网络爬虫爬取新闻报道高频词汇
选题背景:
社会:新闻可以让我们第一时间了解到一些新发行的法律法规;可以让我们多了解社会上的风气与文化;可以让我们多知道一些名人事迹以及政治经济发展状况。新闻事实是客观的,它能满足传播主体和接受主体新闻需求的性能,也是一种不以主观意志为转移的客观存在。
经济:新闻可以让我们预见未来的一些趋势,根据关键词可以了解到未来生活发展中,兴起的产业或技术。古人云,知己知彼百战百胜。机遇是留给有准备的人的,要想把握机遇,信息的获取就是必要的。
预期目标:获取指定时间内的新闻时间,爬取新闻中的所有词汇,并按照词语的出现次数排序,并统计出现次数。
数据来源:中国新闻网
设计方法:
内容与数据特征分析:要获取的是该网站首页链接内新闻中的词汇,这些词汇都是text形式,且长度一般不超过十个字符。
方案概述:要获取的是该网站首页链接内新闻中的词汇,所以要用正则表达式匹配出我们想要获取的网址链接的共同点,该网站设置了字母和数字混编的随机码,在这个步骤卡了一小点时间。然后爬取新闻正文中的全部词汇,
主题页面的结构特征分析:
该网站采用‘utf-8’编码格式,首页由table中包含a标签加上跳转链接与图片组成。
网络爬虫程序设计:
获取网页:
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 url = 'http://www.chinadaily.com.cn/' 5 def getUrlData(url): 6 try: 7 r = requests.get(url,timeout=30) 8 r.raise_for_status 9 r.encoding=r.apparent_encoding 10 html = r.text 11 return html 12 except: 13 return '发生异常' 14 #获取网页数据 15 wbdata = requests.get(url).text 16 #使用html解析器 17 soup=BeautifulSoup(wbdata,"html.parser") 18 print (soup)

取出两个网址,使用正则表达式完善规则,使代码能自动提取出符合规则的网址,即我们需要的网页:
#取出两个网址 linklist = ['www.chinadaily.com.cn/a/202106/14/WS60c68a81a31024ad0bac68e2.html','www.chinadaily.com.cn/a/202106/14/WS60c6916da31024ad0bac68f4.html','javascript:void(0)'] #用逗号将网址隔开 s = ",".join(linklist) print(s) #用正则表达式和网址共同部分匹配王者 #[a-z0-9A-Z]*为正则表达式匹配0个或多个数字和字母组合的字符串 links = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', s) #输出结果,查看网址匹配效果 print(links)

使用正则表达式,对获取爬取到的网页中的所有网址进行循环匹配:
linklist = [] for k in soup.find_all('a'): link = k.get('href') linklist.append(link) set(linklist)#去重 s = ",".join(linklist) #print(linklist) #[a-z0-9A-Z]*为正则表达式匹配0个或多个数字和字母组合的字符串 links = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', s) print(len(links)) #print(links) #创建一个空list newlist = [] #使用循环将整合的link数据集下标赋予新list for i in linklist: link = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', i) if link != []: newlist.append(link[0]) #循环给links中每个网址补齐 for i in range(0,len(links)): newlist[i] = 'http://' + links[i] #输出完整网址的列表 print(newlist)

将获取到的网址通过循环写入新的列表,并打开网址,将网页内的所有词汇写入词典,并将不需要的东西替换掉,将所有字母转为小写方便统计:
for url in newlist: print(url) wbdata = requests.get(url).content soup = BeautifulSoup(wbdata,'lxml') # 替换换行字符 text = str(soup).replace('\n','').replace('\r','') # 替换<script>标签 text = re.sub(r'\<script.*?\>.*?\</script\>',' ',text) # 替换HTML标签 text = re.sub(r'\<.*?\>'," ",text) text = re.sub(r'[^a-zA-Z]',' ',text) # 转换为小写 text = text.lower() text = text.split() text = [i for i in text if len(i) > 1 and i != 'chinadaily' and i != 'com' and i != 'cn'] text = ' '.join(text) print (text) with open(r"D:\新建文件夹\1.txt",'a+') as file: file.write(text+' ') print("写入成功")
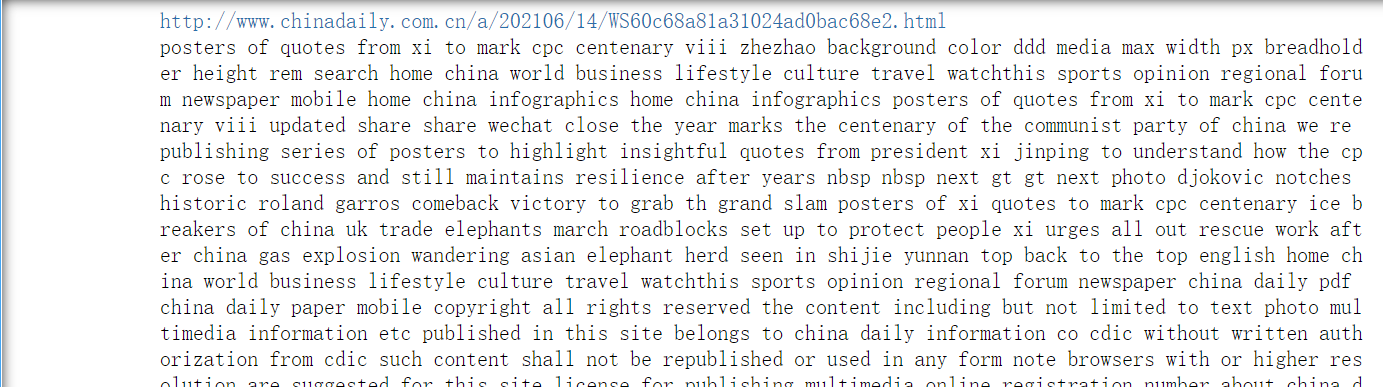
统计txt文档中出所有词汇的出现次数,并记录排序。显示词汇总数,并显示前50个。
from nltk.corpus import stopwords from nltk.probability import * from nltk.corpus import PlaintextCorpusReader import nltk corpus_root = 'D:\新建文件夹' #载入文件作为语料库 wordlists = PlaintextCorpusReader(corpus_root, '.*') #获取整个语料库中的词汇 text = nltk.Text(wordlists.words('1.txt')) print (len(text)) fdist = FreqDist(text) print (fdist) #设置以字典值排序,使频率从高到低显示 newd = sorted(fdist.items(), key=lambda fdist: fdist[1], reverse=True) #输出频率最高的前50个词汇及出现次数 print (newd[:50])

将文件转为csv格式,为了方便后续的画图:
#将list列表通过DataFrame转换为csv格式 import pandas as pd #将list分为两列,加上列名 name=['热频词汇','出现次数'] test=pd.DataFrame(columns=name,data=newd) print(test) test.to_csv('D:/testcsv.csv',encoding='gbk')

取出出现次数最多的前十个词汇及次数:
import csv from pyecharts import options as opts from pyecharts.charts import Bar #读取表 data_df = pd.read_csv('D:/testcsv.csv',encoding='utf-8') df = data_df.dropna() df1 = df[['热频词汇', '出现次数']] data_df.sort_values(by='出现次数',ascending=False) #取前10最高频词 df2 = df1.iloc[:10] print(df2['热频词汇'].values) print(df2['出现次数'].values)
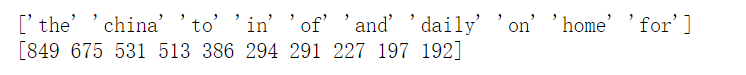
绘制柱状图:
from pyecharts.charts import Line # 导入图表类 from pyecharts.faker import Faker # 用来造假数据的,示例用 from pyecharts import options as opts # 导入配置方法 from pyecharts.globals import ThemeType # 导入主题样式,对我这个色弱太友好了 bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.INFOGRAPHIC )) #x轴数据 bar.add_xaxis(list(df2['热频词汇'].values)) #y轴数据 bar.add_yaxis("词汇出现次数",cishu) #设置标签配置项 bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) #设置标题 bar.set_global_opts(title_opts=opts.TitleOpts(title="高频词前10统计表")) #直接在notebook显示图表 bar.render_notebook()

扩大汇图范围:
df3 = df1.iloc[:20] print(df3)
from pyecharts.charts import Line # 导入图表类 from pyecharts.faker import Faker # 用来造假数据的,示例用 from pyecharts import options as opts # 导入配置方法 from pyecharts.globals import ThemeType # 导入主题样式,对我这个色弱太友好了 bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.ESSOS )) #x轴数据 bar.add_xaxis(list(df3['热频词汇'].values)) #y轴数据 bar.add_yaxis("词汇出现次数",cishu2) #设置标签配置项 bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) #设置标题 bar.set_global_opts(title_opts=opts.TitleOpts(title="高频词前20统计表")) #直接在notebook显示图表 bar.render_notebook()
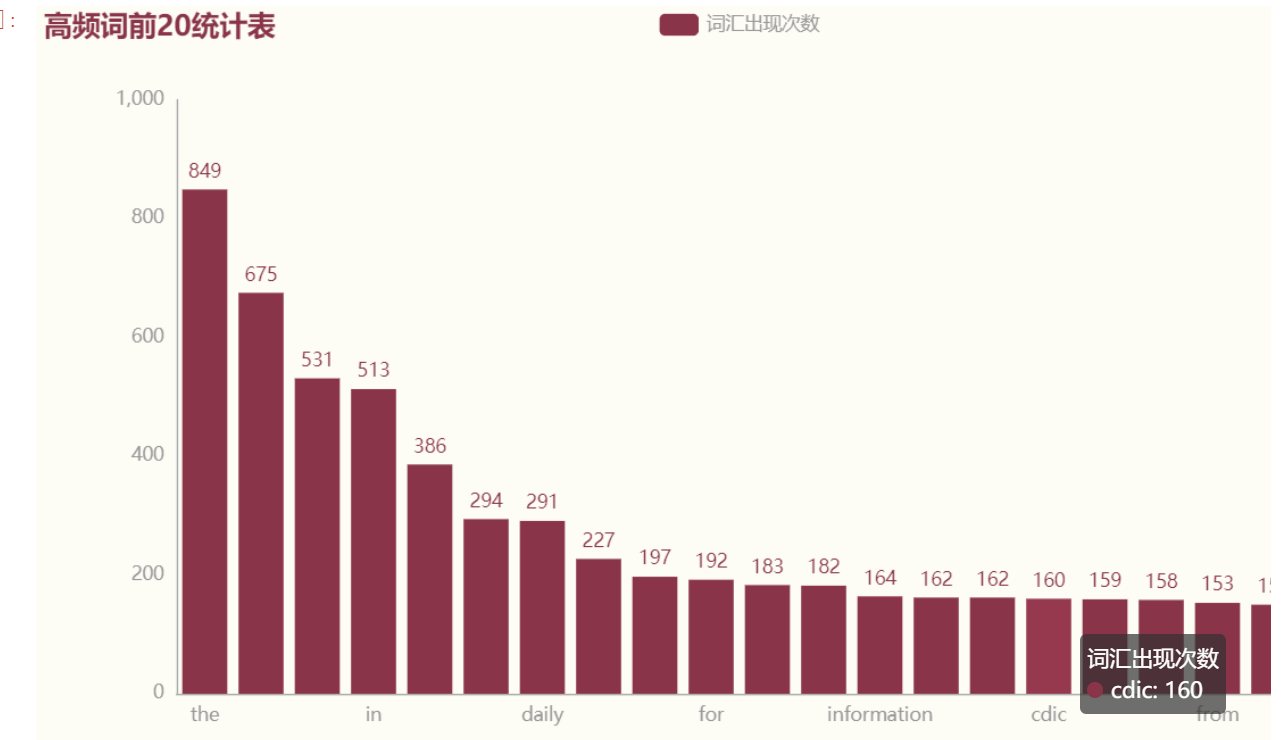
绘制散点图
import matplotlib.pyplot as plt plt.xlabel("词语") plt.scatter(list(df2['热频词汇'].values), cishu, color='b', s=100, marker="o") plt.xlabel("词语") plt.ylabel("出现次数") plt.title("词语出现频率(越上方出现次数越低)") plt.grid() # 添加网格 plt.show()
完整代码:
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 url = 'http://www.chinadaily.com.cn/' 5 def getUrlData(url): 6 try: 7 r = requests.get(url,timeout=30) 8 r.raise_for_status 9 r.encoding=r.apparent_encoding 10 html = r.text 11 return html 12 except: 13 return '发生异常' 14 #获取网页数据 15 wbdata = requests.get(url).text 16 #使用html解析器 17 soup=BeautifulSoup(wbdata,"html.parser") 18 print (soup) 19 #取出两个网址 20 linklist = ['www.chinadaily.com.cn/a/202106/14/WS60c68a81a31024ad0bac68e2.html','www.chinadaily.com.cn/a/202106/14/WS60c6916da31024ad0bac68f4.html','javascript:void(0)'] 21 #用逗号将网址隔开 22 s = ",".join(linklist) 23 print(s) 24 #用正则表达式和网址共同部分匹配王者 25 #[a-z0-9A-Z]*为正则表达式匹配0个或多个数字和字母组合的字符串 26 links = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', s) 27 #输出结果,查看网址匹配效果 28 print(links) 29 linklist = [] 30 for k in soup.find_all('a'): 31 link = k.get('href') 32 linklist.append(link) 33 set(linklist)#去重 34 s = ",".join(linklist) 35 #print(linklist) 36 #[a-z0-9A-Z]*为正则表达式匹配0个或多个数字和字母组合的字符串 37 links = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', s) 38 print(len(links)) 39 #print(links) 40 #创建一个空list 41 newlist = [] 42 #使用循环将整合的link数据集下标赋予新list 43 for i in linklist: 44 link = re.findall('www.chinadaily.com.cn/a/202106/14/WS60[a-z0-9A-Z]*\.html', i) 45 if link != []: 46 newlist.append(link[0]) 47 #循环给links中每个网址补齐 48 for i in range(0,len(links)): 49 newlist[i] = 'http://' + links[i] 50 #输出完整网址的列表 51 print(newlist) 52 for url in newlist: 53 print(url) 54 wbdata = requests.get(url).content 55 soup = BeautifulSoup(wbdata,'lxml') 56 # 替换换行字符 57 text = str(soup).replace('\n','').replace('\r','') 58 # 替换<script>标签 59 text = re.sub(r'\<script.*?\>.*?\</script\>',' ',text) 60 # 替换HTML标签 61 text = re.sub(r'\<.*?\>'," ",text) 62 text = re.sub(r'[^a-zA-Z]',' ',text) 63 # 转换为小写 64 text = text.lower() 65 text = text.split() 66 text = [i for i in text if len(i) > 1 and i != 'chinadaily' and i != 'com' and i != 'cn'] 67 text = ' '.join(text) 68 print (text) 69 with open(r"D:\新建文件夹\1.txt",'a+') as file: 70 file.write(text+' ') 71 print("写入成功") 72 from nltk.corpus import stopwords 73 from nltk.probability import * 74 from nltk.corpus import PlaintextCorpusReader 75 import nltk 76 77 corpus_root = 'D:\新建文件夹' 78 #载入文件作为语料库 79 wordlists = PlaintextCorpusReader(corpus_root, '.*') 80 #获取整个语料库中的词汇 81 text = nltk.Text(wordlists.words('1.txt')) 82 print (len(text)) 83 fdist = FreqDist(text) 84 print (fdist) 85 #设置以字典值排序,使频率从高到低显示 86 newd = sorted(fdist.items(), key=lambda fdist: fdist[1], reverse=True) 87 #输出频率最高的前50个词汇及出现次数 88 print (newd[:50]) 89 #将list列表通过DataFrame转换为csv格式 90 import pandas as pd 91 #将list分为两列,加上列名 92 name=['热频词汇','出现次数'] 93 test=pd.DataFrame(columns=name,data=newd) 94 print(test) 95 test.to_csv('D:/testcsv.csv',encoding='gbk') 96 import csv 97 from pyecharts import options as opts 98 from pyecharts.charts import Bar 99 100 #读取表 101 data_df = pd.read_csv('D:/testcsv.csv',encoding='utf-8') 102 df = data_df.dropna() 103 df1 = df[['热频词汇', '出现次数']] 104 data_df.sort_values(by='出现次数',ascending=False) 105 #取前10最高频词 106 df2 = df1.iloc[:10] 107 print(df2['热频词汇'].values) 108 print(df2['出现次数'].values) 109 import numpy as np #导入numpy计算模块 110 import matplotlib.pyplot as plt #导入matplotlib.pyplot画图模块 111 plt.rcParams['font.sans-serif']='SimHei' #设置中文显示 112 plt.rcParams['axes.unicode_minus']=False 113 data=pd.read_csv('D:/testcsv.csv',encoding='utf-8') 114 #提取其中的'热频词汇'数组,视为数据的标签 115 name=data['热频词汇'] 116 #提取'出现次数'数组:数据存在位置 117 values=data['出现次数'] 118 print(values[:10]) 119 print(name[:10]) 120 from pyecharts.charts import Line # 导入图表类 121 from pyecharts.faker import Faker # 用来造假数据的,示例用 122 from pyecharts import options as opts # 导入配置方法 123 from pyecharts.globals import ThemeType # 导入主题样式,对我这个色弱太友好了 124 bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.INFOGRAPHIC )) 125 #x轴数据 126 bar.add_xaxis(list(df2['热频词汇'].values)) 127 #y轴数据 128 bar.add_yaxis("词汇出现次数",cishu) 129 #设置标签配置项 130 bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) 131 #设置标题 132 bar.set_global_opts(title_opts=opts.TitleOpts(title="高频词前10统计表")) 133 #直接在notebook显示图表 134 bar.render_notebook() 135 #扩大范围: 136 df3 = df1.iloc[:20] 137 print(df3) 138 from pyecharts.charts import Line # 导入图表类 139 from pyecharts.faker import Faker # 用来造假数据的,示例用 140 from pyecharts import options as opts # 导入配置方法 141 from pyecharts.globals import ThemeType # 导入主题样式,对我这个色弱太友好了 142 bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.ESSOS )) 143 #x轴数据 144 bar.add_xaxis(list(df3['热频词汇'].values)) 145 #y轴数据 146 bar.add_yaxis("词汇出现次数",cishu2) 147 #设置标签配置项 148 bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) 149 #设置标题 150 bar.set_global_opts(title_opts=opts.TitleOpts(title="高频词前20统计表")) 151 #直接在notebook显示图表 152 bar.render_notebook() 153 import matplotlib.pyplot as plt 154 plt.xlabel("词语") 155 plt.scatter(list(df2['热频词汇'].values), cishu, color='b', s=100, marker="o") 156 plt.xlabel("词语") 157 plt.ylabel("出现次数") 158 plt.title("词语出现频率(越上方出现次数越低)") 159 plt.grid() # 添加网格 160 plt.show()
总结:
中国新闻中出现的高频词汇还是与我们生活相关的居多,毕竟是中国新闻。距离预期还是有点差距,一些常用的介词影响了数据的准确性。在此次的项目学习中,了解了正则表达式的匹配规则,并对其进行了运用。应该可以通过某些方法排除词典中常用介词,使其从中剔除,不影响最后的数据。因本人技术有限,今后学习生活中一定多多学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号