10 期末大作业
补交 02Spark架构与运行流程 和 07 Spark RDD编程 综合实例 英文词频统计 作业
未交原因 发在随笔上忘记提交了
1.为什么要引入Yarn和Spark
1.部署Application和服务更加方便
只需要yarn服务,包括Spark,Storm在内的多种应用程序不要要自带服务,它们经由客户端提交后,由yarn提供的分布式缓存机制分发到各个计算节点上。
2.资源隔离机制
yarn只负责资源的管理和调度,完全由用户和自己决定在yarn集群上运行哪种服务和Applicatioin,所以在yarn上有可能同时运行多个同类的服务和Application。Yarn利用Cgroups实现资源的隔离,用户在开发新的服务或者Application时,不用担心资源隔离方面的问题。
3.资源弹性管理
Yarn可以通过队列的方式,管理同时运行在yarn集群种的多个服务,可根据不同类型的应用程序压力情况,调整对应的资源使用量,实现资源弹性管理。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
Spark生态圈即BDAS===》

Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
spark跟hadoop的比较:
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
3. 用图文描述你所理解的Spark运行架构,运行流程。
Spark运行架构及流程:

基本概念:
Application:用户编写的Spark应用程序。
Driver:Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:有向无环图,反映RDD之间的依赖关系。
Task:运行在Executor上的工作单元。
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
1) Standalon : spark原生的资源管理,由Master负责资源的分配
2) Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
3) Hadoop Yarn: 主要是指Yarn中的ResourceManager
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
Spark运行基本流程:
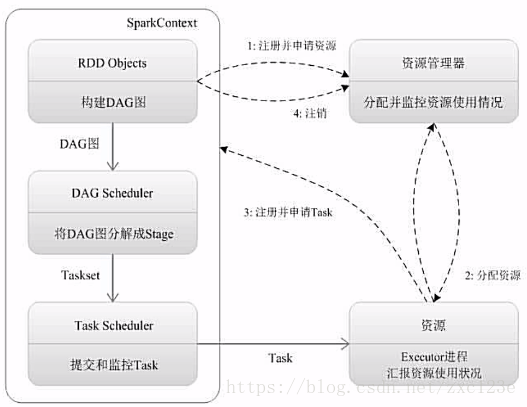
为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控
资源管理器为Executor分配资源,并启动Executor进程。
SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
1. 用Pyspark自主实现词频统计过程。
>>> s = txt.lower().split()
>>> dd = {}
>>> for word in s:
... if word not in dd:
... dd[word] = 1
... else:
... dd[word] = dic[word] + 1
...
>>> ss = sorted(dd.items(),key=operator.itemgetter(1),reverse=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'operator' is not defined
>>> import operator
>>> ss = sorted(dditems(),key=operator.itemgetter(1),reverse=True)
>>> print(ss)
[('the', 136), ('and', 111), ('of', 82), ('to', 71), ('our', 68), ('we', 59), ('that', 49), ('a', 46), ('is', 36), ('in', 26), ('this', 24), ('for', 23), ('are', 22), ('but', 20), ('--', 17), ('they', 17), ('on', 17), ('it', 17), ('will', 17), ('not', 16), ('have', 15), ('us', 14), ('has', 14), ('can', 13), ('with', 13), ('who', 13), ('be', 12), ('as', 11), ('or', 11), ('(applause.)', 11), ('those', 11), ('nation', 10), ('you', 10), ('their', 10), ('new', 9), ('these', 9), ('us,', 9), ('so', 8), ('by', 8), ('than', 8), ('must', 8), ('because', 8), ('what', 8), ('every', 8), ('all', 8), ('its', 8), ('been', 7), ('at', 7), ('when', 7), ('no', 6), ('less', 6), ('cannot', 6), ('let', 6), ('too', 6), ('common', 6), ('was', 5), ('time', 5), ('people', 5), ('only', 5), ('know', 5), ('nor', 5), ('now', 5), ('from', 5), ('seek', 4), ('work', 4), ('greater', 4), ('whether', 4), ('america', 4), ('more', 4), ('before', 4), ('power', 4), ('which', 4), ('long', 4), ('through', 4), ('men', 4), ('meet', 4), ('women', 4), ('journey', 3), ('up', 3), ('between', 3), ('were', 3), ('say', 3), ('where', 3), ('an', 3), ('god', 3), ('may', 3), ('last', 3), ('economy', 3), ('hard', 3), ('do', 3), ('today', 3), ('there', 3), ('founding', 3), ('hope', 3), ('crisis', 3), ('words', 3), ('carried', 3), ('them', 3), ('future', 3), ('come', 3), ('shall', 3), ('most', 3), ('generation', 3), ('day,', 3), ('you.', 3), ('things', 3), ('upon', 3), ('force', 3), ('i', 3), ('spirit', 3), ('just', 3), ('over', 3), ('father', 3), ('question', 3), ('your', 3), ('once', 3), ('across', 3), ('face', 2), ('better', 2), ('do,', 2), ('why', 2),
2. 并比较不同计算框架下编程的优缺点、适用的场景。
–Python
Python优缺点
优点
1、简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读
英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。
它使你能够专注于解决问题而不是去搞明白语言本身。
2、易学:就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简
单的语法。
3、免费、开源:Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这
个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS
是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希
望看到一个更加优秀的Python的人创造并经常改进着的。
4、高层语言:当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内
存一类的底层细节。
5、可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在
不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修
改就可以在下述任何平台上面运行。这些平台包括Linux、Windows、FreeBSD、
Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm
OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、
Windows CE甚至还有PocketPC、Symbian以及Google基于linux开发的Android平台!
6、解释型语言:一个用编译型语言比如C或C++写的程序可以从源文件(即C或C++语言)转换
到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标
记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中
并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程
序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译
成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接
转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序
拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
7、面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程
序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和
功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常
强大又简单的方式实现面向对象编程。
8、可扩展性:如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的
部分程序用C或C++编写,然后在你的Python程序中使用它们。
9、丰富的库:Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档
生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、
HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,
只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。除了标准
库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
10、规范的代码:Python采用强制缩进的方式使得代码具有极佳的可读性。
缺点
Python语言非常完善,没有明显的短板和缺点,唯一的缺点就是执行效率慢,这个是解释型语言
所通有的,同时这个缺点也将被计算机越来越强大的性能所弥补。
Python应用场景
1、Web应用开发
Python经常被用于Web开发。比如,通过mod_wsgi模块,Apache可以运行用Python编写的
Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间
的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发
和管理复杂的Web程序。
2、操作系统管理、服务器运维的自动化脚本
在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD
和Mac OS X都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器
使用Python语言编写,比如Ubuntu的Ubiquity安装器,Red Hat Linux和Fedora的Anacond
–MapReduce
优点:
1)MapReduce易于编程
如果要编写分布式程序,只需实现一些简单接口,与编写普通程序类似,避免了复杂过程。这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2)良好的扩展性
当计算资源不能得到满足的时候,可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的 PC 机器上,廉价的 PC 机器坏的概率相对较高,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
4)适合PB级以上海量数据的离线处理
这里的“离线”可以理解为存在本地,非实时处理,离线计算往往需要一段时间,比如几分钟或几个小时。可以实现上干台服务器集群并发工作,提供数据处理能力。
缺点:
1)不擅长实时计算
MapReduce 不适合在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
典型应用场景
1)单词统计
2)简单的数据统计,比如网站PV和UV统计
3)搜索引擎建立索引
4)搜索引擎中,统计最流行的K个搜索词
5)统计搜索词的频率,帮助优化搜索词提示
6)复杂数据分析算法实现
–Hive
优点:
(1)简单容易上手:提供了类SQL查询语言HQL
(2)可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)
一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
(3)提供统一的元数据管理
(4)延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
(5)容错:良好的容错性,节点出现问题SQL仍可完成执行
缺点:
(1)hive的HQL表达能力有限
1)迭代式算法无法表达,比如pagerank
2)数据挖掘方面,比如kmeans
(2)hive的效率比较低
1)hive自动生成的mapreduce作业,通常情况下不够智能化
2)hive调优比较困难,粒度较粗
3)hive可控性差
应用场景:
(1)数据仓库:数据抽取、数据加载、数据转换 (2)数据汇总:每天/每周用户点击数、流量统计 (3)非实时分析:日志分析、文本分析 (4)数据挖掘:用户行为分析、兴趣分区、区域展示
–Spark
spark的优势:(1)图计算,迭代计算(训练机器学习算法模型做广告推荐,点击预测,同时基于spark的预测模型能做到分钟级)(2)交互式查询计算(实时)
缺点:1.资源调度方面,Spark和Hadoop不同,执行时采用的是多线程模式,Hadoop是多进程,多线程模式会减少启动时间,但也带来了无法细粒度资源分配的问题。但本质上讲其实这也不能算是Spark的缺点,只不过是tradeoff之后的结果而已。2.其实Spark这种利用内存计算的思想的分布式系统你想要最大发挥其性能优势的话对集群资源配置要求较高,比如内存(当然内存不足也能用)
spark的主要应用场景:(1)推荐系统,实时推荐 (2)交互式实时查询
spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存(中间结果不需要落地到hdfs)
还有一个特点:Spark在做Shuffle时,在Groupby,Join等场景下去掉了不必要的Sort操作,相比于MapReduce只有Map和Reduce二种模式,Spark还提供了更加丰富全面的运算操作如filter,groupby,join等。
期末大作业

 浙公网安备 33010602011771号
浙公网安备 33010602011771号