BUAA_OO_2022第一单元表达式解析总结
BUAA-OO-2022-Unit1
1. 第一次作业
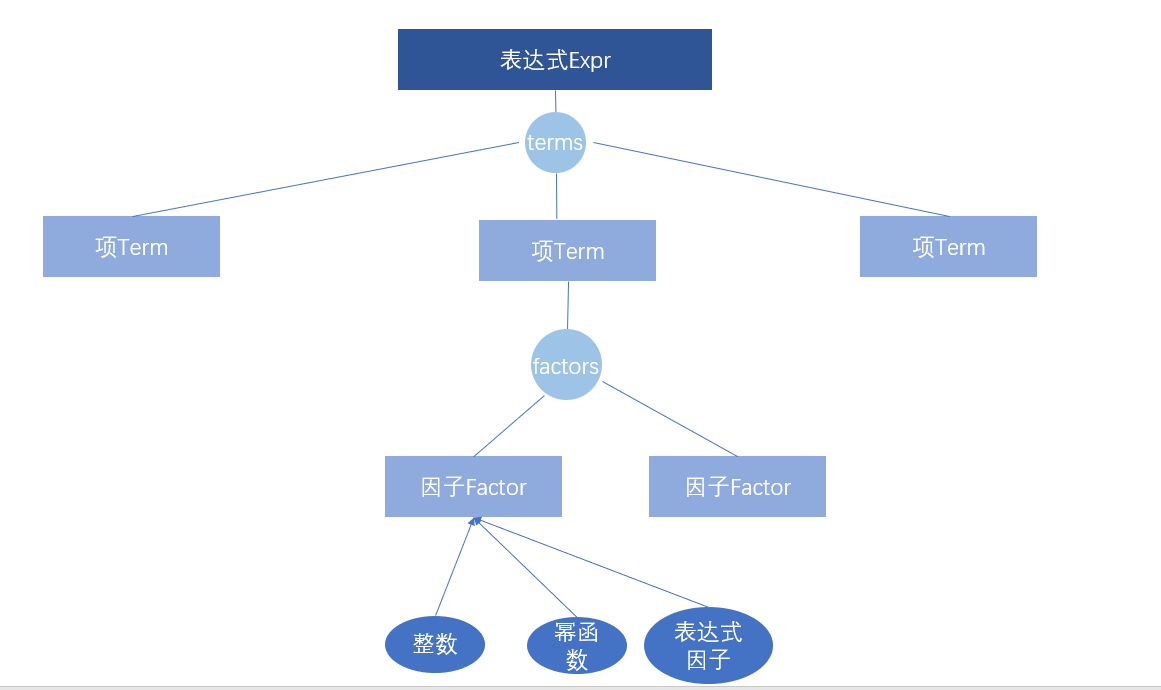
1.1 表达式树
根据第一次作业所给的形式化表述,得到表达式树。
1.2 设计思路
借助第一单元的训练,采用了递归下降的模式。
1.2.1 Lexer类
用于读取待化简表达式的每一个“单元”,这些“单元”包括‘整数’、‘(’、‘)’、‘+’、‘-’、‘x’、‘*’、‘**’
其中,特别注意‘*’和‘**’的读取
另外,还要对待化简表达式进行一些预处理:
- 空白符的存在 ->
replaceAll("\\s",""); - 整数允许有前导零 -> 删除,注意整数‘0’
- 连续多个‘+’和‘-’ -> 循环合并至仅以个‘+’或‘-’
1.2.2 Parser类
采用递归下降的方法,依次解析表达式、项、因子。正是因为使用了递归,所以在第一次就足以支持括号嵌套的要求。(一点也不虚)
1.2.3 Expr、Numvar、Term类
因为第一次作业只涉及幂函数和整数,于是可以将其合并为一个类Numvar,基本单元为a*x**b
(这一个想法,在后续的迭代过程中其实很有用处,但是笔者忙于“交差”,没有多加考虑,导致第二三次作业对于这样的类的提取并不明确)
由于基本单元比较简单,以及指数的限制,笔者选用HashMap<Interger,BigInteger>来存放term以及expr。
1.3 优化
第一次作业的优化很简单,合并同类项只需要考虑系数和指数。
细节上的优化:
- 保证首项系数尽可能为正
- x**2 优化为 x*x
1.4 UML

1.5 程序结构分析
类复杂度
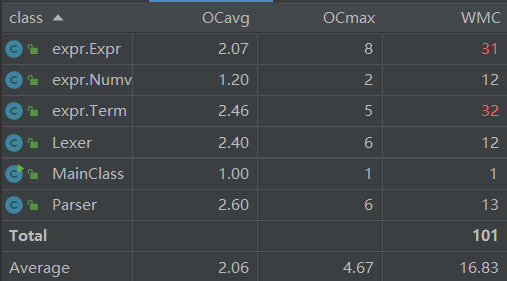
可以发现,expr包中的Expr类和Term类复杂度过高,主要原因是方法的冗余。
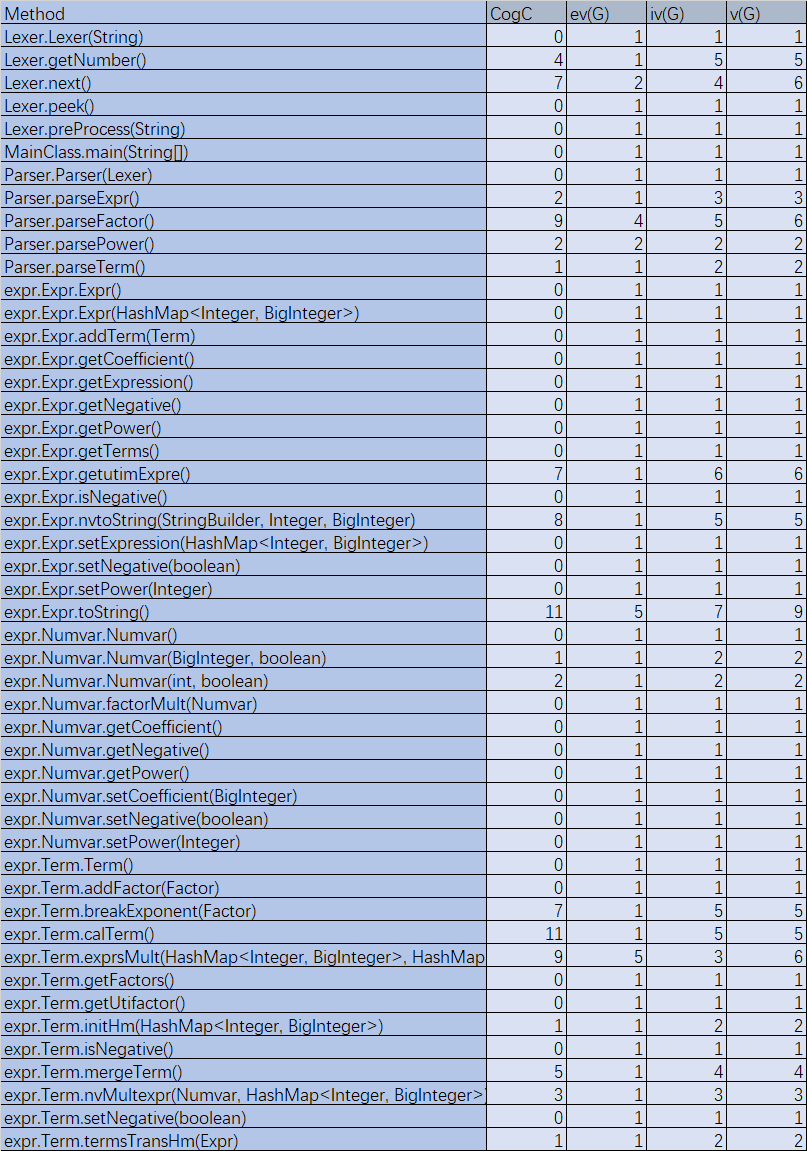
方法复杂度
1.6 第一次作业感受和反思
感受: 由于之前的pre没有做完,所以作业发布后的前三天都在做pre,直到周四才开始写作业1,突出一个没有思绪,时间紧张。借助官方所给的递归下降的思想,中途卡在了带指数的表达式因子去括号上,也是因为没有想清楚Expr类中哪一个属性才是需要处理的。最后在同学和gyy学长的帮助下,周六上午搭完架构,下午开始debug,最后压线提交通过中测。
反思:
- 对java语法不够熟悉,实现了一些本不需要的方法
- 在封装方面做的并不好,代码臃肿难读,耦合度高;
- 因为指数被限制在了8以内,所以在处理乘法时,直接判断下标是否大于8跳出循环,无法处理指数大于8的情形。后来知道迭代器更好用,但也没有去修改方法(因为耦合度高,一处修改多处报错)
- 递归下降的架构对后续作业的迭代很有帮助,但是自己写的类中处理表达式的方法几乎无法迭代,甚至于想要支持指数大于8便要大改。
2. 第二次作业
2.1 表达式树
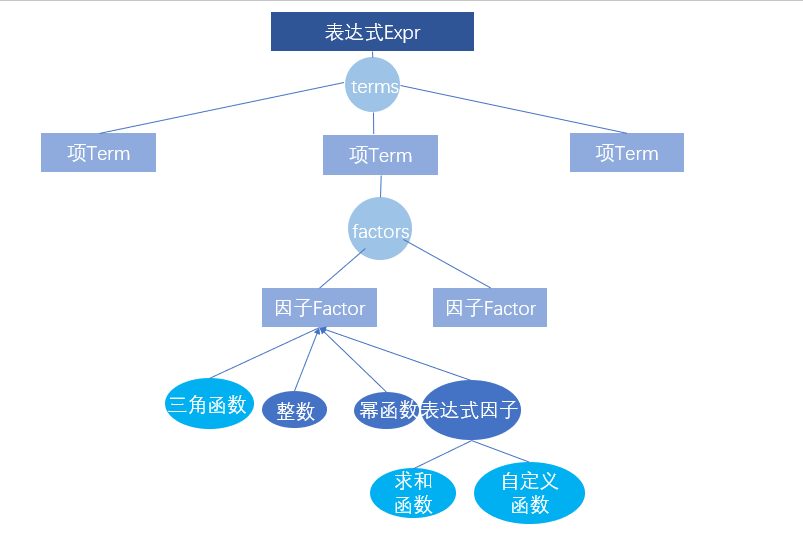
2.2 设计思路
可以看到,相较于第一次作业,增加了三角函数、自定义函数和求和函数。笔者把三角函数添加到因子类中,但把自定义函数和求和函数归为表达式因子(即暴力替换字符串的想法)。
2.2.1 迭代
2.2.1.1 Lexer类
需要读取的“单元”增加了‘=’、‘f’、‘g’、‘h’、‘sin’、‘cos’、‘sum’
注意事项:
1.‘sin’、‘cos’、‘sum’的读取应使用正则匹配而不能直接判断第一个字母是‘s’或‘c’(显然会出问题)
2.读取“单元”后,pos应该增加多少,以保证lexer.next()的语义正确
2.2.1.2 Parser类
第二次作业除了需要解析整数和幂函数,还增加了三角函数、自定义函数和求和函数。笔者的迭代思路是先增加对三角函数的解析,然后一并增加自定义函数和求和函数,思考如下:
- 三角函数的因子只可能是常数因子或者变量因子,最容易实现
- 三角函数不依赖于自定义函数和求和函数,但后者在表达式中会出现三角函数
- 笔者在处理自定义函数和求和函数的化简时,采用字符串暴力替换,最后返回一个表达式因子,所以在处理这两个因子的时候只需要递归调用parseExpr()。
注意事项:暴力替换时,需要用括号把实参或者‘i’的值括起来,让它们作为表达式因子替换到字符串中,否则会有诸如2**2的bug
2.2.2 重构
对expr包几乎所有类的方法、属性进行了重构。
重构Expr、Term、ConPowFactor,新增TrigFunc、Mono、SelfDefFunc、SumFunc类
Factor接口虚实现isEquals()和toString()
Mono类
新增的这个类与第一次作业中的Numvar类作用相同,用来表示基本单元,本次作业的基本单元的形式为a*x**b*Πsin(factor)**c*Πcos(factor)**d
在Mono类中实现了multTrig()等方法,用于合并因子、合并项,意在封装。
SelfDefFunc和SumFunc类
自定义函数和求和函数的处理方法大同小异,这里只介绍有关自定义函数的处理。
第二次作业中,笔者为自定义函数类定义的属性如下:
private String name; // f, g, h
private ArrayList<String> formalParas = new ArrayList<>(3); // 存放形参
private String exprFunc; // 函数表达式(定义
private ArrayList<Factor> arguments = new ArrayList<>(); // 存放实参
private boolean negative = false;
针对于多次调用一个函数的情况,每次调用函数的时候,都要清空arguments容器。
(因为第二次作业不存在函数作为实参的情况,所以这里将实参放在函数类里面没有问题,但是到第三次作业的时候会出bug。)
最后调用funCall()暴力替换字符串返回表达式因子
注意事项:要先替换x,再替换y、z;替换时给实参加括号,避免类似1**1等情况
Term、Expr、ConPowFactor、TrigFunc类
(ConPowFunc就是第一次作业中的Numvar,做到中途的时候意识到“基本单元”的重要性,然后新加的Mono类,所以依然保留了ComPowFunc这类)
重构了合并factor和term的方法,放弃使用HashMap,直接使用Arraylist存放基本单元。
在化简表达式的时候,尤其需要注意对象可不可变,能不能变,要根据情况使用深克隆,最好的办法应该还是直接改成不可变对象。
2.3 优化
印象中是做了sin(0)和cos(0)的优化。但是强测还是在这上面扣了性能分
然后是最简单的平方和优化成1,以及第一次作业的优化。
2.4 UML

2.5 程序结构设计
类复杂度
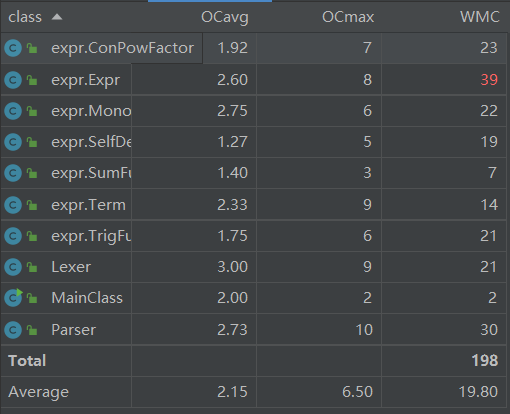
这一次Expr复杂度仍然很高
方法复杂度
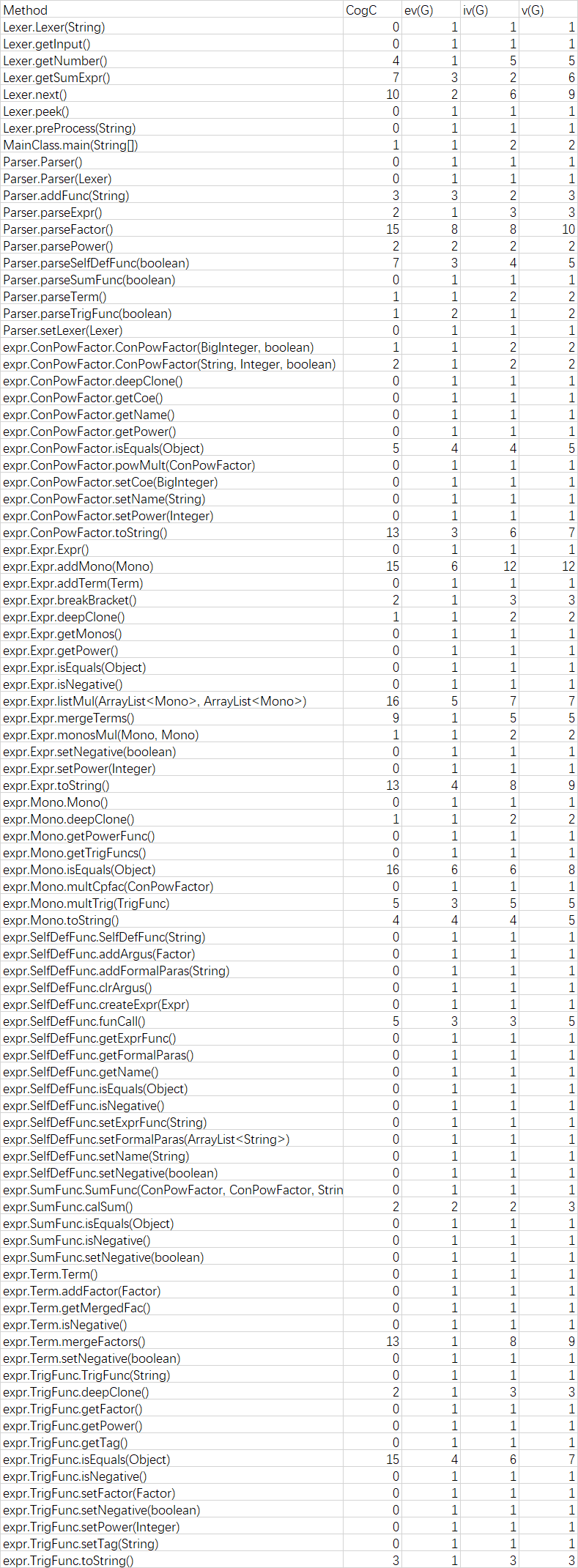
2.6 第二次作业总结
重构最难的部分还是在于多个因子相乘的合并,然后就是要找出基本单元。
这一次作业有意识地进行了一些方法的封装,但是因为没有使用助教建议的“用表达式树的形式解析函数,然后再进行实参的替换”这一方法,而采用暴力替换字符串,导致代码的耦合度仍然较高(但是不难理解)。
3. 第三次作业
第三次作业的要求只是在第二次作业的基础上放宽了限制,所以只需要进行些小的修改,迭代即可。
3.1 迭代
基本上把所有的parseFactor()方法替换成parseExpr()就可以完成大部分要求,比如三角函数的嵌套、自定义函数的调用。这样子替换之后,会产生一个臭虫,如下:
// 第二次作业
// Parser 中调用 parseSelfDefFunc() 部分代码
func.clrArgus();
lexer.next(); // lexer.peek() = "("
lexer.next();
while (!lexer.peek().equals(")")) {
if (!lexer.peek().equals(",")) {
func.addArgus(parseFactor()); // 幂、三角、常因, bug!!!
}
else {
lexer.next();
}
}
问题出现在,递归调用同一函数的时候,不同层次的函数实参被放在了同一个容器中,导致遍历实参的时候访问越界,处理方法为把实参从SelfDefFunc类中拿出来。修正如下:
// 第三次作业
// Parser 中调用 parseSelfDefFunc() 部分代码
ArrayList<Factor> arguments = new ArrayList<>();
lexer.next(); // lexer.peek() = "("
lexer.next();
while (!lexer.peek().equals(")")) {
if (!lexer.peek().equals(",")) {
arguments.add(parseFactor());
}
else {
lexer.next();
}
} // lexer.peek() = ")"
由此实现了函数的递归调用。
3.2 优化
实现了sin(0)和cos(0)的优化
后来又做了三角函数提取负号的优化,但是由于时间关系,加上自动化测试检测出问题,就没有提交,丢了几个强测点的性能分。
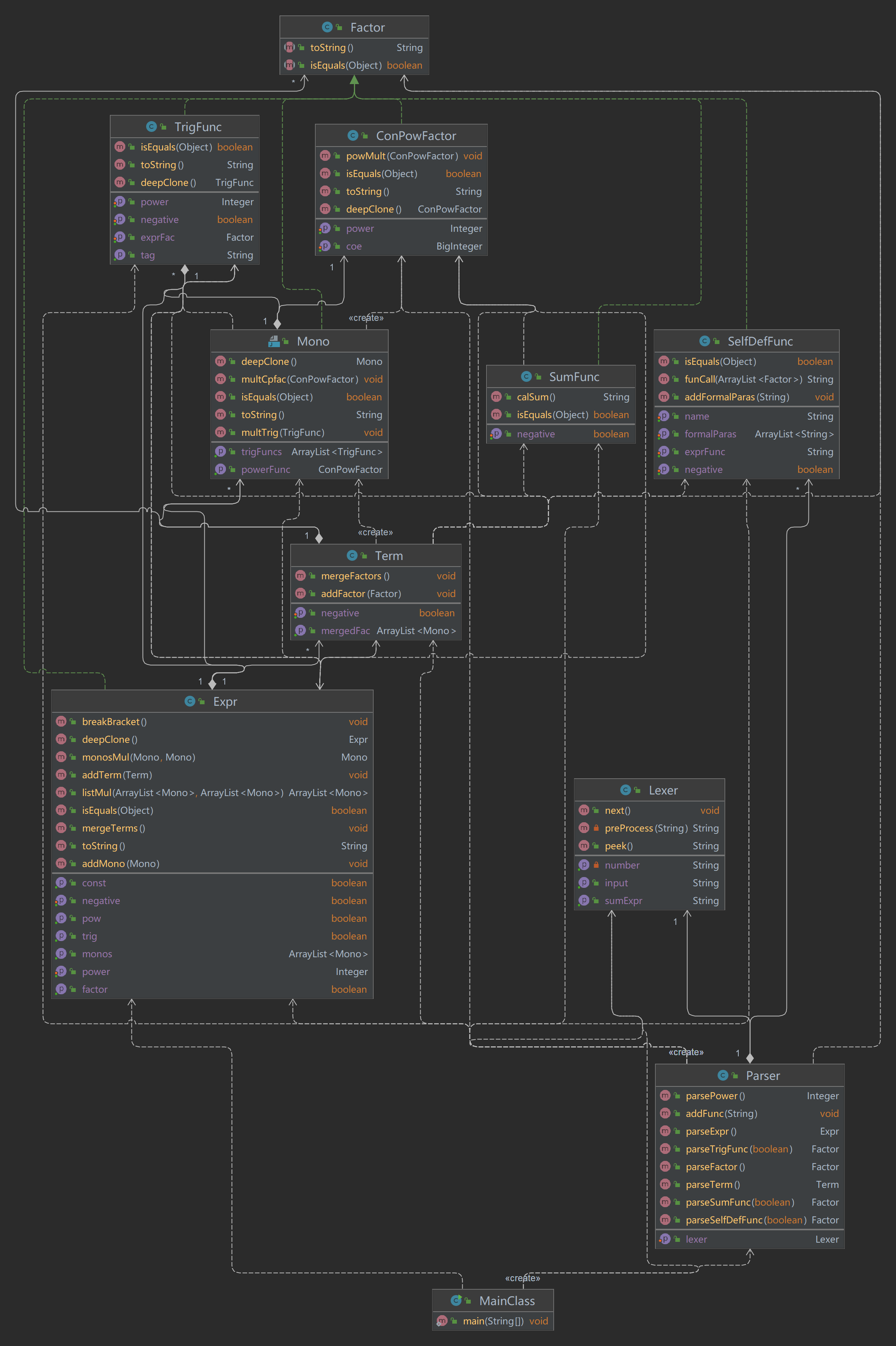
3.3 UML
与第二次作业几乎一样,然后觉得idea生成的uml真好看,就想贴这张图(虽然更复杂一点,但是自己画的太吃藕了)
3.4 程序结构分析
类复杂度
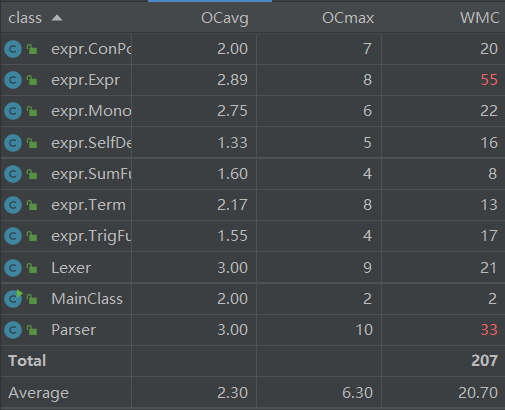
方法复杂度
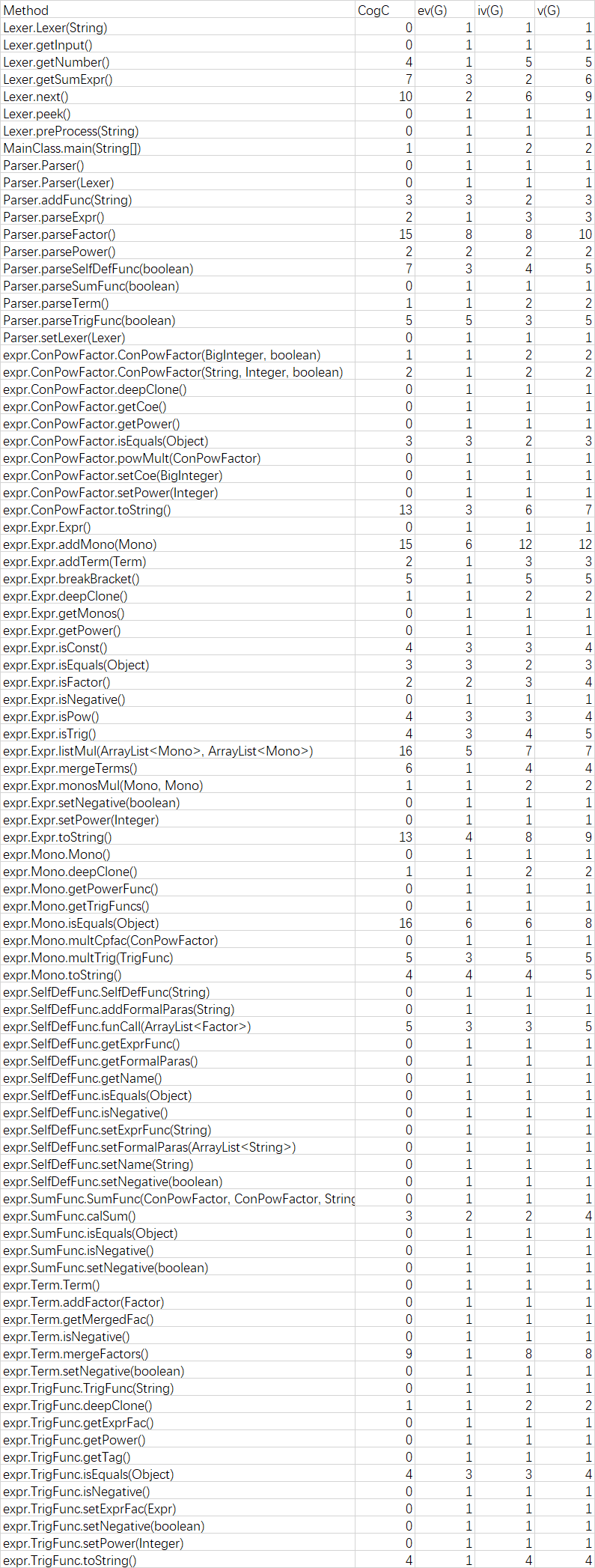
3.5 第三次作业总结
本来第二次暴力处理自定义函数和求和函数的时候,以为第三次又要重构了,在处理sum函数的时候,由于暴力替换表达式里面的i,如果有sum嵌套在里面的话,暴力替换就行不通了。
这次作业因为是在第二次作业基础上迭代,所以没有花很多时间就过了中测,之后一直在用自动化评测,没有手造边界数据,也导致没有考虑到sum的上下界超过int的情况。互测被干烂了
4.第一单元总结
4.1 互测
使用自动化评测,对自己以及其他人的代码进行评测,只能测功能的实现是否有大的漏洞,无法发现由边界数据引发的bug。
自己的bug:前两次作业都没有发现bug,第三次作业的bug就是sum函数里面上下界应该用BigInteger而不是Integer。不过,第二次作业并没有对sum的上下界有数据限制,所以第二次作业没被找出bug。
别人的bug:第一次作业找到一个bug,应该是多项式相乘出现问题了;后两次作业遇到同一个bug——无脑去掉1*,还有在处理三角函数时,sin(X**10)等处理不当。
4.2 总体感受
收获: 快速掌握了java的基本语法,学习了继承、接口、多态等知识。
不足:
- 在设计架构上,还未完全从面向过程转到面向对象,无论是封装还是方法的复杂度,由很大的进步空间。
- 对于java的语法特性熟练度不够

 浙公网安备 33010602011771号
浙公网安备 33010602011771号