

自变量(x1, x2, x3...) 叫特征(feature)
因变量y 叫标签(label),有时也叫标记
训练数据集(training dataset)
测试数据集(test dataset)
拟合(fit)
监督学习(supervised learning)
无监督学习(unsupervised learning)
半监督学习(semi-supervised learning)
深度学习(deep learning)
人工神经网络(Artificial Neural Network, ANN)
深度学习:层数较多,结构比较复杂的神经网络的机器学习技术。
强化学习(reinforcement learning)研究的目标是智能体(agent)如何基于环境而做出行为反应,以取得最大化的累计奖励。
机器学习的两大应用场景:回归(regression), 分类(classification)
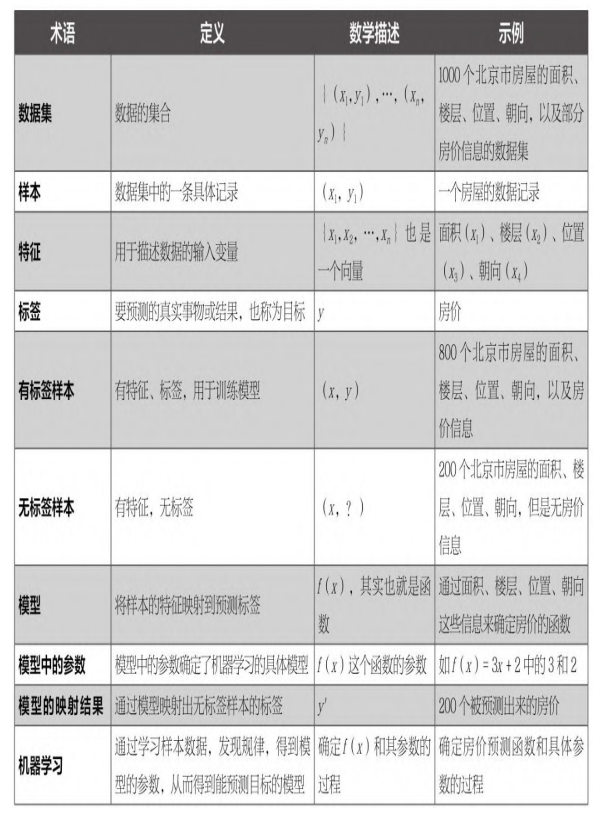
数据集:数据的集合
样本:数据集中的一条具体记录
特征:用于描述数据的输入变量
标签:要预测的真是事物或结果,亦称目标
有标签样本:有特征,有标签,用于训练模型
无标签样本:有特征,无标签
特征的维度指特征的数目
标签是试图预测的目标
模型就是函数,是执行预测的工具
机器学习的5个环节:
(1)问题定义
(2)数据的收集和预处理
(3)选择机器学习模型
(4)训练机器,确定参数
(5)超参数调试和性能优化
数据预处理:
可视化(visualization)
数据向量化(data vectorization)
处理坏数据和缺失值
特征缩放(feature scaling):标准化(standardization)(特别的,归一化),规范化(normalization)等
选择模型:
线性模型:线性回归,逻辑回归
非线性模型:支持向量机,K最邻近分类
基于树和集成的模型:决策树,随机森林,梯度提升树等
神经网络:人工神经网络,卷积神经网络,长短期记忆网络等
内部参数:
权重(wieght),偏置(bias | kernel)
超参数(hyperparameter)
优化(optimization)
泛化(generalization)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号