Elasticsearch常用操作命令——增删改查、集群维护
elasticsearch 根据id删除
允许从基于其id的特定索引中删除一个JSON文档,下面的示例从twitter中删除类型为_doc的JSON文档,其id为1:
DELETE /index/_doc/1上述删除操作的结果为:
{
"_shards" : {
"total" : 2,
"failed" : 0,
"successful" : 2
},
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_primary_term": 1,
"_seq_no": 5,
"result": "deleted"
}elasticsearch带路由删除
DELETE /index/doc_type/94d6cfcc828df7ba0fcdd8825eefe4a0?routing=1上述删除操作的结果为:
{
"_index": "test",
"_type": "relation",
"_id": "94d6cfcc828df7ba0fcdd8825eefe4a0",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 3406,
"_primary_term": 1
}elasticsearch 根据条件删除
POST /index/doc_type/_delete_by_query -- _delete_by_query是elasticsearch的删除指令
{
"query":{
"match":{
"id":"28"
}
}
}_delete_by_query会删除所有query语句匹配上的文档,用法如下:
curl -X POST "localhost:9200/twitter/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"name": "测试删除"
}
}
}
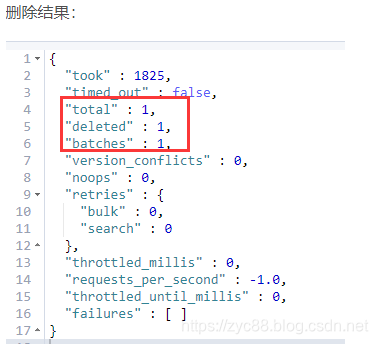
'先查看一下现有的记录:
GET /index/doc_type/_search
{
"query": {
"match": {
"id": "28"
}
}
}
当启动时(开始要删除时),_delete_by_query会得到索引(数据库)的快照并且使用内部版本号来找到要删除哪些文档。这意味着,如果获取到快照与执行删除过程的这段时间,有文档发生改变,那么版本就会冲突。通过版本控制匹配到的文档会被删除。
因为internal版本控制不支持0为有效数字,所以版本号为0的文档不能删除,并且请求将会失败。
在执行_delete_by_query期间,为了删除匹配到的所有文档,多个搜索请求是按顺序执行的。每次找到一批文档时,将会执行相应的批处理请求来删除找到的全部文档。如果搜索或者批处理请求被拒绝,_delete_by_query根据默认策略对被拒绝的请求进行重试(最多10次)。达到最大重试次数后,会造成_delete_by_query请求中止,并且会在failures字段中响应 所有的故障。已经删除的仍会执行。换句话说,该过程没有回滚,只有中断。
在第一个请求失败引起中断,失败的批处理请求的所有故障信息都会记录在failures元素中;并返回回去。因此,会有不少失败的请求。
如果你想计算有多少个版本冲突,而不是中止,可以在URL中设置为conflicts=proceed或者在请求体中设置"conflicts": "proceed"。
回到api格式中,你可以在一个单一的类型(即:表)中限制_delete_by_query。
下面仅仅只是删除索引(即:数据库)twitter中类型(即:表)tweet的所有数据:
curl -X POST "localhost:9200/twitter/_doc/_delete_by_query?conflicts=proceed" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}
'
一次删除多个索引(即:数据库)中的多个类型(即表)中的数据,也是可以的。例如:
curl -X POST "localhost:9200/twitter,blog/_docs,post/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}
'
如果你提供了routing,接着这个路由会被复制给scroll query,根据匹配到的路由值,来决定哪个分片来处理:
curl -X POST "localhost:9200/twitter/_delete_by_query?routing=1" -H 'Content-Type: application/json' -d'
{
"query": {
"range" : {
"age" : {
"gte" : 10
}
}
}
}
'
默认情况下,_delete_by_query自上而下批量1000条数据,你也可以在URL中使用参数scroll_size:
curl -X POST "localhost:9200/twitter/_delete_by_query?scroll_size=5000" -H 'Content-Type: application/json' -d'
{
"query": {
"term": {
"user": "kimchy"
}
}
}
'
elasticsearch新增文档
POST /index/doc_type/
{
"name":"test"
}elasticsearch修改文档
方式和添加一样,只不过要指定已经存在的id
POST /index/doc_type/94d6cfcc828df7ba0fcdd8825eefe4a0
{
"name":"test1"
}elasticsearch指定路由查询文档
GET /index/doc_type/94d6cfcc828df7ba0fcdd8825eefe4a0?routing=12. 例子
2.1 创建一个新的index
PUT /my_index2
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}
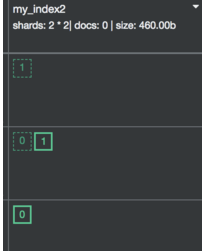
index只有2个shard,shard 0和 shard 1
2.2 设置mapping
PUT /my_index2/_mapping/student
{
"_routing": {
"required": true
},
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
2.3 指定doc路由
POST /my_index2/student/1?routing=key1
{
"name":"n1",
"age":10
}
POST /my_index2/student/2?routing=key1
{
"name":"n2",
"age":10
}
POST /my_index2/student/3?routing=key1
{
"name":"n3",
"age":10
}
上面的3条命令会使得doc1、2、3放置在同一个shard上shard 0
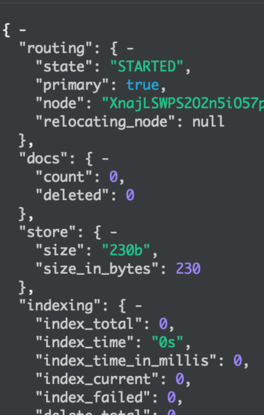
shard 1
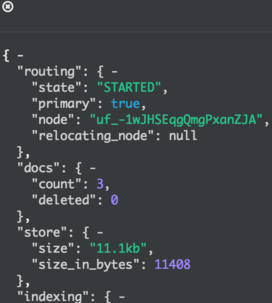
shard 0上的doc数是0,shard 1上的doc数是3,可见doc的分布是按照我们的要求来执行的。shard的具体编号由以下公式决定
shard_num = hash(_routing) % num_primary_shards
2.4 添加mapping字段
PUT /index/type/_mapping
{
"properties": {
"status": {
"type": "integer"
},
"start_time": {
"format": "yyyy-MM-dd HH:mm:ss",
"type": "date"
},
"end_time": {
"format": "yyyy-MM-dd HH:mm:ss",
"type": "date"
}
}
}初始化默认值:
用update_by_query结合script
POST my_index/_update_by_query
{
"script": {
"lang": "painless",
"inline": "if (ctx._source.status_code == null) {ctx._source.status_code= '02'}"
}
}就可以为新添加的字段设置默认值。
如果不加conflicts=proceed会出现版本冲突
POST index/type/_update_by_query?conflicts=proceed
{
"script": {
"lang": "painless",
"inline": "if (ctx._source.字段== null) {ctx._source.字段 = '0'}"
}
}或者可以带条件:
POST index/type/_update_by_query?conflicts=proceed
{
"script": {
"lang": "painless",
"inline": "if (ctx._source.字段== null) {ctx._source.字段 = '0'}"
},
"query": {
"match_phrase": {
"obj_level": "01"
}
}
}
多字段操作:
POST index/type/_update_by_query?conflicts=proceed
{
"script": {
"lang": "painless",
"inline": "if (ctx._source.字段1== null) {ctx._source.字段1 = '0'} if (ctx._source.字段2== null) {ctx._source.字段2 = '0'}"
},
"query": {
"match_phrase": {
"obj_level": "01"
}
}
}当es中数据量非常巨大时,一次请求不能完全执行成功,会出现超时(默认1分钟)。
此时采用带有搜索条件的批量操作,如下:
POST index/type/_update_by_query?conflicts=proceed
{
"script": {
"inline": "ctx._source.字段1='1';ctx._source.字段2='2'"
},
"query": {
"range": {
"id": {
"gte": 0,
"lte": 10000
}
}
}
}
3. 作用
那么自定义routing到底有什么作用呢?
我们知道,正常的一次查询(search),请求会被发给所有shard(不考虑副本),然后等所有shard返回,再将结果聚合,返回给调用方。如果我们事先已经知道数据可能分布在哪些shard上,那么就可以减少不必要的请求。
GET /_search_shards?routing=key1
返回
{
"shards": [
[
{
"state": "STARTED",
"primary": true, // 主副本
"node": "uf_-1wJHSEqgQmgPxanZJA",
"relocating_node": null,
"shard": 1, // 只需要检索`shard` 1
"index": "my_index2",
"allocation_id": {
"id": "tZzcW3DRQ12QzGJXvVswvQ"
}
},
{
"state": "STARTED",
"primary": false, // 从副本
"node": "3bo9Z0krShyAK-t_F5Fo8A",
"relocating_node": null,
"shard": 1, // 只需要检索`shard` 1
"index": "my_index2",
"allocation_id": {
"id": "NWILXOXcTGCXYHrgPJ6_-A"
}
}
]
]
}
下面的查询只会检索与routing key,”key1″和”key2″相关的shard
GET /my_index2/_search?routing=key1,key2
{
"query": {
"term": {
"name": "n2"
}
}
}========elasticsearch常用操作命令 集群维护=========
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates例如:
1、节点运行状况维度:内存,磁盘和CPU指标
当Elasticsearch集群中有节点挂掉,我们可以去查看集群的日志信息查找错误,不过在查找错误日志之前,我们可以通过elasticsearch的cat api简单判断下各个节点的状态,包括磁盘,heap,ram的使用情况,先做初步判断。
查看集群资源使用情况
curl -XGET 'http://localhost:9200/_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,master 'eg:
localhost:9200/_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,master 返回:
http version jdk disk.total disk.used disk.avail disk.used_percent heap.current heap.percent heap.max ram.current ram.percent ram.max master
10.0.0.4:9200 6.3.1 1.8.0_181 29gb 3.3gb 25.6gb 11.72 254mb 7 3.3gb 6.2gb 92 6.8gb -
10.0.0.5:9200 6.3.1 1.8.0_181 29gb 3.3gb 25.6gb 11.71 195.5mb 5 3.3gb 6.2gb 91 6.8gb -
10.0.0.6:9200 6.3.1 1.8.0_181 29gb 3.4gb 25.6gb 11.74 293.6mb 8 3.3gb 6.2gb 92 6.8gb *JSON化:
GET _cat/nodes?v&h=id,disk.total,disk.used,disk.avail,disk.used_percent,ram.current,ram.percent,ram.max,cpu&format=json&pretty
返回结果:
[
{
"id" : "yrVc",
"disk.avail" : "17.7gb",
"ram.current" : "2.6gb",
"ram.percent" : "56",
"ram.max" : "4.6gb",
"cpu" : "0"
}
]节点运行的重要指标:
- disk.total :总磁盘容量。节点主机上的总磁盘容量。
- disk.used:总磁盘使用量。节点主机上的磁盘使用总量。
- avail disk:可用磁盘空间总量。
- disk.avail disk.used_percent:使用的磁盘百分比。已使用的磁盘百分比。
- ram:当前的RAM使用情况。当前内存使用量(测量单位)。
- percent ram:RAM百分比。正在使用的内存百分比。
- max : 最大RAM。 节点主机上的内存总量
- cpu:中央处理器。正在使用的CPU百分比。
此处的disk占用,heap使用量等都是监测集群状态的关键参数,更多参数可以官网cat node api参考此处。
2、JVM运行状况维度:堆,GC和池大小
Elasticsearch是一个严重依赖内存 以实现性能的系统,因此密切关注内存使用情况与每个节点的运行状况和性能相关。改进指标的相关配置更改也可能会对内存分配和使用产生负面影响,因此记住从整体上查看系统运行状况非常重要。
GET /_nodes/stats返回结果:
...
"jvm" : {
"timestamp" : 1557588707194,
"uptime_in_millis" : 22970151,
"mem" : {
"heap_used_in_bytes" : 843509048,
"heap_used_percent" : 40,
"heap_committed_in_bytes" : 2077753344,
"heap_max_in_bytes" : 2077753344,
"non_heap_used_in_bytes" : 156752056,
"non_heap_committed_in_bytes" : 167890944,
"pools" : {
"young" : {
"used_in_bytes" : 415298464,
"max_in_bytes" : 558432256,
"peak_used_in_bytes" : 558432256,
"peak_max_in_bytes" : 558432256
},
"survivor" : {
"used_in_bytes" : 12178632,
"max_in_bytes" : 69730304,
"peak_used_in_bytes" : 69730304,
"peak_max_in_bytes" : 69730304
},
"old" : {
"used_in_bytes" : 416031952,
"max_in_bytes" : 1449590784,
"peak_used_in_bytes" : 416031952,
"peak_max_in_bytes" : 1449590784
}
}
},
"threads" : {
"count" : 116,
"peak_count" : 119
},
"gc" : {
"collectors" : {
"young" : {
"collection_count" : 260,
"collection_time_in_millis" : 3463
},
"old" : {
"collection_count" : 2,
"collection_time_in_millis" : 125
}
}
}
JVM运行的重要指标如下:
- mem:内存使用情况。堆和非堆进程和池的使用情况统计信息。
- threads:当前使用的线程和最大数量。
- gc:垃圾收集。算和垃圾收集所花费的总时间。
3、搜索性能维度:请求率和延迟
请求过程本身分为两个阶段:
- 第一是查询阶段(query phase),集群将请求分发到索引中的每个分片(主分片或副本分片)。
- 第二个是获取阶段(fetch phrase),查询结果被收集,处理并返回给用户。
通过GET {index}/_stats查看对应目标索引状态。
GET {index}/_statsf返回结果:
...
"search" : {
"open_contexts" : 0,
"query_total" : 10,
"query_time_in_millis" : 0,
"query_current" : 0,
"fetch_total" : 1,
"fetch_time_in_millis" : 0,
"fetch_current" : 0,
"scroll_total" : 5,
"scroll_time_in_millis" : 15850,
"scroll_current" : 0,
"suggest_total" : 0,
"suggest_time_in_millis" : 0,
"suggest_current" : 0
}请求检索性能相关的重要指标如下:
- query_current:当前正在进行的查询数。集群当前正在处理的查询计数。
- fetch_current:当前正在进行的fetch次数。集群中正在进行的fetch计数。
- query_total:查询总数。集群处理的所有查询的聚合数。
- query_time_in_millis:查询总耗时。所有查询消耗的总时间(以毫秒为单位)。
f- etch_total:提取总数。集群处理的所有fetch的聚合数。
f- etch_time_in_millis:fetch所花费的总时间。所有fetch消耗的总时间(以毫秒为单位)。
4、索引性能维度:刷新(refresh)和合并(Merge)时间
文档的增、删、改操作,集群需要不断更新其索引,然后在所有节点上刷新它们。所有这些都由集群负责,作为用户,除了配置 refresh interval 之外,我们对此过程的控制有限。
增、删、改批处理操作,会形成新段(segment)并刷新到磁盘,并且由于每个段消耗资源,因此将较小的段合并为更大的段对于性能非常重要。同上类似,这由集群本身管理。
监视文档的索引速率( indexing rate )和合并时间(merge time)有助于在开始影响集群性能之前提前识别异常和相关问题。将这些指标与每个节点的运行状况并行考虑,这些指标为系统内的潜问题提供重要线索,为性能优化提供重要参考。
可以通过GET /_nodes/stats 获取索引性能指标,并可以在节点,索引或分片级别进行汇总。
GET /_nodes/stats返回结果:
...
"merges" : {
"current" : 0,
"current_docs" : 0,
"current_size_in_bytes" : 0,
"total" : 245,
"total_time_in_millis" : 58332,
"total_docs" : 1351279,
"total_size_in_bytes" : 640703378,
"total_stopped_time_in_millis" : 0,
"total_throttled_time_in_millis" : 0,
"total_auto_throttle_in_bytes" : 2663383040
},
"refresh" : {
"total" : 2955,
"total_time_in_millis" : 244217,
"listeners" : 0
},
"flush" : {
"total" : 127,
"periodic" : 0,
"total_time_in_millis" : 13137
},索引性能维度相关重要指标:
- refresh.total:总刷新计数。刷新总数的计数。
- refresh.total_time_in_millis:刷新总时间。汇总所有花在刷新的时间(以毫秒为单位进行测量)。
- merges.current_docs:目前的合并。合并目前正在处理中。
- merges.total_docs:合并总数。合并总数的计数。
- merges.total_stopped_time_in_millis。合并花费的总时间。合并段的所有时间的聚合。
主要指标梳理
- Cluster Health – Nodes and Shards
- Search Performance – Request Latency and
- Search Performance – Request Rate
- Indexing Performance – Refresh Times
- Indexing Performance – Merge Times
- Node Health – Memory Usage
- Node Health – Disk I/O
- Node Health – CPU
- JVM Health – Heap Usage and Garbage Collection
- JVM health – JVM Pool Size
其它操作:
(1)elasticsearch 查看集群统计信息
curl -XGET 'http://localhost:9200/_cluster/stats?pretty' (2)elasticsearch 查看所有索引
curl 'localhost:9200/_cat/indices?v' (3)elasticsearch 查看集群的节点列表
curl 'localhost:9200/_cat/nodes?v' (4)elasticsearch 检测集群是否健康
curl 'localhost:9200/_cat/health?v' (5)elasticsearch 创建索引
curl -XPUT 'localhost:9200/customer?pretty'(6)elasticsearch 插入数据
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'(7)elasticsearch 获取数据
curl -XGET 'localhost:9200/customer/external/1?pretty'
获取customer索引下类型为external,id为1的数据,pretty参数表示返回结果格式美观。(8)elasticsearch 删除索引
curl -XDELETE 'localhost:9200/customer?pretty' (9)elasticsearch 修改数据
新增
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'修改
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "Jane Doe"
}'
先新增id为1,name为John Doe的数据,然后将id为1的name修改为Jane Doe。
(10)elasticsearch 更新数据
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '
{
"doc": { "name": "Jane Doe" }
}'多字段
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '{
"doc": { "name": "Jane Doe", "age": 20 }
}'脚本化
curl -XPOST 'localhost:9200/customer/external/1/_update?pretty' -d '{
"script" : "ctx._source.age += 5"
}'
(11)elasticsearch 删除数据
//将执行删除Customer中ID为2的数据
curl -XDELETE 'localhost:9200/customer/external/2?pretty'
//创建索引
curl -XPUT 'localhost:9200/customer'
//插入数据
curl -XPUT 'localhost:9200/customer/external/1'-d '
{
"name": "John Doe"
}'
//查询数据
curl 'localhost:9200/customer/external/1'
//删除索引
curl -XDELETE 'localhost:9200/customer'
(12)elasticsearch 批处理
批量操作中执行创建索引:
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d '
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
'
下面语句批处理执行更新id为1的数据然后执行删除id为2的数据
curl -XPOST 'localhost:9200/customer/external/_bulk?pretty' -d '
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}'(13)elasticsearch 导入数据集
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary "@accounts.json"curl 'localhost:9200/_cat/indices?v' 查看
(14)elasticsearch 查询数据
curl 'localhost:9200/bank/_search?q=*&pretty'
返回所有bank中的索引数据。其中 q=* 表示匹配索引中所有的数据。
等价于:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} }
}' 匹配所有数据,但只返回1个:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"size": 1
}'
注意:如果siez不指定,则默认返回10条数据。
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"from": 10,
"size": 10
}' 返回从11到20的数据。(索引下标从0开始)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}'上述示例匹配所有的索引中的数据,按照balance字段降序排序,并且返回前10条(如果不指定size,默认最多返回10条)。
(15)elasticsearch 搜索
返回两个字段(account_number balance)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}' 返回account_number 为20 的数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "account_number": 20 } }
}'返回address中包含mill的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "address": "mill" } }
}'返回地址中包含mill或者lane的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match": { "address": "mill lane" } }
}'和上面匹配单个词语不同,下面这个例子是多匹配(match_phrase短语匹配),返回地址中包含短语 “mill lane”的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_phrase": { "address": "mill lane" } }
}' 以下是布尔查询,布尔查询允许我们将多个简单的查询组合成一个更复杂的布尔逻辑查询。这个例子将两个查询组合,返回地址中含有mill和lane的所有记录数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'
上述例子中,must表示所有查询必须都为真才被认为匹配。
相反, 这个例子组合两个查询,返回地址中含有mill或者lane的所有记录数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"should": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'上述例子中,bool表示查询列表中只要有任何一个为真则认为匹配。
下面例子组合两个查询,返回地址中既没有mill也没有lane的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must_not": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}'
上述例子中,must_not表示查询列表中没有为真的(也就是全为假)时则认为匹配。
我们可以组合must、should、must_not来实现更加复杂的多级逻辑查询。
下面这个例子返回年龄大于40岁、不居住在ID的所有数据:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}'(16) elasticsearch 过滤filter(查询条件设置)
下面这个例子使用了布尔查询返回balance在20000到30000之间的所有数据。
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}'(17) elasticsearch 聚合 Aggregations
下面这个例子: 将所有的数据按照state分组(group),然后按照分组记录数从大到小排序,返回前十条(默认):
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state"
}
}
}
}'下面这个实例按照state分组,降序排序,返回balance的平均值:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}'(18)elasticsearch 取得某个索引中某个字段中的所有出现过的值
这种操作类似于使用SQL的SELECT UNIQUE语句。当需要获取某个字段上的所有可用值时,可以使用terms聚合查询完成:
GET /index_streets/_search?search_type=count
{
"aggs": {
"street_values": {
"terms": {
"field": "name.raw",
"size": 0
}
}
}
}因为目标是得到name字段上的所有出现过的值,因此search_type被设置为了count,这样在返回的响应中不会出现冗长的hits部分。另外,查询的目标字段的索引类型需要设置为not_analyzed。所以上面的field指定的是name.raw。
得到的响应如下所示:
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 7445,
"max_score": 0,
"hits": []
},
"aggregations": {
"street_values": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "江苏路",
"doc_count": 29
},
{
"key": "南京东路",
"doc_count": 28
},
...
...
...
(19)elasticsearch 取得某个索引/类型下某个字段中出现的不同值的个数
这种操作类似于使用SQL的select count( ) from (select distinct from table)语句。当需要获取某个字段上的出现的不同值的个数时,可以使用cardinality聚合查询完成:
GET /index_streets/_search?search_type=count
{
"aggs": {
"uniq_streets": {
"cardinality": {
"field": "name.raw"
}
}
}
}因为目标是得到name字段上的所有出现过的值,因此search_type被设置为了count,这样在返回的响应中不会出现冗长的hits部分。另外,查询的目标字段如果是字符串类型的,那么其索引类型需要设置为not_analyzed。所以上面的field指定的是name.raw。
得到的响应如下所示:
{
"took": 96,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 4136543,
"max_score": 0,
"hits": []
},
"aggregations": {
"uniq_streets": {
"value": 1951
}
}
}
(20)elasticsearch 每个命令都支持使用?v参数,来显示详细的信息:
curl localhost:9200/_cat/master?v id host ip node
yBet3cYzQbC68FRzLZDmFg 127.0.0.1 127.0.0.1 lihao
(21)elasticsearch 每个命令都支持使用help参数,来输出可以显示的列:
curl localhost:9200/_cat/master?help id | | node id
host | h | host name
ip | | ip address
node | n | node name
(22)elasticsearch 通过h参数,可以指定输出的字段:
curl localhost:9200/_cat/master?v
id host ip node
yBet3cYzQbC68FRzLZDmFg 127.0.0.1 127.0.0.1 lihao
curl localhost:9200/_cat/master?h=ip,node
127.0.0.1 lihao
(23) elasticsearch 很多的命令都支持返回可读性的大小数字,比如使用mb或者kb来表示。
curl localhost:9200/_cat/indices?v
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open aaa 5 1 2 0 7.2kb 7.2kb
yellow open logstash-eos-2016.09.01 5 1 297 0 202.3kb 202.3kb
yellow open bank 5 1 1001 1 451.6kb 451.6kb
yellow open website 5 1 2 0 7.8kb 7.8kb
yellow open .kibana 1 1 5 1 26.6kb 26.6kb
yellow open logstash-eos-2016.09.02 5 1 11 0 33.9kb 33.9kb
yellow open test-2016.09.01 5 1 1 0 3.9kb 3.9kb
yellow open testst_index 5 1 0 0 795b 795b
PS: 返回字段说明:
Versioning
索引的每个文档都是版本化的。在删除文档时,可以指定版本,以确保正在删除的相关文档实际上正在被删除,同时它也没有改变。每个在文档上执行的写操作,包括删除,都会使其版本增加。删除文档的版本号可以在删除后短时间内可用,以控制并发操作。删除文档的版本仍然可用的时间长度由索引决定。gc_deletes索引设置和默认设置为60秒。
Routing
当索引使用控制路由的能力时,为了删除文档,也应该提供路由值。例如:
DELETE /twitter/_doc/1?routing=kimchy上面的消息将会删除一条id为1的tweet,但是会基于用户发送。注意,在没有正确路由的情况下发出删除,将导致文档不被删除。 当将_routing映射设置为required且没有指定路由值时,delete api将抛出一个RoutingMissingException并拒绝该请求。
Automatic index creation
如果使用外部版本变体,删除操作会自动创建索引,如果没有之前创建(create index API手动创建一个索引),并自动创建一个动态类型映射为特定类型,如果没有之前创建(查看手动映射API创建类型映射)。
Distributed
删除操作被散列到一个特定的shard id中,然后被重定向到该id组内的主分片,并在该id组中复制(如果需要)到shard副本。
Wait For Active Shards
在删除请求时,您可以设置wait_for_active_shards参数,在开始处理删除请求之前,需要使用最少的shard副本。有关详细信息和使用示例,请参阅此处。
Refresh
在搜索时,可以看到该请求所做的更改。看到了什么?刷新。
Timeout
在执行删除操作时,指定执行删除操作的主碎片可能无法使用。一些原因可能是,主要碎片目前正在从商店中恢复,或者正在进行重新安置。默认情况下,delete操作在失败和响应一个错误前将在主分片上等待1分钟。timeout参数可用于显式指定等待的时间。这里有一个设置为5分钟的例子:
DELETE /twitter/_doc/1?timeout=5meg:自己的例子:
在policy_document中删除类型为policy_document的,id=e_87431dc564341cf2cc1af8d2877476df的文档
DELETE policy_document/policy_document/e_87431dc564341cf2cc1af8d2877476df返回结果:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}PS: 高级参数说明
URL Parameters(url 参数)
除了标准参数像pretty,Delete By Query API也支持refresh、wait_for_completion、wait_for_active_shards和timeout。
发送带refresh参数的请求一旦完成,在delete by queryapi中涉及到的所有分片都将会刷新。这不同于Delete API中的refresh参数,其是在收到删除请求时就刷新分片。
如果请求中包含wait_for_completion=false,那么elasticsearch将会执行预检查、启动请求,并返回一个可被Tasks APIs使用的task,以取消或者得到task状态。elasticsearch也将会在.tasks/task/${taskId}路径中创建一个文档来记录这个task。你可以根据自己的情况来选择保留还是删除它;当你删除后,elasticsearch会回收利用它的空间。
在处理请求之前,wait_for_active_shards控制需要多少个副本分片必须处于活动状态。详情这里。timeout用于控制每个写请求等待不可用分片变成可用分片的时间。两者都能在Bulk API中正常工作。
requests_per_second可以设置任何正的十进制数字(1.4、6、1000等等)并且可以限制delete-by-query发出的每秒请求数量或者将其设置为-1来禁用这种限制。这种限制会在批处理之间等待,以便于其能操作scroll timeout。这个等待时间与完成批处理之间的时间和requests_per_second * requests_in_the_batch时间是有区别的。由于批处理不会分解成多个请求,而如此大的批处理将会造成elasticsearch创建多个请求并且会在开始下个集合(批处理)之前等待一会,这是bursty而不是smooth。默认为-1。
Response body(响应体)
响应体的json格式如下:
{
"took" : 639,
"deleted": 0,
"batches": 1,
"version_conflicts": 2,
"retries": 0,
"throttled_millis": 0,
"failures" : [ ]
}
参数 描述
took 从整个操作开始到结束花费的时间,单位是毫秒
deleted 成功删除文档的数量
batches 通过delete by query返回滚动响应的数量(我的看法:符合delete by query条件的文档数量)
version_conflicts delete by queryapi命中的冲突版本的数量(即在执行过程中,发生了多少次冲突)
retries 在delete by query api响应一个完整队列,重试的次数
throttled_millis 根据requests_per_second,请求睡眠多少毫秒
failures 是个数组,表示失败的所有索引(插入);如果它不为空的话,那么请求会因为故障而中止。可以参考如何防止版本冲突而中止操作。
Works with the Task API
你可以使用Task API来获取任何一个正在运行的delete-by-query请求的状态。
curl -X GET "localhost:9200/_tasks?detailed=true&actions=*/delete/byquery"
响应
{
"nodes" : {
"r1A2WoRbTwKZ516z6NEs5A" : {
"name" : "r1A2WoR",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"attributes" : {
"testattr" : "test",
"portsfile" : "true"
},
"tasks" : {
"r1A2WoRbTwKZ516z6NEs5A:36619" : {
"node" : "r1A2WoRbTwKZ516z6NEs5A",
"id" : 36619,
"type" : "transport",
"action" : "indices:data/write/delete/byquery",
"status" : { [](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-delete-by-query.html#CO38-1)
"total" : 6154,
"updated" : 0,
"created" : 0,
"deleted" : 3500,
"batches" : 36,
"version_conflicts" : 0,
"noops" : 0,
"retries": 0,
"throttled_millis": 0
},
"description" : ""
}
}
}
}
}</pre>
①这个对象包含实际的状态。响应体是json格式,其中total字段是非常重要的。total表示期望执行reindex操作的数量。你可以通过加入的updated、created和deleted字段来预估进度。但它们之和等于total字段时,请求将结束。
使用task id可以直接查找此task。
curl -X GET "localhost:9200/_tasks/taskId:1"
这个api的优点是它整合了wait_for_completion=false来透明的返回已完成任务的状态。如果此任务完成并且设置为wait_for_completion=false,那么其将返回results或者error字段。这个特性的代价就是当设置wait_for_completion=false时,会在.tasks/task/${taskId}中创建一个文档。当然你也可以删除这个文档。
curl -X POST "localhost:9200/_tasks/task_id:1/_cancel"
可以使用上面的task api来找到task_id;
取消应该尽快发生,但是也可能需要几秒钟,上面的task 状态 api将会进行列出task直到它被唤醒并取消自己。
curl -X POST "localhost:9200/_delete_by_query/task_id:1/_rethrottle?requests_per_second=-1"
Rethrottling
requests_per_second的值可以在使用_rethrottle参数的正在运行的delete by queryapi上进行更改:
curl -X POST "localhost:9200/_delete_by_query/task_id:1/_rethrottle?requests_per_second=-1"
使用上面的tasks API来查找task_id
就像在_delete_by_query中设置一样,requests_per_second可以设置-1来禁止这种限制或者任何一个10进制数字,像1.7或者12来限制到这种级别。加速查询的Rethrottling会立即生效,但是缓慢查询的Rethrottling将会在完成当前批处理后生效。这是为了防止scroll timeouts。
Manually slicing
Delete-by-query支持Sliced Scroll,其可以使你相对容易的手动并行化进程:
curl -X POST "localhost:9200/twitter/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"slice": {
"id": 0,
"max": 2
},
"query": {
"range": {
"likes": {
"lt": 10
}
}
}
}
'
curl -X POST "localhost:9200/twitter/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"slice": {
"id": 1,
"max": 2
},
"query": {
"range": {
"likes": {
"lt": 10
}
}
}
}
'
你可以通过以下方式进行验证:
curl -X GET "localhost:9200/_refresh"
curl -X POST "localhost:9200/twitter/_search?size=0&filter_path=hits.total" -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"likes": {
"lt": 10
}
}
}
}
'
像下面这样只有一个total是合理的:
{
"hits": {
"total": 0
}
}
Automatic slicing
你也可以使用Sliced Scroll让delete-by-query api自动并行化,以在_uid上切片:
curl -X POST "localhost:9200/twitter/_delete_by_query?refresh&slices=5" -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"likes": {
"lt": 10
}
}
}
}
'
你可以通过以下来验证:
curl -X POST "localhost:9200/twitter/_search?size=0&filter_path=hits.total" -H 'Content-Type: application/json' -d'
{
"query": {
"range": {
"likes": {
"lt": 10
}
}
}
}
'
像下面的total是一个合理的结果:
{
"hits": {
"total": 0
}
}
添加slices,_delete_by_query将会自动执行上面部分中使用手动处理的部分,创建子请求这意味着有些怪事:
- 你可以在
Tasks APIs中看到这些请求。这些子请求是使用了slices请求任务的子任务。 - 为此请求(使用了
slices)获取任务状态仅仅包含已完成切片的状态。 - 这些子请求都是独立寻址的,例如:取消和
rethrottling. - Rethrottling the request with slices will rethrottle the unfinished sub-request proportionally.
- 取消
slices请求将会取消每个子请求。 - 由于
slices的性质,每个子请求并不会得到完全均匀的文档结果。所有的文档都将要处理,但是有些slices(切片)会大些,有些会小些。希望大的slices(切片)有更均匀的分配。 - 在
slices请求中像requests_per_second和size参数,按比例分配给每个子请求。结合上面的关于分配的不均匀性,你应该得出结论:在包含slices的_delete_by_query请求中使用size参数可能不会得到正确大小的文档结果。 - 每个子请求都会获得一个略微不同的源索引快照,尽管这些请求都是大致相同的时间。
Picking the number of slices
这里我们有些关于slices数量的建议(如果是手动并行的话,那么在slice api就是max参数):
- 不要使用大数字。比如500,将会创建相当大规模的
CPU震荡。
这里说明下震荡(thrashing)的意思:cpu大部分时间都在进行换页,而真正工作时间却很短的现象称之为thrashing (震荡) - 从查询性能角度来看,在源索引中使用多个分片是更高效的。
- 从查询性能角度来看,在源索引中使用和分片相同的数量是更高效的。
- 索引性能应该在可利用
slices之间进行线性扩展。 - 索引(插入)或查询性能是否占主导地位取决于诸多因素,比如:重新索引文档和集群进行重新索引。
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-delete-by-query.html
https://www.cnblogs.com/Neeo/articles/10869556.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号