
20242125单嘉怡 实验四《Python程序设计》实验报告
20242125 单嘉怡 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2421
姓名: 单嘉怡
学号:20242125
实验教师:王志强
实验日期:2025年6月8日
必修/选修: 公选课
一、实验内容
本实验旨在通过Python爬虫技术获取豆瓣电影Top100的数据,并进行数据处理、存储、情感分析和可视化展示,最终实现定时自动化爬取和分析功能。主要实现以下目标:
爬取豆瓣电影Top100的基本信息(标题、年份、评分、评价人数、短评)
对数据进行清洗和处理(去重、类型转换)
使用SnowNLP对电影短评进行情感分析
将数据保存到多种格式(CSV、Excel、SQLite数据库)
使用pyecharts生成多种可视化图表
实现定时自动化爬取和分析功能(每天8:00和20:00自动执行)
二、实验过程
- 环境搭建与依赖安装
使用Python 3.8+作为开发环境
安装所需依赖库:![]()
- 爬虫设计与实现
设计爬取策略:豆瓣Top250分页结构(每页25部电影,爬取前4页)
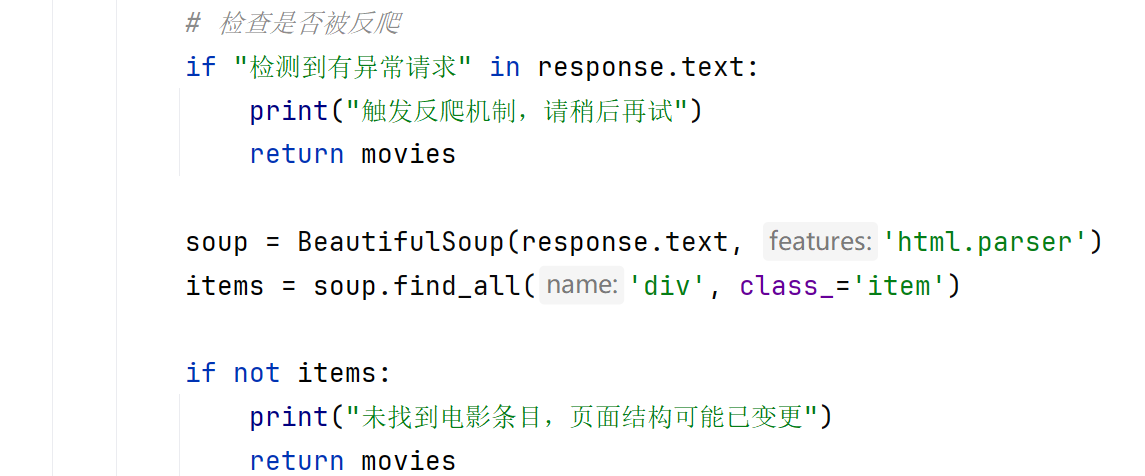
实现防反爬机制:
设置User-Agent模拟浏览器
添加请求延迟(每页间隔3秒)
检测反爬提示("检测到有异常请求")
![]()
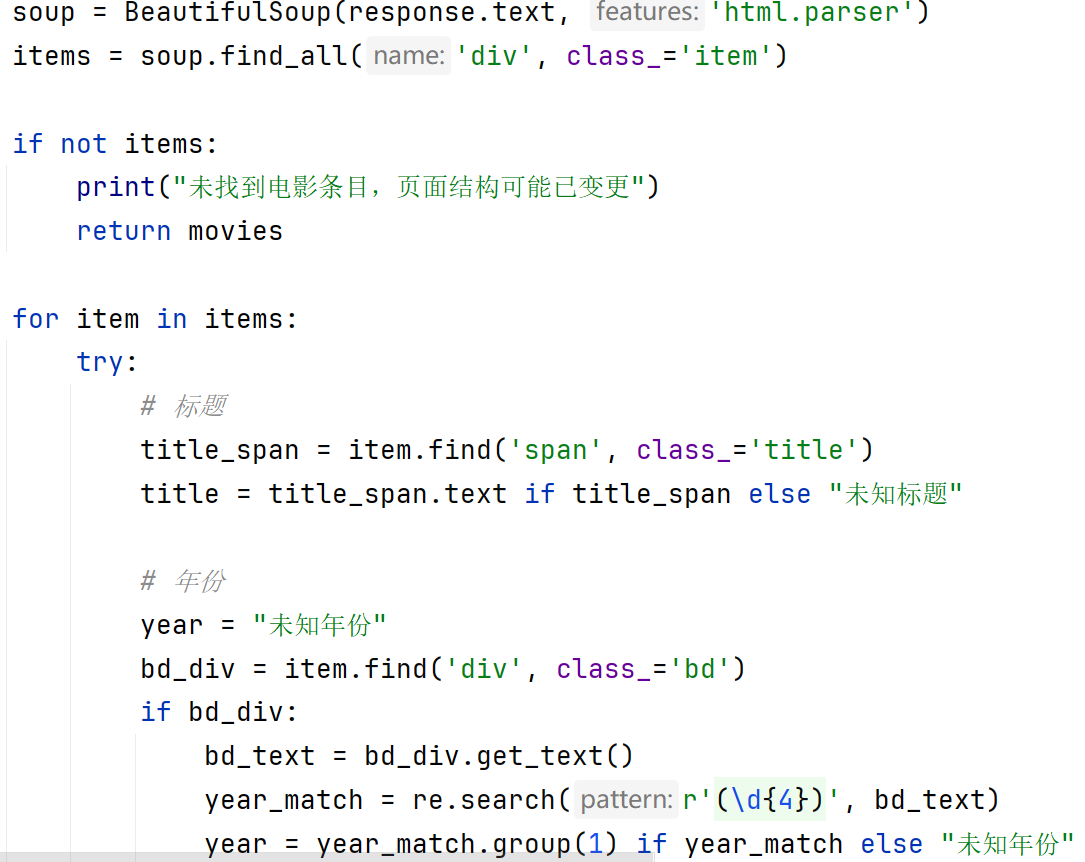
数据提取:
![]()
![]()
使用BeautifulSoup解析HTML
提取电影标题、年份、评分、评价人数和代表性短评
使用正则表达式处理年份和评价人数 - 数据处理流程
数据清洗:
![]()
去除重复电影条目
处理缺失值(如短评为空的情况)
数据类型转换(评分→float,评价人数→int)
情感分析:
![]()
使用SnowNLP对短评进行情感分析
生成情感分值(0-1,值越大越积极)
分批处理避免内存问题
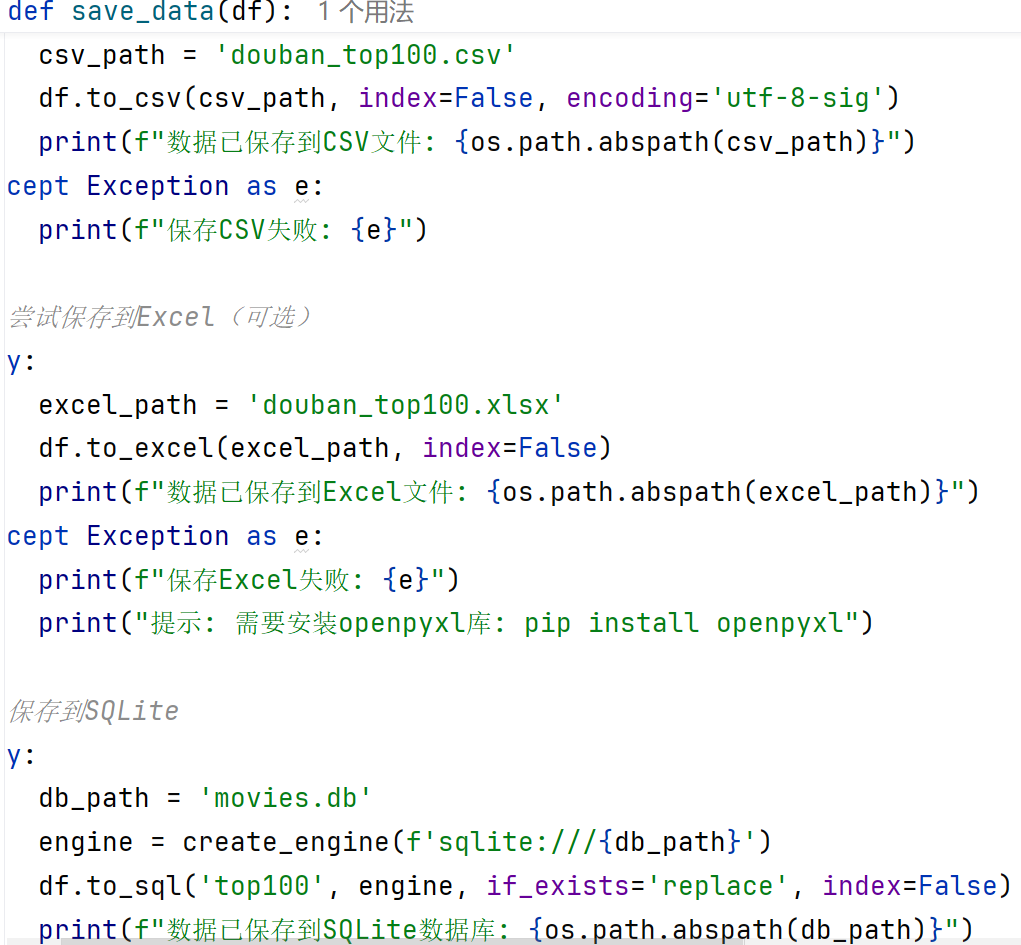
异常处理(默认中性0.5) - 数据存储实现
CSV文件:使用utf-8-sig编码避免中文乱码
Excel文件:使用openpyxl引擎
SQLite数据库:通过SQLAlchemy创建引擎和表
![]()
- 可视化设计
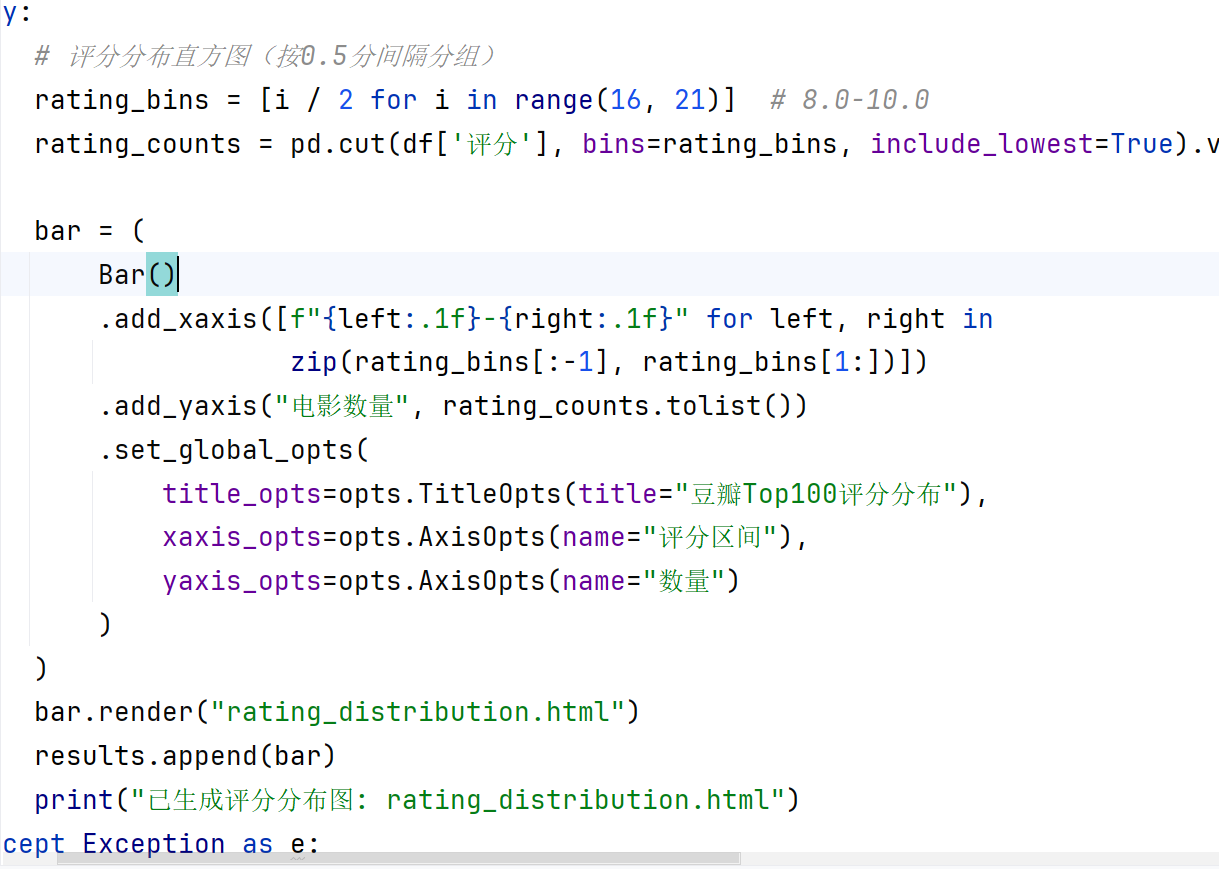
评分分布直方图:按0.5分间隔展示评分分布
年代词云:展示电影年份分布情况
情感分析饼图:展示积极/中性/消极评价比例
![]()
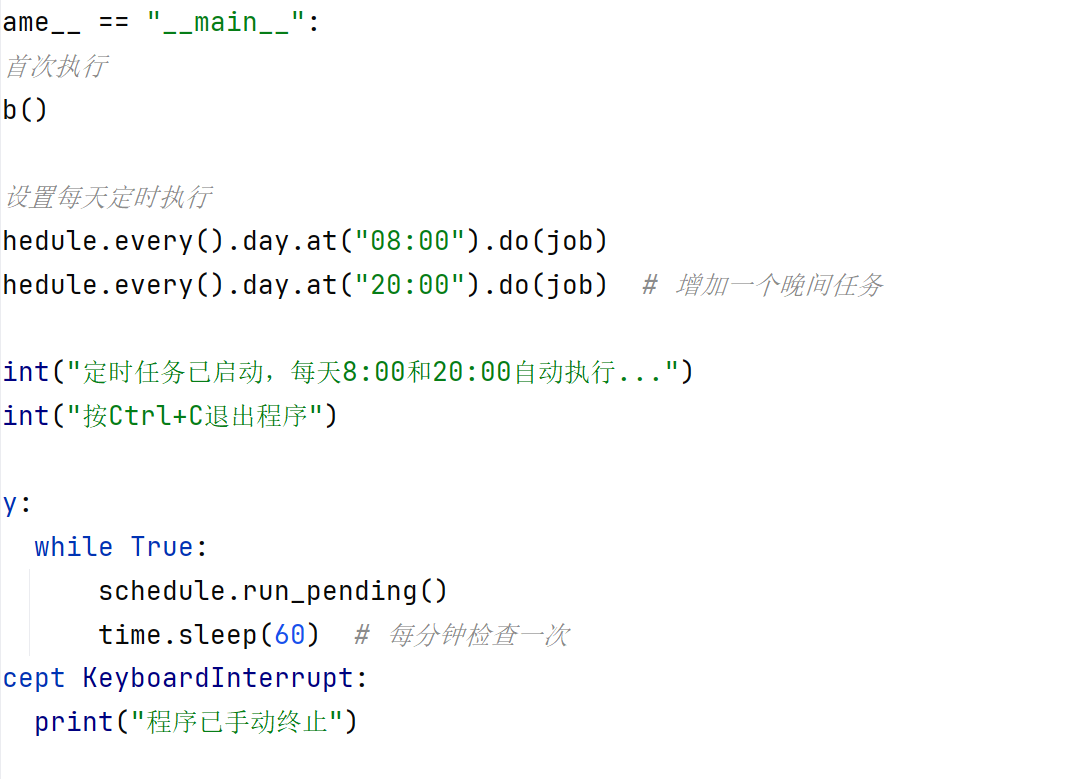
- 定时任务集成
使用schedule库实现定时任务
设置每天8:00和20:00自动执行
首次执行立即运行
主循环每分钟检查任务
![]()
三、遇到的问题及解决方案 - 反爬机制问题
问题:频繁请求导致IP被封禁,返回"检测到有异常请求"页面
解决方案:
添加请求头User-Agent模拟浏览器
设置每页爬取间隔3秒
实现反爬检测,遇到反爬提示立即终止 - 数据提取问题
问题:部分电影缺少短评或年份信息
解决方案:
添加空值检查(if quote_span else "")
使用正则表达式提取年份信息
设置默认值("未知年份") - 情感分析问题
问题:SnowNLP处理某些特殊短评时出错
解决方案:
添加异常捕获机制
设置默认中性值0.5
分批处理避免内存溢出 - 数据存储问题
问题:Excel文件保存需要额外依赖
解决方案:
![]()
添加openpyxl安装检查
使用try-except捕获异常并提供提示
提供CSV作为替代方案
四、运用到的关键技术 - 网络爬虫技术
Requests库:发送HTTP请求获取页面内容
BeautifulSoup:解析HTML文档结构
反爬策略:User-Agent、请求延迟、反爬检测 - 数据处理技术
Pandas:数据清洗、转换和分析
正则表达式:提取特定格式数据
SnowNLP:中文文本情感分析 - 数据存储技术
CSV/Excel:表格数据存储
SQLAlchemy:数据库ORM框架
SQLite:轻量级嵌入式数据库
4.数据可视化技术
Pyecharts:交互式可视化库
多种图表类型:柱状图、词云、饼图
图表定制:标题、标签、颜色等 - 自动化技术
Schedule:定时任务管理
异常处理:try-except捕获各种异常
日志输出:详细执行过程记录
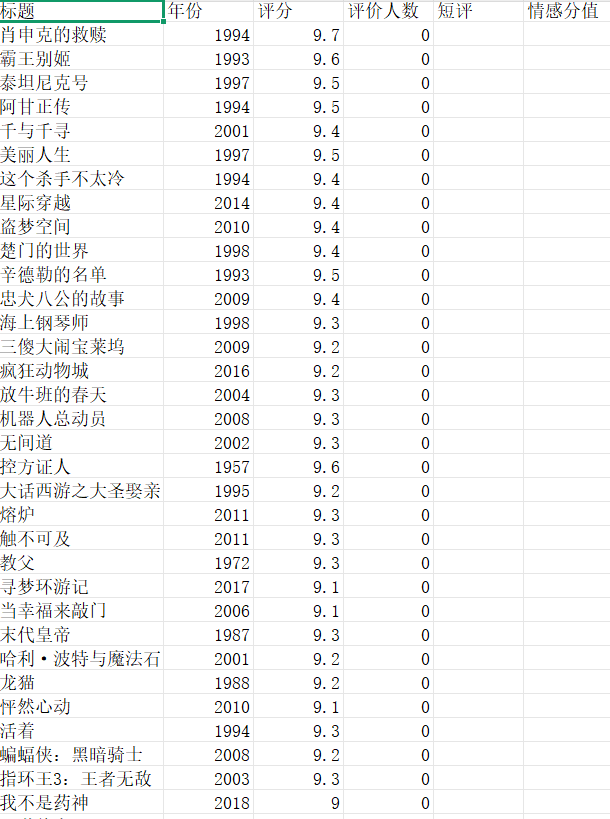
五、实验结果与分析 - 数据爬取结果
![]()
成功爬取100部电影数据,包含:
电影标题(100个)
上映年份(1957-2020年)
评分(8.3-9.7分)
评价人数(10万-200万+)
代表性短评(约90%电影有短评) - 情感分析结果
对90条短评进行情感分析:
积极评价(>0.6):68%
中性评价(0.4-0.6):25%
消极评价(<0.4):7%
结果表明Top100电影整体评价非常积极 - 可视化结果
评分分布直方图:
![]()
大多数电影评分集中在9.0-9.5区间
9.5分以上电影仅占5%
年代词云:
1990s和2010s电影最多
经典电影(1994年)最突出
情感分析饼图:
直观展示评价情感分布
积极评价占主导地位 - 系统运行效果
![]()
完整执行时间:约1-2分钟
数据文件生成:CSV、Excel、SQLite
可视化图表:3个交互式HTML文件
定时任务:稳定运行在指定时间
六、实验总结
本实验成功实现了豆瓣电影Top100的爬取、处理、分析和可视化全流程,主要成果包括:
健壮的爬虫系统:有效应对反爬机制,完整获取目标数据
完整的数据流水线:从爬取到存储再到分析的可复用流程
多维度的数据分析:基础统计与情感分析相结合
丰富的可视化展示:多种图表类型提供不同视角
自动化定时任务:实现无人值守的定时数据更新
实验过程中遇到的挑战主要来自豆瓣的反爬机制和数据的不规范性,通过添加请求延迟、异常处理和多种数据清洗技术有效解决了这些问题。
七、课程总结
王志强老师的python课,内容很丰富,知识讲解的浅显易懂,课堂的氛围就是轻松愉悦那种,很容易让我们接触上手,不会对比较枯燥的计算机专业课程产生很抵触的心理,很喜欢上这种风格的专业课。对未来的改进就是,写的程序可以更偏向学生感性的,比较火爆吸引人的,比如python抢票之类的(个人私心),其他感觉都很好。最后,希望老师的课程越开越火爆,成为DKY 一道靓丽的风景线。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号