
Logstash——Aggregate Filter Plugin
前言
此过滤器的目的是聚合属于同一任务的多个事件(通常是日志行)中的可用信息,并最终将聚合信息推送到最终任务事件中。
有以下几种使用场景:
- 无启动和结束事件
- 无启动事件
- 无结束事件
- 无结束事件,任务接踵而至
- 无有结束事件和尽快推送事件
各种场景的使用方式,请参考官网:aggregate filter
重要:使用此过滤器时,需要将Logstash筛选器工作线程设置为1(-w 1),否则可能会无序处理事件,并会出现意外结果。
参考示例1
aggreate 插件大致有5种使用方式,我们这里是使用的第三种:Example #3 : no end event。有的场景是需要聚合的日志有开始、结束标记的,但是有的场景并没有很好的方式标记。第三种方式就是设定一个 taskid ,使用 timeout 来控制一个聚合事件的结束。
应用日志:
在一次业务请求中,应用分别在不同地方打印了以下两条日志:
{"traceId":"45149684156451","name":"zs","hobby":"book"}
{"traceId":"45149684156451","age":26}
这两条日志的关联性就是其中的traceId,现在想将traceId相同的日志通过logstash输出为一条日志。
如果不做任何处理的话,那么logstash将会把每一条日志作为一个事件来输出。这样不符合需求,为此需要通过logstash的聚合插件来解决。
logstash配置:
#输入方式:控制台 input { stdin{} } filter{ #将采集到的日志分割为一个个json字段 json { source => "message" } #对同一个task_id的日志做聚合处理 aggregate{ #聚合的依据:traceId task_id => "%{traceId}" #聚合动作:获取以上得到的json字段并赋值给map中相应的字段 code => " map['traceId'] ||= event.get('traceId') map['name'] ||= event.get('name') map['hobby'] ||= event.get('hobby') map['age'] ||= event.get('age') #相同traceId的日志不输出,只有当超时或者聚合完成后才作为一条日志输出,因为我们最终目标是只输出聚合后的一条日志 event.cancel() " #当检测到不同的task_id时,就会将之前聚合的map作为一个新的事件并立即推送,然后以新的task_id建立新的聚合事件等待聚合 #push_previous_map_as_event => true #直到超时才将聚合的map作为事件进行推送 push_map_as_event_on_timeout => true #超时后将事件打一个新的标签。这个配置至关重要,如果要将聚合后的事件推送到ES(output中根据该标签来新建一个ES索引),那么必须有这个设置,否则ES得不到推送的数据 timeout_tags => ["my_aggr"] #超时时间:在该时间内如果没有相同的task_id日志,那么就将已经采集到的日志输出为一个事件 #超时时间的设置至关重要,决定了能否将需要关联的日志聚合为一条日志,具体取决于业务 timeout => 7 } } #输出方式:控制台 output { stdout{ codec => "rubydebug" } }
测试结果:
The stdin plugin is now waiting for input: {"bizId":"45149684156451","name":"zs","hobby":"book"} {"bizId":"45149684156451","age":26} { "name" => "zs", "age" => 26, "@version" => "1", "bizId" => "45149684156451", "hobby" => "book", "@timestamp" => 2022-06-15T06:39:53.001Z }
参考示例2
aggreate 插件大致有5种使用方式,我们这里是使用的第三种:Example #3 : no end event。有的场景是需要聚合的日志有开始、结束标记的,但是像nginx 日志,并没有很好的方式标记。第三种方式就是设定一个 taskid ,使用 timeout 来控制一个聚合事件的结束。
配置说明:
我们的 taskid: %{request_host}_%{[beat][hostname]} 代表域名与主机名连接之后作为一个唯一标记,timeout: 20。这就意味着每20 秒,针对每个 taskid 创建一个聚合事件,如果 request_host / hostname 有 5 种组合,那么在 20 秒内就会创建 5 个聚合事件。为了可以按照不同的维度统计,因此 taskid 使用了这些维度相关的字段来保证每个聚合事件中聚合的这些记录都有相同的 request_host 与 hostname ,对应上面需求中的维度:域名、服务器。
aggregate 的第3种使用方式中还有2个配置,分别是 code 与 timeout_code, 这2个配置项的值是 支持ruby 语法的,并且可以使用 ruby 中的 if/elsif/end 以及常用对象方法,大大提高了配置的灵活性。另外,code 中可用字典类型的 map 变量,用于保存一些字段信息,当配置 push_map_as_event_on_timeout => true 时会自动把map变量的字段放入新的聚合事件中。code 中还可以使用 event.get(field) 与 event.set(field, value) ,在 code 中的 event 代指每次输入的单行事件,所以可以使用 event.get() 来获取字段信息,然后结合 ruby 代码来聚合数据之后,存入 map 变量中。timeout_code 中不可以使用上面的 map 变量,不过没关系,之前map中字段已经全部存放到聚合事件了,可以使用 event.get() 来获取之前在 map 中的字段,然后做最后的计算之后,再把新的计算结果通过 event.set 放入聚合事件中。重点需要区分的是 code 与 timeout_code 中的 event 指代的对象不是同一个。
其实经过一些ruby逻辑的处理,为了把一些变量传递到聚合事件中,我们可能把一些中间变量放入了 map 变量,但是最终不希望在 elasticsearch 中使用它,那在 aggregate 中是办不到的,只能通过 mutate filter 插件删掉。
logstash配置:
filter { if "aggr-nginx" in [tags] { aggregate { task_id => "%{request_host}_%{[beat][hostname]}" code => " map['aggr'] ||= {}; map['request_host'] = event.get('request_host');
map['count'] ||= 0; map['count'] += 1; map['aggr']['total_time'] ||= 0; map['aggr']['total_time'] += event.get('request_time'); map['bytes'] ||= 0; map['bytes'] += event.get('bytes'); map['st_5xx'] ||= 0; map['st_4xx'] ||= 0; map['st_3xx'] ||= 0; map['st_2xx'] ||= 0; map['st_xxx'] ||= 0; if event.get('status') >= 500 map['st_5xx'] += 1; elsif event.get('status') >= 400 map['st_4xx'] += 1; elsif event.get('status') >= 300 map['st_3xx'] += 1; elsif event.get('status') >= 200 map['st_2xx'] += 1; else map['st_xxx'] += 1; end map['gt_500ms'] ||= 0; if event.get('request_time') > 0.5 map['gt_500ms'] += 1; end map['gt_100ms'] ||= 0; if event.get('request_time') > 0.1 map['gt_100ms'] += 1; end map['hostname'] = 'le.com'; if event.get('beat') map['hostname'] = event.get('beat')['hostname']; end map['aggr']['index'] = event.get('@metadata')['index']; " push_map_as_event_on_timeout => true #timeout_task_id_field => "task_id" timeout => 20 timeout_code => " avg_time = (event.get('[aggr][total_time]') / event.get('count')).round(3); event.set('avg_time', avg_time); meta_index = event.get('[aggr][index]').sub('access', 'count'); event.set('[@metadata][index]', meta_index); " } } }
另外,我们把普通事件与聚合事件分发到了 elasticsearch 的不同的索引(index)中,这样就可以非常方便的根据需要选择使用2种不同的索引(index)。其中上面针对 [@metadata][index] 的代码就是把原来索引名称中的 access 替换为 count,最后,普通事件的索引名称是 logstash-sso-nginx-access ,聚合事件的索引名称是 logstash-sso-nginx-count 。
测试结果:
最终到达 elasticsearch 中的结果分别是:
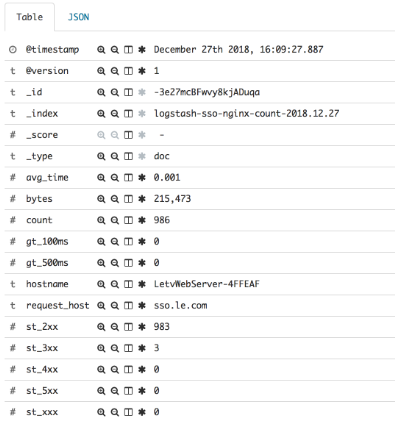
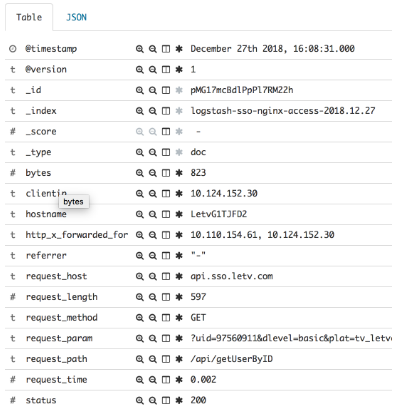
本人示例3
该示例是本人实际业务场景。聚合支付业务中,统计每一笔请求的总耗时,请求状态,支付渠道耗时,支付渠道状态等。我们是微服务架构,拆分为多个应用。需要通过aggregate把各个应用中的日志聚合起来,因为没有明确的开始和结束标记,所以使用的第三种:Example #3 : no end event。通过设定一个 taskid(traceId) ,使用 timeout 来控制一个聚合事件的结束。
日志说明:
logstash配置:
我们把普通事件与聚合事件分发到了 elasticsearch 的不同的索引(index)中,这样就可以非常方便的根据需要选择使用2种不同的索引(index)。
普通事件的索引名称是 app-request-trace ,聚合事件的索引名称是 app-request-aggregate 。
测试结果:
总结
- aggregate 有几种使用方式,分别使用不同的配置字段,可以根据需要使用;
- code 与 timeout_code, 这2个配置项的值是支持ruby语法的,并且可以使用 ruby 中的 if/elsif/end 以及常用对象方法,大大提高了配置的灵活性;
- 聚合的记录是以一个新的 event 输出的,并不影响原来每行一个的 event 。比如我要聚合 5 条数据,aggregate 会先把这5条数据输出,然后再输出一条聚合的数据;
引用:
- https://521-wf.com/archives/logstash-aggregate-filter.html
- https://blog.csdn.net/weixin_40660408/article/details/125297181
- https://www.elastic.co/guide/en/logstash/7.14/plugins-filters-aggregate.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号