百万级交易订单系统jvm调优思路
JVM内存模型:JVM内部主要由运行时数据区、类加载子系统、字节码执行引擎三部分构成,jvm调优,很大部分是针对运行时数据区进行的。运行时数据区主要由本地方法栈、虚拟机栈、程序计数器、堆、方法区几部分构成。对象的创建一般是在堆上创建的,这个过程中会频繁的产生垃圾、回收垃圾,这是一个比较费时间的工作,也是影响系统运行的一个重要原因。首先我们来看看堆内部的主要结构。
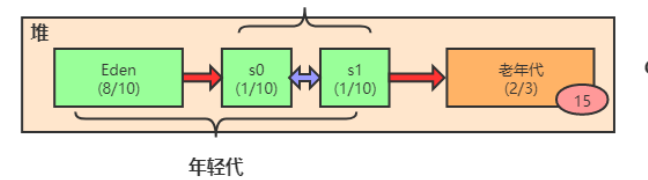
堆中包含年轻代和老年代,年轻代和老年代的空间比例大概在1:2,年轻代中又包含伊甸园(Eden)、survival1区、servival2区默认的比例在8:1:1,不考虑特殊情况,大多数情况下新创建的对象会被分配到伊甸园区,当伊甸园区的空间放满后会触发年轻代的一次垃圾回收(Minor Gc),垃圾对象在此过程中会被清理,存货的对象会移入survival1区,当伊甸园区被再次放满会再次触发Minor Gc,回收掉伊甸园区和survival1区的所有垃圾对象,并且将剩余存货对象转移到另一个survival区,此过程循环往复,每经过一次gc对象的年龄会+1,当对象年龄超过一定的数值(一般情况为15),会转移到老年代,若老年代也放满则会触发fullGC,若fullGc后不能形成足够的空间则会出现OOM。在gc的过程中会出现STW(stop the world)用户线程会被暂停,这也是引起程序性能问题的主要原因,fullgc会比minorGC慢10倍以上,所以jvm调优很大一部分是减小jvm的fullGc次数。
我们来看以下一个场景:
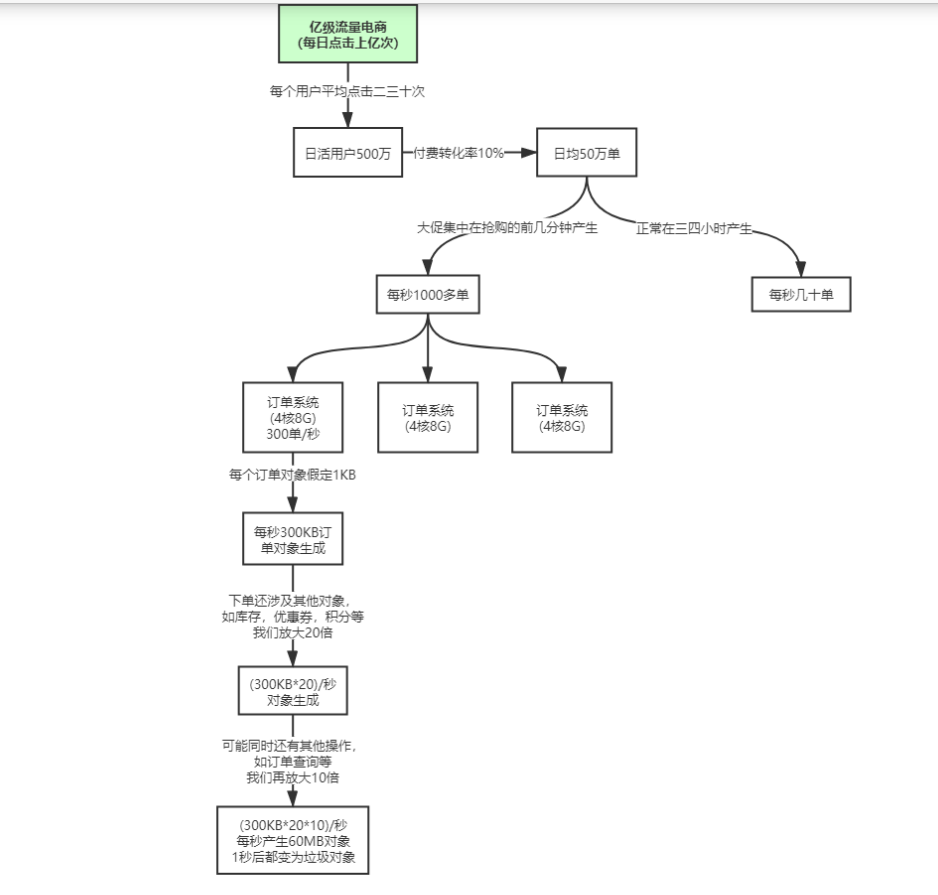
假设有这样一个网站,假设有三台服务器,我们根据对应的业务估算出在每台服务器上每秒会产生300单,根据订单的字段我们假设一个订单占用的空间为1kb,那么每秒在这台服务器上就会产生300k的订单数据,由于订单相关的操作肯定不止涉及到订单仅仅一个对象(例如优惠券、积分啊之类的),我们将此估值放大二十倍,那么每秒就有大概300k*20的数据,假设还涉及到其他类似订单查询等等操作,我们将数据再放大十倍,大概每秒会产生60M的数据,假设在下一秒执行完相关的操作后,这60M的数据就成为了垃圾。
我们来看看这60M的数据在堆中是怎么流转的。
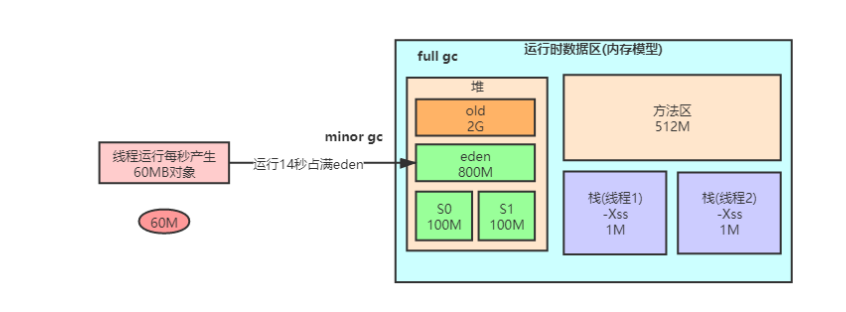
假设默认的堆的大小是3G,老年代2g,伊甸园800M,survival区200M,由于一般情况下新产生的对象会被分配在伊甸园区,那么每秒60M的垃圾经过14秒会占满伊甸园区,则在第15秒会进行Minorgc,新产生的60M对象会被移入survival区,这里面会涉及到动态对象年龄判断机制(一般在minorGc后触发,survival区年龄为1+年龄为2+.....+年龄为n的对象的大小如果大于survival区的50%,则会将年龄>=n的survival中的对象移入老年代)那么做个粗略的估算,从产生第一个对象开始经过15秒后会有60M的对象被移入老年代,那么大概估算经过八九分钟后老年代也会被放满,触发fullGc,每八九分钟就触发一次fullGc这样的频率显然有些太高了,正常至少应该好几天,所以我们可以通过调整堆的内存分配来进行优化。假设我们给老年代分配1G年轻代2G。那么年轻代中各个部分的大小都发生了翻倍。调整后,28s放满伊甸园区,minorGc后,假设此时的60M对象转移到了存活区,由于此时存活区的大小通过我们的设置也发生了翻倍,60M不再大于50%的空间,则此时不会触发动态年龄判定机制,对象不会再被送往老年区,而会直接存放在survival区,由于该业务下,对象大多数都是朝生夕死的,所以当伊甸园再次放满后,触发minorgc大多数的对象又被回收了,循环往复,堆中的压力便小了很多,几乎很少有对象会被放入堆区了,fullGc的频率自然就减少了。
以上是对jvm调优做的一个简单介绍,具体调优还要根据不同的业务场景进行具体分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号