软工实践寒假作业(2/2)
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践 W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) 作业要求 |
| 这个作业的目标 | 阅读《构建之法》并提问、学习使用git以及github、编写程序使用PSP进行时间管理和总结、学会进行单元测试和性能优化 |
| 其他参考文献 | 邹欣老师的博客园讲义 |
任务一:阅读《构建之法》并提问
阅读《构建之法》并提问
一、我看了第三章结对编程中的这一段文字:
“在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。”
于我而言,之前参加团队项目时,在完成自己分工部分工作后,有去还未完成同学那帮忙,当时就是采用类似结对编程的方式,一人编写代码,一人检查代码手代码的逻辑、语法有无出错,并提示下一步骤。我认为在进行同一模块时,按照书本中所说结对编程确实能提高代码的质量和效率,但是感觉在实际中还是可能会出现以下问题:
1、当还有很多模块需要完成时,相比同一个模块由两个人负责,是否两人负责不同的模块效率会更高?
2、在结对编程的过程中,领航员若存在不理解驾驶员的代码时,又如何做到领航?若领航员无法起到领航的作用,那结对编程又有何意义?
我查了资料
工程师结对编程能否大幅提高工作效率?
国内为何很少有人做结对编程呢?是确实不好还是属于中国特色?
这些文章中提到:
“ 结对编程有以下优点:
1,代码质量提升巨大(不好意思写烂代码啊!)
2,开发速度提升巨大(两个人的知识和智慧联合)
3,分工明确,"心流"不易被打断(一人敲键盘一人查手册,或应付其他琐碎事)
4,可以互相学习,没有什么比看别人工作更能让自己提高的了。但结对需要条件,尤其是对程序员素质要求较高。”
“ 对结对人员的条件如下:
1,水平相当接近,不然容易造成心理不适
2,使用工具集一致,一个vi一个emacs光打架了不干活了
3,对编程的品味和态度一致,不要为了一些各有所好的东西争论
4,不一定是很好的朋友,但至少互相尊重”
这些经验能给解决以上问题很大帮助,确实,两个人的知识和智慧联合,相互监督,一定程度上可以提升代码质量、提升开发速度,但是我还是存在有以下疑惑:
对于结对人员的要求条件实际上是非常严苛的,而且还存在很多工程师不喜欢交流、不习惯结对的情况,针对于此,结对编程是否是必要的?在公司里面,怎么判断什么工作需要结对?什么组合可以结对?
二、我看了第四章关于明星模式的这一段文字:
“主治医师模式运用到极点, 可以蜕化为明星模式, 在这里明星的光芒盖过了团队其他人, 前一阵子喧嚣一时的“翔之队”就是一个例子。明星也是人, 也会受伤, 犯错误, 如何让团队的利益最大化, 而不是明星的利益最大化?”
于我而言,之前大一参加团队项目时,当时我的编程能力还是比较弱的,队里有个大佬,能力比较强。于是在整个项目过程中,我基本上就处于所谓“躺”的状态,大多数工作都是由那个大佬完成的,但可能对整个项目的完成而言,完全由大佬来完成的话,质量和效率可能比分工还高 /(ㄒoㄒ)/~~。以这段经历为例来说,在类似这种情况下,明星的利益最大化的同时就是团队的利益最大化的时候,这时是应该把资源全分配给明星,突出强调明星模式的优点,还是把资源兼顾给每个人?
我查了资料
几种常见的软件团队模式优缺点总结
文章中提到:
“ 2.主治医师模式:
优点:初衷很好,一个软件团队中,有首席程序员,负责主要模块的设计和编码,其他人尽可能从各个方面支持他的工作
缺点:在一些学校的软工课上,这种模式逐渐退化成“一个学生干活,其他学生打酱油”
3.明星模式:主治医师模式运用到极点
优点:对“明星”个人的成长进步可能会有所帮助
缺点:团队模式强调的是团队的作用,而不是个人的独角戏,这种模式显然违背了团队模式的初衷,效率也很低”
这些经验能给解决以上问题很大帮助,确实,明星模式说到底还是团队模式,对于团队模式而言,团队才是核心,但是我还是存在有疑惑:有的情况下,如果以纯明星为核心的情况下,团队利益可以最大化,此时怎么进行明星和其他成员的利益取舍的度量?
三、我看了第四章敏捷方法中的这一段文字:
“Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage 翻译:敏捷流程欢迎需求的变化, 并利用这种变化来提高用户的竞争优势。 ”
产品、策划需求频繁变更,这经常发生,却实在是令人头皮发麻。以我个人的理解,敏捷开发作为一种应对快速变化的需求的一种软件开发能力,通过快速迭代的方法来适应需求变化的原理,但是,对于那些已经实现完成的需求的变化,
应该是无条件接受吗?或者说对于需求变化的欢迎的极限应该在哪里?该怎么样去度量呢?
我查了资料
你如何理解敏捷开发?
文章中提到:
“在敏捷开发中,每个新特性必须有独立的测试。每个生产环境的变更必须通过严格的测试测试(在CD中通过单元测试、集成测试、性能测试等)。在不影响其他部分、不影响大版本规划的前提下,各个部分可以按需部署,用于快速响应游客的诉求、修复缺陷。 ”
这些经验能给解决以上问题很大帮助。对于需求变化是否接受,那应该说满足用户要求是相对的而不是绝对,因为每个客户的需求都不一样,在相对程度上尽量满足客户的需求。同时,产品、策划需求频繁变更不可避免,但是响应游客的诉求、修复缺陷可以不必一蹴而就,可以通过完成各个部分,循序渐进,一定程度上减小其造成的影响。
四、我看了第六章用户调研中的这一段文字:
“Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage 翻译:敏捷流程欢迎需求的变化, 并利用这种变化来提高用户的竞争优势。 ”
以我个人的理解,之前进行认知实习课程时,调查数据时就有用到问卷这一手段,但是当时遇到有的人填写时心不在焉,乱点一气,全选A、B等情况的发生,这对于后续的数据分析和得出结论会造成很大的影响。以这段经历为例来说,作为一名程序员,在开发软件的时候,想知道用户到底想的是什么,但是收集到这种乱填的无效的甚至有误导性的数据,该怎么合理的处理这些数据?
我查了资料
遇到乱写调查问卷的人怎么办?
文章中提到:
“筛选无效问卷是必要的一个工作,有一个筛选标准,筛选掉就好了。至于从根本上解决问题,除非你控制他们的思想……”
“调查过程中会有很多这种人,所以我们在收集完已经填完的问卷中,还要进行筛选。”
这些经验能给解决以上问题很大帮助。确实,乱填问卷这种情况不可避免,但是可以通过如设计陷阱题的方法解决,一定程度上减小其造成的影响,同时,对于收集进来的数据,要设计一定具体方法来进行筛选,从而使得数据准确性得以提高。
五、我看了第九章创新的出路 - 走进作坊中的这一段文字:
“作坊这么好, 那中国的许多作坊为什么不能兴旺? 一个大家常说的重要原因, 就是 “环境对知识产权的尊重和保护不够”, 其实哪里都有盗版, 哪里都有抄袭, 哪里都有竞争。有能力的作坊, 往往找到合适的渠道, 合适的空间, 实现自己的价值。 ”
提出这个问题,是感觉这段话与我的理解有所偏差。自己辛辛苦苦开发数载的软件,结果被别人恶意抄袭,恶意盗版,又或者刚有起色被某些垄断性大互联网企业要求收并或者盗用创意,以小工作室来说,无论是公关、宣传能力和研发水平,肯定是没法和这些大公司相比,在市场上与之竞争,生存空间必然会被挤压。“有能力的作坊, 往往找到合适的渠道, 合适的空间, 实现自己的价值。”这种话,相对而言,也太理想化了。同时,在这种情况下,小工作室到底该何去何从?
我查了资料
为什么多有小工作室被大公司收购后最终解散,如何看这个现象?
你如何避免软件被抄袭,包括它的商业模式?
文章中提到:
“被收购是小的工作室资本化的唯一途径。也别太高估了他们的盈利能力,不然干嘛卖身大厂呢,很可能就死亡和苟活的选择。有些人资本化了拿到钱就不好好做东西了,也别都算在大厂头上。玩家跟从业人员之间有一条巨大的鸿沟,就是对游戏成本认知的差异,基本上是6倍的关系... 按某些玩家的思路,大家都只能选择死亡了”
“不恰当的比方,跟买股票一个道理:表现好就长期持有,表现不好就抛掉止损。游戏研发商最大的特点是不管之前产品多么成功,不保证之后产品一定大麦。所以,可把控的只有这几项:
1.IP强不强
2.渠道质量高不高
3.量够不够
4.能不能搭边儿强势品牌
5.事件营销玩得6不6
6.配套运营有没有亮点(视频、电影微电影、直播、社区、赛事)很可惜,一旦被收购,这些都tm不是研发团队能管的。Sigh。”
“说实话这个事情很难: 我们国家的巨头可以通过很多手段让你的软件废掉 例如腾讯就可以依靠它强大的社交软件垄断,封锁你的软件,然后推出它的。。。。这个最有名的还是微软,扶持你的竞争对手来打压你等。。。就目前中国的局势来看,很难不被巨头所左右,真的还不如将版权或者软件做好了卖给那些巨头,特别是在最成功的时候”
这些经验能给解决以上问题很大帮助。确实,软件被恶意抄袭、盗用,这是可能发生的存在,作为一名工程师,在涉及到专利,著作权的,一定要提前做好专利申请,原创保护。信息化爆炸的时代,垄断问题再所难免,真正遇上了就仁者见仁,智者见智,做出对自己最有利的选择,相信随着国家法律的完善,此类问题也能一定程度上减少。
附加题
1、Guido van Rossum喜欢看喜剧团体Monty Python,所以发明了一个编程语言叫作Python。同样的,Python自带的那个IDE,IDLE名字来源于该团体的成员Eric Idle。此外,用来表示垃圾邮件的单词spam也是出自Monty Python这部作品,而这个单词在剧中指的是Spam品牌的午餐肉。
1987 - Larry Wall在电脑前打了个盹,Larry Wall的脑门子压到了键盘上。醒来之后,Larry Wall深信 ,在Larry Wall的显示器上出现的神秘字符串并非是随机的,那是某种编程语言之程序样例的神谕。那必是上帝要他的先知,Larry Wall,去设计的。Perl语言就此诞生了。
对此我不禁感叹,这些程序员在命名这一点上可真是随心啊,我也要这样(虽然不太可能)。
任务二:
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 750 | 1190 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 30 | 50 |
| • Coding | • 具体编码 | 300 | 360 |
| • Code Review | • 代码复审 | 120 | 300 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 180 | 300 |
| Reporting | 报告 | 100 | 130 |
| • Test Repor | • 测试报告 | 60 | 90 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 860 | 1330 |
解题思路描述
本题要求统计input.txt中的以下几个指标:
1、统计文件的字符数;
2、统计文件的单词总数;
3、统计文件的有效行数;
4、统计文件中各单词的出现次数;
一开始我是打算使用正则表达式的,但是发现出现某些特殊情况(如'\nabc\n'),处理起来也很麻烦,于是乎,我就选择自己一步一步来处理单词了。
对于统计字符数,是最简单的功能,每次通过流从文件中读出一个字符,遇到特殊字符数(如'\n'等)再进行特殊处理;
对于统计单词数,相比会比较复杂点,。通过设置状态位canbeword(每次增加,当最后大于四的时候成立)、canbetransferred(当上一个是‘\’,则可能是控制符)等,来处理一系列特殊情况。
对于统计行数,我也是通过设置状态位canbetransferred、linechcount,来处理一系列特殊情况。
对统计文件中各单词的出现次数,是打算(String)word和(int)frequency将存在hashMap中,在通过将hashMap排序,来输出前十的频率排序。
代码规范制定链接
设计与实现过程
接口类设计
class Lib {
int chcount; //字符总数
int wordcount; //单词总数
int linecount; //行总数
String finname;
String foutname;
Map<String, Integer > hashMap = new HashMap<String, Integer>();
characterCount();//字符统计
wordCount();//单词和行统计
wordOccMax();//单词出现最多频率
outFile(String fname, String str);//输出
字符统计characterCount();
canbetransferred用来处理可能为\n\r的情况,因为按照要求'\n'、'\r'在被读取进来时是连续两个字符,而我们每次只读一个字符。为了处理这种情况,于是当读入为'',进入(if 1),我们将canbetransferred设置为1,表示有可能出现'\n'、'\r'的情况,当下一次读入时,由于上一次canbetransferred被置为1,则进入(if 2),判断下一个是不是n或r再进行处理。
while ((i = br.read()) != -1) {
ch = (char)i;
chcount++; //字符统计
if ((i == 92)) { //(if 1)
canbetransferred = 1;
}
if (canbetransferred == 1) { //(if 2)
canbetransferred = 0;
if (ch == 'n' || ch == 'r') {
chcount--;
continue;
}
}
}
单词统计和行统计wordCount();
设置的一下状态符合思路。
int canbeword = 0; //当为0时遇到字母每次增加,前四个有非字母就置0,当最后大于四的时候说明前四个都是字母
int canbetransferred = 0;//可能为\n\r
int linechcount = 0; //统计每行字符,不为空字符则++,为空不能算一行
String tempword = ""; //存放临时字符串
因为仅在换行和出现分割符时,word数量才会相加,通过!Character.isLetter(ch) && !Character.isDigit(ch))判断ch是否为分割符,分下列两种情况:
一、ch为'',
1、判断tempword是否可为word(通过canbeword是否为4),若是则加入hashmap, 且wordcount++;2、将tempword、canbeword重置;3、将canbetransferred = 1;4、continue,进入下一层判断是否为'r'或'n' ;
二、ch不为''
1、判断tempword是否可为word(通过canbeword是否为4),若是则加入hashmap, 且wordcount++; 2、将tempword、canbeword重; 3、continue,进入下一层判断是否为'r'或'n'
换行统计主要代码
if (linechcount != 0) {
linecount++;
}
linechcount = 0;
前10单词出现最多频率wordOccMax()
思路与单词数统计差不多,当可为一个单词时,就存入hashMap。最后再统计。
存入HashMap的代码:
if (hashMap.containsKey(tempword)) {
Integer hvalue = ((Integer)hashMap.get(tempword))+1;
hashMap.put(tempword, hvalue);
}else {
hashMap.put(tempword, 1);
}
排序代码,先按value,value相同,再按key:
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
int re = o2.getValue().compareTo(o1.getValue()); //重写排序规则,小于0表示升序,大于0表示降序
if (re != 0) {
return re;
}else {
return o1.getKey().compareTo(o2.getKey());
}
}
运行结果示例:
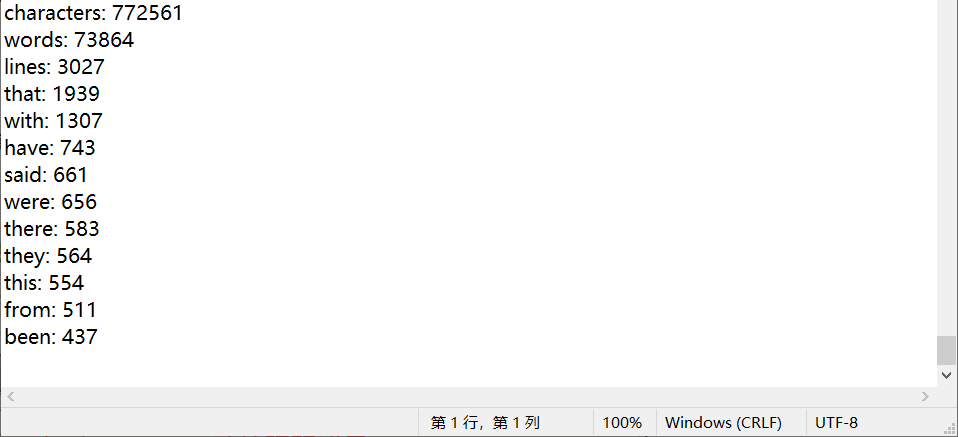
性能改进
1、使用HashMap为存储单词和频率的结构
一开始是想到要排序,就打算使用TreeMap, 因为TreeMap取出来的是排序后的键值对,如果要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。而我仔细想了想,其实比起排序,本次程序当单词数重复多时,插入的使用频率明显是更多的,但TreeMap在插入、删除需要维护平衡会牺牲效率,于是我就想到了用HashMap。
HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap是最好的选择。
用HashMap后,而且通过将HashMap转化为List,重新定义List的排序比较规则,对排序时间也有所缩短,运行代码速度有了一定的提升。
2、使用BufferedReader缓存流来读取字符
我一开始没有用BufferedReader,只是简单用输入输出流来读取,当遇到百万字符时,我直接好家伙,居然用了10s,于是我使用BufferedReader缓存流来读取字符,运行速度有质的飞跃。
100字符的文本运行:
程序运行时间: 7ms
100w字符的文本运行:
程序运行时间: 154ms
单元测试
单元测试主要用junit来实现的
字符数单元测试代码
@Test
public void testCharacterCount() {
lib = new Lib("C:\\ccc\\s5.txt","C:\\ccc\\s6.txt");
int result = lib.characterCount();
assertEquals(115, result);
}
单词数单元测试代码
@Test
public void testWordCount() {
lib = new Lib("C:\\ccc\\s5.txt","C:\\ccc\\s7.txt");
int result = lib.wordCount();
assertEquals(17, result);
}
单词出现频率单元测试代码
@Test
public void testWordOccMax() {
......
lib.wordOccMax();
try{
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("C:\\ccc\\s18.txt"), "UTF-8"));//构造一个BufferedReader类来读取文件
......
while ((s = br.readLine()) != null){//使用readLine方法,一次读一行
if(index >= strArray.length) { //读的比测试多
fail("Not yet implemented");
}
assertEquals(strArray[index],s);
index++;
}
if(index < strArray.length) { //读的比测试少
fail("Not yet implemented");
}
}
可以看到测试结果
进行多组数据测试
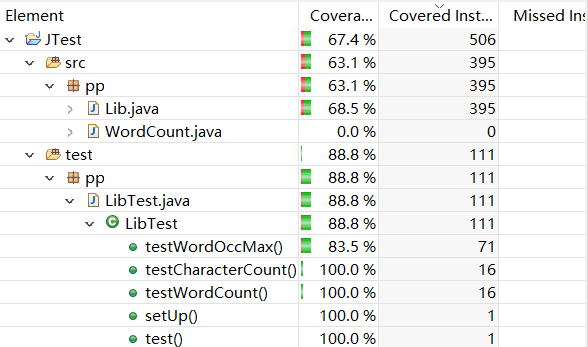
以下为代码覆盖率示例,其中WordCount代码覆盖率为0, 是因为所有功能实现都在Lib.java中,于是单元测试是针对Lib写的,当然这仅仅只是一个测试数据的覆盖率,更全面的测试数据的覆盖率更高。
如何提高代码覆盖率?
设置合理测试规则(数据),尽量全面覆盖。
异常处理说明
1、处理可能出现的数组越界情况,采用了ArrayIndexOutOfBoundsException进行异常处理。
2、处理可能出现的输入输出流问题,采用了IOException进行异常处理。
心路历程与收获
本次实验是软工实践第二次作业,主要内容是阅读《构建之法》并提问、学习使用git以及github、编写程序,使用PSP进行时间管理和总结、学会进行单元测试和性能优化。在完成此次实验的过程中,我锻炼了自己编写Java程序的能力,同时训练了自己的思维能力,熟悉了对Map类的理解,也是第一次尝试并学会去利用Junit等工具对程序进行单元测试,同时在不断的测试中更加意识到性能优化的重要性,最重要的是学会使用PSP进行时间管理和总结,以后我会好好利用今日所学知识,努力做到最好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号