
1、执行 Python 脚本的两种方式
脚本:脚本简单地说就是一条条的文字命令,这些文字命令是可以看到的(如可以用记事本打开查看、编辑),脚本程序在执行时,是由系统的一个解释器,将其一条条的翻译成机器可识别的指令,并按程序顺序执行。因为脚本在执行时多了一道翻译的过程,所以它比二进制程序执行效率要稍低一些。

关于编译器与解释器的区别:https://blog.csdn.net/touzani/article/details/1625760
从Hello World 谈Python运行原理:https://blog.csdn.net/sxb0841901116/article/details/21418885
2、简述位、字节的关系
位:"位(bit)"是电子计算机中最小的数据单位。每一位的状态只能是0或1。
字节:8个二进制位构成1个"字节(Byte)",它是存储空间的基本计量单位。1个字节可以储存1个英文字母或者半个汉字,换句话说,1个汉字占据2个字节的存储空间。
简单的说
字(word) 占2字节
字节(byte) 占8位
位(bit) 最小的单位
比特就是 bit ,就是位。
1字=2字节
1字节=8位
1字=2*8=16位
3、简述 a sc ii、 u n i c o de、 u t f-8、 gbk 的关系
ASCII:(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
Unicode:(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
UTF-8:(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
GBK :是又一个汉字编码标准,全称《汉字内码扩展规范》(GBK),英文名称 Chinese Internal Code Specification ,中华人民共和国全国信息技术标准化技术委员会 1995 年 12 月 1 日制订,国家技术监督局标准化司、电子工业部科技与质量监督司 1995 年 12 月 15 日联合以技监标函 [1995] 229 号文件的形式,将它确定为技术规范指导性文件,发布和实施。这一版的 GBK 规范为 1.0 版。GB 即“国标”,K 是“扩展”的汉语拼音第一个字母。
a.Unicode 和 UTF-8 有何区别:
https://www.zhihu.com/question/23374078
b.GBK和UTF-8是什么,它们有什么区别:
GBK包含中日韩字符集合,他能完美支持简体中文和英文,但如果在IE没有安装简体中文支持的电脑上阅读GBK编码的网页,中文会变成乱码,例 如英国人浏览您的网站,电脑全是火星文,UTF-8则包含了大部分文字的编码,可以表达更多的语言,使用UTF-8一个最大的好处就是其他地区的用 户(美国、印度、台湾)无需安装简体中文支持,就能正常看您的文字,并且不会出现乱码,通常网络传输也是使用UTF-8编码。
- unicode:包含所有国家的字符编码,
- utf-8可变长的字符编码,英文表示一个字节,中文(繁文)表示3个字节
- ascii美国标志信息交换代码,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,一个字符占一个字节
- gbk全称《汉字内码扩展规范》,一个字符占用两个字节
4、请写出 “李杰” 分别用 utf-8 和 gbk 编码所占的位数
- 在utf-8中,一个中文字符占用3个字节
- 在gbk中一个汉字占用2个字节
- 李杰 = utf-8(6字节)=48
- 李杰 = gbk(4字节)=32
5、Pyhton 单行注释和多行注释分别用什么?
- 单行注释 #被注释内容 :井号(#)常被用作单行注释符号,在代码中使用#时,它右边的任何数据都会被忽略,当做是注释。
print 1 #输出1
#号右边的内容在执行的时候是不会被输出的。
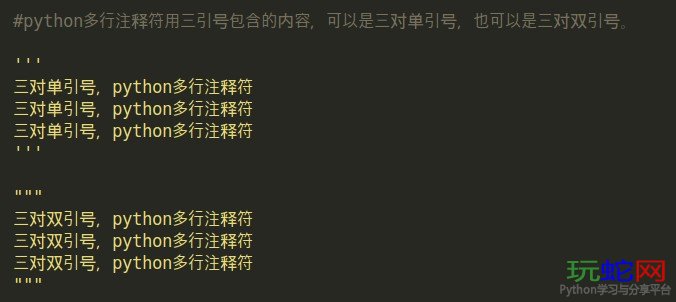
- 多行注释 '''被注释内容''':多行注释是用三引号''' '''包含的。
6、声明变量注意事项有那些?
声明变量:简单的说就是避免编程时产生不必要的错误,一位不同类型变量的存储格式和长度都不同,所以字节长度不同,声明变量可以让计算机知道你更需要用什么样的格式存储变量,从而高效稳定地运行程序。
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
- ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 最好不好和python内置的东西重复
7、如有一下变量n1=5,请使用int 的提供的方法,得到该变量最少可以用多少个二进制位表示?
n1=5 v = int(n1.bit_length()) print(v)
执行结果:
3
8.布尔值分别有什么?
- 一个布尔值只有True、False两种值,要么是True,要么是False
- 可以用0或1表示
a = "alex" b = a.capitalize() print(a) print(b)
执行结果:
alex
Alex
10、写代码,有如下变量,请按照要求实现每个功能
name="aleX"
a.移除 name 变量对应的值两边的空格,并输入移除后的内容
print(name.strip()) #aleX
b.判断 name 变量对应的值是否以"al"开头,并输出结果
print(name.startswith('al')) #False
c.判断 name 变量对应的值是否以"X"结尾,并输出结果
print(name.endswith('X')) #False
d.将 name 变量对应的值中的“l”替换为“p”,并输出结果
print(name.replace('l','p')) #aleX
e.将 name 变量对应的值根据“l”分割,并输出结果。
print(name.split('l')) #['a', 'eX']
f.请问,上一题e分割之后得到值是什么类型(可选)
print(type(name.split('l'))) #<class 'list'>
g.将 name 变量对应的值变大写,并输出结果
print(name.upper()) #ALEX
h.将 name 变量对应的值变小写,并输出结果
print(name.lower()) #alex
i.请输出 name 变量对应的值的第 2 个字符?
print(name[1:2]) #l
j.请输出 name 变量对应的值的前 3 个字符?
print(name[:3]) #ale
k.请输出 name 变量对应的值的后 2 个字符?
print(name[-2:]) #eX
l.请输出 name 变量对应的值中“e”所在索引位置?
print(name.index('e')) #2
m.获取子序列,仅不包含后一个字符。如:oldboy则获取oldbo;root则获取roo
字符?
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 n1 = "oldboy" 6 n2 = n1.strip('y') 7 print(n2)
执行结果:
1 oldbo
21、字符串是否可迭代对象?如可以请使用for 循环每一个元素?
python循环语句:http://www.runoob.com/python/python-loops.html
可以
1 name = "nulige" 2 for i in name: 3 print(i)
执行结果:
1 n 2 u 3 l 4 i 5 g 6 e
补充知识:
什么是迭代?
利用 for 循环来遍历一个列表(list)或元组(tuple),将值依次取出,这种方法我们称为迭代。
利用for语句迭代字符串,创建一个字符串,name = "nulige",然后用for语句进行迭代。
22、请用代码实现:
a. 利用下划线将列表的每一个元素拼接成字符串, li = "alexericrain"
1 li = "alexericrain" 2 v = "_".join(li) 3 print(v)
执行结果:
1 a_l_e_x_e_r_i_c_r_a_i_n
b. 利用下划线将列表的每一个元素拼接成字符串, li = ['alex', 'eric', 'rain'] (可选)
1 li = ['alex','eric','rain'] 2 v = "_".join(li) 3 print(v)
执行结果:
1 alex_eric_rain
23、 Python2 中的 range 和 Python3 中的 range 的区别?
python2直接就在内存中创建出来
pyhotn3没有在内存中创建出来,需要使用for循环才会创建出来
24、实现一个整数加法计算器:
如:content=input('请输入内容:')#如:5+9或5+9或5+9
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 n1 = int(input("name:")) 6 n2 = int(input("age:")) 7 info = n1+n2 8 print(info)
执行结果:
1 name:5 2 age:9 3 14
25、计算用户输入的内容中有几个十进制小数?几个字母?
如: content = input('请输入内容: ') # 如: asduiaf878123jkjsfd-213928
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 number_null = "" 6 name = "123456asdfsdf" 7 str_null = "" 8 for i in name: 9 if i.isdecimal(): #判断i的值是不是数字 10 number_null += i #如果i的值是数字的话,则加入到number_null 11 elif i.isalpha(): #判断i的值是不是字母 12 str_null += i 13 print(number_null,str_null) 14 print(len(number_null),len(str_null))
执行结果:
1 123456 asdfsdf
2 6 7
为什么python中,程序开始都要敲入“# -*- coding: UTF-8 -*-” 这个有什么作用呢:PY文件当中是不支持中文的,即使你输入的注释是中文也不行,为了解决这个问题,就需要把文件编码类型改为UTF-8的类型,输入这个代码就可以让PY源文件里面有中文了。建议你写代码之前都把这句话加上,因为不管是注释还是弹出消息提示,免不了的要输入中文,所以这个基本是必须的。
26、简述 int 和 9 等数字 以及 str 和 "xxoo" 等字符串的关系?
数字就是整型,带“ ”的就是字符串
27、制作趣味模板程序
需求:等待用户输入名字、地点、爱好,根据用户的名字和爱好进行任意现实
如:敬爱可亲的 xxx,喜欢在 xxx 地方干 xxx
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 n1 = input("name:") 6 n2 = input("add:") 7 n3 = input("hobby:") 8 print("敬爱的",n1,"喜欢在",n2,"安静的",n3)
执行结果:
1 name:成龙 2 add:图书馆 3 hobby:看书 4 敬爱的 成龙 喜欢在 图书馆 安静的 看书
28、制作随机验证码,不区分大小写。
流程: - 用户执行程序
- 给用户显示需要输入的验证码
- 用户输入的值
用户输入的值和显示的值相同时现实正确信息;
否则继续生成随机验证码继续等待用户输入
生成随机验证码代码示例:
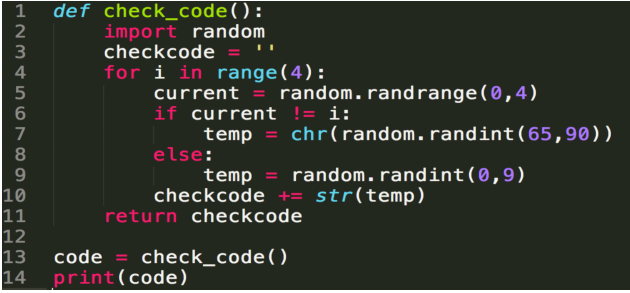
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 def check_code(): 6 import random 7 checkcode = '' 8 for i in range(4): 9 current = random.randrange(0,4) 10 if current != i: 11 temp = chr(random.randint(65,90)) 12 else: 13 temp = random.randint(0,9) 14 checkcode += str(temp) 15 return checkcode 16 code = check_code() 17 print(code) 18 19 count = 0 20 while count < 3: 21 identifying_code = input("请输入验证码:") 22 if code == identifying_code.upper(): 23 print("验证通过---登录成功---") 24 break 25 else: 26 continue 27 count += 1
执行结果:
1 请输入验证码:lwv9
2 验证通过---登录成功---
29、开发敏感词语过滤程序,提示用户输入内容,如果用户输入的内容中包含特殊的字符:
如:"苍老师"“东京热”,则将内容替换为***
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #Author: nulige 4 5 n1 = input("请输入:") 6 m = str.maketrans("苍老师", "***") 7 a = str.maketrans("东京热", "***") 8 new_v = n1.translate(m).translate(a) 9 print(new_v)
执行结果:
1 请输入:苍老师
2 ***
30、制作表格
循环提示用户输入:用户名、密码、邮箱 (要求用户输入的长度不超过 20 个字符,如果超过则只有前 20 个字符有效) 如果用户输入 q 或 Q 表示不再继续输入,将用户输入的内容以表格形式打印
1 W = "用户名\t密码\t邮箱\n" 2 while 1 == 1: 3 name = input("asfdsa:") 4 if name == "q" or name == "Q" or name == "no": 5 print(w) 6 break 7 passwd = input("密码:") 8 if passwd == "q" or passwd == "Q" or quit == "no": 9 print(w) 10 break 11 mail = input("邮箱:") 12 if mail == "q" or mail == "Q" or mail == "no": 13 print(w) 14 break 15 Name = name[0:20] 16 Pwd = passwd[0:20] 17 Mail = mail[0:20] 18 b = "{0}\t{1}\t{2}\n".format(Name,Pwd,Mail) 19 n1 = W + b 20 w = n1.expandtabs(20) 21 continue
执行结果:
1 用户名:asfdsa 2 密码:ddd 3 邮箱:qq@qq.com 4 用户名:q 5 用户名 密码 邮箱 6 asfdsa ddd qq@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号