

def __init__(self, k=40, normal_channel=True):
__init__方法是一个特殊的方法,用于类的初始化。当创建一个类的新实例时,__init__方法会自动被调用,以设置对象的初始状态或属性。
self.feat = PointNetEncoder(global_feat=True, feature_transform=True, channel=channel)
特征转换是数据预处理最重要的过程之一,因为在某些算法中,会给较大特征值以更大的权重,会使结果受到严重影响,所以要对数据进行缩放
- standardization 标准化

- Min/Max Scaling/ Normalization
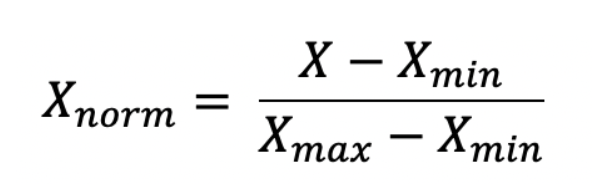
- Robust Scaler 当数据集有太多异常值时,标准化和归一化不好处理

- Logarithmic Transformation
- Reciprocal Transformation
- Square Root Translation
- Box Cox 将数据转为正态分布
def parse_args(): parser = argparse.ArgumentParser('Model') parser.add_argument('--model', type=str, default='pointnet_part_seg', help='model name') parser.add_argument('--batch_size', type=int, default=16, help='batch Size during training') parser.add_argument('--epoch', default=251, type=int, help='epoch to run') parser.add_argument('--learning_rate', default=0.001, type=float, help='initial learning rate') parser.add_argument('--gpu', type=str, default='0', help='specify GPU devices') parser.add_argument('--optimizer', type=str, default='Adam', help='Adam or SGD') parser.add_argument('--log_dir', type=str, default=None, help='log path') parser.add_argument('--decay_rate', type=float, default=1e-4, help='weight decay') parser.add_argument('--npoint', type=int, default=2048, help='point Number') parser.add_argument('--normal', action='store_true', default=False, help='use normals') parser.add_argument('--step_size', type=int, default=20, help='decay step for lr decay') parser.add_argument('--lr_decay', type=float, default=0.5, help='decay rate for lr decay') return parser.parse_args()
使用了 Python 的 argparse 库来解析命令行参数。argparse 是 Python 标准库中的一个模块,用于编写用户友好的命令行接口。
使用了 Python 的 argparse 库来解析命令行参数。argparse 是 Python 标准库中的一个模块,用于编写用户友好的命令行接口。下面是对这段代码中每个 add_argument 方法的解释:
-
--model: 这个参数允许用户指定模型名称。默认值是'pointnet_part_seg'。 -
--batch_size: 指定训练时的批量大小。默认值是16。 -
--epoch: 指定要运行的轮次(epoch)数。默认值是251。 -
--learning_rate: 指定初始学习率。默认值是0.001。 -
--gpu: 指定要使用的 GPU 设备。默认值是'0',表示使用第一个 GPU。 -
--optimizer: 指定优化器类型。默认值是'Adam',另一个选项是'SGD'。 -
--log_dir: 指定日志路径。默认值是None,意味着用户可能需要手动指定一个路径来保存日志。 -
--decay_rate: 指定权重衰减率(也称为正则化项的系数)。默认值是1e-4。 -
--npoint: 指定点的数量。默认值是2048。 -
--normal: 一个布尔标志,用于指示是否使用法线(normals)。如果指定了这个参数(即--normal),则默认值为True;否则为False。 -
--step_size: 指定学习率衰减的步长。默认值是20。 -
--lr_decay: 指定学习率衰减的比率。默认值是0.5。
x = F.log_softmax(x, dim=1)
dim=0通常表示沿着最外层的维度(即批处理大小batch size的维度->矩阵的第一个维度(索引为0的维度),它对应于批次中的图像数量)进行操作。dim=1则通常表示沿着特征的维度(即每个样本的特征或类别的维度)进行操作。
iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(
batchsize, 1)
new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]
torch.eye 是 PyTorch 中的一个函数,用于生成一个二维的张量(矩阵),这个矩阵是对角矩阵,即主对角线上的元素为1,其余位置上的元素为0。torch.eye(n, m=None, *, dtype=None, layout=torch.strided, device=None, requires_grad=False)
n(int):矩阵的行数。m(int, optional):矩阵的列数。如果未指定,默认为n,即生成一个n x n的方阵。dtype(torch.dtype, optional):返回张量的数据类型。如果不指定,则默认使用全局默认数据类型(通常是torch.float32)。layout(torch.layout, optional):返回张量的内存布局。默认为torch.strided。device(torch.device, optional):返回张量的设备。如果不指定,则使用当前默认设备。requires_grad(bool, optional):如果为True,则返回的张量将计算梯度。默认为False。
total_seen_class = [0 for _ in range(num_part)]
这行代码是在Python中创建一个名为total_seen_class的列表,列表的长度由变量num_part决定。列表中的每个元素都被初始化为0。
for _ in range(num_part):这是一个循环,range(num_part)生成一个从0到num_part-1的序列(如果num_part是正整数的话)。_是一个常用的占位符,表示循环变量在循环体中不会被使用。
#处理一批图像分割的预测结果,并将这些结果转换为最终的类别标签
for i in range(cur_batch_size): cat = seg_label_to_cat[target[i, 0]] logits = cur_pred_val_logits[i, :, :] cur_pred_val[i, :] = np.argmax(logits[:, seg_classes[cat]], 1) + seg_classes[cat][0]
#seg_label_to_cat是一个映射,用于将目标标签(target)转换为类别标识符
-
for i in range(cur_batch_size)::这个循环遍历当前批次中的每个样本。 -
cat = seg_label_to_cat[target[i, 0]]:对于批次中的第i个样本,从target张量中获取其目标标签(通常位于每个样本的第一列或第一维,这里假设是第一列),并使用seg_label_to_cat映射将其转换为类别标识符cat。 -
logits = cur_pred_val_logits[i, :, :]:从cur_pred_val_logits张量中获取第i个样本的预测logits。这些logits是模型对每个像素属于不同类别的原始预测分数。 -
cur_pred_val[i, :] = np.argmax(logits[:, seg_classes[cat]], 1) + seg_classes[cat][0]:logits[:, seg_classes[cat]]:从logits中选取对应于当前类别cat的分数。这里假设seg_classes[cat]返回了一个包含该类别所有可能标签的列表或数组,因此这个操作是在选取logits中与这些标签对应的列。np.argmax(..., 1):沿着第二个维度(维度索引为1,因为Python是从0开始计数的)找到最大值的索引。这意味着对于每个像素,我们都找到了具有最高分数的类别标签的索引。+ seg_classes[cat][0]:由于np.argmax返回的是索引,而这些索引是相对于seg_classes[cat]内部的。如果seg_classes[cat]表示的是一个连续的标签范围(比如从某个起始值开始的整数序列),那么这个起始值(seg_classes[cat][0])需要被加到索引上,以得到最终的类别标签。
-
cur_pred_val[i, :] = ...:将计算得到的最终预测结果赋值给cur_pred_val张量的第i行。
#计算交并比 for i in range(cur_batch_size): segp = cur_pred_val[i, :] segl = target[i, :] cat = seg_label_to_cat[segl[0]] part_ious = [0.0 for _ in range(len(seg_classes[cat]))] for l in seg_classes[cat]: if (np.sum(segl == l) == 0) and ( np.sum(segp == l) == 0): # part is not present, no prediction as well part_ious[l - seg_classes[cat][0]] = 1.0 else: part_ious[l - seg_classes[cat][0]] = np.sum((segl == l) & (segp == l)) / float( np.sum((segl == l) | (segp == l))) shape_ious[cat].append(np.mean(part_ious))
通用:
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) ROOT_DIR = BASE_DIR sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
BASE_DIR = os.path.dirname(os.path.abspath(__file__))__file__是一个特殊变量,它包含了当前文件的路径。os.path.abspath(__file__)会获取__file__的绝对路径,即完整的文件路径,无论当前工作目录在哪里。os.path.dirname()函数会获取给定路径的目录部分。所以,os.path.dirname(os.path.abspath(__file__))得到的是当前文件所在目录的绝对路径。- 这行代码的作用是将当前文件(通常是项目的入口文件,如
main.py或app.py)所在的目录设置为BASE_DIR。
-
ROOT_DIR = BASE_DIR- 这行代码简单地将
BASE_DIR的值赋给ROOT_DIR。这意味着ROOT_DIR也代表了当前文件所在的目录。
- 这行代码简单地将
-
sys.path.append(os.path.join(ROOT_DIR, 'models'))sys.path是一个列表,它包含了Python解释器自动查找所需模块的目录的名称。默认情况下,它包含了一些标准库的目录。os.path.join(ROOT_DIR, 'models')会将ROOT_DIR和'models'这两个路径组件合并成一个完整的路径。假设ROOT_DIR是/home/user/project,那么合并后的路径就是/home/user/project/models。sys.path.append()方法会将一个新的路径添加到sys.path列表的末尾。这意味着,当Python解释器需要导入一个模块时,它也会在/home/user/project/models这个目录下查找。
- 这行代码的作用是将项目中的
models目录添加到模块搜索路径中,使得在项目的任何地方都可以直接导入models目录下的模块,而不需要担心相对路径或设置PYTHONPATH环境变量。
设置深度学习或机器学习实验的环境:
'''HYPER PARAMETER''' os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu '''CREATE DIR''' timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
- 这行代码获取当前的时间字符串,格式为
'YYYY-MM-DD_HH-MM',用于给实验目录命名,以确保唯一性。
exp_dir = Path('./log/') exp_dir.mkdir(exist_ok=True)
Path是pathlib模块中的一个类,用于表示文件系统路径。exp_dir初始化为'./log/',然后调用mkdir(exist_ok=True)确保这个目录存在(如果已存在则不会报错)。- 接着,将
exp_dir更新为'./log/part_seg/',并再次调用mkdir(exist_ok=True)确保这个子目录也存在。
exp_dir = exp_dir.joinpath('part_seg') exp_dir.mkdir(exist_ok=True) if args.log_dir is None: exp_dir = exp_dir.joinpath(timestr) else: exp_dir = exp_dir.joinpath(args.log_dir) exp_dir.mkdir(exist_ok=True) checkpoints_dir = exp_dir.joinpath('checkpoints/') checkpoints_dir.mkdir(exist_ok=True) log_dir = exp_dir.joinpath('logs/') log_dir.mkdir(exist_ok=True)
- 训练循环:
for epoch in range(start_epoch, args.epoch):
这行代码表示从start_epoch开始,直到args.epoch(不包括args.epoch)结束的训练循环。start_epoch通常用于恢复训练,从之前的某个epoch继续开始。
- 初始化:
mean_correct = []
这行代码初始化了一个空列表mean_correct,尽管在这个代码片段中没有直接使用它,但它可能用于存储每个epoch中的某些统计信息(如正确分类的样本数)。
- 日志记录:
log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
这行代码使用log_string函数(该函数未在代码片段中定义,但假设它用于记录日志)来记录当前epoch的信息。注意这里使用了global_epoch + 1,但global_epoch变量在代码片段中未定义,可能是外部定义的变量,用于跟踪整个训练过程中的epoch数。
- 调整学习率:
lr = max(args.learning_rate * (args.lr_decay ** (epoch // args.step_size)), LEARNING_RATE_CLIP)
这行代码根据epoch数调整学习率。它使用了一个衰减公式,其中args.learning_rate是初始学习率,args.lr_decay是衰减率,args.step_size是衰减步长。计算结果与学习率下限LEARNING_RATE_CLIP(未在代码片段中定义)取最大值,以防止学习率过低。
- 更新优化器的学习率:
for param_group in optimizer.param_groups: param_group['lr'] = lr
这行代码遍历优化器中的所有参数组,并将每个组的学习率更新为新的学习率lr。
- 调整BN动量:
momentum = MOMENTUM_ORIGINAL * (MOMENTUM_DECCAY ** (epoch // MOMENTUM_DECCAY_STEP)) if momentum < 0.01: momentum = 0.01
这行代码根据epoch数调整BN的动量。它使用了一个衰减公式,其中MOMENTUM_ORIGINAL是初始动量,MOMENTUM_DECCAY是衰减率,MOMENTUM_DECCAY_STEP是衰减步长。如果计算出的动量小于0.01,则将其设置为0.01。
- 应用BN动量调整:
classifier = classifier.apply(lambda x: bn_momentum_adjust(x, momentum))
这行代码使用apply函数遍历classifier模型中的所有模块,并对每个模块应用一个lambda函数。这个lambda函数调用bn_momentum_adjust函数
'''learning one epoch''' for i, (points, label, target) in tqdm(enumerate(trainDataLoader), total=len(trainDataLoader), smoothing=0.9): optimizer.zero_grad() 这行代码使用tqdm库(一个快速、可扩展的Python进度条)来遍历trainDataLoader。trainDataLoader是一个数据加载器,它按批次提供训练数据。每个批次包含点云数据points、标签label和目标target。 points = points.data.numpy() points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3])
这行代码对点云的坐标(假设是前三维)进行随机缩放。provider.random_scale_point_cloud函数接收点云的坐标部分,并返回缩放后的坐标。这里使用了切片操作[:, :, 0:3]来选择所有点在所有批次中的所有三维坐标。 points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3]) points = torch.Tensor(points) points, label, target = points.float().cuda(), label.long().cuda(), target.long().cuda() points = points.transpose(2, 1) seg_pred, trans_feat = classifier(points, to_categorical(label, num_classes))
这行代码将处理后的点云数据和标签(经过one-hot编码)传递给classifier模型进行前向传播。模型返回分割预测seg_pred和变换特征trans_featseg_pred = seg_pred.contiguous().view(-1, num_part) target = target.view(-1, 1)[:, 0]
-
重新塑形(Reshaping):
target.view(-1, 1)将target张量重新塑形为一个二维张量,其中第二维的大小为1(即每个元素都变成了单独的一行)。-1在这里是一个特殊值,它告诉PyTorch自动计算该维度的大小,以便保持张量中的元素总数不变。 -
索引(Indexing):
[:, 0]是一个索引操作,它选择了重新塑形后的张量的第一列(由于第二维大小为1,所以实际上只有一列)。这会将二维张量转换回一维张量,但只包含原始张量中的每个元素的第一个值(在这个情况下,由于我们刚刚将每个元素变成了单独的一行,所以这里实际上就是取原始张量的每个元素)。
pred_choice = seg_pred.data.max(1)[1] correct = pred_choice.eq(target.data).cpu().sum() mean_correct.append(correct.item() / (args.batch_size * args.npoint)) loss = criterion(seg_pred, target, trans_feat) loss.backward() optimizer.step() train_instance_acc = np.mean(mean_correct) log_string('Train accuracy is: %.5f' % train_instance_acc)
if weight[b, n] != 0 and not np.isinf(weight[b, n]): vote_label_pool[int(point_idx[b, n]), int(pred_label[b, n])] += 1
-
weight[b, n] != 0:这个条件检查当前点(或预测)的权重是否不为零。如果权重为零,可能意味着这个点(或预测)在最终决策中不应该被考虑。 -
not np.isinf(weight[b, n]):这个条件检查当前点的权重是否不是无穷大。无穷大的权重可能是数据错误或数值不稳定的迹象,因此应该被排除。 -
如果上述两个条件都满足,即权重既不为零也不是无穷大,那么代码将执行投票操作。
-
vote_label_pool[int(point_idx[b, n]), int(pred_label[b, n])] += 1:这行代码将投票池的相应位置增加1。point_idx[b, n]和pred_label[b, n]分别给出了当前点的索引和预测标签,这些值被用作投票池的索引,以记录该点对该标签的投票。
batch_smpw[0:real_batch_size, ...] = scene_smpw[start_idx:end_idx, ...]
... 表示选择剩余所有维度的所有元素。这是一种省略表示法,用于快速选择多维数组的子集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号