
我们经常需要处理各种语言的文本数据。然而,在处理不同语言的字符串时,我们可能会遇到一些意想不到的问题。本文将讨论字符编码以及在跨语言环境中遍历字符串时可能遇到的特殊情况,并提供解决这些问题的方法。
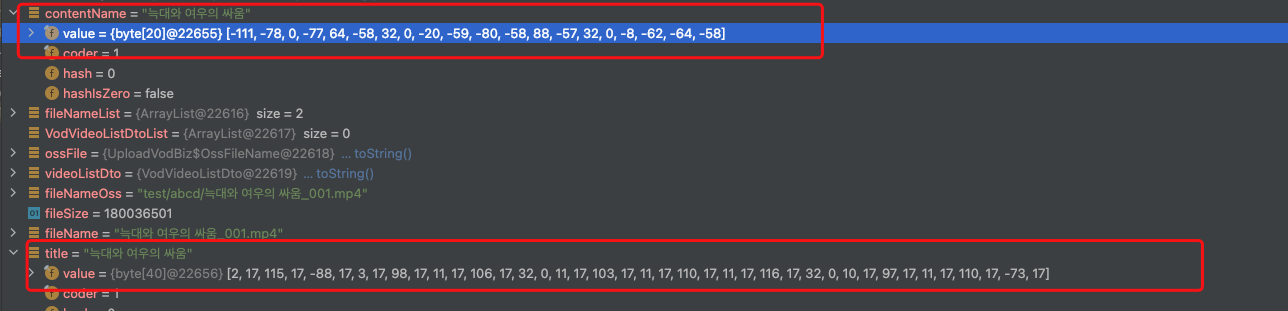
遇到的问题: title是读取文件获取到的文件名称, contentName是从本地服务获取的文件名。 两个名字看起来是完全一样的,但是 equals() 结果却是false
分析原因: 中文名称和英文名称都没有问题。 韩文和日语结果异常。 原因是 韩文在Unicode中可以以预先合成,有两种表现形式。 当表现形式不一致时,equals() 结果就会是false
解决方案:使用Unicode标准化 String normalized = Normalizer.normalize(original, Form.NFC);
equals 结果false

byte字节数组也不一样
### 1. 字符编码
字符编码用于将字符映射到计算机可以处理的字节表示形式。常见的字符编码包括ASCII、UTF-8、UTF-16等。每种字符编码都有其特定的字符集,其中包含了对应语言的字符。
### 2. 特殊情况
#### 2.1 韩文字符编码
韩文字母(Hangul)在Unicode中可以以预先合成(precomposed)的形式表示,也可以以分解(decomposed)的形式表示。预先合成的字符将多个字母组合成一个单一的字符,而分解的字符则将每个字母分开表示。这种情况可能导致在遍历字符串时每个字符都显示为分解形式的单个字母,而不是完整的字符。要解决这个问题,可以使用Unicode标准化技术将字符串转换为标准形式。
#### 2.2 其他语言的类似情况
类似的情况也可能发生在其他语言中,如日语、印尼语等。日语中的假名(Hiragana 和 Katakana)以及汉字(Kanji),印尼语中的拉丁字母扩展、重音符号以及特殊字符等,都可能涉及字符的组合形式。
### 3. 解决方案
在处理跨语言字符串时,我们应该意识到不同语言可能存在不同的字符编码和特殊情况。为了确保字符串在遍历时每个字符都能正确显示,我们可以采用以下解决方案:
- 使用Unicode标准化技术,将字符串转换为标准形式。
- 使用特定语言或框架提供的字符处理函数,如Java中的`java.text.Normalizer`类、Python中的`unicodedata.normalize`函数等。
- 确保在处理字符串时,选择合适的字符编码和字符处理方法,以适应目标语言的特点。
### 结论
在处理跨语言字符串时,了解不同语言的字符编码和特殊情况至关重要。通过采用适当的字符处理方法,我们可以确保在不同语言环境中处理字符串时能够正确地处理和显示文本数据,从而提高软件的可移植性和国际化水平。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号