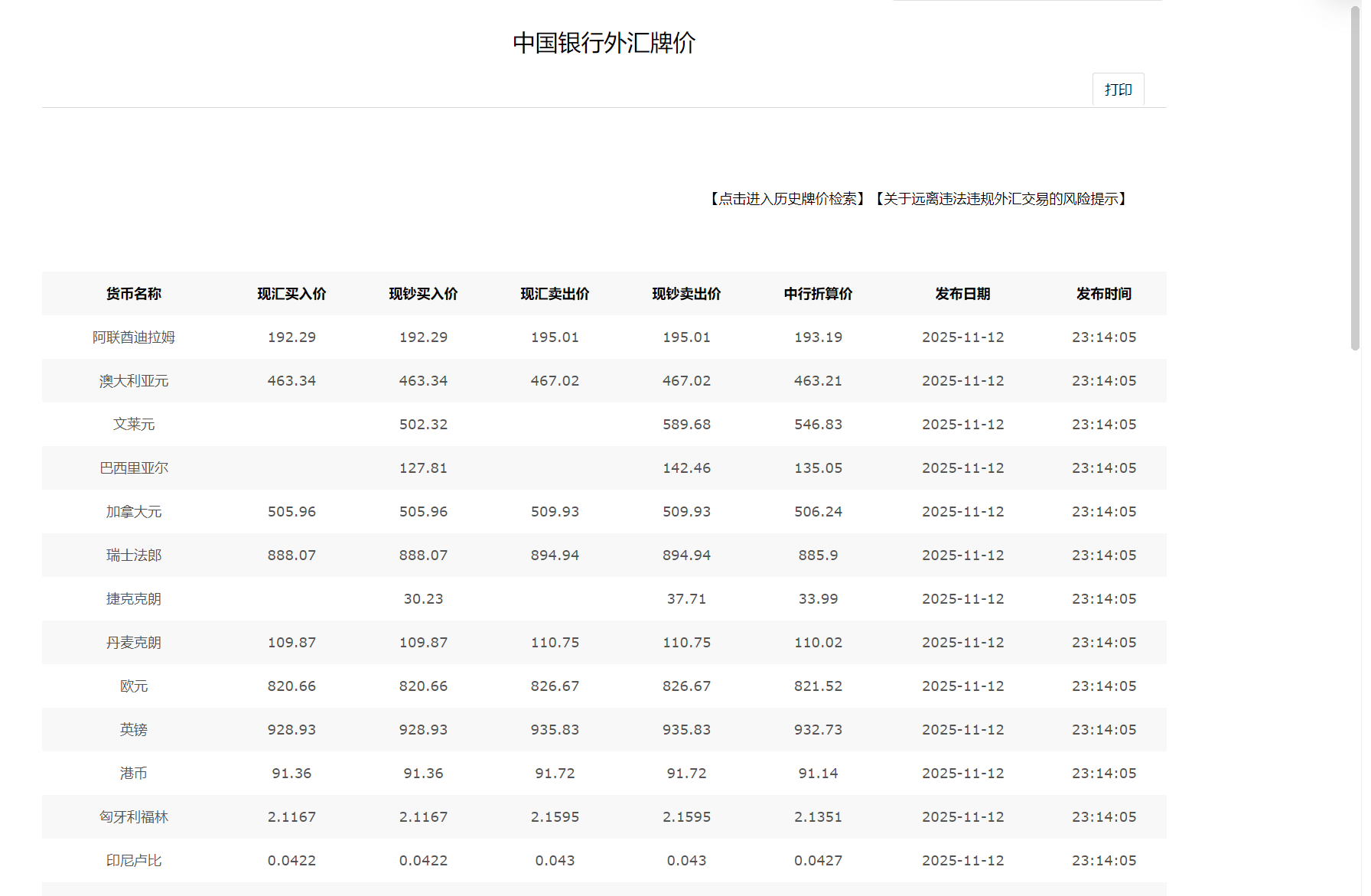
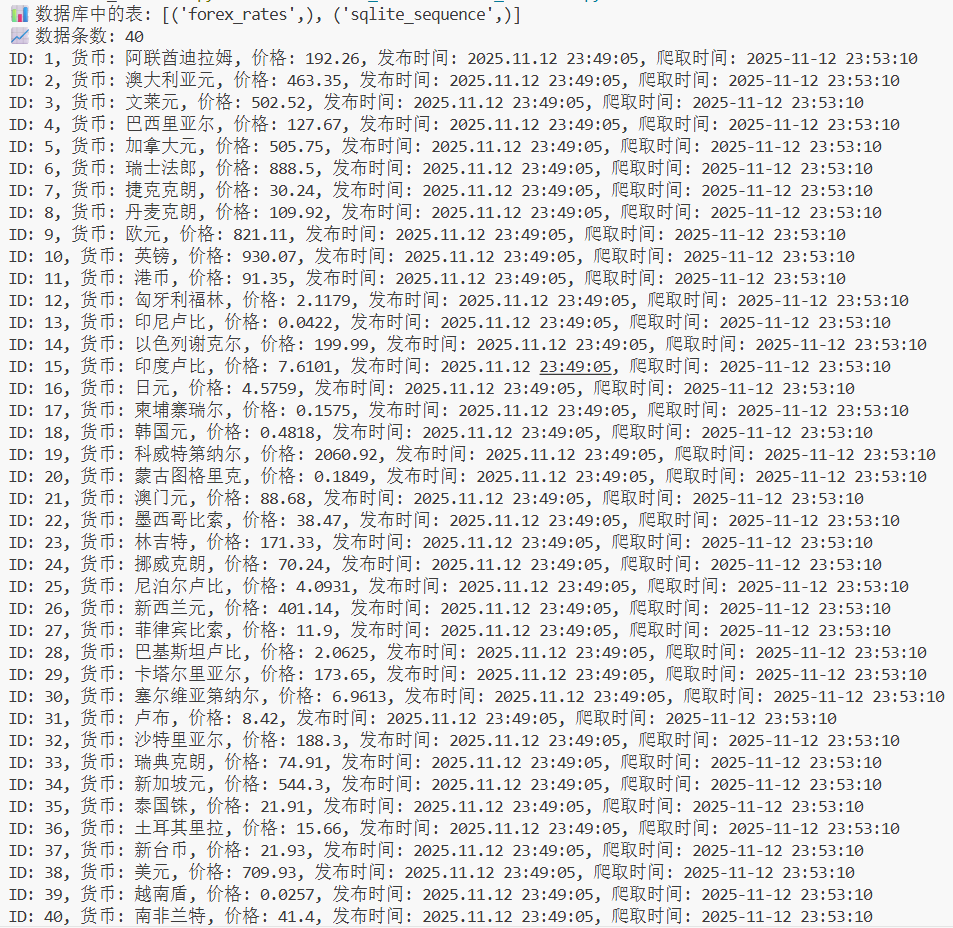
作业心得
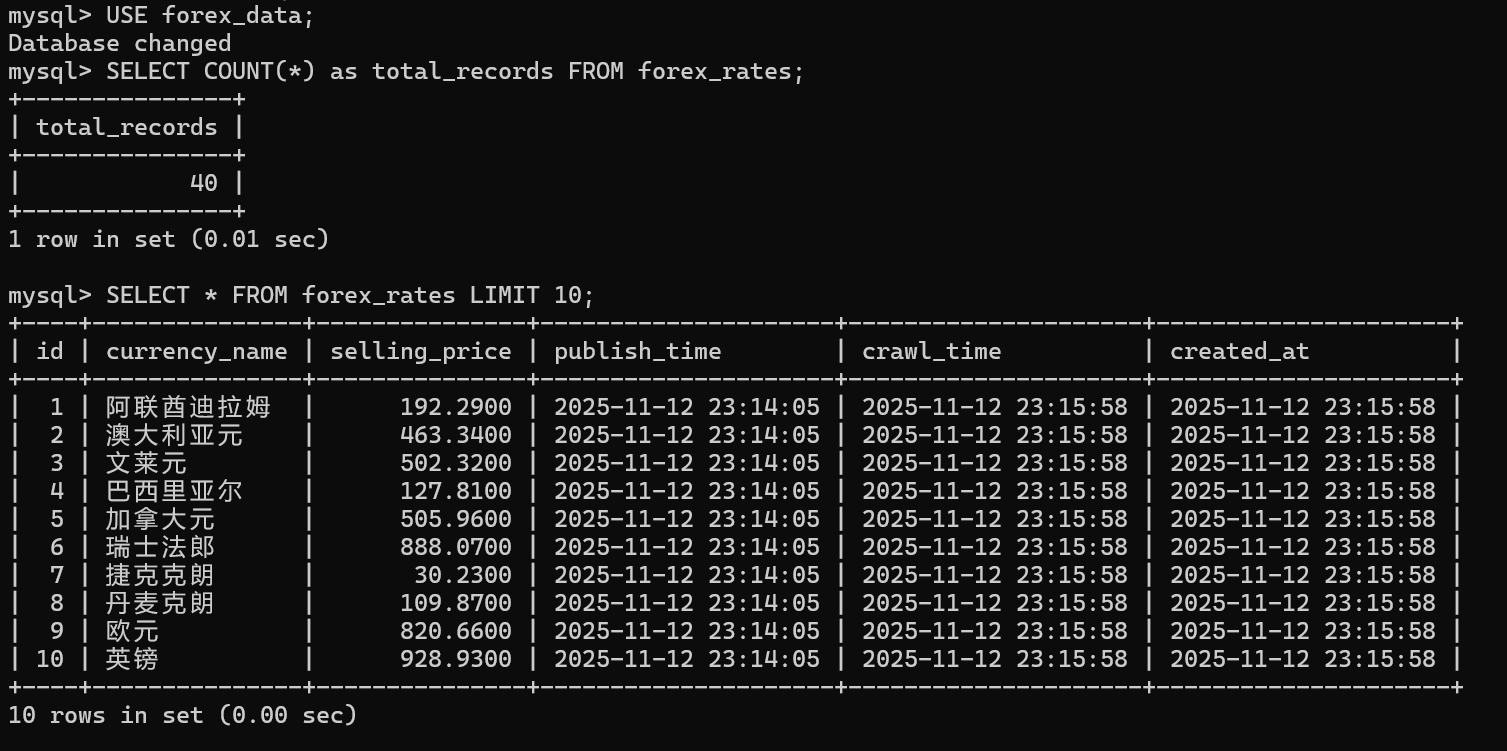
这次爬虫开发让我深刻体会到,数据处理就像一场精心设计的舞蹈——不仅要跟上网页结构的节奏变化,更要在错误出现时优雅转身。从数据库连接的磕磕绊绊到最终40种货币数据的完美落地,每个bug的解决都是对系统思维的一次锤炼。最珍贵的收获是:真正稳定的爬虫,其核心不在于能爬多快,而在于遇到各种意外情况时依然能从容应对。
https://gitee.com/chen-caiyi041130/chen-caiyi/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号