
MLPerf Training 参考实现
一、MLPerf Training 参考实现
1.MLPerf 简介
MLPerf 官网:https://mlperf.org/
2020年7月29日,MLPerf联盟发布了MLPerf Training v0.7的结果,这是MLPerf基准测试的第三轮结果。v0.5为第一轮,v0.6是第二轮。MLPerf基准测试是衡量机器学习性能的行业标准,显示了行业的巨大进步和日益增长的多样性,包括多个新的处理器,加速器和软件框架。MLPerf Training v0.7中有两个任务组合,一个用于常规系统,一个用于高性能计算(HPC)系统。
2.MLPerf 测试任务
MLPerf训练测试基准包括图像分类、翻译、推荐系统和围棋等8个机器学习任务中,最终结果是这8项任务的训练时间,速度越快则性能越强。具体的8项任务内容如下:
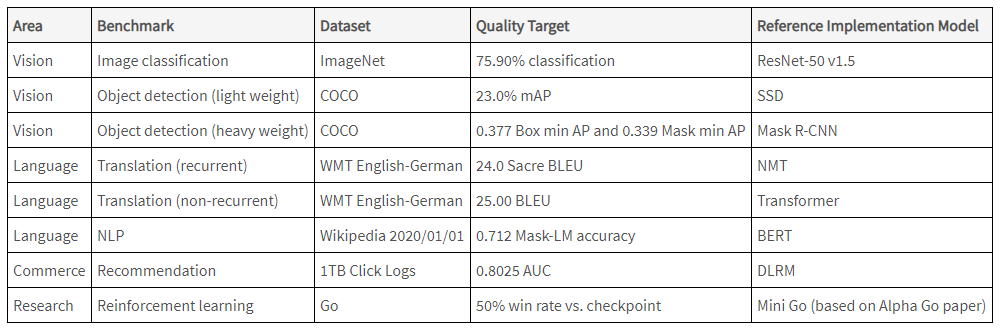
另一个用于用于高性能计算(HPC)系统的任务内容如下:

MLPerf Training v0.7的规则参考:https://github.com/mlcommons/training_policies/blob/master/training_rules.adoc。
3.MLPerf 分类
MLPerf training可以分为封闭模型分区(Closed Model Division)和开放模型分区(Open Model Division)。其中封闭模型分区要求使用相同模型和优化器,并限制batch大小或学习率等超参数的值,它旨在硬件和软件系统的公平比较。而开放模型分区只会限制使用相同的数据解决相同的问题,其它模型或平台都不会限制,它旨在推进ML模型和优化的创新。
4.MLPerf 评价标准
MLperf按照不同的领域问题设置了不同的Benchmark,对于MLPerf Training测试,每个Benchmark的评价标准是:在特定数据集上训练一个模型使其达到Quality Target时的Clock time。由于机器学习任务的训练时间有很大差异,因此,MLPerf 的最终训练结果是由指定次数的基准测试时间平均得出的,其中会去掉最低和最高的数字,一般是运行5次取平均值,Train测试时间包含了模型构建,数据预处理,训练以及质量测试等时间。对于MLPerf Inference测试,每个Benchmark的评价标准是:在特定数据集上测量模型的推理性能,包括Latency和吞吐量。
5.MLPerf 测试结果
MLPerf Result被定义为将模型训练到目标质量的Clock时间,这个时间包括模型构建,数据预处理,训练以及质量测试等时间,它通常是数小时或数天。MLPerf也提供了一个参考基准,该基准是MLPerf使用一块 Pascal P100显卡在未进行任何优化情况下的测试结果。下表为MLPerf Training v0.5的封闭分区的参考基准和各大厂商的测试结果。
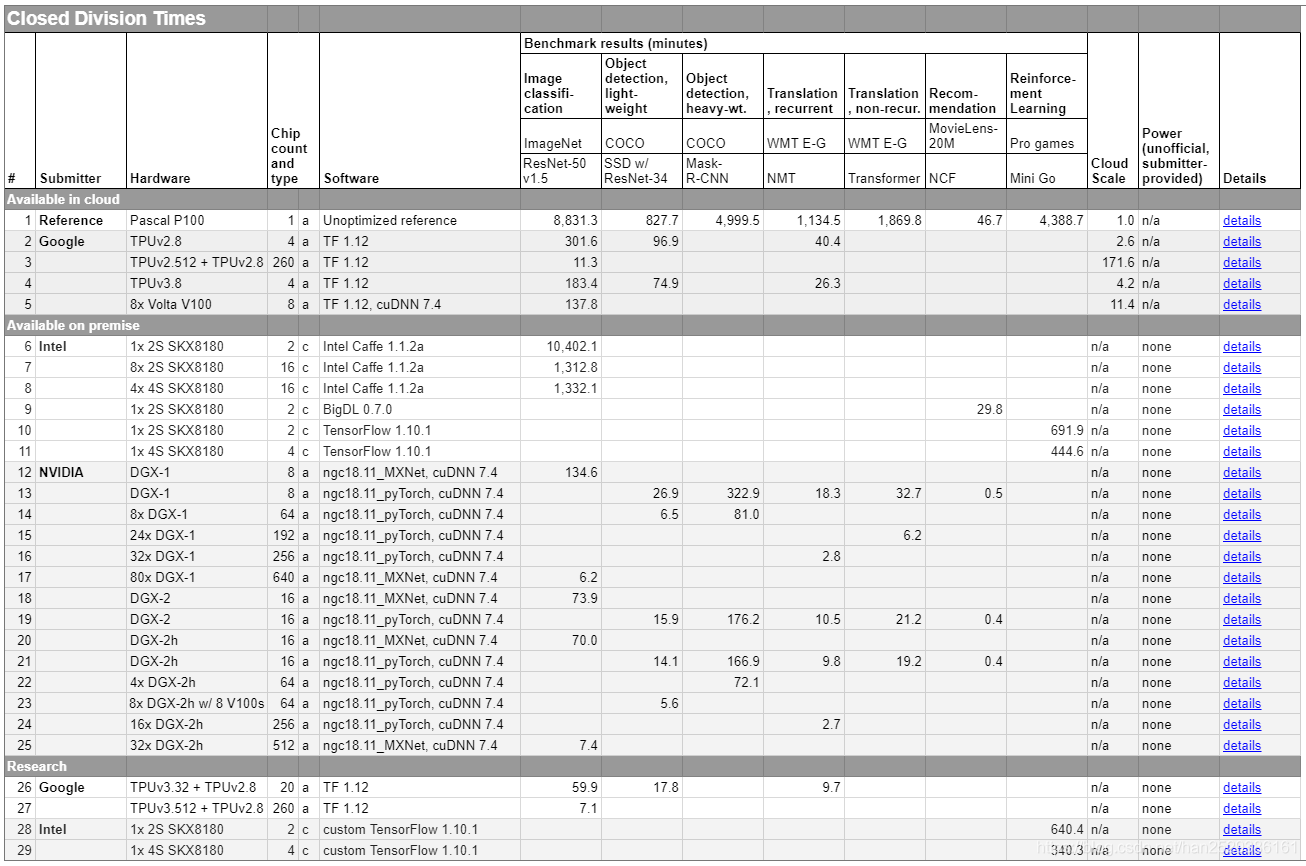
MLperf 的结果首先按照 Division 分类,然后按照 Category 分类。结果表格中的每一行都是由单个提交者使用相同软件堆栈和硬件平台生成的一组结果。每行包含以下信息:
| 名称 | 说明 |
|---|---|
| Submitter | 提交结果的组织 |
| Hardware | 使用的 ML 硬件类型,例如加速器或高性能 CPU。 |
| Chip Count and Type | 使用的ML硬件芯片的数量,以及它们是加速器还是CPU。 |
| Software | 使用的 ML 框架和主要 ML 硬件库。 |
| Benchmark result | 在各个基准测试中将模型训练到目标质量的时间。 |
| Cloud Scale | Cloud Scale源自几家主要云提供商的定价,并提供相对系统size/cost的粗略指标。参考单个Pascal P100系统的云规模为1,云规模为4的系统大约需要四倍的成本。 |
| Power | 可用内部部署系统的信息。由于标准化功率测量的复杂性,此版本 MLPerf 只允许自愿报告任意非官方功率信息。 |
| Details | 链接到提交的元数据。 |
另一种结果输出是:加速比(Speedups)。加速比是当前测试结果和使用一块Pascal P100显卡在未进行任何优化情况下的测试结果的比值。即当前测试结果和参考基准的比值。因此,MLPerf 的Speedups结果若是10,则表示被测试系统的训练速度是在一块Pascal P100上训练同一个模型速度的10倍,训练时间是其 1/10。下表为MLPerf Training v0.5封闭分区的参考基准和各大厂商的Speedups结果。
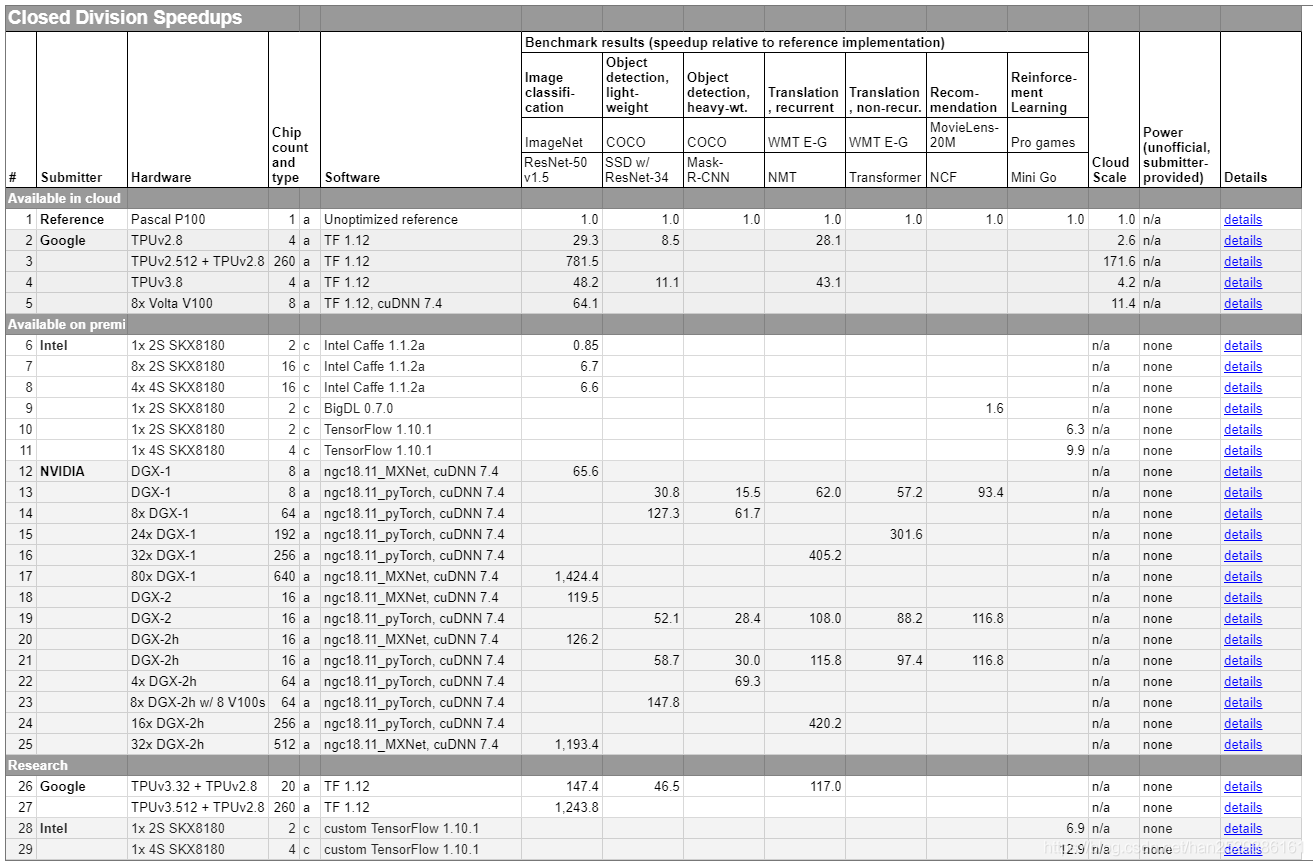
MLPerf Training v0.7的测试结果参考:https://mlperf.org/training-results-0-7
其它有关MLPerf Training v0.7更多信息参考官网网站:https://mlperf.org/training-overview。
我们拿谷歌MLPerfTraining v0.5的拥有8V100的系统的图像识别结果为例
参考链接:https[😕/github.com/mlcommons/training_results_v0.5/tree/master/v0.5.0/google]

选取一次测试结果,计算run_start到run_stop之间的时间


将结果与谷歌提交的结果进行比对

发现结果比较接近,就是这样计算。加速比则是8831.3/137.8得到

二、当前mlperf存储及运行情况
1.工作目录
当前工作目录为 /home/intern/yscai2/worktable
cd /home/intern/yscai2/worktable
工作目录下,文件夹如下图所示
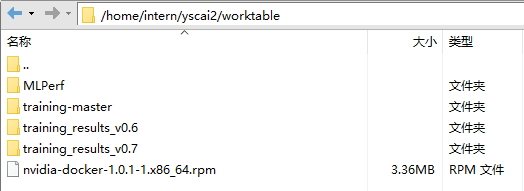
2.数据存储目录
当前的数据存储目录为/yrfs2/dlp/yscai2
cd /yrfs2/dlp/yscai2/
数据存储目录下,文件夹如下图所示。其中,.tar文件是相应的镜像压缩包,存着以备不时之需。
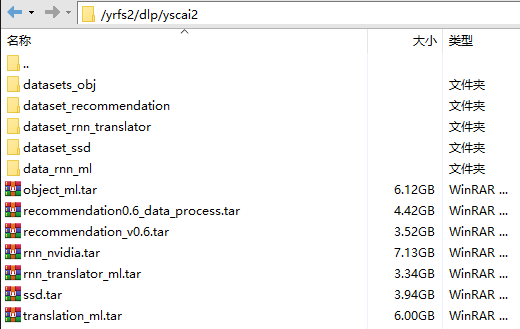
★3.基准测试运行情况
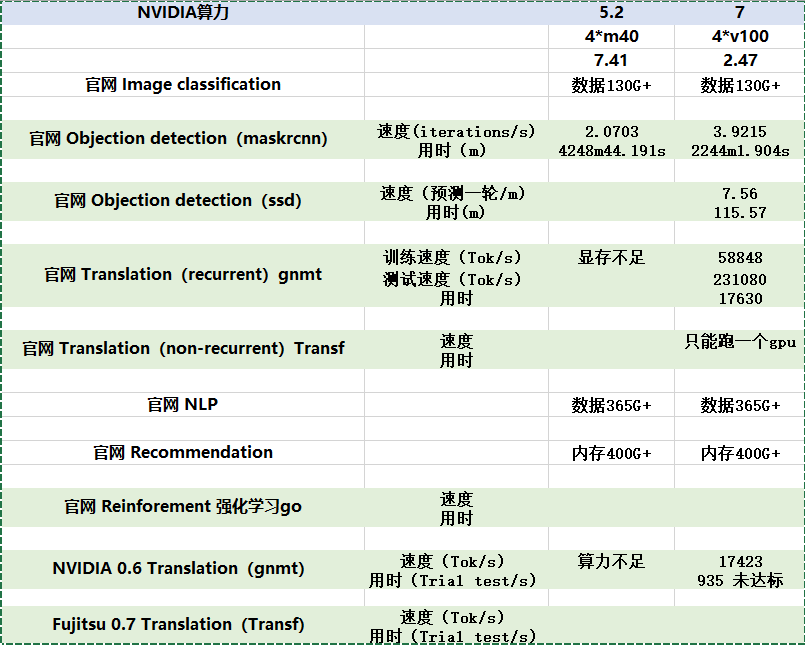
其中,基准测试当前进展如下图所示,其中是否跑通这一栏 ✔× 表示2.47(4*V100)的机器跑通,✔✔ 表示两台机器都跑通,”一个gpu“表示只跑通了两台机器,但都只能跑一个GPU。
| 准程序 | 是否跑通 | 相对工作目录 | 相对数据存储目录 |
|---|---|---|---|
| 官网 Image classification | ×× | 数据量130G+ | |
| 官网 Objection detection(maskrcnn) | ✔✔ | MLPerf/training/ object_detection | datasets_obj |
| 官网 Objection detection(ssd) | ✔✔ | training-master/ single_stage_detector | datasets_obj |
| 官网 Translation(recurrent)gnmt | ✔✔ | training-master/ rnn_translator | data_rnn_ml |
| 官网 Translation(non-recurrent)Transfer | ✔✔一个gpu | training-master/ translation | data_rnn_ml |
| 官网 NLP | ×× | 数据量365G+ | |
| 官网 Recommendation | ×× | training-master/ recommendation | 内存400G+ |
| 官网 Reinforement 强化学习go | ×× | training-master/ reinforement | 无需数据 |
| NVIDIA 0.6 Translation(gnmt) | ✔× | training_results_v0.6/NVIDIA/ benchmarks/gnmt/implementations |
dataset_rnn_translator |
未跑通原因
- 官网 Image classification:
- 官网 NLP:
- 官网 Recommendation:
- 官网 Reinforement 强化学习go:
- NVIDIA 0.6 Translation(gnmt):
官网 Translation(recurrent)gnmt 两台机器虽然都能跑通,但是7.41跑到后面显存不足,GPU out of memory。
4.各基准测试运行步骤
三、官网 Objection detection(maskrcnn)
1.运行步骤
使用镜像:要保证存在相应的镜像mlperf/object_detection:latest。没有nvidia-docker就是要docker。
参考链接:https://github.com/mlcommons/training/tree/master/object_detection
无需要求在某个目录下,直接启动镜像
docker run -v /home/intern/yscai2/worktable/:/workspace -v /yrfs2/dlp/yscai2/datasets_obj:/datasets -t -i --rm --ipc=host mlperf/object_detection:latest
在镜像中进入工作目录
cd /workspace/MLPerf/training/object_detection
更改日志打印位置。如果是共同存储,同时运行时,共同存储的多台机器的日志会被混搭在同一text文件中
vim pytorch/maskrcnn_benchmark/config/defaults.py
在第383行
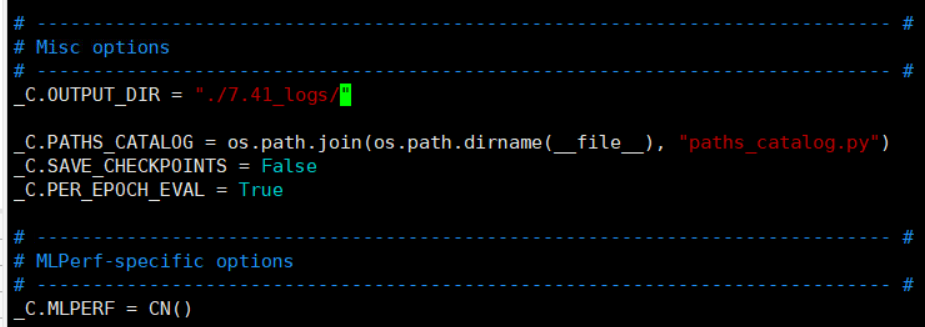
更改完成后,保存退出,运行基准程序。
./run_and_time.sh
提示:在初始状态的镜像里运行,需要先下载 R-50.pkl 和 maskrcnn_benchmark,并更改数据位置,我在完成上述操作后对镜像commit保存,因此可以直接运行。如有报错,则需再执行下述的几个操作,更改数据位置,下载 R-50.pkl 和 maskrcnn_benchmark 。
更改数据位置:在 pytorch/maskrcnn_benchmark/config/paths_catalog.py 里,数据地址为挂载后相对于容器的地址。
vim pytorch/maskrcnn_benchmark/config/paths_catalog.py
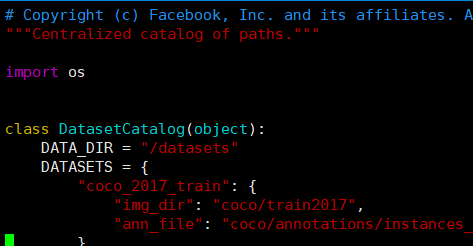
2.搭建步骤
本文将以MLPerf Training 中的object_detection (heavy weight) 任务为例,阐述如何利用官方的参考代码实现其中的任务。object_detection使用Mask R-CNN with ResNet50 backbone进行模型训练.
参考链接为:https://github.com/mlperf/training/tree/master/object_detection。
代码官方来源:https://github.com/mlcommons/training/tree/master/object_detection
(1)将MLPerf库拷到本地
mkdir -p mlperf
cd mlperf
git clone https://github.com/mlperf/training.git
(2)安装CUDA、nvidia-docker和docker
source training/install_cuda_docker.sh
安装完成后,可以查看 nvidia-docker 版本和cuda版本。

(3)建立镜像
training/object_detection/ 文件下有Dockerfile,根据此文件构建镜像。
cd training/object_detection/
nvidia-docker build . -t mlperf/object_detection
如果显示如下错误,可能是因为电脑没有gpu,可能CUDA、nvidia-docker组件没装好。可以将nvidia-docker改为docker试试

在镜像中,我们需要构建如下组件,以成功实现测试。构建镜像中会自己搭建如下组件的环境。

镜像构建比较缓慢,Sending build content to Docker daemon 要达到40G左右。

如果在构建镜像过程中显示如下错误,

则要更改Dockerfile文件,添加:
RUN rm /var/lib/apt/lists/* -vf
RUN apt-get clean
RUN mv /var/lib/apt/lists /tmp
RUN mkdir -p /var/lib/apt/lists/partial
RUN apt-get clean

镜像构建完成后,docker images 查看是否构建成功,镜像名为mlperf/object_detection。
(4)准备数据
退出容器,回到本机。运行 download_dataset.sh 下载数据,download_dataset.sh 包含数据下载的相关信息。数据集为COCO2014,也可以用COCO2017。
source download_dataset.sh
打开 download_dataset.sh 查看下载的数据信息,如果shell里下载较慢,可以利用下载器下载。
本例中 download_dataset.sh 如下,我们分别用下载器下载以下四个数据:coco_annotations_minival.tgz、train2014.zip、val2014.zip、annotations_trainval2014.zip,数据量较大,四个压缩包一共在19G左右。
#!/bin/bash
# Get COCO 2014 data sets
mkdir -p pytorch/datasets/coco
pushd pytorch/datasets/coco
curl -O https://dl.fbaipublicfiles.com/detectron/coco/coco_annotations_minival.tgz
tar xzf coco_annotations_minival.tgz
curl -O http://images.cocodataset.org/zips/train2014.zip
unzip train2014.zip
curl -O http://images.cocodataset.org/zips/val2014.zip
unzip val2014.zip
curl -O http://images.cocodataset.org/annotations/annotations_trainval2014.zip
unzip annotations_trainval2014.zip
# TBD: MD5 verification
# $md5sum *.zip *.tgz
#f4bbac642086de4f52a3fdda2de5fa2c annotations_trainval2017.zip
#cced6f7f71b7629ddf16f17bbcfab6b2 train2017.zip
#442b8da7639aecaf257c1dceb8ba8c80 val2017.zip
#2d2b9d2283adb5e3b8d25eec88e65064 coco_annotations_minival.tgz
popd
如果用下载器下载在当前目录下,更改download_dataset.sh文件如下,再运行。
#!/bin/bash
# Get COCO 2014 data sets
mkdir -p pytorch/datasets/coco
pushd pytorch/datasets/coco
tar xzf coco_annotations_minival.tgz
unzip train2014.zip
unzip val2014.zip
unzip annotations_trainval2014.zip
popd
(5)启动镜像
/root/worktable/ 为当前工作目录,mlperf/object_detection 为生成镜像的名称。
nvidia-docker run -v /root/worktable/:/workspace -t -i --rm --ipc=host mlperf/object_detection
在镜像生成的容器中进入工作目录。
cd mlperf/training/object_detection

install.sh里的内容,调用了pytorch/setup.py,要去下载maskrcnn-benchmark,可以先 github 里下载下来放到pytorch目录下。

运行 install.sh
./install.sh
(6)运行 Benchmark
如果是单机单卡gpu,那么直接运行 run_and_time.sh。
./run_and_time.sh
其中会涉及下载ResNet50 base,即R-50.pkl,在断网情况下会报错 downing 错误
可以先下载到本地,再把本地的R-50.pkl放到镜像里的 /root/.torch/models/ 下。R-50.pkl的链接为,https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/MSRA/R-50.pkl

注意:如果单机多卡,则要更改 run_and_time.sh 里的命令
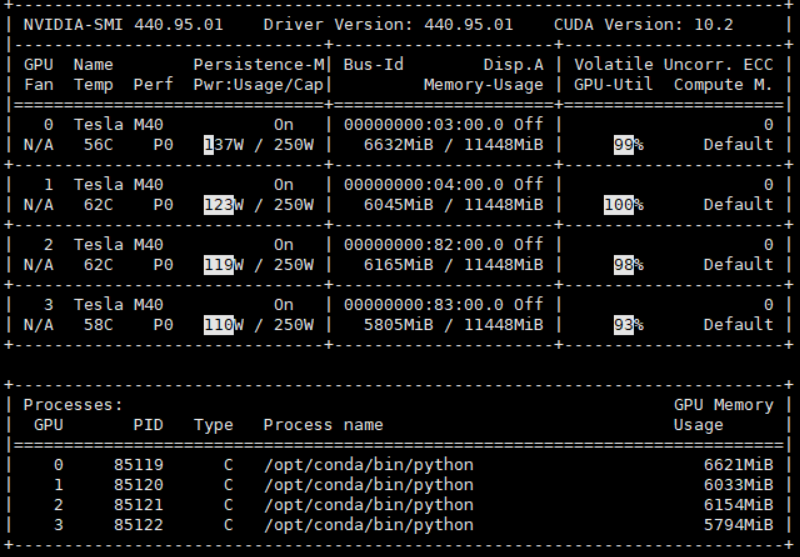
查看自己电脑gpu信息
watch -d -n 1 nvidia-smi
pytorch单机多卡训练的命令
python -m torch.distributed.launch --nproc_per_node=你的GPU数量
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
arguments of your training script)
对于本机,修改 run_and_time.sh
python -m torch.distributed.launch --nproc_per_node=4 \
tools/train_mlperf.py \
--config-file "configs/e2e_mask_rcnn_R_50_FPN_1x.yaml" \
SOLVER.IMS_PER_BATCH 2 \
TEST.IMS_PER_BATCH 1 \
SOLVER.MAX_ITER 720000 \
SOLVER.STEPS "(480000, 640000)" \
SOLVER.BASE_LR 0.0025
再执行 run_and_time.sh 后,就可以看到gpu都跑起来了。

中途如果报错且它并未停止,或者中途手动停止,查看gpu信息,watch -d -n 1 nvidia-smi,会发现仍有不少进程还占用这gpu资源。有时候会由于某种原因,在关闭程序后,GPU的显存仍处于被占用的状态。如果在没有释放资源的情况下,再次运行会报如下错误:
这时释放显存的方法:
sudo fuser /dev/nvidia*

该命令会显示所有占用nvidia设备的进程pid,将这些pid逐个kill掉:kill -9 pid 。发现显存已经被释放。

模型采用的是基于ResNet50的Mask R-CNN ,采用的损失函数和优化器如下:

(7)结果分析
按理,程序在满足一定条件后会停止迭代,输出得到训练模型所用时间和加速比。
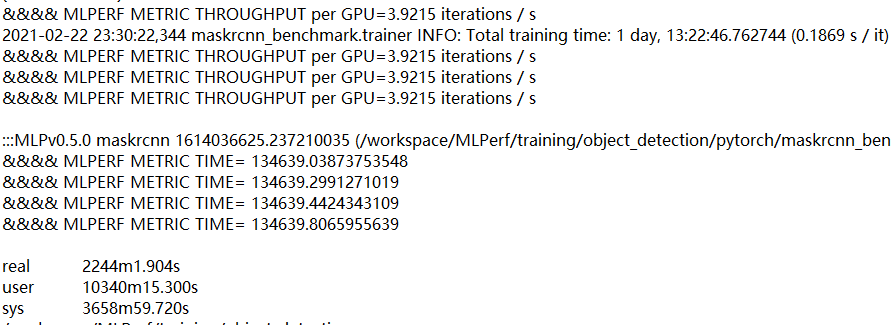
最终会给出训练总时间为 real=2244m1.904s,以及每个GPU的吞吐量为3.9215 iterations/s
8 NVIDIA V100 GPUs 的参考结果为:https://github.com/mlcommons/training/blob/master/object_detection/pytorch/MODEL_ZOO.md
(8)其它
其余基准测试实现参考:https://github.com/mlcommons/training
一般步骤都可分为:拷贝MLPerf库--->配置环境--->安装镜像--->下载预处理数据--->调整参数--->启动Benchmark结果分析:
(2)官网 Objection detection(ssd)
使用镜像:要保证存在相应的镜像mlperf/single_stage_detector:latest。对应数据存储目录里 ssd.tar 。
参考链接:https://github.com/mlcommons/training/tree/master/single_stage_detector/ssd
进入工作目录
cd /home/intern/yscai2/worktable/training-master/single_stage_detector/ssd
运行
./run.sub
运行结果,最终给出的只有运行时间

还有预测所花时间

提示:在初始状态下,需要配置CPU、GPU参数,并更改镜像名、数据和log日志位置 。
参数设置:进入工作目录,更改run.sub中的相关参数
cd /home/intern/yscai2/worktable/training-master/single_stage_detector/ssd
vim run.sub
CONT=镜像名,DATADIR=数据路径,LOGDIR=日志路径
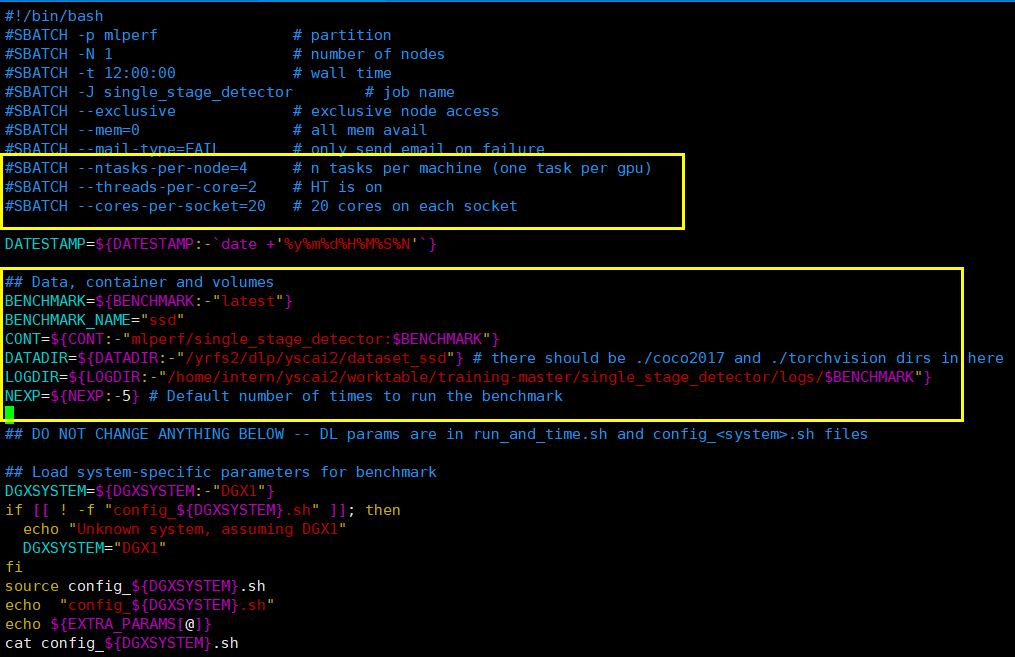
vim config_DGX1_32.sh
修改参数配置,gpu数量和cpu参数,参考:六、NVIDIA v0.6 Translation GNMT 实现步骤
(3)官网 Translation(recurrent)gnmt
使用镜像:要保证存在相应的镜像 mlperf/rnn_translator:mlcommons。对应数据存储目录里 rnn_translator_ml.tar 。
参考链接:https://github.com/mlcommons/training/tree/master/rnn_translator
无需要求在某个目录下,直接启动镜像
NV_GPU=4 docker run -it --rm --ipc=host \
-v /home/intern/yscai2/worktable:/worktable \
-v /yrfs2/dlp/yscai2/dataset_rnn_translator:/data \
mlperf/rnn_translator:mlcommons
运行
./run_and_time.sh
提示:默认只能运行一个GPU,因此要在docker前加 NV_GPU=4。同时在镜像里要更改 run.sh,注意是在镜像里改。由于我已经改好了,所以可以直接运行run_and_time.sh
更改 run.sh,采用多GPU:
更改run.sh里的数据路径,更改代码,采用多GPU启动程序
vim run.sh
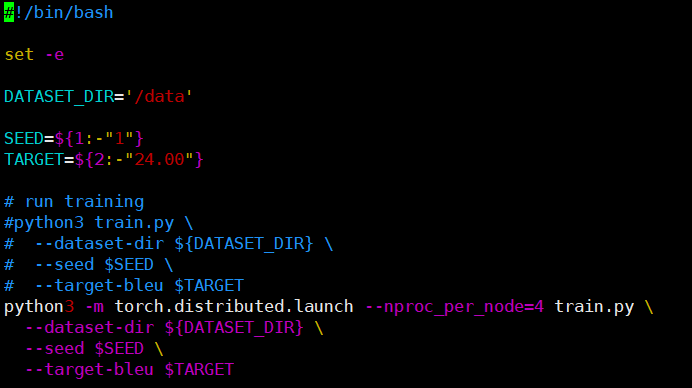
将 run training 的代码改为:
python3 -m torch.distributed.launch --nproc_per_node=4 train.py \
--dataset-dir ${DATASET_DIR} \
--seed $SEED \
--target-bleu $TARGET
(4)官网 Translation(non-recurrent)Transfer
使用镜像:要保证存在相应的镜像 mlperf/translation:mlcommons。对应数据存储目录里 translation_ml.tar 。
参考链接:https://github.com/mlcommons/training/tree/master/translation
docker run -v /yrfs2/dlp/yscai2/dataset_rnn_translator:/raw_data -v /home/intern/yscai2/worktable/training-master/compliance:/mlperf/training/compliance -v /home/intern/yscai2/worktable/training-master:/worktable -e "MLPERF_COMPLIANCE_PKG=/mlperf/training/compliance" -t -i mlperf/translation:mlcommons
运行,不过只能运行一个GPU
./run_and_time.sh
提示:上述之所以可以直接运行,是因为镜像我已经调好了,初始情况下,还会遇到如下的错误。
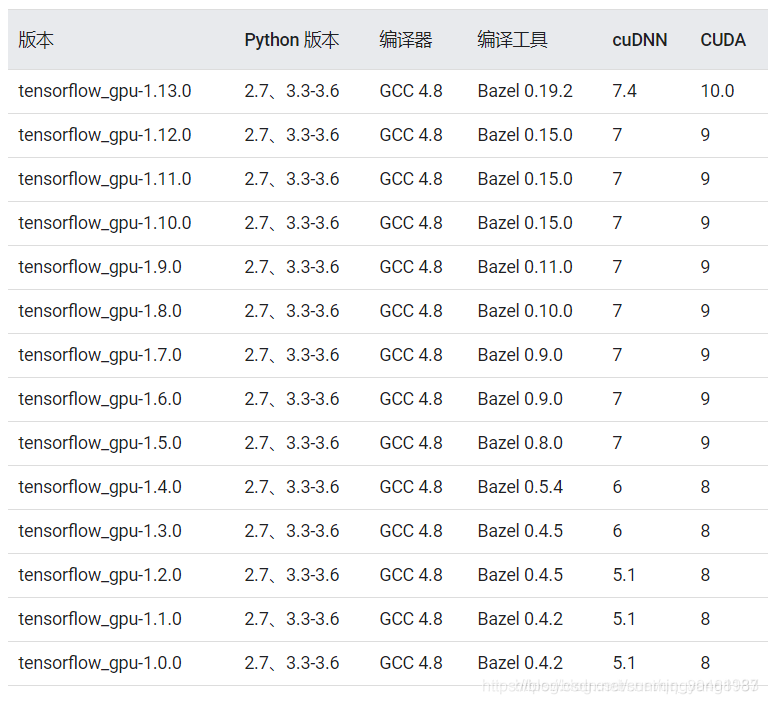
提示:Dockfile文件里要求安装 cuda9 和 tensorflow-gpu 1.9,但是如今 tensorflow-gpu 已经不支持 1.13版本以下。因此本镜像选择了 tensorflow-gpu 1.13,但是根据 tensorflow、cuda、cudnn配置表,cuda要求10,因此更改Dockerfile,下载cuda10。
FROM nvidia/cuda:10.0-cudnn7-runtime-ubuntu16.04
tensorflow、cuda、cudnn版本对应关系。
提示:运行的时候还会出现如下错误:
1. Traceback (most recent call last):
2. ...
3.
4. from twisted.conch import manhole, telnet
5. File "c:\users\pearl\appdata\local\programs\python\python37\lib\sitepackages\twisted\conch\manhole.py", line 154
6. def write(self, data, async=False):
7. ^
8. SyntaxError: invalid syntax
参考链接:https://blog.csdn.net/as849167276/article/details/82019983
将该py文件里所有的async改为shark
提示:还会遇到联网下载一个压缩包。 http://data.statmt.org/wmt17/translation-task/training-parallel-nc-v12.tgz to /raw_data/training-parallel-nc-v12.tgz。先在外网下载下来,再挂载到镜像中,再在镜像中将压缩包放到指定位置。
(5)官网 Recommendation
使用镜像:要保证存在相应的镜像 mlperf/recommendation:v0.6。对应数据存储目录里 recommendation_v0.6.tar
参考链接:https://github.com/mlcommons/training/tree/master/recommendation/pytorch
docker run --rm -it --ipc=host --network=host -v /yrfs2/dlp/yscai2/dataset_recommendation:/data/cache mlperf/recommendation:v0.6 /bin/bash
运行,不过运行到后面就内存不足,官方提示需要至少400G内存。
python convert.py /data/cache/ml-20mx16x32 --seed 0
(6)NVIDIA 0.6 Translation(gnmt)
使用镜像:要保证存在相应的镜像 mlperf/recommendation:v0.6。
cd /home/intern/yscai2/worktable/training_results_v0.6/NVIDIA/benchmarks/gnmt/implementations/pytorch
运行
./run.sub
5.MLPerf当前测试结果对比
三、Object_detection(maskrcnn) 搭建步骤
四、官网 Objection detection(ssd) 搭建步骤
参考链接:https://github.com/mlcommons/training/tree/master/single_stage_detector/ssd
1.环境准备
将MLPerf库拷到本地
git clone https://github.com/mlperf/reference.git
安装CUDA、nvidia-docker和docker
source reference/install_cuda_docker.sh
2.构建镜像
# Build from Dockerfile
cd reference/single_stage_detector/
sudo docker build -t mlperf/single_stage_detector .
3.准备数据
cd reference/single_stage_detector/
source download_dataset.sh
下载ResNet34神经网络框架和权重
cd reference/single_stage_detector/
./download_resnet34_backbone.sh
4.构建镜像
docker build . -t 镜像名
docker build . -t mlperf/single_stage_detector:latest
5.运行 Benchmark
进入工作目录,更改run.sub中的相关参数
cd /home/intern/yscai2/worktable/training-master/single_stage_detector/ssd
vim run.sub
CONT=镜像名,DATADIR=数据路径,LOGDIR=日志路径

vim config_DGX1_32.sh
修改参数配置,gpu数量和cpu参数,参考:三、NVIDIA v0.6 GNMT 实现步骤
./run.sub
#NVIDIA DGX-1 (single GPU),参数在config_DGX1_32.sh
DATADIR=<path/to/data/dir> LOGDIR=<path/to/output/dir> DGXSYSTEM=DGX1_32 ./run.sub
#NVIDIA DGX-1 (single node),参数在config_DGX1_singlenode.sh
DATADIR=<path/to/data/dir> LOGDIR=<path/to/output/dir> DGXSYSTEM=DGX1_singlenode ./run.sub
#NVIDIA DGX-1 (multi node),参数在config_DGX1_multinode.sh
DATADIR=<path/to/data/dir> LOGDIR=<path/to/output/dir> DGXSYSTEM=DGX1_multinode sbatch -N $DGXNNODES -t $WALLTIME run.sub
6.运行结果
达到目标 mAP of 0.23 自动停止,计算时间。每一轮迭代后都会计算。

五、官网 Translation(recurrent) gnmt 搭建步骤
本基准测试是将英语翻译成德语,采用的是基于NMT的较复杂的训练模型。
参考链接:https://github.com/mlcommons/training/tree/master/rnn_translator/pytorch
1.环境准备
将MLPerf库拷到本地
git clone https://github.com/mlperf/training.git
安装组件
source training/install_cuda_docker.sh
2.准备数据
下载数据
bash download_dataset.sh
其中包括了数据下载和做处理,由两部分代码下载需要联网。
git clone https://github.com/moses-smt/mosesdecoder.git
git clone https://github.com/rsennrich/subword-nmt.git
验证数据
bash verify_dataset.sh
3.构建镜像
sudo docker build . --rm -t mlperf/rnn_translator:mlcommons
4.启动镜像
要把GPU个数写上,不然可能会只跑一个GPU
NV_GPU=4 docker run -it --rm --ipc=host \
-v /home/intern/yscai2/worktable:/worktable \
-v /yrfs2/dlp/yscai2/dataset_rnn_translator:/data \
mlperf/rnn_translator:mlcommons
更改run.sh里的数据路径,更改代码,采用多GPU启动程序
vim run.sh
将run training的代码改为:
python3 -m torch.distributed.launch --nproc_per_node=4 train.py \
--dataset-dir ${DATASET_DIR} \
--seed $SEED \
--target-bleu $TARGET
5.运行Benchmark
./run_and_time.sh
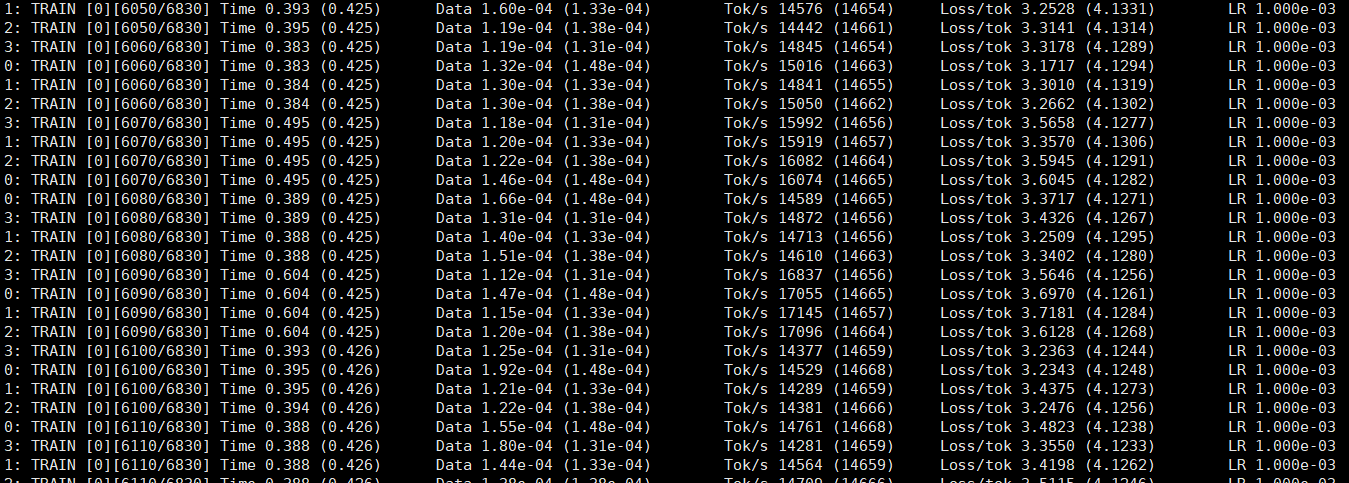
6.运行结果
训练达标的标准是没被当作训练的newstest2014 en-de数据集的BLEU,得分需达到24。使用 sacrebleu 的 python软件包报告BLEU分数(版本1.2.10)。 Sacrebleu使用以下命令执行:--score-only -lc --tokenize intl。每一轮迭代后都会计算评估一次BLEU得分。评估使用的是所有的newstest2014.en(3003 s的句子)。
最终五轮测试结束后,显示如下

在第五次基准测试中,测试结果的BLEU高达 24.15,符合要求的 24,达标。在训练集上的速度为 58848 Tok/s,在测试集上的速度为 231080 Tok/s。第五次基准测试从3月8日1:43:08开始执行,于3月8日6:36:58结束,共用时17630秒。
本基准测试生成的结果会在容器中的 pytorch 文件夹下的 results 里,要想在退出镜像后保存,要将其取出。

cp -r results /worktable/training-master/rnn_translator/pyttorch/results
六、NVIDIA v0.6 Translation gnmt 搭建步骤
官方给的都是未经优化的基准测试,仅供参考,大多适用于16 CPUs, one Nvidia P100的机器。不同互联网厂家会对官方的测试进行优化,以针对性适配于自己的机器型号。以下选择的就是英伟达在第二代v0.6,针对单节点,8块V100的gpu,优化后的Translation(non-recurrent)基准测试。
1.将MLPerf库拷到本地
本例使用的是 training_results_v0.6,而不是mlperf / training存储库中提供的参考实现。
git clone https://github.com/Caiyishuai/training_results_v0.6
在此存储库中,有每个供应商提交的目录(Google,Intel,NVIDIA等),其中包含用于生成结果的代码和脚本。在NVIDIA GPU上运行基准测试。
[root@2 ~]# cd training_results_v0.6/
[root@2 training_results_v0.6]# ls
Alibaba CONTRIBUTING.md Fujitsu Google Intel LICENSE NVIDIA README.md
[root@2 training_results_v0.6]# cd NVIDIA/; ls
benchmarks LICENSE.md README.md results systems
[root@2 NVIDIA]# cd benchmarks/; ls
gnmt maskrcnn minigo resnet ssd transformer
2.下载并验证数据集
[root@2 implementations]# pwd
/data/training_results_v0.6/NVIDIA/benchmarks/gnmt/implementations
[root@2 implementations]# ls
data download_dataset.sh pytorch verify_dataset.sh wget-log
download_dataset.sh 中包含下载数据的信息,如果已经下载在本地,要注意修改此文件。
将原来的这部分
echo "Downloading Europarl v7. This may take a while..."
wget -nc -nv -O ${OUTPUT_DIR_DATA}/europarl-v7-de-en.tgz \
http://www.statmt.org/europarl/v7/de-en.tgz
echo "Downloading Common Crawl corpus. This may take a while..."
wget -nc -nv -O ${OUTPUT_DIR_DATA}/common-crawl.tgz \
http://www.statmt.org/wmt13/training-parallel-commoncrawl.tgz
echo "Downloading News Commentary v11. This may take a while..."
wget -nc -nv -O ${OUTPUT_DIR_DATA}/nc-v11.tgz \
http://data.statmt.org/wmt16/translation-task/training-parallel-nc-v11.tgz
echo "Downloading dev/test sets"
wget -nc -nv -O ${OUTPUT_DIR_DATA}/dev.tgz \
http://data.statmt.org/wmt16/translation-task/dev.tgz
wget -nc -nv -O ${OUTPUT_DIR_DATA}/test.tgz \
http://data.statmt.org/wmt16/translation-task/test.tgz
修改为:
echo "Downloading Europarl v7. This may take a while..."
mv -i data/de-en.tgz ${OUTPUT_DIR_DATA}/europarl-v7-de-en.tgz \
echo "Downloading Common Crawl corpus. This may take a while..."
mv -i data/training-parallel-commoncrawl.tgz ${OUTPUT_DIR_DATA}/common-crawl.tgz \
echo "Downloading News Commentary v11. This may take a while..."
mv -i data/training-parallel-nc-v11.tgz ${OUTPUT_DIR_DATA}/nc-v11.tgz \
echo "Downloading dev/test sets"
mv -i data/dev.tgz ${OUTPUT_DIR_DATA}/dev.tgz \
mv -i data/test.tgz ${OUTPUT_DIR_DATA}/test.tgz \
数据处理需要消耗不少时间,消耗大量cpu资源。可能会造成卡顿。数据下载处理完成后,验证数据集。
[root@2 implementations]# du -sh data/
13G data/
[root@2 implementations]# bash verify_dataset.sh
OK: correct data/train.tok.clean.bpe.32000.en
OK: correct data/train.tok.clean.bpe.32000.de
OK: correct data/newstest_dev.tok.clean.bpe.32000.en
OK: correct data/newstest_dev.tok.clean.bpe.32000.de
OK: correct data/newstest2014.tok.bpe.32000.en
OK: correct data/newstest2014.tok.bpe.32000.de
OK: correct data/newstest2014.de
3.配置文件开始准备训练
用于执行训练作业的脚本和代码位于 pytorch 目录中。
[root@2 implementations]# cd pytorch/
[root@2 pytorch]# ll
total 124
-rw-r--r-- 1 root root 5047 Jan 22 15:45 bind_launch.py
-rwxr-xr-x 1 root root 1419 Jan 22 15:45 config_DGX1_multi.sh
-rwxr-xr-x 1 root root 718 Jan 25 10:50 config_DGX1.sh
-rwxr-xr-x 1 root root 1951 Jan 22 15:45 config_DGX2_multi_16x16x32.sh
-rwxr-xr-x 1 root root 1950 Jan 22 15:45 config_DGX2_multi.sh
-rwxr-xr-x 1 root root 718 Jan 22 15:45 config_DGX2.sh
-rw-r--r-- 1 root root 1372 Jan 22 15:45 Dockerfile
-rw-r--r-- 1 root root 1129 Jan 22 15:45 LICENSE
-rw-r--r-- 1 root root 6494 Jan 22 15:45 mlperf_log_utils.py
-rw-r--r-- 1 root root 4145 Jan 22 15:45 preprocess_data.py
-rw-r--r-- 1 root root 12665 Jan 22 15:45 README.md
-rw-r--r-- 1 root root 43 Jan 22 15:45 requirements.txt
-rwxr-xr-x 1 root root 2220 Jan 22 15:45 run_and_time.sh
-rwxr-xr-x 1 root root 7173 Jan 25 10:56 run.sub
drwxr-xr-x 3 root root 45 Jan 22 15:45 scripts
drwxr-xr-x 7 root root 90 Jan 22 15:45 seq2seq
-rw-r--r-- 1 root root 1082 Jan 22 15:45 setup.py
-rw-r--r-- 1 root root 25927 Jan 22 15:45 train.py
-rw-r--r-- 1 root root 8056 Jan 22 15:45 translate.py
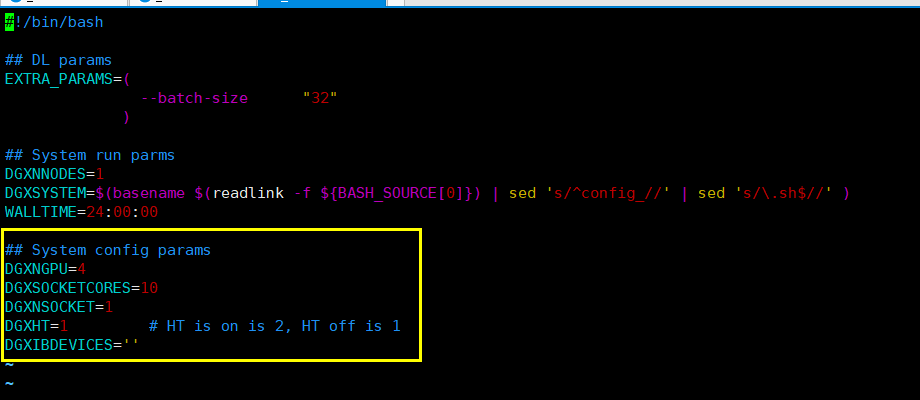
需要配置config_
要编辑的参数:
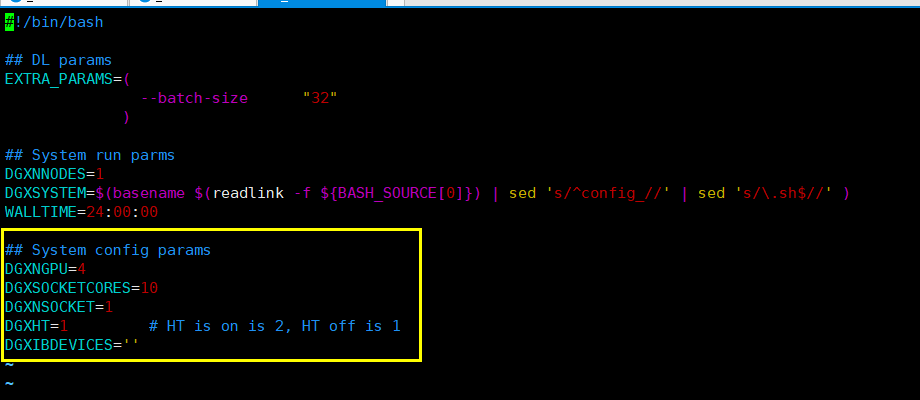
DGXNGPU = 4
DGXSOCKETCORES = 10
DGXNSOCKET = 2
可以使用 nvidia-smi 命令获取GPU信息,并使用 lscpu 命令获取CPU信息,尤其是:
Core(s) per socket: 18
Socket(s): 2
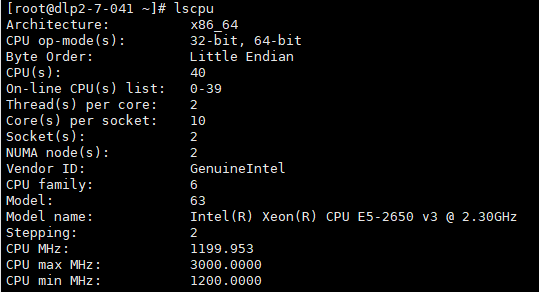
注意:在 run_and_time.sh 文件中也写入上述参数,为防止最终测试失败,在建立镜像前,就应确保参数设置正确。否则运行时会出现 numactl <n-m,n-m> 的错误
下图为对 config_DGX1.sh 内的修改。

下图为对run_and_time.sh内的修改。

4.构建镜像
docker build -t mlperf-nvidia:rnn_translator .
镜像构建需要花不少时间。查看一下dockfile文件。
ARG FROM_IMAGE_NAME=nvcr.io/nvidia/pytorch:19.05-py3
FROM ${FROM_IMAGE_NAME}
# Install dependencies for system configuration logger
RUN apt-get update && apt-get install -y --no-install-recommends \
infiniband-diags \
pciutils && \
rm -rf /var/lib/apt/lists/*
# Install Python dependencies
WORKDIR /workspace/rnn_translator
COPY requirements.txt .
RUN pip install --no-cache-dir https://github.com/mlperf/training/archive/6289993e1e9f0f5c4534336df83ff199bd0cdb75.zip#subdirectory=compliance \
&& pip install --no-cache-dir -r requirements.txt
# Copy & build extensions
COPY seq2seq/csrc seq2seq/csrc
COPY setup.py .
RUN pip install .
# Copy GNMT code
COPY . .
# Configure environment variables
ENV LANG C.UTF-8
ENV LC_ALL C.UTF-8
注意:Docker 报错 Please provide a source image with from prior to commit,是因为Dockerfile的From之前不能使用ARG,允许这种用法是在docker 17.05.0-ce (2017-05-04)之后才引入的。因此要升级docker版本,查看我的docker版本。
[root@2 pytorch]# docker version
Client: Docker Engine - Community
Version: 20.10.2
API version: 1.41
Go version: go1.13.15
Git commit: 2291f61
Built: Mon Dec 28 16:17:48 2020
OS/Arch: linux/amd64
Context: default
Experimental: true
…………
升级docker,先查找主机上关于Docker的软件包。
[root@2 ~]# rpm -qa | grep docker
docker-ce-rootless-extras-20.10.2-3.el7.x86_64
nvidia-docker-1.0.1-1.x86_64
docker-ce-20.10.2-3.el7.x86_64
docker-ce-cli-20.10.2-3.el7.x86_64
使用yum remove卸载软件
# yum remove docker-ce-rootless-extras-20.10.2-3.el7.x86_64
# yum remove docker-ce-20.10.2-3.el7.x86_64
# yum removedocker-ce-cli-20.10.2-3.el7.x86_64
再使用docker命令会提示docker不存在,使用curl升级到最新版
# curl -fsSL https://get.docker.com/ | sh
重启Docker
# systemctl restart docker
设置Docker开机自启 ,完成后就可以用docker version 查看Docker版本信息
# systemctl enable docker
5.运行Benchmark
对于本测试,将使用config_DGX1.sh并因此将DGXSYTEM指定为DGX1。还要将PULL设置为0,以指示使用本地映像而不是从存储库中提取docker映像。创建了一个新目录“ logs”来存储基准日志文件,并在启动基准运行时提供数据目录路径,如下所示:
DATADIR=/data/training_results_v0.6/NVIDIA/benchmarks/gnmt/implementations/data
LOGDIR=/data/training_results_v0.6/NVIDIA/benchmarks/gnmt/implementations/logs
PULL=0 DGXSYSTEM=DGX1
注意:以上参数应写在 run.sub文件里,运行前必须先修改。
如下图所示, vim run.sub ,中 run.sub 中增加上述语句。
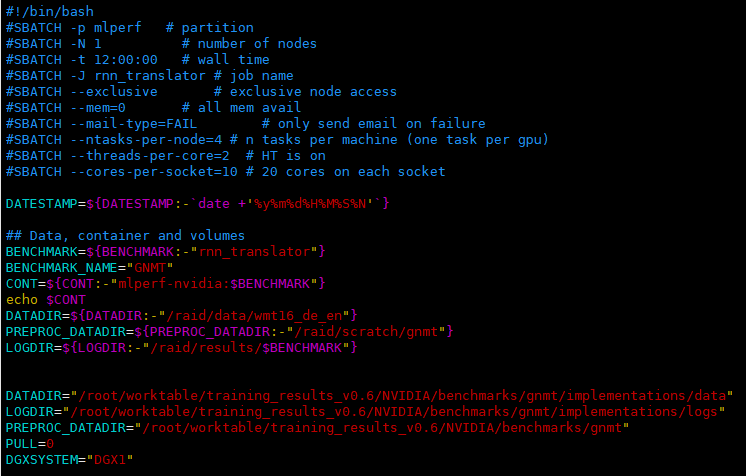
阅读 run.sub 会发现,之后命令中涉及启动镜像,启动镜像的命令保存在 DOCKEREXEC 中,并且会把上述 data 和 logs挂载到镜像。

最后运行 run.sub
./run.sub
注意:运行时会出现 numactl <n-m,n-m> 的错误,提示 cpu ranges out of the actual range 的错误,可能是因为参数没有设置正确。但是仅仅在容器中的 run_and_time.sh 或 config_DGX1.sh 是不行的,可以选择修改完成后,将容器用 docker commit 命令保存为镜像。
如果 RuntimeError: cuda runtime error (209) : no kernel image is available for execution on the device,可能是 pytorch和 cuda 版本不匹配,也有可能是算力不足。测试 pytorch 和 cuda的兼容性。
import torch
import torchvision
print(torch.cuda.is_available())
a = torch.Tensor(5,3)
a=a.cuda()
print(a)
一般来讲,输出主要是报48号错误,也就是CUDA的问题,出现这个问题在于硬件的支持情况。本例中报209错误,在容器中测试 pytorch和 cuda 版本匹配,原因可能是算力不足。
更换机器,采用8块V100gpu。进入工作目录
cd /home/intern/yscai2/worktable/training_results_v0.6/NVIDIA/benchmarks/gnmt/implementations/pytorch
./run.sub
启动基准程序,发现可以运行。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号