Java 集合框架之Collection,一文解决
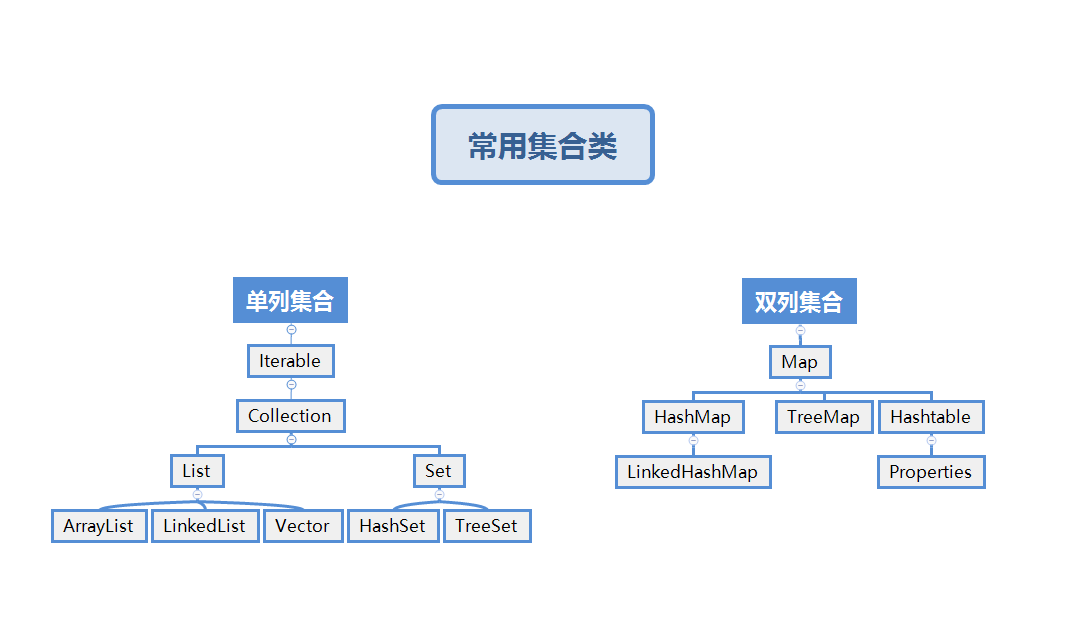
JDK提供了一些特殊的类,这些类可以存储任意类型的对象,并且长度可变,在Java中这些被称为集合。按照存储结构可以分为两大类,单列集合Collection和双列集合
常用集合类如下
Collection
Collection为单列集合类的跟接口,用于存储一些列符合某种规则的元素。有三个重要的子接口,分别是List和Set以及Queue。
List特点是有序、可重复;Set特点是元素无序且不可重复。List接口的主要实现类有ArrayList和LinkList;Set接口的主要实现类有HashSet和TreeSet
|
方法声明 |
描述 |
|
boolean add(Object o) |
向集合添加一个元素 |
|
boolean addAll(Collection c) |
将指定的Collection中所有元素添加到该集合中 |
|
void clear |
删除该集合中的所有元素 |
|
boolean remove(Object o) |
删除该集合中的指定元素 |
|
boolean removeALL(Collection c) |
删除该集合中所有元素 |
|
boolean isEmpty() |
判断集合是否为空 |
|
boolean contains(Object o) |
判断集合是否包含某个元素 |
|
boolean containsAll(Collection c) |
判断该集合是否包含某个集合中的所有元素 |
|
Iterator iterator() |
返回在该集合的元素上进行迭代的迭代器,用于遍历该集合的所有元素 |
|
int size() |
获取该集合的元素个数 |
List
List集合特点:线性存储,有序,可重复的;并且List集合的每个元素都有其对应的顺序索引,即支持索引,索引从0开始。
list不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法。
|
void add(int index, Object element) |
将元素element插入到List集合的index处 |
|
void addAll(int index, Collection c) |
将集合c所包含的所有元素插入到List集合的index处 |
|
Object get(int index) |
返回集合索引index处的元素 |
|
Object remove(int index) |
删除index索引处的元素 |
|
Object set(int index, Object element) |
将索引index处的元素替换为element对象,并将替换后的元素返回 |
|
int indexOf(Object o) |
返回对象o在List集合中出现的位置索引 |
|
int lastIndexOf(Object o) |
返回对象o在List集合中最后一次出现的位置索引 |
|
List subList(int fromIndex, int toIndex) |
返回从索引fromIndex(包括)到toIndex(不包括)处所有元素组成的子集合 |
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Demo01 {
public static void main(String[] args) {
List list = new ArrayList();//这里定义时没有指定存储类型如List<String> list = new ArrayList<>();默认可以存储任意类型,如果表明String,那么就只能存储String
list.add("xml");
list.add(123);
list.add('a');
System.out.println(list);
Iterator iterator = list.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
for (Object obj : list){
System.out.println(obj);
}
System.out.println(list.toArray());
}
}
ArrayList
ArrayList是List接口的一个实现类,也是程序中一种最常见的集合。
- ArrayList可以存放null值并且可以存放多个
- ArrayList底层使用数组实现的
- ArrayList扩容机制:
- ArrayList中维护了一个Object类型的数组elementData
- 当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第一次添加,则扩容为10;如果需要再次扩容,则扩容大小为elementData的1.5倍
- 如果使用指定大小的构造器,则初始容量为指定的大小,再次扩容则为elementData的1.5倍
- https://blog.csdn.net/weixin_42621338/article/details/82080167?spm=1001.2014.3001.5502
- ArrayList是线程不安全的,不过执行效率高。多线程下,不建议使用该集合。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Demo01 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("xml");
list.add(123);
list.add('a');
list.add("xml");
System.out.println(list);
Iterator iterator = list.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
for (Object obj : list){
System.out.println(obj);
}
System.out.println(list.toArray());
}
}
LinkedList
LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度较慢。
另外,它还提供了List接口没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用(Java中使用的双向链表)
- LinkedList底层实现了双向链表和双端队列的特点
- LinkedList底层维护了一个双向链表
- LinkedList中维护了两个属性first和last,分别指向首节点和尾节点
- 每个节点里面维护了prev、next、item三个属性;prev:指向前一个、通过next指向后一个节点,最终实现双向链表
- LinkedList中元素的添加或删除,不是通过数组实现的,效率相对较高
- 可以任意添加元素,元素可重复、可为null
- 线程不是安全的,没有实现同步
|
方法声明 |
描述 |
|
void add(int index, E element) |
指定位置插入指定元素 |
|
void addFirst(Object o) |
将指定元素插入列表开头 |
|
void addLast(Object o) |
将指定元素插入列表结尾 |
|
Object getFirst() |
返回列表的第一个元素 |
|
Object getLast() |
返回列表的最后一个元素 |
|
Object removeFirst() |
移除并且返回列表的第一个元素 |
|
Object removeLast() |
移除并且返回列表的最后一个元素 |
import java.util.*;
public class Demo01 {
public static void main(String[] args) {
LinkedList link = new LinkedList();
link.add("xml");
link.add(123);
link.add('y');
System.out.println(link);
link.addFirst("xml");
link.addLast("ywj");
System.out.println(link);
link.remove("xml");//如果有重复元素,只能移除第一个出现的
System.out.println(link);
link.remove(3);//移除指定索引的元素
System.out.println(link);
Object obj = link.removeFirst();
System.out.println(obj + " " + link);//移除开头的元素
}
}
ArrayList和LinkedList比较
|
底层结构 |
增删效率 |
改查的效率 |
|
|
ArrayList |
可变数组 |
较低,通过数组扩容 |
较高,不需要改变数组 |
|
LinkedList |
双向链表 |
较高,通过链表追加 |
较低,需要通过node一个个遍历找到后操作 |
如何选择?
- 如果改查操作较多,选择ArrayList
- 如果增删操作较多,选择LinkedList
- 一般来说在程序中大多数都是查询,因此大部分情况下会选择ArrayList
- 不适合用于多线程,LinkedList和ArrayList的线程不是安全的
Vector(不推荐使用)
Vector与ArrayList一样也是通过数组实现的,不过不同的是它支持线程的同步,即在某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要的花费很高,因此访问它比访问ArrayList慢。
vector特点:
- 有序的,可以存储重复值和null值
- 底层是数组实现的,线程安全。结构和ArrayList非常相似,同样是一个线性的动态可扩容数组
- 初始容量是10,没有设置扩容增量的情况下以自身的2倍容量扩容;可以设置容量增量,初始容量和扩容两可以通过构造函数
public Vetor(int initialCapacity, int capacityIncrement)进行初始化
查看Vector源码,和ArrayList几乎一模一样,区别就是Vector的方法使用了synchronized锁实现了线程安全
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--elementCount] = null; // Let gc do its work
return oldValue;
}
那为什么很少见到使用Vector呢?
- 因为Vector虽然线程安全,但是每个可能出现线程安全的方法上加上了
synchronized关键字,所以效率低。但是其实并没有很好的解决线程安全问题,比如下面这段代码,在判断是否包含某元素后会释放锁,在不包含的情况下,执行add之前,锁很有可能会被抢占
if (!vector.contains(element))
vector.add(element);
}
- Vector空间满了以后扩容是一倍,而ArrayList仅是一半。如果数据太多可能会导致内存分配失败
- 只能在尾部进行插入和删除,效率较低
- 现在已经有了更好的替代品
CopyOnWriteArrayList
Set
Set是无序且值不重复的Collection。无序依赖于对象是否相等的判断,对象相等的本质是对象hashcode值判断的,如果想让两个不同的对象视为相等的,就必须覆盖Object的hashcode和equals方法。
HashSet
HashSet的哈希表边存放的是哈希值。HashSet存储元素的顺序并不是按照存入时的顺序(和List不相同),而是按照哈希值来存的所以取数据也是按照哈希值取。
元素的哈希值是通过元素的hashcode方法来获取,HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法,如果equals结果为true,HashSet就视为一个元素。如果equals为false就不是同一个元素。HashSet通过hashCode值来确定元素在内存中的位置。因此一个hashCode位置上可以存放多个元素。
import java.util.*;
public class Demo01 {
public static void main(String[] args) {
Set set = new HashSet();
set.add("xml");
set.add('0');
set.add("xml");
set.add(1);
set.add(null);
set.add(2);
Iterator iterator = set.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
}
}
TreeSet
TreeSet是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入到二叉树指定的位置。
Integer和String对象都可以进行默认的TreeSet排序,而自定义的对象是不可以的,自己定义的类必须实现Comparable接口,并且覆盖写对应的compareTo()函数,才可以正常使用。在覆盖写compare()函数时,要返回相应的值才能使TreeSet按照一定的规则来排序,比较此对象和指定对象的顺序,如果该对象小于、等于或者大于指定对象,则返回负整数、零或正整数。
不过treeset存储的对象必须是同类型的对象,而且存储的类型必须实现了Comparable接口。如果没有实现该接口,那么add进入集合时进行元素大小比较的时候,调用comparableTo方法时会报错ClassCastException异常
import java.util.*;
public class Demo01 {
public static void main(String[] args) {
Set set = new TreeSet();
set.add("xml");
set.add("ywj");
set.add("xml");
//set.add(null); 这里报错java.lang.NullPointerException,是不允许null值的
set.add("test");
Iterator iterator = set.iterator();
while (iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
}
}
Iterator
Iterator主要用于迭代访问Collection中的元素,因此Iterator对象也被称为迭代器。案例如上面写的demo。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号