
qemu对虚拟机的内存管理(二)
上篇文章主要分析了qemu中对虚拟机内存管理的关键数据结构及他们之间的联系,这篇文章则主要分析在地址空间发生变化时,如何将其更新至KVM中,保持用户空间与内核空间的同步。
这一系列操作与之前说的AddressSpace注册绑定的listener相关,针对地址空间注册listener的操作在函数kvm_init()中:
kvm_memory_listener_register(s, &s->memory_listener, &address_space_memory, 0); memory_listener_register(&kvm_io_listener, &address_space_io);
在初始化过程中为 address_space_memory 和 address_space_io 分别注册了 memory_listener 和 kvm_io_listener 。前者类型为 KVMMemoryListener ,后者类型为 MemoryListener。 KVMMemoryListener 主体就是 MemoryListener ,而 MemoryListener 包含大量函数指针,用来指向 address_space 成员发生变化时调用的回调函数,从何保持内核和用户空间的内存信息的一致性。函数kvm_memory_listener_register()中对相关回调函数进行了注册:
void kvm_memory_listener_register(KVMState *s, KVMMemoryListener *kml, AddressSpace *as, int as_id) { int i; kml->slots = g_malloc0(s->nr_slots * sizeof(KVMSlot)); kml->as_id = as_id; for (i = 0; i < s->nr_slots; i++) { kml->slots[i].slot = i; } kml->listener.region_add = kvm_region_add; kml->listener.region_del = kvm_region_del; kml->listener.log_start = kvm_log_start; kml->listener.log_stop = kvm_log_stop; kml->listener.log_sync = kvm_log_sync; kml->listener.priority = 10; memory_listener_register(&kml->listener, as); }
实际上,任何对 AddressSpace 和 MemoryRegion 的操作,都以 memory_region_transaction_begin 开头,以 memory_region_transaction_commit 结尾. 如在父MR中添加子MR时,调用函数memory_region_add_subregion(),该函数进一步调用函数memory_region_add_subregion_common(),主要实现为函数memory_region_update_container_subregions():
static void memory_region_update_container_subregions(MemoryRegion *subregion) { MemoryRegion *mr = subregion->container; MemoryRegion *other; memory_region_transaction_begin(); memory_region_ref(subregion); QTAILQ_FOREACH(other, &mr->subregions, subregions_link) { if (subregion->priority >= other->priority) { QTAILQ_INSERT_BEFORE(other, subregion, subregions_link); goto done; } } QTAILQ_INSERT_TAIL(&mr->subregions, subregion, subregions_link); done: memory_region_update_pending |= mr->enabled && subregion->enabled; memory_region_transaction_commit(); }
该函数按照优先级顺序把subregion插入到system_memory的subregions链表中,添加区域后地址空间已经发生变化,然后通过memory_region_transaction_commit()实现将这一变化与KVM进行同步。
接下来对于这一变化的同步过程主要转载自:https://www.cnblogs.com/ck1020/p/6729224.html 及 https://www.cnblogs.com/ck1020/p/6738116.html
void memory_region_transaction_commit(void) { AddressSpace *as; assert(memory_region_transaction_depth); --memory_region_transaction_depth; if (!memory_region_transaction_depth) { if (memory_region_update_pending) { MEMORY_LISTENER_CALL_GLOBAL(begin, Forward); //从前向后调用全局列表 memory_listeners 中所有 listener 的 begin 函数 QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) { address_space_update_topology(as);//对 address_spaces 中的所有 address space,调用 address_space_update_topology ,更新 QEMU 和 KVM 中维护的 slot 信息 } MEMORY_LISTENER_CALL_GLOBAL(commit, Forward);//从后向前调用全局列表 memory_listeners 中所有 listener 的 commit 函数 } else if (ioeventfd_update_pending) { QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) { address_space_update_ioeventfds(as); } } memory_region_clear_pending(); } }
该函数对于每个address_space,调用address_space_update_topology()执行更新。里面涉及两个重要的函数generate_memory_topology和address_space_update_topology_pass。前者对于一个给定的MR,生成其对应的FlatView,而后者则根据oldview和newview对当前视图进行更新。函数address_space_update_topology如下:
static void address_space_update_topology(AddressSpace *as) { FlatView *old_view = address_space_get_flatview(as);//获取原来 FlatView(AddressSpace.current_map) FlatView *new_view = generate_memory_topology(as->root);//根据AddressSpace对应的MR生成新的FlatView //比较新老 FlatView,对其中不一致的 FlatRange,执行相应的操作 address_space_update_topology_pass(as, old_view, new_view, false); address_space_update_topology_pass(as, old_view, new_view, true); /* Writes are protected by the BQL. */ atomic_rcu_set(&as->current_map, new_view);//设置新的FlatView call_rcu(old_view, flatview_unref, rcu); /* Note that all the old MemoryRegions are still alive up to this * point. This relieves most MemoryListeners from the need to * ref/unref the MemoryRegions they get---unless they use them * outside the iothread mutex, in which case precise reference * counting is necessary. */ flatview_unref(old_view); address_space_update_ioeventfds(as); }
在获取了新旧两个FlatView之后,调用了两次address_space_update_topology_pass()函数,首次调用重在删除原来的,而后者重在添加。之后设置as->current_map为new_view。并对old_view减少引用,当引用计数为1时会被删除。接下来重点在两个地方:1、如何根据一个MR获取对应的FlatView;2、如何对旧的FlatView进行更新。
前者由generate_memory_topology函数实现:
/* Render a memory topology into a list of disjoint absolute ranges. */ static FlatView *generate_memory_topology(MemoryRegion *mr) { FlatView *view; view = g_new(FlatView, 1); flatview_init(view); if (mr) { render_memory_region(view, mr, int128_zero(), addrrange_make(int128_zero(), int128_2_64()), false);// 从根级 region 开始,递归将 region 映射到线性地址空间中,产生一个个 FlatRange,构成 FlatView. addrrange_make创建起始地址为 0,结束地址为 2^64 的地址空间,作为 guest 的线性地址空间 } flatview_simplify(view);//将 FlatView 中连续的 FlatRange 进行合并为一个 return view; }
首先申请一个FlatView结构,并对其进行初始化,然后调用render_memory_region函数实现核心功能,最后还调用flatview_simplify合并相邻的FlatRange.
static void render_memory_region(FlatView *view,MemoryRegion *mr,Int128 base,AddrRange clip,bool readonly)是一个递归函数,参数中,view表示当前FlatView,mr最初为system_memory即全局的MR,base起初为0表示从地址空间的其实开始,clip最初为一个完整的地址空间。readonly标识是否只读。
static void render_memory_region(FlatView *view, MemoryRegion *mr, Int128 base, AddrRange clip, bool readonly) { MemoryRegion *subregion; unsigned i; hwaddr offset_in_region; Int128 remain; Int128 now; FlatRange fr; AddrRange tmp; if (!mr->enabled) { return; } int128_addto(&base, int128_make64(mr->addr)); readonly |= mr->readonly; /*获得当前MR的地址区间范围*/ tmp = addrrange_make(base, mr->size); /*判断目标MR和clip是否有交叉,即MR应该落在clip的范围内*/ if (!addrrange_intersects(tmp, clip)) { return; } /*缩小clip到交叉的部分*/ clip = addrrange_intersection(tmp, clip); /*子区域才有alias字段*/ if (mr->alias) { int128_subfrom(&base, int128_make64(mr->alias->addr)); int128_subfrom(&base, int128_make64(mr->alias_offset)); /*这里base应该为subregion对应的alias中的区间基址*/ render_memory_region(view, mr->alias, base, clip, readonly); return; } /* Render subregions in priority order. */ QTAILQ_FOREACH(subregion, &mr->subregions, subregions_link) { render_memory_region(view, subregion, base, clip, readonly); } if (!mr->terminates) { return; } /*offset_in_region is distance between clip.start and base */ /*clip.start表示地址区间的起始,base为本次映射的基址,差值就为offset*/ offset_in_region = int128_get64(int128_sub(clip.start, base)); /***开始映射时,clip表示映射的区间范围,base作为一个移动指导每个FR的映射,remain表示clip总还没映射的大小*/ /*最初base=clip.start */ base = clip.start; remain = clip.size; fr.mr = mr; fr.dirty_log_mask = mr->dirty_log_mask; fr.romd_mode = mr->romd_mode; fr.readonly = readonly; /* Render the region itself into any gaps left by the current view. */ for (i = 0; i < view->nr && int128_nz(remain); ++i) { /*if base > addrrange_end(view->ranges[i].addr)即大于一个range的end*/ if (int128_ge(base, addrrange_end(view->ranges[i].addr))) { continue; } /*如果base < = view->ranges[i].addr.start*/ /*now 表示已经存在的FR 或者本次填充的FR的长度*/ if (int128_lt(base, view->ranges[i].addr.start)) { now = int128_min(remain, int128_sub(view->ranges[i].addr.start, base)); /*fr.offset_in_region表示映射的部分在所属MR中的偏移*/ fr.offset_in_region = offset_in_region; fr.addr = addrrange_make(base, now); flatview_insert(view, i, &fr); ++i; int128_addto(&base, now); offset_in_region += int128_get64(now); int128_subfrom(&remain, now); } /*if base > rang[i].start,means overlap exists,need escape*/ now = int128_sub(int128_min(int128_add(base, remain), addrrange_end(view->ranges[i].addr)), base); int128_addto(&base, now); offset_in_region += int128_get64(now); int128_subfrom(&remain, now); } /*如果还有剩下的clip没有映射,则下面不会在发生冲突,直接一次性的映射完成*/ if (int128_nz(remain)) { fr.offset_in_region = offset_in_region; fr.addr = addrrange_make(base, remain); flatview_insert(view, i, &fr); } }
在此必须清楚MR和clip的意义,即该函数实现的是把MR的区域填充clip空间。填充的方式就是生成一个个FlatRange,并交由FlatView管理。对于某一个MR而言,其基本管理逻辑理论上如图所示:
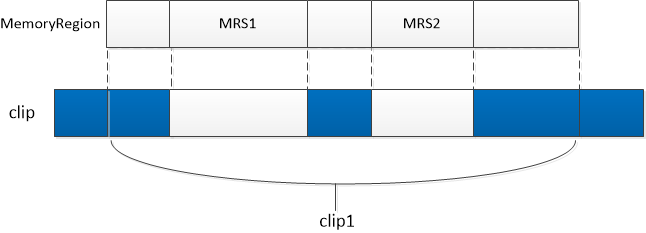
蓝色部分意味着已经存在的映射,对于某一个MR而言,可能存在如上图中的情况,由于重叠的关系,原本的region只需要把MRS1和MRS2映射进来即可,而这两部分也可以看成是原本region的一个分段,即MemoryRegionSection。(但是如果如图中所示,最终也会合并连续的flatRange,所以最后会是一个大的FlatRange)最终FlatView中的FlatRange按照在物理地址空间的布局,依次排列。
但是按照实际情况来讲,实际上传递进来的MR是整个地址空间system_space,所以像图中那样比较复杂的格局应该基本不会出现。不过咱们还是根据代码来看。首先获取了当前MR的区间范围,以base为起点。我们目的是要把MR的区间映射进clip中,所以如果两者没有交叉,那么无法完成映射。接着设置clip为二者地址区间重叠的部分,以图中所示,clip就成了clip1所标的范围。如果当前MR是某个subregion,则需要对其原始的MR进行展开,因为具体的信息都保存在原始的MR中。但是全局MR system_memory作为参数传递进来,那么这里mr->alias为NULL,所以到了下面对system_memory的每个subregion均进行展开。就这样再次进入render_memory_region函数的时候,MR为某个subregion,clip也为subregion对应的区域和原始clip的交集,由于其mr->alias指向原始MR,进入if判断,对原始MR的对应区间进行展开,再次调用render_memory_region。这一次就要进行真正的展开操作了,即生成对应的FlatRange。
顺着函数往下走,涉及几个变量这里先介绍下,offset_in_region表示需要映射的部分在其所属MR中的偏移,base为一个移动指针,指向当前映射的小区间,指导每个FR的映射。now当前已经映射的FR的长度,有两种可能,第一可能是当前映射的FR,第二可能是已经映射的FR。remain表示当前clip中剩下的未映射的部分(不考虑已经存在的FR),有了这些再看下面的代码就不吃力了。
核心的工作起始于一个for循环,循环的条件是 view->nr && int128_nz(remain),表示当前还有未遍历的FR并且remain还有剩余。循环中如果MR base的值大于或者等于当前FR的end,则继续往后遍历FR,否则进入下面,如果base小于当前FR的start,则表明base到start之间的区间还没有映射,则为其进行映射,now表示要映射的长度,取remain和int128_sub(view->ranges[i].addr.start, base)之间的最小值,后者表示下一个FR的start和base之间的差值,当然按照clip为准。接下来就没难度了,设置FR的offset_in_region和addr,然后调用flatview_insert插入到FlatView的FlatRange数组中。不过由于FR按照地址顺序排列,如果插入位置靠前,则需要移动较多的项,不知道为何不用链表实现。下面就很自然了移动base,增加offset_in_region,减少remain等操作。出了if,此时base已经和FR的start对齐,所以还需要略过当前FR(在映射MRS1时,当前FR为MRS1后面已经映射的FR,而完成MRS1的映射之后,将当前映射的FR插入了view中,且i++,故退出if后view->range[i]还是MRS1后面的FR,由于该FR已经映射,故需要略过)。之后就这么一直映射下去。
出了for循环,如果remain不为0,则表明还有没有映射的,但是现在已经没有已经存在的FR了,所以不会发生冲突,直接把remain直接映射成一个FR即可。
按照这个思路,把所有的subregion都映射下去,最终把FlatView返回。这样generate_memory_topology就算是介绍完了,下面的flatview_simplify是对数组表项的尝试合并,这里就不再介绍。到此为止,已经针对当前MR生成了一个新的FlatView,接下来需要用address_space_update_topology_pass函数对old_view和new_view做对比。连续调用了两次这个函数,不过最后的adding参数先后为false和true。进入函数分析下
static void address_space_update_topology_pass(AddressSpace *as, const FlatView *old_view, const FlatView *new_view, bool adding) { /*FR计数*/ unsigned iold, inew; FlatRange *frold, *frnew; /* Generate a symmetric difference of the old and new memory maps. * Kill ranges in the old map, and instantiate ranges in the new map. */ iold = inew = 0; while (iold < old_view->nr || inew < new_view->nr) { if (iold < old_view->nr) { frold = &old_view->ranges[iold]; } else { frold = NULL; } if (inew < new_view->nr) { frnew = &new_view->ranges[inew]; } else { frnew = NULL; } /*int128_lt 小于等于*/ /*int128_eq 等于*/ /*frold not null and( frnew is null || frold not null and old.start <= new.start || frold not null and old.start == new.start) and old !=new*/ if (frold && (!frnew || int128_lt(frold->addr.start, frnew->addr.start) || (int128_eq(frold->addr.start, frnew->addr.start) && !flatrange_equal(frold, frnew)))) { /* In old but not in new, or in both but attributes changed. */ /*if not add*/ if (!adding) { MEMORY_LISTENER_UPDATE_REGION(frold, as, Reverse, region_del); } ++iold; /*if old and new and old==new*/ } else if (frold && frnew && flatrange_equal(frold, frnew)) { /* In both and unchanged (except logging may have changed) */ /*if add*/ if (adding) { MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_nop); if (frold->dirty_log_mask && !frnew->dirty_log_mask) { MEMORY_LISTENER_UPDATE_REGION(frnew, as, Reverse, log_stop); } else if (frnew->dirty_log_mask && !frold->dirty_log_mask) { MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, log_start); } } ++iold; ++inew; } else { /* In new */ /*if add*/ if (adding) { MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add); } ++inew; } } }
该函数主体是一个while循环,循环条件是old_view->nr和new_view->nr,表示新旧view的可用FlatRange数目。这里依次对FR数组的对应FR 做对比,主要有下面几种情况:frold和frnew均存在、frold存在但frnew不存在,frold不存在但frnew存在。下面的if划分和上面的略有不同:
1、如果frold不为空&&(frnew为空||frold.start<frnew.start||frold.start=frnew.start)&&frold!=frnew 这种情况是新旧view的地址范围不一样,则需要调用lienter的region_del对frold进行删除。
2、如果frold和frnew均不为空且frold.start=frnew.start 这种情况需要判断日志掩码,如果frold->dirty_log_mask && !frnew->dirty_log_mask,调用log_stop回调函数;如果frnew->dirty_log_mask && !frold->dirty_log_mask,调用log_start回调函数。
3、frold为空但是frnew不为空 这种情况直接调用region_add回调函数添加region。
函数主体逻辑基本如上所述,那我们注意到,当adding为false时,执行的只有第一个情况下的处理,就是删除frold的操作,其余的处理只有在adding 为true的时候才得以执行。这意图就比较明确,首次执行先删除多余的,下次直接添加或者对日志做更新操作了。
上述对于要添加的FR,调用了 MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add)
#define MEMORY_LISTENER_UPDATE_REGION(fr, as, dir, callback, _args...) \ do { \ MemoryRegionSection mrs = section_from_flat_range(fr, as); \ MEMORY_LISTENER_CALL(as, callback, dir, &mrs, ##_args); \ } while(0) section_from_flat_range(FlatRange *fr, AddressSpace *as) {//根据flatrange生成MRS return (MemoryRegionSection) { .mr = fr->mr, .address_space = as, .offset_within_region = fr->offset_in_region, .size = fr->addr.size, .offset_within_address_space = int128_get64(fr->addr.start), .readonly = fr->readonly, }; } #define MEMORY_LISTENER_CALL(_as, _callback, _direction, _section, _args...) \ do { \ MemoryListener *_listener; \ struct memory_listeners_as *list = &(_as)->listeners; \ \ switch (_direction) { \ case Forward: \ QTAILQ_FOREACH(_listener, list, link_as) { \ if (_listener->_callback) { \ _listener->_callback(_listener, _section, ##_args); \ } \ } \ break; \ case Reverse: \ QTAILQ_FOREACH_REVERSE(_listener, list, memory_listeners_as, \ link_as) { \ if (_listener->_callback) { \ _listener->_callback(_listener, _section, ##_args); \ } \ } \ break; \ default: \ abort(); \ } \ } while (0)
宏MEMORY_LISTENER_UPDATE_REGION中首先根据需要添加的FR生成MRS,然后调用宏MEMORY_LISTENER_CALL,这里有个_direction,其实就是遍历方向,因为listener按照优先级从低到高排列,所以这里其实就是确定让谁先处理。Forward就是从前向后,而reverse就是从后向前。然后根据传入的_callback参数调用相应的回调函数。如参入region_add,则调用kvm_region_add(),该函数把region信息告知KVM,KVM以此对内存信息做记录,函数核心在static void kvm_set_phys_mem(MemoryRegionSection *section, bool add)函数,上一篇中由GPA及HVA的计算有对该函数的内容进行分析,以下分段介绍:
KVMState *s = kvm_state; KVMSlot *mem, old; int err; MemoryRegion *mr = section->mr; bool log_dirty = memory_region_is_logging(mr); /*是否可写*/ bool writeable = !mr->readonly && !mr->rom_device; bool readonly_flag = mr->readonly || memory_region_is_romd(mr); //section中数据的起始偏移 hwaddr start_addr = section->offset_within_address_space; /*section的size*/ ram_addr_t size = int128_get64(section->size); void *ram = NULL; unsigned delta; /* kvm works in page size chunks, but the function may be called with sub-page size and unaligned start address. */ /*内存对齐后的偏移*/ delta = TARGET_PAGE_ALIGN(size) - size; if (delta > size) { return; } start_addr += delta; size -= delta;//这样可以保证size是页对齐的 size &= TARGET_PAGE_MASK; if (!size || (start_addr & ~TARGET_PAGE_MASK)) { return; } /*如果不是rom,则不能进行写操作*/ if (!memory_region_is_ram(mr)) { if (writeable || !kvm_readonly_mem_allowed) { return; } else if (!mr->romd_mode) { /* If the memory device is not in romd_mode, then we actually want * to remove the kvm memory slot so all accesses will trap. */ add = false; } }
第一部分主要是一些基础工作,获取section对应的MR的一些属性,如writeable、readonly_flag。获取section的start_addr和size,其中start_addr就是section中的offset_within_address_space也就是FR中addr的start,接下来对size进行了对齐操作 。如果对应的MR关联的内存并不是作为ram存在,就要进行额外的验证。这种情况如果writeable允许写操作或者kvm不支持只读内存,那么直接返回。
接下来是函数的重点处理部分,即把当前的section转化成一个slot进行添加,但是在此之前需要处理已存在的slot和新的slot的重叠问题,当然如果没有重叠就好办了,直接添加即可。进入while循环
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + delta; /*对重叠部分的处理*/ while (1) { /*查找重叠的部分*/ mem = kvm_lookup_overlapping_slot(s, start_addr, start_addr + size); /*如果没找到重叠,就break*/ if (!mem) { break; } /*如果要添加区间已经被注册*/ if (add && start_addr >= mem->start_addr && (start_addr + size <= mem->start_addr + mem->memory_size) && (ram - start_addr == mem->ram - mem->start_addr)) { /* The new slot fits into the existing one and comes with * identical parameters - update flags and done. */ kvm_slot_dirty_pages_log_change(mem, log_dirty); return; } old = *mem; if (mem->flags & KVM_MEM_LOG_DIRTY_PAGES) { kvm_physical_sync_dirty_bitmap(section); } /*移除重叠的部分*/ /* unregister the overlapping slot */ mem->memory_size = 0; err = kvm_set_user_memory_region(s, mem); if (err) { fprintf(stderr, "%s: error unregistering overlapping slot: %s\n", __func__, strerror(-err)); abort(); } /* Workaround for older KVM versions: we can't join slots, even not by * unregistering the previous ones and then registering the larger * slot. We have to maintain the existing fragmentation. Sigh. * * This workaround assumes that the new slot starts at the same * address as the first existing one. If not or if some overlapping * slot comes around later, we will fail (not seen in practice so far) * - and actually require a recent KVM version. */ /*如果已有的size小于申请的size,则需要在原来的基础上,添加新的,不能删除原来的再次添加*/ if (s->broken_set_mem_region && old.start_addr == start_addr && old.memory_size < size && add) { mem = kvm_alloc_slot(s); mem->memory_size = old.memory_size; mem->start_addr = old.start_addr; mem->ram = old.ram; mem->flags = kvm_mem_flags(s, log_dirty, readonly_flag); err = kvm_set_user_memory_region(s, mem); if (err) { fprintf(stderr, "%s: error updating slot: %s\n", __func__, strerror(-err)); abort(); } start_addr += old.memory_size; ram += old.memory_size; size -= old.memory_size; continue; } /* register prefix slot */ /*new 的start_addr大于old.start_addr,需要补足前面多余的部分*/ if (old.start_addr < start_addr) { mem = kvm_alloc_slot(s); mem->memory_size = start_addr - old.start_addr; mem->start_addr = old.start_addr; mem->ram = old.ram; mem->flags = kvm_mem_flags(s, log_dirty, readonly_flag); err = kvm_set_user_memory_region(s, mem); if (err) { fprintf(stderr, "%s: error registering prefix slot: %s\n", __func__, strerror(-err)); #ifdef TARGET_PPC fprintf(stderr, "%s: This is probably because your kernel's " \ "PAGE_SIZE is too big. Please try to use 4k " \ "PAGE_SIZE!\n", __func__); #endif abort(); } } /* register suffix slot */ /**/ if (old.start_addr + old.memory_size > start_addr + size) { ram_addr_t size_delta; mem = kvm_alloc_slot(s); mem->start_addr = start_addr + size; size_delta = mem->start_addr - old.start_addr; mem->memory_size = old.memory_size - size_delta; mem->ram = old.ram + size_delta; mem->flags = kvm_mem_flags(s, log_dirty, readonly_flag); err = kvm_set_user_memory_region(s, mem); if (err) { fprintf(stderr, "%s: error registering suffix slot: %s\n", __func__, strerror(-err)); abort(); } } }
首先调用了kvm_lookup_overlapping_slot函数找到一个冲突的slot,注意返回结果是按照slot为单位,只要两个地址范围有交叉,就意味着存在冲突,就返回冲突的slot。如果没有,那么直接break,添加新的。否则就根据以下几种情况进行分别处理。其实主要有两种大情况:
1、新的slot完全包含于引起冲突的slot中,并且参数都是一致的。
2、新的slot和引起冲突的slot仅仅是部分交叉。
针对第一种情况,如果flag有变动,则只更新slot的flags,否则,不需要变动。第二种情况,首先要把原来的region delete掉,具体方式是设置mem->memory_size=0,然后调用kvm_set_user_memory_region()函数。由于 新的region和delete的region不是完全对应的,仅仅是部分交叉,所以就会连带 删除多余的映射,那么接下来的工作就 是分批次弥补映射。如图所示
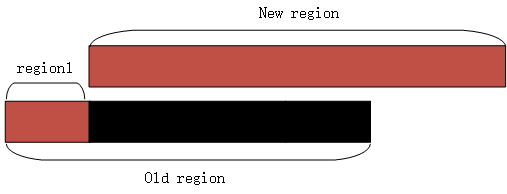
如图所示,old region是找到的和new region重叠的slot,首次删除把整个slot都删除了,造成了region1部门很无辜的受伤,所以在映射时,要把region1在弥补上。而黑色部分就是实际删除的,这样接下来就可以直接映射new region了,如果多余的部分在后方,也是同样的道理。在把无辜被删除region映射之后,接下来就调用kvm_set_user_memory_region把new slot映射进去。基本思路就是这样。下面看下核心函数kvm_set_user_memory_region
struct kvm_userspace_memory_region { __u32 slot; // 对应 kvm_memory_slot 的 id __u32 flags; __u64 guest_phys_addr; // GPA __u64 memory_size; /* bytes */ // 大小 __u64 userspace_addr; /* start of the userspace allocated memory */ // HVA };
static int kvm_set_user_memory_region(KVMState *s, KVMSlot *slot) { struct kvm_userspace_memory_region mem; mem.slot = slot->slot; mem.guest_phys_addr = slot->start_addr; mem.userspace_addr = (unsigned long)slot->ram; mem.flags = slot->flags; if (s->migration_log) { mem.flags |= KVM_MEM_LOG_DIRTY_PAGES; } if (slot->memory_size && mem.flags & KVM_MEM_READONLY) { /* Set the slot size to 0 before setting the slot to the desired * value. This is needed based on KVM commit 75d61fbc. */ mem.memory_size = 0; kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem); } mem.memory_size = slot->memory_size; return kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem); }
该函数使用了一个kvm_userspace_memory_region对应,该结构本质上作为参数传递给KVM,只是由于不能共享堆栈,在KVM中需要把该结构复制到内核空间,代码本身没什么难度,只是这里如果是只读的mem,需要调用两次kvm_vm_ioctl,第一次设置mem的size为0.
KVM接收端在kvm_vm_ioctl()函数中
…… case KVM_SET_USER_MEMORY_REGION: { struct kvm_userspace_memory_region kvm_userspace_mem; r = -EFAULT; if (copy_from_user(&kvm_userspace_mem, argp, sizeof (kvm_userspace_mem))) goto out; kvm_userspace_mem->flags |= 0x1; r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem); break; } ……
可以看到首要任务就是把参数复制到内核,然后调用了kvm_vm_ioctl_set_memory_region()函数。
int kvm_vm_ioctl_set_memory_region(struct kvm *kvm, struct kvm_userspace_memory_region *mem) { if (mem->slot >= KVM_USER_MEM_SLOTS) return -EINVAL; return kvm_set_memory_region(kvm, mem); }
函数检查下slot编号如果超额,那没办法,无法添加,否则调用kvm_set_memory_region()函数。而该函数没做别的,直接调用了__kvm_set_memory_region。该函数比较长,咱们还是分段介绍。开始就是一些常规检查。
if (mem->memory_size & (PAGE_SIZE - 1)) goto out; if (mem->guest_phys_addr & (PAGE_SIZE - 1)) goto out; /* We can read the guest memory with __xxx_user() later on. */ if ((mem->slot < KVM_USER_MEM_SLOTS) && ((mem->userspace_addr & (PAGE_SIZE - 1)) || !access_ok(VERIFY_WRITE, (void *)(unsigned long)mem->userspace_addr, mem->memory_size))) goto out; if (mem->slot >= KVM_MEM_SLOTS_NUM) goto out; if (mem->guest_phys_addr + mem->memory_size < mem->guest_phys_addr) goto out;
如果memory_size 不是页对齐的,则失败;如果mem的客户机物理地址不是页对齐的,也失败;如果slot的id在合法范围内但是用户空间地址不是页对齐的或者地址范围内的不能正常访问,则失败;如果slot id大于等于KVM_MEM_SLOTS_NUM,则失败。
/*定位到指定slot*/ slot = id_to_memslot(kvm->memslots, mem->slot); base_gfn = mem->guest_phys_addr >> PAGE_SHIFT; npages = mem->memory_size >> PAGE_SHIFT; r = -EINVAL; if (npages > KVM_MEM_MAX_NR_PAGES) goto out; /*如果npages为0,则设置*/ if (!npages) mem->flags &= ~KVM_MEM_LOG_DIRTY_PAGES; /*new 为用户空间传递过来的mem,old为和用户空间mem id一致的mem*/ new = old = *slot; new.id = mem->slot; new.base_gfn = base_gfn; new.npages = npages; new.flags = mem->flags; r = -EINVAL; /*如果new 的 npage不为0*/ if (npages) { /*如果old 的npage为0,则创建新的mem*/ if (!old.npages) change = KVM_MR_CREATE; /*否则修改已有的mem*/ else { /* Modify an existing slot. */ if ((mem->userspace_addr != old.userspace_addr) || (npages != old.npages) || ((new.flags ^ old.flags) & KVM_MEM_READONLY)) goto out; /*如果两个mem映射的基址不同*/ if (base_gfn != old.base_gfn) change = KVM_MR_MOVE; /*如果标志位不同则更新标志位*/ else if (new.flags != old.flags) change = KVM_MR_FLAGS_ONLY; else { /* Nothing to change. */ /*都一样的话就什么都不做*/ r = 0; goto out; } } } /*如果new的npage为0而old的npage不为0,则需要delete已有的*/ else if (old.npages) { change = KVM_MR_DELETE; } else /* Modify a non-existent slot: disallowed. */ goto out;
这里如果检查都通过了,首先通过传递进来的slot的id在kvm维护的slot数组中找到对应的slot结构,此结构可能为空或者为旧的slot。然后获取物理页框号、页面数目。如果页面数目大于KVM_MEM_MAX_NR_PAGES,则失败;如果npages为0,则去除KVM_MEM_LOG_DIRTY_PAGES标志。使用旧的slot对新的slot内容做初始化,然后对new slot做设置,参数基本是从用户空间接收的kvm_userspace_memory_region的参数。然后进入下面的if判断
1、如果npages不为0,表明本次要添加slot此时如果old slot的npages为0,表明之前没有对应的slot,需要添加新的,设置change为KVM_MR_CREATE;如果不为0,则需要先修改已有的slot,注意这里如果old slot和new slot的page数目和用户空间地址必须相等,还有就是两个slot的readonly属性必须一致。如果满足上述条件,进入下面的流程。如果映射的物理页框号不同,则设置change KVM_MR_MOVE,如果flags不同,设置KVM_MR_FLAGS_ONLY,否则,什么都不做。
2、如果npages为0,而old.pages不为0,表明需要删除old slot,设置change为KVM_MR_DELETE。到这里基本是做一些准备工作,确定用户空间要进行的操作,接下来就执行具体的动作了
if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) { /* Check for overlaps */ r = -EEXIST; kvm_for_each_memslot(slot, kvm->memslots) { if ((slot->id >= KVM_USER_MEM_SLOTS) || (slot->id == mem->slot)) continue; if (!((base_gfn + npages <= slot->base_gfn) || (base_gfn >= slot->base_gfn + slot->npages))) goto out; } } /* Free page dirty bitmap if unneeded */ if (!(new.flags & KVM_MEM_LOG_DIRTY_PAGES)) new.dirty_bitmap = NULL; r = -ENOMEM; if (change == KVM_MR_CREATE) { new.userspace_addr = mem->userspace_addr; if (kvm_arch_create_memslot(&new, npages)) goto out_free; } /* Allocate page dirty bitmap if needed */ if ((new.flags & KVM_MEM_LOG_DIRTY_PAGES) && !new.dirty_bitmap) { if (kvm_create_dirty_bitmap(&new) < 0) goto out_free; } /*如果用户层请求释放*/ if ((change == KVM_MR_DELETE) || (change == KVM_MR_MOVE)) { r = -ENOMEM; slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots), GFP_KERNEL); if (!slots) goto out_free; /*先根据id定位具体的slot*/ slot = id_to_memslot(slots, mem->slot); /*首先设置非法*/ slot->flags |= KVM_MEMSLOT_INVALID; old_memslots = install_new_memslots(kvm, slots, NULL); /* slot was deleted or moved, clear iommu mapping */ kvm_iommu_unmap_pages(kvm, &old); /* From this point no new shadow pages pointing to a deleted, * or moved, memslot will be created. * * validation of sp->gfn happens in: * - gfn_to_hva (kvm_read_guest, gfn_to_pfn) * - kvm_is_visible_gfn (mmu_check_roots) */ kvm_arch_flush_shadow_memslot(kvm, slot); slots = old_memslots; } r = kvm_arch_prepare_memory_region(kvm, &new, mem, change); if (r) goto out_slots; r = -ENOMEM; /* * We can re-use the old_memslots from above, the only difference * from the currently installed memslots is the invalid flag. This * will get overwritten by update_memslots anyway. */ if (!slots) { slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots), GFP_KERNEL); if (!slots) goto out_free; } /* * IOMMU mapping: New slots need to be mapped. Old slots need to be * un-mapped and re-mapped if their base changes. Since base change * unmapping is handled above with slot deletion, mapping alone is * needed here. Anything else the iommu might care about for existing * slots (size changes, userspace addr changes and read-only flag * changes) is disallowed above, so any other attribute changes getting * here can be skipped. */ if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) { r = kvm_iommu_map_pages(kvm, &new); if (r) goto out_slots; } /* actual memory is freed via old in kvm_free_physmem_slot below */ if (change == KVM_MR_DELETE) { new.dirty_bitmap = NULL; memset(&new.arch, 0, sizeof(new.arch)); } old_memslots = install_new_memslots(kvm, slots, &new); kvm_arch_commit_memory_region(kvm, mem, &old, change); kvm_free_physmem_slot(&old, &new); kfree(old_memslots); return 0;
这里就根据change来做具体的设置了,如果 KVM_MR_CREATE,则设置new.用户空间地址为新的地址。如果new slot要求KVM_MEM_LOG_DIRTY_PAGES,但是new并没有分配dirty_bitmap,则为其分配。如果change为KVM_MR_DELETE或者KVM_MR_MOVE,这里主要由两个操作,一是设置对应slot标识为KVM_MEMSLOT_INVALID,更新页表。二是增加slots->generation,撤销iommu mapping。接下来对于私有映射的话(memslot->id >= KVM_USER_MEM_SLOTS),如果是要创建,则需要手动建立映射。
接下来确保slots不为空,如果是KVM_MR_CREATE或者KVM_MR_MOVE,就需要重新建立映射,使用kvm_iommu_map_pages函数 ,而如果是KVM_MR_DELETE,就没必要为new设置dirty_bitmap,并对其arch字段的结构清零。最终都要执行操作install_new_memslots,不过当为delete操作时,new的memory size为0,那么看下该函数做了什么。
static struct kvm_memslots *install_new_memslots(struct kvm *kvm, struct kvm_memslots *slots, struct kvm_memory_slot *new) { struct kvm_memslots *old_memslots = kvm->memslots; update_memslots(slots, new, kvm->memslots->generation); rcu_assign_pointer(kvm->memslots, slots); kvm_synchronize_srcu_expedited(&kvm->srcu); kvm_arch_memslots_updated(kvm); return old_memslots; }
这里核心操作在update_memslots里,如果是添加新的(create or move),那么new 的memory size肯定不为0,则根据new的id,在kvm维护的slot 数组中找到对应的slot,然后一次性吧new的内容赋值给old slot.如果页面数目不一样,则需要进行排序。如果是删除操作,new的memorysize 为0,这里就相当于把清空了一个slot。update之后就更改kvm->memslots,该指针是受RCU机制保护的,所以不能直接修改,需要先分配好,调用API修改。最后再刷新MMIO页表项。
void update_memslots(struct kvm_memslots *slots, struct kvm_memory_slot *new, u64 last_generation) { if (new) { int id = new->id; struct kvm_memory_slot *old = id_to_memslot(slots, id); unsigned long npages = old->npages; *old = *new; /*如果是删除操作,那么new.npages就是0*/ if (new->npages != npages) sort_memslots(slots); } slots->generation = last_generation + 1; }
可见qemu中创建了一系列 MemoryRegion ,分别表示 Guest 中的 ROM、RAM 等区域。 MemoryRegion 之间通过 alias 或 subregion 的方式维护相互之间的关系,从而进一步细化区域的定义。
对于一个实体 MemoryRegion(非 alias),在初始化内存的过程中会创建它所对应的 RAMBlock 。 RAMBlock 通过 mmap 的方式从 QEMU 的进程空间中分配内存,并负责维护该 MemoryRegion 管理内存的起始 HVA/GPA/size 等信息。
AddressSpace 表示 VM 的物理地址空间。如果 AddressSpace 中的 MemoryRegion 发生变化,则 listener 被触发,将所属 AddressSpace 的 MemoryRegion 树展平,形成一维的 FlatView ,比较 FlatRange 是否发生了变化。如果是调用相应方法如 region_add 对变化的 section region 进行检查,更新 QEMU 内的 KVMSlot,同时填充 kvm_userspace_memory_region 结构,作为 ioctl 的参数更新 KVM 中的 kvm_memory_slot ,维护两者信息的一致性。
该文章主体内容转自:https://www.cnblogs.com/ck1020/p/6729224.html https://www.cnblogs.com/ck1020/p/6738116.html 对部分地方进行了一些修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号