大数据Hadoop之MapReduce(1)
一、什么是mapreduce
mapreduce是hadoop中的分布式计算框架,用于处理海量数据的计算。主要利用的是分治的思想,由两个阶段构成,(1)Map阶段将复杂的任务分解为若干个简单重复的任务(2)reduce阶段用于将Map阶段的结果进行汇总。
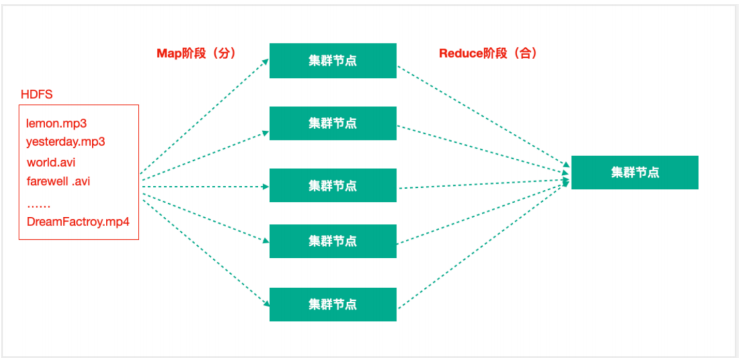
二、入门案例
我们来看一个入门案例,单词统计。
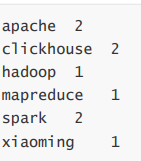
需求
词频统计,输出结果如下
第一步,编写Mapper
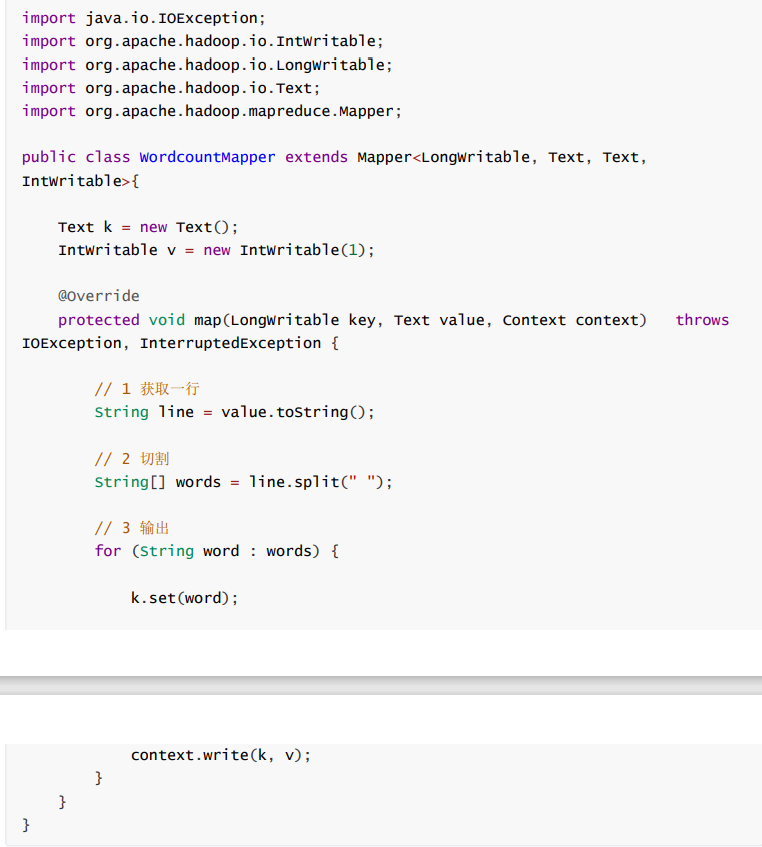
如果进行其他的配置,默认map采用的是TextInputFormat的数据输入方式,该方式默认数据文件中每行数据调用一次map方法,根据文本文件的特性我们对每一行数据用空格进行进行拆分,将拆分后的结果设置为Key,value为intwriteable(1)。
第二部 编写reducer
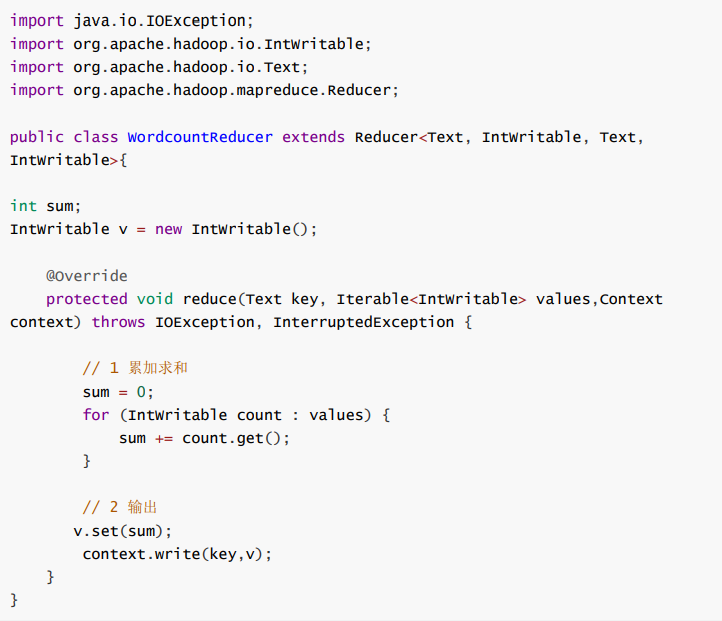
reduce方法会对相同的key的一组value进行一次reduce函数的调用。所以对每个key我们进行累加即可。
第三步 编写Driver类
该类是对相关的配置信息进行设置

三、序列化Writable接口
基本序列化类型往往不能满足所有的要求,例如自定义bean,那么该对象就需要我们实现自定义序列化接口。
步骤如下:
1、实现writable接口,2、空参构造必须有3、重写序列化和反序列化方法(字段的顺序必须一致)4、若自定义对象要放到key处还需要实现comparable接口。
案例如下
需求统计每台智能音箱设备的内容播放时长
原日志格式如下:

需要得到的输出结果如下

一、自定义bean对象



二、编写Mapper

三、编写reducer

第四步:编写驱动类

四、小结
结合业务设计Map输出的key和v,利用key相同则去往同一个reduce的特点!!
map()方法中获取到只是一行文本数据尽量不做聚合运算
reduce()方法的参数要清楚含义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号