
Java 虚拟机(JVM)原理深度解析
JVM 是 Java 程序运行的核心引擎,工作原理可分为 7 大核心模块:
一、类加载机制(Class Loading)

1、加载阶段:通过类加载器(ClassLoader)查找 .class 文件
- Bootstrap ClassLoader:加载 JRE 核心库, tr.jar
- Extension ClassLoader:加载扩展库(jre/lib/ext)
- Application ClassLoader: 加载用户类路径(-classpath)
2、验证阶段:校验字节码安全性
- 文件格式验证
- 元数据验证
- 字节码验证
3、准备阶段:为静态变量分配内存(默认初始值)
4、解析阶段:符号引用转直接引用
5、初始化阶段:执行静态代码块
二、运行时数据区(Runtime Data Areas)
public class MemoryModel {
static int classVar; // 方法区
int instanceVar; // 堆
void execute() {
int localVar = 0; // 栈帧-局部变量表
Object obj = new Object(); // 堆
}
}
1、方法区(Method Areas)
- 存储类结构(字段/方法数据)
2、堆(Heap)
- 所有对象实例存储区(GC主战场)
- 分代结构
- 新生代
- 老年代
- 永久代
3、虚拟机栈(JVM Stack)
- 线程私有,存储栈帧(Frame)
- 栈帧结构
| 局部变量表 | 操作数栈 | 动态链接 | 返回地址 |
4、程序计数器(PC Register)
- 当前线程执行的字节码行号指示器
- 唯一不会 OOM 的区域
5、本地方法栈(Native Method Stack)
- 服务于 Native 方法
三、执行引擎(Execution Engine)
1、解释器:逐行解释字节码(启动快,执行慢)
2、即时编译器(JIT Compiler)
- 热点代码编译为本地机器码
- C1编译器(Client模式):快速编译
- C2编译器(Server模式):深度优化
3、分层编译策略(Tiered Compilation)
第0层:解释执行
第1层:C1简单编译
第2层:C1带方法计数器的编译
第3层:C1带完整性能监控的编译
第4层:C2深度优化编译
四、垃圾回收(Garbage Collection)
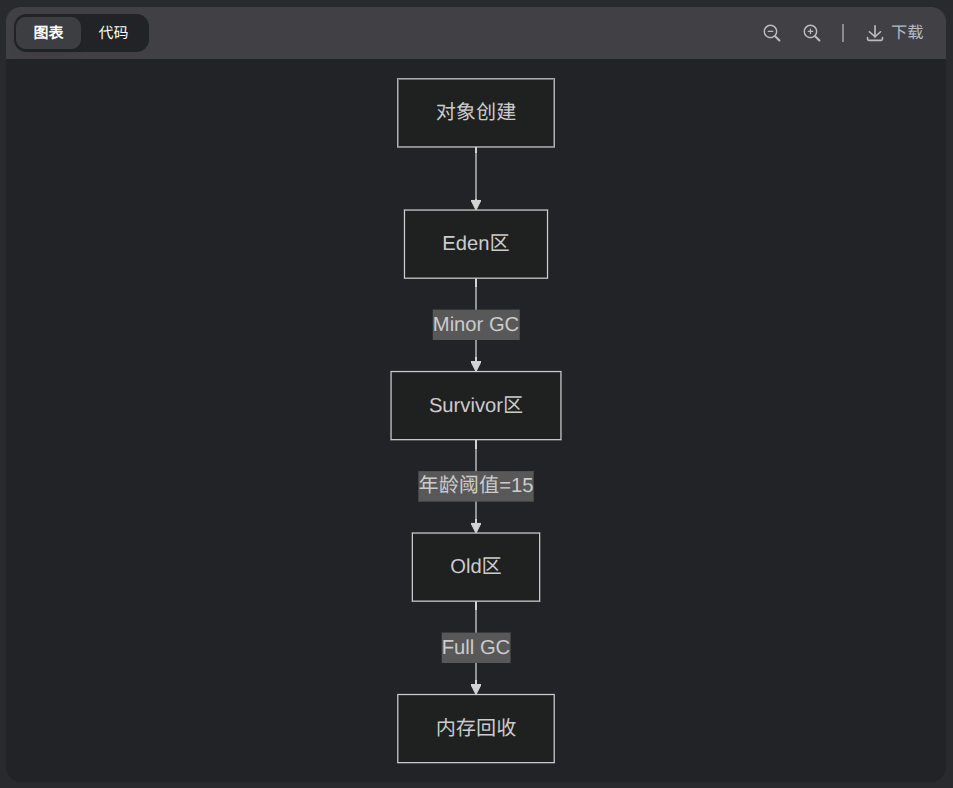
1、回收算法
- 标记-清除(Market-Sweep):产生内存碎片
- 复制(Coping):适合新生代(Eden -> Survivor)
- 标记整理(Mark-Compact):适合老年代
2、GC类型
- Serial GC:单线程STW(Stop-The-World)
- Parallel GC:多线程并行
- CMS:并发标记清除(JDK9废弃)
- G1:分区域收集(JDK9+默认)
- ZGC:亚毫秒级暂停(JDK15+)
五、内存模型(JMM)
1、主内存与工作内存
- 线程操作变量需从主内存拷贝到工作内存
- 修改后刷新回主内存(Volatile强制立即刷新)
2、原子性/可见性/有序性
- synchronized:保证三者(锁机制)
- volatile:保证可见性和有序性
- final:构造函数内可见性
3、Happens-Before 原则:
- 程序顺序规则
- 锁规则(解锁优先于加锁)
- volatile规则(写先于读)
六、性能监控工具

七、JVM 调优实战
1、参数配置
# 堆内存设置
-Xms4g -Xmx4g
# 新生代比例
-XX:NewRatio=2
# G1配置
-XX:+UseG1GC -XX:MaxGCPauseMillis=200
2、常见问题处理
- OOM 分析:
- 堆溢出:
java.lang.OutOfMemoryError: Java heap space - 方法区溢出:
java.lang.OutOfMemoryError: Metaspace - CPU 飚高排查:
top -Hp <pid> # 找高CPU线程 printf "%x" <tid> # 转16进制 jstack <pid> | grep <nid> # 定位线程栈 - 堆溢出:
自己的总结
JVM 是 Java 虚拟机,使用软件模拟出来的机器,运行在操作系统之上,负责把 Java 文件编译成的字节码文件翻译成指令集,告诉操作系统我需要做什么呢操作。 JVM 随 Java 程序的开始儿开始运行,随 Java 程序的结束而结束。
JVM 的工作机制是,首先调用类加载器加载字节码文件,进行一些初始化的操作,然后在运行时内存分为 5 个区域:
- 方法区:存储类型、常亮、静态变量
- 堆:存储 new 出来的对象或者数组
- 虚拟机栈:保存基础数据类型 byte short int long float double boolean char 1 2 4 8 4 8 1 2 字节
- 本地方法栈:执行 native 方法,保存的是本地局部变量表
- 程序计数器:用来指示程序运行到哪里,多线程运行的时候实际上就是通过获取CPU时间片执行各自的任务,各个线程维护一个程序计数器来保证下一次继续执行任务的正确性
方法区 和 堆 内存是垃圾回收机制 GC 的主战场。
一般采用 root 搜索方法 (可达性检测),即 不在引用链上的对象,其内存就是空闲的,需要被回收
引用计数法由于会出现类似死锁的循环引用,导致计数不为0,实际上方法调用已经结束,需要回收的情况,所以一般使用 root 搜索法,gc root 一般报错内存泄漏的时候会有相应的提示信息
GC 的方法:
- 标记-清除法:就是标记一下哪些可用对象是存活的,将其他的回收掉,缺点是会造成内存碎片化
- 标记-整理法:对 标记-清除法 的改进,进行垃圾回收之后,对当前正在使用的内存区域进行复制整理,使得有连续的空闲存储空间得以使用,成本高,但是有效果
- 标记-复制法:将存储的空间复制到另一块连续的空间上,将原来空间的内存全部回收
eden - survivor1 - survivior2 - 老年代
内存占比:8 - 1 - 1 - 20
年轻代的对象用完就回收,不会长期存活,利用 两个 survivor 区进行标记复制垃圾回收。如果在这个过程有对象存活时间超过15次,就把他放到老年代,因为老年代的区域不是经常进行垃圾回收。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号