scrapy爬虫框架
这是我近期学习的一些内容,可能不仅仅局限于scrapy爬虫框架,还会有很多知识的扩展。写的可能不是那么有条理,想到什么就写什么吧,毕竟也是自己以后深入学习的基础,有些知识说的不够明白欢迎留言,共同学习!
一、框架详解
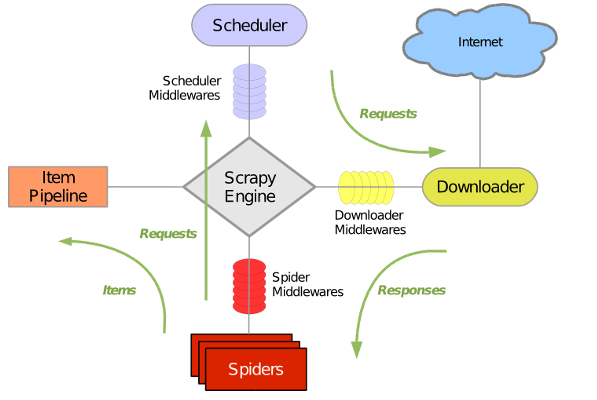
Scrapy是由Twisted写的一个受欢迎的python事件驱动网络框架,它使用的是非阻塞的异步处理。
1.内部各组件的作用
ScrapyEngine(scrapy引擎):是用来控制整个系统的数据处理流程,并进行事务处理的触发。
Scheduler(调度器):用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。它就像是一个URL的优先队列,由它来决定下一个要抓取的网址是什么,同时在这里会去除重复的网址。
Downloader(下载器):用于下载网页内容,并将网页内容返回给爬虫(Spiders)(Scrapy下载器是建立在Twisted这个高效的异步模型上的)。
Spiders(爬虫):爬虫主要是干活的,用于从特定网页中提取自己需要的信息,即所谓的实体(Item)。也可以从中提取URL,让scrapy继续爬取下一个页面。
Pipeline(项目管道):负责处理爬虫从网页中爬取的实体,主要的功能就是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被送到项目管道,并经过几个特定的次序处理数据。
Downloader Middlewares(下载器中间件):位于scrapy引擎和下载器之间的框架,主要是处理scrapy引擎与下载器之间的请求及响应。设置代理ip和用户代理可以在这里设置。
Spider Middlewares(爬虫中间件):位于scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
Scheduler Middlewares(调度中间件):位于scrapy引擎和调度器之间的框架,主要是处理从scrapy引擎发送到调度器的请求和响应。
2.Scrapy运行流程
引擎从调度器中取出一个URL用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器
下载器把资源下载下来,并封装成一个响应(Response)
爬虫解析Response
解析出的是实体(Item),则交给项目管道(Pipeline)进行进一步的处理
解析出的是链接(URL),则把URL交给调度器等待下一步的抓取
二、为什么使用scrapy?爬虫能做什么?
1.Scrapy vs requests+beautifulsoup
首先,requests和beautifulsoup都是库,scrapy是框架;在scrapy框架中可以加入requests和beautifulsoup,它是基于Twisted(异步非阻塞)实现的,性能上有很大的优势;scrapy方便扩展,提供了很多内置的功能;它内置的css和Xpath以及selector提取数据的时候非常高效,beautifulsoup最大的缺点就是慢。
2.爬虫能做什么?
搜索引擎(如百度、Google)、推荐引擎(如今日头条)、机器学习的数据样本、数据分析(如金融数据分析)、舆情分析等
三、爬虫基础知识
1.正则表达式
为什么使用正则表达式?
有时候,我们爬取一些网页具体内容时,会发现我们只需要这个网页某个标签的一部分内容,或者这个标签的某个属性的值时,用xpath和css不太好提取数据,这时候我们就需要用到正则表达式去匹配提取。
re模块简介


1 import re 2 r''' 3 re.match函数 4 原型:match(pattern, string, flags=0) 5 参数: 6 pattern:匹配的正则表达式 7 string:要匹配的字符串 8 flags:标志位,用于控制正则表达式的匹配方式,值如下 9 re.I: 忽略大小写 10 re.L: 做本地化识别 11 re.M: 多行匹配,只影响^和$,对每一行进行操作 12 re.S: 使.匹配包括换行符在内的所有字符 13 re.U: 根据Unicode字符集解析字符,影响\w \W \b \B 14 re.X: 使我们以更灵活的格式理解正则表达式 15 注意:多个选项同时使用时用"|"隔开,如:re.I|re.L|re.M|re.S|re.U|re.X 16 功能:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配,成功的话返回None 17 ''' 18 # www.baidu.com 19 print(re.match('www', 'www.baidu.com')) 20 print(re.match('www', 'www.baidu.com').span()) 21 print(re.match('www', 'wwW.baidu.com', flags=re.I)) 22 # 返回None 23 print(re.match('www', 'ww.baidu.com')) 24 print(re.match('www', 'baidu.www.com')) 25 print(re.match('www', 'wwW.baidu.com')) 26 # 扫描整个字符串返回从起始位置成功的匹配 27 print('----------------------------------------------------------') 28 r''' 29 re.search函数 30 原型:search(pattern, string, flags=0) 31 参数: 32 pattern:匹配的正则表达式 33 string:要匹配的字符串 34 flags:标志位,用于控制正则表达式的匹配方式 35 功能:扫描整个字符串,并返回第一个成功的匹配 36 ''' 37 print(re.search('sunck', 'good man is sunck!sunck is nice')) 38 39 print('---------------------------------------------------------') 40 r''' 41 re.findall函数 42 原型:findall(pattern, string, flags=0) 43 参数: 44 pattern:匹配的正则表达式 45 string:要匹配的字符串 46 flags:标志位,用于控制正则表达式的匹配方式 47 功能:扫描整个字符串,并返回结果列表 48 ''' 49 print(re.findall('sunck', 'good man is sunck!sunck is nice')) 50 print(re.findall('sunck', 'good man is sunck!Sunck is nice', flags=re.I)) 51 52 print('---------------------------------------------------------')
常用的一些正则元字符
1 import re 2 print('------------------匹配单个字符与数字------------------') 3 r''' 4 . 匹配除换行符以外的任意字符 5 * 匹配0个或多个重复的字符,只装饰前面的一个字符 贪婪模式 6 + 匹配1个或者多个重复的字符,只装饰前面的一个字符 贪婪模式 7 ? 匹配0个或者1个字符,只装饰前面的一个字符 8 [0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符 9 [sunck] 匹配's','u','n','c','k'中的任意一个字符 10 [a-z] 匹配任意小写字母 11 [A-Z] 匹配任意大写字母 12 [0-9] 匹配任意数字,类似[0123456789] 13 [0-9a-zA-Z] 匹配任意的数字和字母 14 [0-9a-zA-Z_] 匹配任意的数字、字母和下划线 15 [^sunck] 匹配除了's','u','n','c','k'这几个字母以外的所有字符,中括号的"^"称为脱字符,表示不匹配集合中的字符 16 [^0-9] 匹配所有的非数字字符 17 \d 匹配所有的数字,效果同[0-9] 18 \D 匹配所有的非数字字符,效果同[^0-9] 19 \w 匹配数字、字母和下划线,效果同[0-9a-zA-Z_] 20 \W 匹配非数字、字母和下划线,效果同[^0-9a-zA-Z_] 21 \s 匹配所有的空白符(空格、换行、回车、换页、制表),效果同[ \r\n\f\t(v)] 22 \S 匹配任意的非空白符,效果同[^ \r\n\f\t(v)] 23 ''' 24 print(re.search('.', 'sunck is a good man')) 25 print(re.search('[0123456789]', 'sunck is a good 3 man')) 26 print(re.search('[0123456789]', 'sunck is a good man 6')) 27 print(re.search('[sunck]', 'sunck is a good 3 man')) 28 print(re.findall('[^\d]', 'sunck is a good 3 man')) 29 print('------------------锚字符(边界字符)------------------') 30 r''' 31 ^ 行首匹配,和在[]里的^不是一个意思 32 $ 行尾匹配 33 \A 匹配字符串开始,它和^的区别是:\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配它行的行首 34 \Z 匹配字符串结尾,它和$的区别是:\Z只匹配整个字符串的结尾,即使在re.M模式下也不会匹配它行的行尾 35 \b 匹配一个单词的边界,指单词结束的位置能匹配,r'er\b'可以匹配never,不能匹配nerve,也就是-w和-W相邻的时候是边界 不转义的是时候是删除上一个字符 36 \B 匹配非单词的边界,指单词里面的位置能匹配,r'er\B'可以匹配nerve,不能匹配never 37 ''' 38 print(re.search('^sunck', 'sunck is a good man')) 39 print(re.search('sunck$', 'sunck is a good man')) 40 print(re.search('man$', 'sunck is a good man')) 41 print(re.search(r'er\b', 'never')) 42 print(re.search(r'er\b', 'nerve')) 43 print(re.search(r'er\B', 'never')) 44 print(re.search(r'er\B', 'nerve')) 45 print('------------------匹配多个字符------------------') 46 r''' 47 说明:下方的x、y、z均为假设的普通字符,n、m均为非负整数,不是正则表达式的元字符 48 (xyz) 匹配小括号内的xyz(作为一个整体去匹配) 49 x? 匹配0个或者1个x 50 x* 匹配0个或者任意多个x,(.* 表示匹配0个或者任意多个字符(换行符除外)) 51 x+ 匹配至少一个x 52 x{n} 匹配确定的n个x(n是一个非负整数) 53 x{n,} 匹配至少n个x 54 x{n,m} 匹配至少n个最多m个x,注意:n <= m 55 x|y 匹配的是x或y,|表示或 56 print(re.findall(r"a.*c|b[\w]{2}$", 'asacbas')) 57 注意:多个正则表达式相或的时候,匹配过程是从左向右依次尝试匹配,如果左边有一个或者若干个匹配已经把整个字符串匹配完了, 58 那么后面的表达式将不再进行匹配。匹配是从左向右依次使用正则表达式去匹配前面匹配后剩下来的字符串 59 60 ''' 61 print(re.findall(r'(sunck)', 'sunckgood is a good man,sunck is a nice man')) 62 print(re.findall(r'a?', 'aaa')) # 非贪婪匹配(尽可能少的匹配) 63 print(re.findall(r'a*', 'aaabbaaa')) # 贪婪匹配(尽可能多的匹配) 64 print(re.findall(r'a+', 'aaabbaaaaaaaaaaaa')) # 贪婪匹配(尽可能多的匹配) 65 # 需求,提取sunck----man 66 str = 'sunck is a good man!sunck is a nice man!sunck is a very handsome man' 67 print(re.findall(r'sunck.*?man', str)) 68 69 print('------------------特殊------------------') 70 r''' 71 *? +? x? 最小匹配 通常都是尽可能多的匹配,可以使用这种方式解决贪婪匹配 72 (?:x) 类似(xyz),但不表示一个组,取消组的缓存,无法通过group()获取其中的组 73 (?P<name>) 给一个组起个别名,group()的时候可以直接使用该名字进行匹配 74 (?P=name) 命名反向引用,可以直接使用前面命名的组 75 (a|b)\1 匿名分组的反向引用,通过组号匹配(aa|bb) 76 (a|b)(c|d)\1\2 (acac|adad|bcbc|bdbd) 77 abc(?=123) 前向断言,匹配前面紧跟着123的abc 78 abc(?!123) 前向断言,匹配前面不能是紧跟着123的abc 79 (?<=123)abc 后向断言,匹配后面紧跟着123的abc 80 (?<!123)abc 后向断言,匹配后面不能是紧跟着123的abc 81 ''' 82 # 注释: /* part1 */ /* part2 */ 83 print(re.findall(r'//*.*/*/', r'/* part1 */ /* part2 */')) 84 print(re.findall(r'//*.*?/*/', r'/* part1 */ /* part2 */')) 85 # 命名反向引用 86 print(re.search(r'd(?P<first>ab)+(?P=first)', 'asagghhdababhjdkfdabjjk')) 87 # 匿名分组的反向引用,通过组号匹配 88 m = re.search(r'd(a|b)\1', 'daa|dbb') 89 if m: 90 print(m.group()) 91 m = re.search(r'd(a|b)(c|d)\1\2', 'dacac|dadad|dbcbc|dbdbd') 92 if m: 93 print(m.group()) 94 # 前向断言 95 m = re.search(r'abc(?=123)', 'abc123') 96 if m: 97 print(m.group()) 98 m = re.search(r'abc(?!123)', 'abc124') 99 if m: 100 print(m.group()) 101 # 后向断言 102 m = re.search(r'(?<=123)abc', '123abc') 103 if m: 104 print(m.group()) 105 m = re.search(r'(?<!123)abc', '123abc') 106 if m: 107 print(m.group()) 108 109 r''' 110 . 通配符,代表一个任意字符 111 ''' 112 # print(re.findall(r'l..e', a)) 113 r''' 114 * 0个或者多个重复的字符,只装饰前面的一个字符 贪婪模式 115 ''' 116 # print(re.findall(r'l.*e', a)) 117 r''' 118 ^ 以......开头 119 ''' 120 # print(re.findall(r'^I', a)) 121 r''' 122 $ 以......结尾 123 ''' 124 # print(re.findall(r'^a.*b$', 'adfgfhb')) 125 r''' 126 + 1个或者多个重复的字符,只装饰前面的一个字符 贪婪模式 127 ''' 128 # print(re.findall(r'^aa+b$', 'aaaa2aab')) 129 r''' 130 ? 0个或者1个字符,只装饰前面的一个字符 可以把贪婪模式转换为非贪婪模式 131 ''' 132 # print(re.findall(r'ab?', 'aaaa2aab')) 133 r''' 134 {m} m个字符,只装饰前面的一个字符 135 ''' 136 # print(re.findall(r'ab{5}', 'aaabbbbba2aab')) 137 r''' 138 {m,n} 至少m个最多n个字符,只装饰前面的一个字符 139 ''' 140 # print(re.findall(r'ab{3,5}', 'aaabbbbba2aab')) 141 r''' 142 {m,} 至少m个字符,只装饰前面的一个字符 143 ''' 144 # print(re.findall(r'ab{3,}', 'aaabbbbba2aab')) 145 r''' 146 [] 是一个字符集合,在这里面元字符就失去原来的作用,成为普通字符 147 [^abc] 除了集合中的元素,其他的元素都可以匹配到 148 [^^] 只要不是^都可以匹配到 149 - 表示区间,如果想表示-写到最前面或者最后面[a-],或者使用转义'\' 150 ''' 151 # print(re.findall(r'ab[a-z]', 'aaabbbbba2aab')) 152 r''' 153 \d{9}$ :表示以\d{9}结尾 154 \d 匹配所有的数字,效果同[0-9] 155 \D 匹配所有的非数字字符,效果同[^0-9] 156 \w 匹配数字、字母和下划线,效果同[0-9a-zA-Z_] 157 \W 匹配非数字、字母和下划线,效果同[^0-9a-zA-Z_] 158 \s 匹配所有的空白符(空格、换行、回车、换页、制表),效果同[ \r\n\f\t(v)] 159 \S 匹配任意的非空白符,效果同[^ \r\n\f\t(v)] 160 ''' 161 # print(re.findall(r"a.*c|b[\w]{2}$", 'asacbas')) 162 # 注意:多个正则表达式相或的时候,匹配过程是从左向右依次尝试匹配,如果左边有一个或者若干个匹配已经把整个字符串匹配完了, 163 # 那么后面的表达式将不再进行匹配。匹配是从左向右依次使用正则表达式去匹配前面匹配后剩下来的字符串 164 # 匹配特殊字符可以使用'\'或者'[]',* + ? [] () {}等特殊字符就变成一个普通字符了 165 # ret = re.findall(r"d(ab)+", 'asadacbdababadabs') 166 # print(ret) 167 # print(ret.group(1)) 168 # print(ret.group(2))
1 import re 2 r''' 3 字符串切割 4 ''' 5 str = 'sunck is a good man' 6 print(re.split(r' +', str)) 7 8 r''' 9 re.finditer函数 10 原型:finditer(pattern, string, flags=0) 11 参数: 12 pattern:匹配的正则表达式 13 string:要匹配的字符串 14 flags:标志位,用于控制正则表达式的匹配方式 15 功能:与findall类似,扫描整个字符串,返回的是一个迭代器 16 ''' 17 str1 = 'sunck is a good man!sunck is a nice man!sunck is a handsome man' 18 d = re.finditer(r'(sunck)', str1) 19 while True: 20 try: 21 L = next(d) 22 print(L) 23 except StopIteration as e: 24 break 25 26 r''' 27 sunck is a good man 28 字符串的替换和修改 29 sub(pattern, repl, string, count=0, flags=0) 30 subn(pattern, repl, string, count=0, flags=0 31 参数: 32 pattern: 正则表达式(规则) 33 repl: 指定的用来替换的字符串 34 string: 目标字符串 35 count: 最多替换次数 36 flags: 标志位,用于控制正则表达式的匹配方式 37 功能:在目标字符串中以正则表达式的规则匹配字符串,再把他们替换成指定的字符串。可以指定替换的次数,如果不指定,替换所有的匹配字符串 38 区别:前者返回一个被替换的字符串,后者返回一个元组,第一个元素是被替换的字符串,第二个元素是被替换的次数 39 ''' 40 str2 = 'sunck is a good good good man ' 41 print(re.sub(r'(good)', 'nice', str2)) 42 print(type(re.sub(r'(good)', 'nice', str2))) 43 print(re.subn(r'(good)', 'nice', str2)) 44 print(type(re.subn(r'(good)', 'nice', str2))) 45 46 r''' 47 分组: 48 概念:除了简单的判断是否匹配之外,正则表达式还有提取子串的功能。用()表示的就是提取出来的分组 49 50 ''' 51 str3 = '010-52347654' 52 m = re.match(r'(?P<first>\d{3})-(?P<last>\d{8})', str3) 53 # 使用序号获取对应组的信息,group(0)一直代表的是原始字符串 54 print(m.group(0)) 55 print(m.group(1)) 56 print(m.group('first')) 57 print(m.group('last')) 58 print(m.group(2)) 59 # 查看匹配的各组的情况 60 print(m.groups()) 61 62 r''' 63 编译:当我们使用正则表达式时,re模块会干两件事 64 1、编译正则表达式,如果正则表达式本身不合法,会报错 65 2、用编译后的正则表达式去匹配对象 66 compile(pattern, flags=0) 67 pattern:要编译的正则表达式 68 flags:标志位,用于控制正则表达式的匹配方式 69 ''' 70 pat = r'^1(([3578]\d)|(47))\d{8}$' 71 print(re.match(pat, '13600000000')) 72 # 编译成正则对象 73 re_telephone = re.compile(pat) 74 print(re_telephone.match('13600000000')) 75 76 # re模块调用 77 # re对象调用 78 79 # re.match(pattern, string, flags=0) 80 # re_telephone.match(string) 81 82 # re.search(pattern, string, flags=0) 83 # re_telephone.search(string) 84 85 # re.findall(pattern, string, flags=0) 86 # re_telephone.findall(string) 87 88 # re.finditer(pattern, string, flags=0) 89 # re_telephone.finditer(string) 90 91 # re.split(pattern, string, maxsplit=0, flags=0) 92 # re_telephone.split(string, maxsplit=0) 93 94 # re.sub(pattern, repl, string, count=0, flags=0) 95 # re_telephone.sub(repl, string, count=0) 96 97 # re.subn(pattern, repl, string, count=0, flags=0) 98 # re_telephone.subn(repl, string, count=0)
1 r''' 2 JavaScript RegExp 对象 3 RegExp 对象: 4 正则表达式是描述字符模式的对象。正则表达式用于对字符串模式匹配及检索替换,是对字符串执行模式匹配的强大工具。 5 语法:var patt=new RegExp(pattern,modifiers);或者var patt=/pattern/modifiers; 6 参数: 7 pattern(模式) 描述了表达式的模式 8 modifiers(修饰符) 用于指定全局匹配、区分大小写的匹配和多行匹配 9 注意:当使用构造函数创造正则对象时,需要常规的字符转义规则(在前面加反斜杠 \)。比如,以下是等价的: 10 var re = new RegExp("\\w+"); 11 var re = /\w+/; 12 ''' 13 14 r''' 15 修饰符:修饰符用于执行区分大小写和全局匹配 16 i 执行对大小写不敏感的匹配。 17 g 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 18 m 执行多行匹配。 19 ''' 20 21 r''' 22 方括号:方括号用于查找某个范围内的字符 23 [abc] 查找方括号之间的任何字符。 24 [^abc] 查找任何不在方括号之间的字符。 25 [0-9] 查找任何从 0 至 9 的数字。 26 [a-z] 查找任何从小写 a 到小写 z 的字符。 27 [A-Z] 查找任何从大写 A 到大写 Z 的字符。 28 [A-z] 查找任何从大写 A 到小写 z 的字符。 29 [adgk] 查找给定集合内的任何字符。 30 [^adgk] 查找给定集合外的任何字符。 31 (red|blue|green) 查找任何指定的选项。 32 ''' 33 34 r''' 35 元字符:元字符(Metacharacter)是拥有特殊含义的字符 36 . 查找单个字符,除了换行和行结束符。 37 \w 查找单词字符。 38 \W 查找非单词字符。 39 \d 查找数字。 40 \D 查找非数字字符。 41 \s 查找空白字符。 42 \S 查找非空白字符。 43 \b 匹配单词边界。 44 \B 匹配非单词边界。 45 \0 查找 NUL 字符。 46 \n 查找换行符。 47 \f 查找换页符。 48 \r 查找回车符。 49 \t 查找制表符。 50 \v 查找垂直制表符。 51 \xxx 查找以八进制数 xxx 规定的字符。 52 \xdd 查找以十六进制数 dd 规定的字符。 53 \uxxxx 查找以十六进制数 xxxx 规定的 Unicode 字符。 54 ''' 55 56 r''' 57 量词 58 n+ 匹配任何包含至少一个 n 的字符串。 59 n* 匹配任何包含零个或多个 n 的字符串。 60 n? 匹配任何包含零个或一个 n 的字符串。 61 n{X} 匹配包含 X 个 n 的序列的字符串。 62 n{X,Y} 匹配包含 X 至 Y 个 n 的序列的字符串。 63 n{X,} 匹配包含至少 X 个 n 的序列的字符串。 64 n$ 匹配任何结尾为 n 的字符串。 65 ^n 匹配任何开头为 n 的字符串。 66 ?=n 匹配任何其后紧接指定字符串 n 的字符串。 67 ?!n 匹配任何其后没有紧接指定字符串 n 的字符串。 68 ''' 69 70 r''' 71 JavaScript search() 方法 72 定义和用法: 73 search() 方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。如果没有找到任何匹配的子串,则返回 -1。 74 语法:string.search(searchvalue) 75 参数: 76 searchvalue:必须。查找的字符串或者正则表达式。 77 返回值:Number(类型) 78 与指定查找的字符串或者正则表达式相匹配的 String 对象起始位置。 79 ''' 80 81 r''' 82 JavaScript match() 方法 83 定义和用法: 84 match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。 85 注意: match() 方法将检索字符串 String Object,以找到一个或多个与 regexp 匹配的文本。这个方法的行为在很大程度上有赖于 regexp 是否具有标志 g。 86 如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject 中执行一次匹配。如果没有找到任何匹配的文本, match() 将返回 null。 87 否则,它将返回一个数组,其中存放了与它找到的匹配文本有关的信息。 88 语法:string.match(regexp) 89 参数: 90 regexp: 必需。规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。 91 返回值:Array(类型) 92 存放匹配结果的数组。该数组的内容依赖于 regexp 是否具有全局标志 g。 如果没找到匹配结果返回 null 。 93 ''' 94 95 r''' 96 JavaScript replace() 方法 97 定义和用法: 98 replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。 99 该方法不会改变原始字符串。 100 语法:string.replace(searchvalue,newvalue) 101 参数: 102 searchvalue:必须。规定子字符串或要替换的模式的 RegExp 对象。请注意,如果该值是一个字符串,则将它作为要检索的直接量文本模式,而不是首先被转换为 RegExp 对象。 103 newvalue:必需。一个字符串值。规定了替换文本或生成替换文本的函数。 104 返回值:String(类型) 105 一个新的字符串,是用 replacement 替换了 regexp 的第一次匹配或所有匹配之后得到的。 106 ''' 107 108 r''' 109 JavaScript split() 方法 110 定义和用法: 111 split() 方法用于把一个字符串分割成字符串数组。 112 提示: 如果把空字符串 ("") 用作 separator,那么 stringObject 中的每个字符之间都会被分割。 113 注意: split() 方法不改变原始字符串。 114 语法:string.split(separator,limit) 115 参数: 116 separator:可选。字符串或正则表达式,从该参数指定的地方分割 string Object。 117 limit:可选。该参数可指定返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。 118 返回值:Array(类型) 119 一个字符串数组。该数组是通过在 separator 指定的边界处将字符串 string Object 分割成子串创建的。返回的数组中的字串不包括 separator 自身。 120 ''' 121 122 r''' 123 JavaScript compile() 方法 124 定义和用法: 125 compile() 方法用于在脚本执行过程中编译正则表达式。compile() 方法也可用于改变和重新编译正则表达式。 126 语法:RegExpObject.compile(regexp,modifier) 127 参数: 128 regexp: 正则表达式。 129 modifier:规定匹配的类型。"g" 用于全局匹配,"i" 用于区分大小写,"gi" 用于全局区分大小写的匹配。 130 ''' 131 132 r''' 133 JavaScript exec() 方法 134 定义和用法: 135 exec() 方法用于检索字符串中的正则表达式的匹配。如果字符串中有匹配的值返回该匹配值,否则返回 null。 136 语法:RegExpObject.exec(string) 137 参数: 138 string: Required. The string to be searched 139 ''' 140 141 r''' 142 JavaScript test() 方法 143 定义和用法: 144 test() 方法用于检测一个字符串是否匹配某个模式。如果字符串中有匹配的值返回 true ,否则返回 false。 145 语法:RegExpObject.test(string) 146 参数: 147 string: 必需。要检测的字符串。 148 '''
1 100--客户必须继续发送请求 2 101--客户要求服务器根据请求转换HTTP协议版本 3 200--交易成功*** 4 201--提示知道新文件的URL 5 202--接收和处理,但处理未完成 6 203--返回信息不确定或不完整 7 204--请求收到,但返回信息为空 8 205--服务器完成了请求,用户代理必须复位当前已经浏览过的文件 9 206--服务器已经完成了部分用户的GET请求 10 300--请求的资源可在多处得到 11 301--删除请求数据 12 302--在其他地址发现了请求数据 13 303--建议客户访问其他URL或访问方式 14 304--客户端已经执行了GET,但文件为变化*** 15 305--请求的资源必须从服务器指定的地址得到 16 306--前一版本HTTP中使用的代码,现行版本中不再使用 17 307--申明请求的资源临时性删除 18 400--错误请求,如语法错误 19 401--请求授权失败 20 402--保留有效ChargeTo头响应 21 403--请求不允许 22 404--没有发现文件、查询或URL*** 23 405--用户在Request-Line字段定义的方法不允许 24 406--根据用户发送的Accept拖,请求资源不可访问 25 407--类似401,用户必须首先在代理服务器上得到授权 26 408--客户端没有在用户指定的时间内完成请求 27 409--对当前资源状态,请求不能完成 28 410--服务器上不再有此资源且无进一步的参考地址 29 411--服务器拒绝用户定义的Content-Length属性请求 30 412--一个或多个请求头字段在当前请求中错误 31 413--请求的资源大于服务器允许的大小 32 414--请求的资源URL长于服务器允许的长度 33 415--请求资源不支持请求项目格式 34 416--请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段 35 417--服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求 36 500--服务器产生内部错误*** 37 501--服务器不支持请求的函数 38 502--服务器暂时不可用,有时是为了防止发生系统过载 39 503--服务器过载或暂停维修 40 504--关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长 41 505--服务器不支持或拒绝请求头中指定的HTTP版本
2.深度优先和广度优先遍历算法
深度优先搜索(DepthFirstSearch):深度优先搜索的主要特征就是,假设一个顶点有不少相邻顶点,当我们搜索到该顶点,我们对于它的相邻顶点并不是现在就对所有都进行搜索,而是对一个顶点继续往后搜索,直到某个顶点,它周围相邻顶点都已经被访问过了,这时它就可以返回,对它原来的那个顶点的其余顶点进行搜索。深度优先搜索的实现可以利用递归很简单的实现。
广度优点搜索(BreadthFirstSearch):广度优先搜索相对于深度优先搜索侧重点不一样,深度优先好比一个人走迷宫,一次只能选定一条路走下去,而广度优先搜索好比是一次能有任意多个人,一次就走到和一个顶点相连的所有未访问过的顶点,然后再从这些顶点出发,继续这个过程。
3.url常见的去重策略
将访问过的url保存到数据库中
将访问过的url保存到set中,只需要o(1)的代价就可以查询url
url经过MD5等方法哈希后保存到set中
用bitmap方法,将访问过的url通过hash函数映射到某一位
bloomfilter方法对bitmap进行改进,多重hash函数降低冲突
4.爬虫与反爬虫
基本概念:
爬虫:自动获取网站数据的程序,关键是批量的获取
反爬虫:使用技术手段防止爬虫程序的方法
误伤:反爬虫技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
成本:反爬虫需要的人力和机器成本
拦截:成功拦截爬虫,一般拦截率越高,误伤率越高
反爬虫的目的:
应对初级爬虫(简单粗暴,不管服务器压力,容易弄挂网站的)、数据保护、失控的爬虫(由于某些情况下,忘记或者无法关闭的爬虫)、商业竞争对手
爬虫与反爬虫的对抗过程:

防止爬虫被网站禁止的策略
图片验证码、ip访问频率限制、user-agent随机切换
5.提取数据工具
1 article 选取所有article元素的所有子节点 2 /article 选取根元素article 3 article/a 选取所有属于article的子元素的a元素 4 //div 选取所有div子元素(不论出现在文档任何地方) 5 article//div 选取所有属于article元素的后代的div元素,不管它出现在article之下的任何位置 6 //@class 选取所有名为class的属性 7 8 /article/div[1] 选取属于article子元素的第一个div元素 9 /article/div[last()] 选取属于article子元素的最后一个div元素 10 /article/div[last()-1] 选取属于article子元素的倒数第二个div元素 11 //div[@lang] 选取所有拥有lang属性的div元素 12 //div[@lang='eng'] 选取所有lang属性为eng的div元素 13 14 /div/* 选取属于div元素的所有子节点 15 //* 选取所有元素 16 //div[@*] 选取所有带属性的title元素 17 //div/a|//div/p 选取所有div元素的a和p元素 18 //span|//ul 选取文档中的span和ul元素 19 article/div/p|//span 选取所有属于article元素的div元素的p元素以及文档中所有的span元素
1 * 选择所有节点 2 #container 选择id为container的节点 3 .container 选择所有class包含container的节点 4 li a 选取所有li下的所有a节点 5 ul + p 选择ul后面的第一个p元素 6 div#container > ul 选取id为container的div的第一个ul子元素 7 ul ~ p 选取与ul相邻的所有p元素 8 a[title] 选取所有有title属性的a元素 9 a[href="http://jobbole.com"] 选取所有href属性为jobbole.com值的a元素 10 a[href*="jobbole"] 选取所有href属性包含jobbole的a元素 11 a[href^="http"] 选取所有href属性值以http开头的a元素 12 a[href$=".jpg"] 选取所有href属性值以.jpg结尾的a元素 13 input[type=radio]:checked 选择选中的radio的元素 14 div:not(#container) 选取所有id非container的div属性 15 li:nth-child(3) 选取第三个li元素 16 tr:nth-child(2n) 第偶数个tr
6.调试
scrapy shell 要调试的网址
1 from scrapy.cmdline import execute 2 import sys 3 import os 4 5 sys.path.append(os.path.dirname(os.path.abspath(__file__))) 6 execute(["scrapy", "crawl", "jobbole"])
7.安装开发环境
1 安装mysqlclient 2 windows:pip install mysqlclient 3 linux:sudo apt-get install libmysqlclient-dev 4 5 安装虚拟环境 6 pip install virtualenv 7 pip install virtualenvwrapper 8 9 在Windows上运行workon 10 pip install virtualenvwrapper-win 11 12 项目中安装的包,以及在别的项目中安装这些包 13 pip freeze > requirements.txt 14 pip install -r requirements.txt
8.设置用户代理
1 from fake_useragent import UserAgent 2 3 4 # 随机更换user-agent 5 class RandomUserAgentMiddleware(object): 6 def __init__(self, crawler): 7 super(RandomUserAgentMiddleware, self).__init__() 8 self.ua = UserAgent() 9 # 在settings中配置RANDOM_UA_TYPE,可以获得相应浏览器的user-agent 10 self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random") 11 12 @classmethod 13 def from_crawler(cls, crawler): 14 return cls(crawler) 15 16 def process_request(self, request, spider): 17 def get_ua(): 18 return getattr(self.ua, self.ua_type) 19 request.headers.setdefault("User_Agent", get_ua())
9.设置ip代理
1 import requests 2 from scrapy.selector import Selector 3 import MySQLdb 4 5 conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="ccmldl", db="article_spider", charset="utf8") 6 cursor = conn.cursor() 7 8 9 def crawl_ips(): 10 # 爬取西刺的免费ip代理 11 headers = { 12 "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36" 13 } 14 for i in range(1, 3476): 15 re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers) 16 selector = Selector(text=re.text) 17 all_trs = selector.css("#ip_list tr") 18 19 ip_list = [] 20 for tr in all_trs[1:]: 21 speed_str = tr.css(".bar::attr(title)").extract_first() 22 if speed_str: 23 speed = float(speed_str.split("秒")[0]) 24 all_texts = tr.css("td::text").extract() 25 ip = all_texts[0] 26 port = all_texts[1] 27 proxy_type = all_texts[5] 28 ip_list.append((ip, port, proxy_type, speed)) 29 30 for ip_info in ip_list: 31 cursor.execute( 32 "insert into proxy_ip(ip, port, speed, proxy_type) values ('{0}', '{1}', {2}, '{3}')".format( 33 ip_info[0], ip_info[1], ip_info[3], ip_info[2] 34 ) 35 ) 36 conn.commit() 37 38 39 class GetIP(object): 40 def delete_ip(self, ip): 41 # 从数据库中删除无效的ip 42 delete_sql = """ 43 delete from proxy_ip where ip='{0}' 44 """.format(ip) 45 cursor.execute(delete_sql) 46 conn.commit() 47 return True 48 49 def judeg_ip(self, ip, port, proxy_type): 50 # 判断ip是否可用 51 http_url = "http://www.baidu.com" 52 proxy_url = "{0}://{1}:{2}".format(proxy_type.lower(), ip, port) 53 try: 54 proxy_dict = { 55 "http": proxy_url 56 } 57 response = requests.get(http_url, proxies=proxy_dict) 58 # return True 59 except Exception as e: 60 # print("invalid ip and port") 61 self.delete_ip(ip) 62 return False 63 else: 64 code = response.status_code 65 if code >= 200 and code < 300: 66 # print("effective ip") 67 return True 68 else: 69 # print("invalid ip and port") 70 self.delete_ip(ip) 71 return False 72 73 def get_random_ip(self): 74 # 从数据库中随机获取一个可用的ip 75 random_sql = """ 76 select ip, port, proxy_type from proxy_ip order by rand() limit 1 77 """ 78 result = cursor.execute(random_sql) 79 for ip_info in cursor.fetchall(): 80 ip = ip_info[0] 81 port = ip_info[1] 82 proxy_type = ip_info[2] 83 84 judge_res = self.judeg_ip(ip, port, proxy_type) 85 if judge_res: 86 return "{0}://{1}:{2}".format(proxy_type, ip, port) 87 else: 88 return self.get_random_ip() 89 90 91 if __name__ == '__main__': 92 crawl_ips() 93 get_ip = GetIP() 94 print(get_ip.get_random_ip())
1 from tools.crawl_xici_ip import GetIP 2 3 4 # 动态设置ip代理 5 class RandomProxyMiddleware(object): 6 def process_request(self, request, spider): 7 get_ip = GetIP() 8 request.meta["proxy"] = get_ip.get_random_ip()
四、scrapy进阶开发
1.selenium(浏览器自动化测试框架)
1 from selenium import webdriver 2 from scrapy.selector import Selector 3 import time 4 5 browser = webdriver.Chrome(executable_path=r"D:\谷歌浏览器\Google_Chrome_v68.0.3440.106_x64\chromedriver.exe") 6 browser.get("https://www.taobao.com") 7 t_selector = Selector(text=browser.page_source) 8 print(t_selector.css("").extract()) 9 10 browser.find_element_by_css_selector("").send_keys() 11 browser.find_element_by_css_selector("").click() 12 13 # 模拟鼠标下滑加载动态页面 14 browser.execute_script( 15 "window.scrollTo(0, document.body.scrollHeight); 16 var lenOfPage=document.body.scrollHeight; 17 return lenOfPage;" 18 ) 19 20 # 设置chromdriver不加载图片 21 chrome_opt =webdriver.ChromeOptions() 22 prefs = {"profile.managed_default_content_settings.images": 2} 23 chrome_opt.add_experimental_option("prefs": prefs) 24 browser = webdriver.Chrome( 25 executable_path=r"D:\谷歌浏览器\Google_Chrome_v68.0.3440.106_x64\chromedriver.exe", 26 chrome_options=chrome_opt 27 ) 28 browser.get("https://www.taobao.com") 29 30 # phantomjs,无界面的浏览器,多进程情况下phantomjs性能会下降很严重 31 browser = webdriver.Phantomjs(executable_path=r"D:\phantomjs-2.1.1-windows\bin\phantomjs.exe") 32 browser.get("https://www.taobao.com") 33 print(browser.page_source) 34 browser.quit()
2.将selenium集成到scrapy
1 from selenium import webdriver 2 from scrapy.xlib.pydispatch import dispatcher 3 from scrapy import signals 4 5 def __init__(self): 6 self.browser = webdriver.Chrome(executable_path=r"D:\谷歌浏览器\Google_Chrome_v68.0.3440.106_x64\chromedriver.exe") 7 super(JobboleSpider, self).__init__() 8 # 信号的作用:当spider关闭的时候我们做什么事情 9 dispatcher.connect(self.spider_closed, signals.spider_closed) 10 11 def spider_closed(self, spider): 12 # 当爬虫退出的时候关闭Chrome 13 print("spider closed") 14 self.browser.quit()
1 import time 2 from scrapy.http import HtmlResponse 3 4 5 # 通过chromdriver请求动态页面 6 def process_request(self, request, spider): 7 if spider.name == 'jobbole': 8 spider.browser.get(request.url) 9 time.sleep(3) 10 print("访问:{0}".format(request.url)) 11 return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding='utf-8', request=request)
3.scrapy的暂停与重启
job_info需要自己在工程中新建好
scrapy crawl jobbole -s JOBDIR=job_info/001
暂停的信号:Ctrl+c 需要接着原来的数据爬取就执行上面那句话
如果需要重新爬取:scrapy crawl jobbole -s JOBDIR=job_info/002
4.数据收集(stats collection)
1 from scrapy.xlib.pydispatch import dispatcher 2 from scrapy import signals 3 4 5 class JobboleSpider(scrapy.Spider): 6 ... 7 # 收集伯乐在线所有的404的url以及404页面数 8 handle_httpstatus_list = [404] 9 10 def __init__(self): 11 self.fail_urls = [] 12 13 def parse(self, response): 14 if response.status == 404: 15 self.fail_urls.append(response.url) 16 self.crawler.stats.inc_value("failed_url") 17 ...
未完待续...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号