第八次作业
08 分布式计算MapReduce--词频统计
WordCount程序任务:
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数), 并按照单词字母顺序排序, 每个单词和其频数占一行,单词和频数之间有间隔 |
1.用你最熟悉的编程环境,编写非分布式的词频统计程序。
- 读文件
- 分词(text.split列表)
- 按单词统计(字典,key单词,value次数)
- 排序(list.sort列表)
- 输出
-
用Java的代码如下:
![复制代码]()
package com.gcc.test;
import java.io.IOException;
import java.io.InputStream;
import java.util.Map;
import java.util.TreeMap;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @className: CountWord
* @author: 小李探花
* @date: 2021/11/23 9:11
* @description:
*/
public class CountWord {
public static void main(String[] args) throws IOException {
InputStream in = CountWord.class.getResourceAsStream("/resource/word.txt");
//TreeMap默认是升序排序
Map<String, Integer> map = new TreeMap<>();
int len;
byte[] bytes = new byte[1024];
StringBuilder text = new StringBuilder();
if (in != null) {
while ((len = in.read(bytes)) != -1) {
text.append(new String(bytes, 0, len));
}
}
System.out.println("原句子: " + text);
//正则表达式, 匹配规则
String regex = "[A-Za-z]+";
Pattern compile = Pattern.compile(regex);
Matcher matcher = compile.matcher(text);
//如果匹配到
while (matcher.find()) {
map.merge(matcher.group().toLowerCase(), 1, Integer::sum);
}
System.out.println("统计结果如下: " + map);
}
}![复制代码]()
输出结果
![]()
-
在Ubuntu中实现运行。
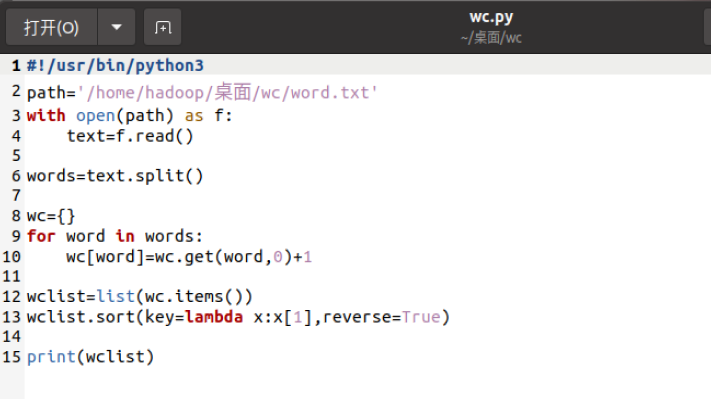
- 准备txt文件
- 编写py文件
- python3运行py文件分析txt文件。
![]()
![]()
![]()
-
2.用MapReduce实现词频统计
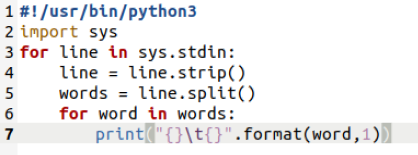
2.1编写Map函数
- 编写mapper.py
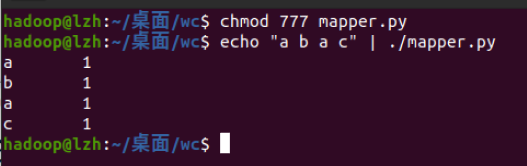
- 授予可运行权限
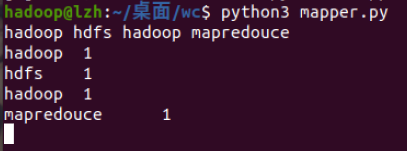
- 本地测试mapper.py
![]()
-
![]()
![]()
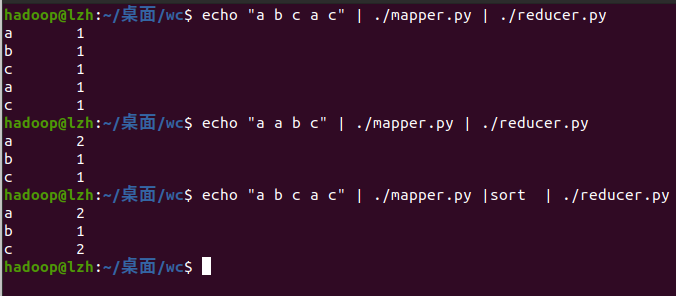
2.2编写Reduce函数
- 编写reducer.py
- 授予可运行权限
- 本地测试reducer.py
![]()
![]()
![]()
2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
-
![]()
![]() 准备待处理文件
准备待处理文件
![]()
- 上传HDFS
![]()
- 运行hadoop-mapreduce-examples-2.7.1.jar
![]()
- 查看结果
![]()
-
![]()
2.4 分布式运行自写的词频统计
- 停止HDFS与YARN














 浙公网安备 33010602011771号
浙公网安备 33010602011771号