


RHadoop和CDH整合实例(三)- RHive
五、 RHive的安装及测试
RHive依赖于Rserve,所有首先需要安装Rserve(在各个namenode上),接下来在所有节点上启动Rserve:
> sudo R > install.packages("Rserve") > q()
> Rserve --RS-conf /usr/lib64/R/Rserv.conf #启动Rserve
> sudo netstat -nltp | grep Rserve #查看Rserve服务端口号
通过netstate会发现Rserve启动后默认端口为6311。
在master节点上telnet(如果未安装,通过shell命令yum install telnet安装)所有slave节点。
> telnet bj1-241-centos169 6311
RHive的安装无法直接通过R的install.packages("RHive")进行,在github上也无法直接从https://github.com/nexr/RHive/downloads下载编译好的tar.gz包,只能从github下载源码后自己编译。编译java源文件的过程需要用到ant,若机器上没有,首先安装ant:
> sudo yum install ant
更改/etc/profile,设置环境变量HIVE_HOME和ANT_HOME,在测试机上,对应为:
HIVE_HOME=/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hive/
ANT_HOME=/usr/share/ant
以下步骤需要对RHive源代码进行一些更改,编译并打包成tar.gz文件后再安装RHive,若不关心修改源码的部分,本文最后会给出已编译好的文件以供下载。
进入$INS_TMP目录后,下载github上RHive项目源码,路径为~/$INS_TMP/RHive。由于测试机群上配置了Kerberos,而R语言通过RHive访问Hive的过程并不是直接通过JDBC接口访问,而是将在R语言中通过.j2r文件下的函数调用java程序,在java程序中加载JDBC驱动而访问hive。尽管当前用户拥有有效的Kerberos票据,在这样的机制下java程序却不能直接拥有Kerberos票据对应的权限。解决方案是在类com.nexr.rhive.hive.DatabaseConnection的代码 (java代码位于/RHive/RHive/inst/javasrc/src/目录下),在connect()方法里加上以下语句。
package com.nexr.rhive.hive; class DatabaseConnection { @SuppressWarnings("deprecation") boolean connect() throws SQLException { //加上的语句,使 RHive调用的java程序能够拥有kerberos权限 System.setProperty("javax.security.auth.useSubjectCredsOnly","false"); ... //函数体其余语句 return true; }
Hive可访问jar包的路径下,因为测试集群上的 sentry限制了程序对Hive的add jar操作,所以这条语句在RHive执行不通过,我们需要将其注释后,手动将rhive_udf.jar添加到Hive可以搜索的目录下。然后修改/etc/profile文件文件,增加HADOOP_HOME环境变量:
HADOOP_HOME=/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop/
回到~/$INS_TMP/RHive目录, 重新对RHive代码进行编译:
> sudo ant build > sudo R CMD build RHive > sudo R CMD INSTALL RHive_2.0-0.10.tar.gz
~/$INS_TMP/RHive目录下生成的RHive_2.0-0.10.tar.gz即为RHive安装包。
在正式使用RHive之前,还需要进行一些配置。RHive会将rhive_udf.jar复制到每台机器上对应的目录下,默认目录为/hive,可以通过/RHive/RHive/R/macro.R里的.DEFAULT_FS_HOME进行修改,这里我们修改为/user/rhive,注意修改后要进行重新编译。
在所有机器上都创建/user/rhive目录,并修改其属性,使所有用户对其都有读写权限。
> sudo mkdir -p /rhive/data > sudo chmod 777 -R /rhive/data
由于刚才我们在RHive的R代码中注释了hiveClient$addJar(.FS_JAR_PATH())一行,现在每台机器上都存在/rhive/data目录,并且RHive在执行过程中会自动将rhive_udf.jar添加到该路径下,此时可更改hive_site.xml的配置,在hive.aux.jars.path加上路径/rhive/data/rhive_udf.jar以使hive能够找到rhive_udf.jar。在cloudera manager下,这步操作可以在hive对应的配置页更改, 地址是http://host:port/cmf/services/38/config的格式。
设置完毕后重启hive。以下用的是169机器上的hiveserver2。
测试代码见test_rHive.r,调用RHive的核心部分如下,
#请确保以下路径配置正确
Sys.setenv(JAVA_LIBRARY_PATH="/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop/lib/native");
Sys.setenv(HADOOP_HOME="/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hadoop");
Sys.setenv(HIVE_HOME="/opt/cloudera/parcels/CDH-5.1.3-1.cdh5.1.3.p0.12/lib/hive/");
Sys.setenv(HADOOP_CONF="/etc/hadoop/conf");
Sys.setenv(DEFAULT_FS="/user/rhive");
library(RHive)
rhive.init() #rhive.init(verbose = TRUE)
rhive.env()
rhive.connect(host = "bj1-241-centos169", port = "10000",hiveServer2=TRUE, properties="hive.principal=hive/bj1-241-centos169@XXX.COM")
rhive.query('select count(*) from test')
rhive.close()
q()
可能出现的问题:
(1)执行rhive.connect()函数后抛出异常javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)],而用beeline进行连接,输入
!connect jdbc:hive2://192.168.241.169:10000/default;principal=hive/bj1-241-centos169@XXX.COM
连接正常,可能原因是kerberos对RHive调用的java程序没有授权,详细的 异常信息打印如下:
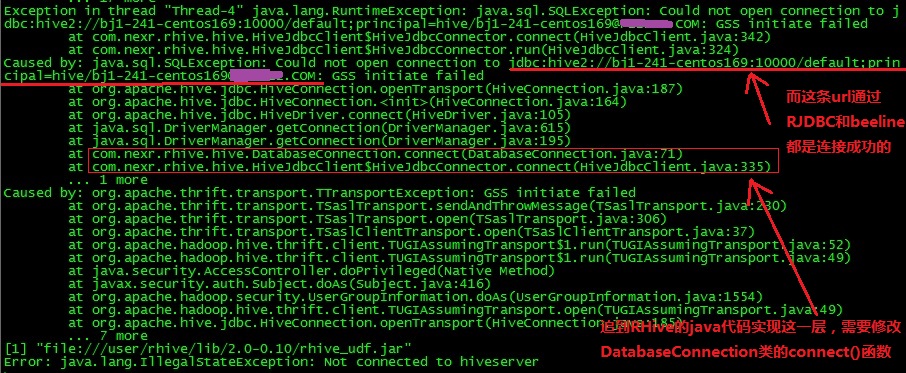
更改DatabaseConnection类下的connecr()函数即可, 即加上语句
System.setProperty("javax.security.auth.useSubjectCredsOnly","false");
(2)RHive执行connect()成功,但出现异java.sql.SQLException: Insufficient privileges to execute ADD, 图例如下(原始的RHive代码在出现这个问题时没有打印栈信息, 为了演示方便我手动加上了栈信息的打印):

出现这个问题的可能原因是sentry限制了对hive的add jar操作,将 rhive.R中的connect()函数进行修改,注释hiveClient$addJar后手动添加rhive_udf.jar路径,即可解决。
posted on 2015-12-21 23:35 cassie_huang89 阅读(627) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号