scrapy
爬虫本质
HTTP协议
爬虫的本质是:就是socket的客户端和服务端基于HTTP协议进行通信。
HTTP协议:基于TCP的一种无状态短连接的数据传递(通过/r/n分割数据,请求头与请求体通过/r/n/r/n区分)
浏览器与服务器进行通信时:连接过程(IO阻塞)、数据响应(IO阻塞)
sk = socket.socket() # 创建连接(IO阻塞) sk.connect(('www.cnblogs.com',80)) sk.sendall(b"GET /wupeiqi http1.1\r\n.....\r\n\r\n") sk.sendall(b"POST /wupeiqi http1.1\r\n.....\r\n\r\nuser=alex&pwd=123") # 接受数据(IO阻塞) data = sk.recv(8096) sk.close()
高性能爬虫
所以在多任务爬虫操作时则使用:依照节约资源和减少IO阻塞(异步IO阻塞):开多进程----->开多线程---->利用“异步IO非阻塞”模块实现单线程并发
异步IO非阻塞:IO多路复用+非socket阻塞
IO多路复用:
- IO多路复用--->监听多个socket对象是否反生变化
import select
while True:
r,w,e = select.select([sk1,sk2],[sk1,sk2],[],0.5)
# 让select模块帮助检测sk1/sk2两个socket对象是否已经发生“变化”
r=[]
# 如果r中有值
r=[sk1,] 表示:sk1这个socket已经获取到响应的内容
r=[sk1,sk2] 表示:sk1,sk2两个socket已经获取到响应的内容
w=[],如果w中有值
w=[sk1,], 表示:sk1这个socket已经连接成功;
w=[sk1,sk2],表示:sk1/sk2两个socket已经连接成功;
非socket阻塞
sk = socket.socket() # 创建连接(IO阻塞)
sk.setblocking(False) #关闭IO阻塞
try: sk.connect(('www.cnblogs.com',80))
except BlockingIOError as e:
pass
自定义异步IO非阻塞


import socket import select class Request(object): def __init__(self,sk,callback): self.sk = sk self.callback = callback def fileno(self): return self.sk.fileno() class AsyncHttp(object): def __init__(self): self.fds = [] self.conn = [] def add(self,url,callback): sk = socket.socket() # 关闭IO阻塞 sk.setblocking(False) try: sk.connect((url,80)) except BlockingIOError as e: pass req = Request(sk,callback) self.fds.append(req) self.conn.append(req) def run(self): """ 监听socket是否发生变化 :return: """ while True: """ fds=[req(sk,callback),req,req] conn=[req,req,req] """ r,w,e = select.select(self.fds,self.conn,[],0.05) # sk.fileno() = req.fileno() # w=已经连接成功的socket列表 w=[sk1,sk2] for req in w: req.sk.sendall(b'GET /wupeiqi HTTP/1.1\r\nUser-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\r\n\r\n') # 已经连接成功的socket,无需再继续监听 self.conn.remove(req) # r=服务端给用户返回数据了 r=[sk1,] for req in r: data = req.sk.recv(8096) req.callback(data) req.sk.close() # 断开连接:短连接、无状态 self.fds.remove(req) # 不再监听 if not self.fds: break ah = AsyncHttp() def callback1(data): print(11111,data) def callback2(data): print(22222,data) def callback3(data): print(333333,data) ah.add('www.cnblogs.com',callback1) # sk1 ah.add('www.baidu.com',callback2) # sk2 ah.add('www.luffycity.com',callback3) # sk3 ah.run()
使用第三方模块
import asyncio import requests @asyncio.coroutine def fetch_async(func, *args): loop = asyncio.get_event_loop() future = loop.run_in_executor(None, func, *args) response = yield from future print(response.url, response.content) tasks = [ fetch_async(requests.get, 'http://www.cnblogs.com/wupeiqi/'), fetch_async(requests.get, 'http://dig.chouti.com/pic/show?nid=4073644713430508&lid=10273091') ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
import gevent from gevent import monkey monkey.patch_all() import requests def fetch_async(method, url, req_kwargs): print(method, url, req_kwargs) response = requests.request(method=method, url=url, **req_kwargs) print(response.url, response.content) # ##### 发送请求 ##### gevent.joinall([ gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}), ]) # ##### 发送请求(协程池控制最大协程数量) ##### # from gevent.pool import Pool # pool = Pool(None) # gevent.joinall([ # pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), # pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), # pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}), # ])
from twisted.web.client import getPage, defer from twisted.internet import reactor def all_done(arg): reactor.stop() def callback(contents): print(contents) deferred_list = [] url_list = ['http://www.bing.com', 'http://www.baidu.com', ] for url in url_list: deferred = getPage(bytes(url, encoding='utf8')) deferred.addCallback(callback) deferred_list.append(deferred) dlist = defer.DeferredList(deferred_list) dlist.addBoth(all_done) reactor.run()
原理问题
1、Http请求本质:
基于TCP的一种无状态短连接的数据传递(通过/r/n分割数据,请求头与请求体通过/r/n/r/n区分)
2、异步非阻塞
- 非阻塞:程序执行过程中遇到IO不等待
- 代码:
sk = socket.socket()
sk.setblocking(False) #会报错,捕获异常
- 异步:
- 通过执行回调函数:当达到某个指定的状态之后,自动调用特定函数。
3、IO多路复用
监听多个socket是否反正变化
- select,内部循环检测socket是否发生变化;最多检测1024个socket
- poll, 内部循环检测socket是否发生变化;
- epoll, 回调的方式
4、什么是协程
协程是一种“微线程”,实际并不存在,是人为创造出来的控制程序执行方式的:当程序执行时遇到IO时,则去执行另一个任务
--如果程序运行时,并没有遇到IO,这时程序来回切换——性能降低
--遇到IO时,程序来回切换——性能提高,实现了单线程并发
5. 自定义异步非阻塞模块?
- 基于事件循环(回调函数)
- 基于协程 (send(生成器))
本质:socket+IO多路复用
scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
下载安装:
安装scrapy a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted-xxxxx.whl 或者直接下载:d. pip3 install scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com e. pip3 install pywin32 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
创建 scrapy
scrapy startproject 项目名 cd xianglong scrapy genspider 文件名 文件名.com 运行项目 scrapy crawl chouti --nolog
解决中文问题:
加在文件开始位置
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
美图:
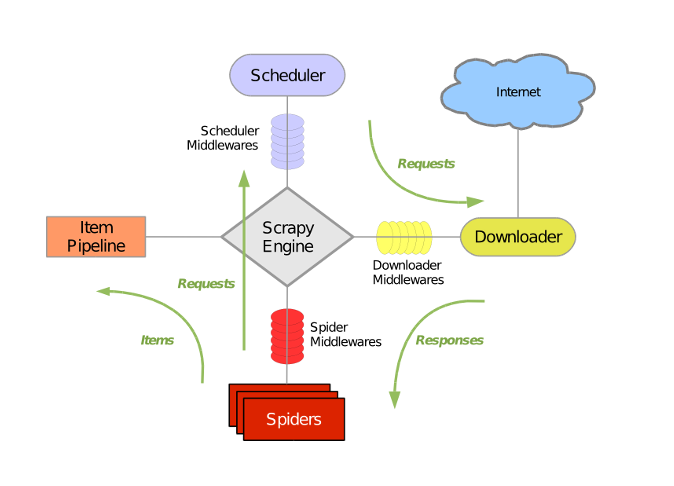
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
start_requests
连续爬多个网站
def start_requests(self): for url in self.start_urls: yield Request(url=url,callback=self.parse) def start_requests(self): req_list = [] for url in self.start_urls: req_list.append(Request(url=url,callback=self.parse)) return req_list scrapy内部会将req_list值转换成迭代器。
解析器
将字符串转换成对象
方式一:
response.xpath('//div[@id='content-list']/div[@class='item']') 格式可按照:copy xpath(页面)
方式二:
hxs = HtmlXPathSelector(response=response)
items = hxs.xpath("//div[@id='content-list']/div[@class='item']")
pipelines
处理spiders返回的item数据
settings.py
ITEM_PIPELINES = { 'pachoing.pipelines.FilePipeline': 300,
'pachoing.pipelines.xxxxxx': 400,
}
多个pipelines时值越小优先级越高
pipeline.py
class FilePipeline(object): def __init__(self,path): self.path = path self.f = None @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ path = crawler.settings.get('XL_FILE_PATH') return cls(path) def process_item(self, item, spider): self.f.write(item['href']+'\n') return item def open_spider(self, spider): """ 爬虫开始执行时,调用 :param spider: :return: """ self.f = open(self.path,'w') def close_spider(self, spider): """ 爬虫关闭时,被调用 :param spider: :return: """ self.f.close()
class FilePipeline(object):
pass
- 多pipelines,return item会将item传递给下一个pipelines的process_item
如果想要丢弃,不给后续pipeline使用:
from scrapy.exceptions import DropItem
class FilePipeline(object):
def process_item(self, item, spider):
raise DropItem()
处理post请求、请求头、cookies
手动添加cookies:
cookie_dict = {} def start_requests(self): for url in self.start_urls: yield Request(url=url,callback=self.parse_index) def parse_index(self,response): # 获取原始cookie # print(response.headers.getlist('Set-Cookie')) # 解析后的cookie from scrapy.http.cookies import CookieJar cookie_jar = CookieJar()
#将响应cookies放入cookie_jar cookie_jar.extract_cookies(response, response.request) for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): self.cookie_dict[m] = n.value req = Request( url='http://dig.chouti.com/login', method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='phone=8613121758648&password=woshiniba&oneMonth=1', cookies=self.cookie_dict, callback=self.parse_check_login ) yield req def parse_check_login(self,response): print(response.text) yield Request( url='https://dig.chouti.com/link/vote?linksId=19440976', method='POST', cookies=self.cookie_dict, callback=self.parse_show_result ) def parse_show_result(self,response): print(response.text)
自动添加cookies
def start_requests(self): for url in self.start_urls:
#自动携带cookies yield Request(url=url,callback=self.parse_index,meta={'cookiejar':True}) def parse_index(self,response): req = Request( url='http://dig.chouti.com/login', method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='phone=8613121758648&password=woshiniba&oneMonth=1', callback=self.parse_check_login, meta={'cookiejar': True} ) yield req def parse_check_login(self,response): # print(response.text) yield Request( url='https://dig.chouti.com/link/vote?linksId=19440976', method='POST', callback=self.parse_show_result, meta={'cookiejar': True} ) def parse_show_result(self,response): print(response.text)
去重
settings.py
DUPEFILTER_CLASS = 'pachong.dupe.MyDupeFilter'
dupe.py 自定义
class MyDupeFilter: def __init__(self): self.visited_url = set() @classmethod def from_settings(cls, settings): """ 初始化时,调用 :param settings: :return: """ return cls() def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ if request.url in self.visited_url: return True self.visited_url.add(request.url) return False def open(self): """ 开始爬去请求时,调用 :return: """ print('open replication') def close(self, reason): """ 结束爬虫爬取时,调用 :param reason: :return: """ print('close replication') def log(self, request, spider): """ 记录日志 :param request: :param spider: :return: """ print('repeat', request.url)
中间件
在所有操作请求前或响应后添加操作:它的流程与falsk中间流程相似
下载中间件: cookie、代理、user_agent
class DownMiddleware1(object): def process_request(self, request, spider): """ 请求需要被下载时,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception """ pass def process_response(self, request, response, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback """ print('response1') return response def process_exception(self, request, exception, spider): """ 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 :param response: :param exception: :param spider: :return: None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 """ return None
爬虫中间件
class SpiderMiddleware(object): def process_spider_input(self,response, spider): """ 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: """ pass def process_spider_output(self,response, result, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) """ return result def process_spider_exception(self,response, exception, spider): """ 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline """ return None def process_start_requests(self,start_requests, spider): """ 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 """ return start_requests
都需要在settings中配置
添加代理
1、内置添加代理
import os import scrapy from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['https://dig.chouti.com/'] def start_requests(self): os.environ['HTTP_PROXY'] = "http://192.168.11.11" #environ只能在一个进程中使用 for url in self.start_urls: yield Request(url=url,callback=self.parse) def parse(self, response): print(response)
2、使用下载中间件自定义添加代理(可以添加多个代理)
import random import base64 import six
#将str转化为bytes def to_bytes(text, encoding=None, errors='strict'): """Return the binary representation of `text`. If `text` is already a bytes object, return it as-is.""" if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class MyProxyDownloaderMiddleware(object): def process_request(self, request, spider): proxy_list = [ {'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(proxy_list) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) else: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
https
Https访问时有两种情况: 1. 要爬取网站使用的可信任证书(默认支持) DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" 2. 要爬取网站使用的自定义证书 DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory" # https.py from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory): def getCertificateOptions(self): from OpenSSL import crypto v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read()) v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read()) return CertificateOptions( privateKey=v1, # pKey对象 certificate=v2, # X509对象 verify=False, method=getattr(self, 'method', getattr(self, '_ssl_method', None)) ) 其他: 相关类 scrapy.core.downloader.handlers.http.HttpDownloadHandler scrapy.core.downloader.webclient.ScrapyHTTPClientFactory scrapy.core.downloader.contextfactory.ScrapyClientContextFactory 相关配置 DOWNLOADER_HTTPCLIENTFACTORY DOWNLOADER_CLIENTCONTEXTFACTORY
信号
框架内部已经定义好的,使用时可以直接调用,可以在其执行前后添加操作
extands.py
from scrapy import signals
class MyExtension(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): obj = cls() # 在爬虫打开时,触发spider_opened信号相关的所有函数:func1 crawler.signals.connect(obj.func1, signal=signals.spider_opened) # 在爬虫关闭时,触发spider_closed信号相关的所有函数:func2 crawler.signals.connect(obj.func2, signal=signals.spider_closed) return obj def func1(self, spider): print('open') def func2(self, spider): print('close')
settings.py
EXTENSIONS = { 'pachong.extends.MyExtension':500, }
自定制命令
1、创建一个与spiders同级的文件,如commands
2、在commamds文件中创建crawlall.py文件 (crawlall就是自定义的命名)
3、在settings.py配置
COMMANDS_MODULE = '项目名称.commands'
crawlall.py
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): #获取所有的爬虫 spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) #开始爬虫程序 self.crawler_process.start()
scrapy-redis
scrapy-redis是基于redis的scrapy组件,它实现了分布式爬虫程序,主要功能有:url去重、调度器、数据持久化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号