
大数据第十四周——Spark编程(RDD编程)
第十五周 Spark编程基础
- 启动集群并检查Spark
- 基于上周未完成部分,这周补上。直接输入以下命令,
~/spark-2.4.5/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster ~/spark-2.4.5/examples/jars/spark-examples_2.11-2.4.5.jar
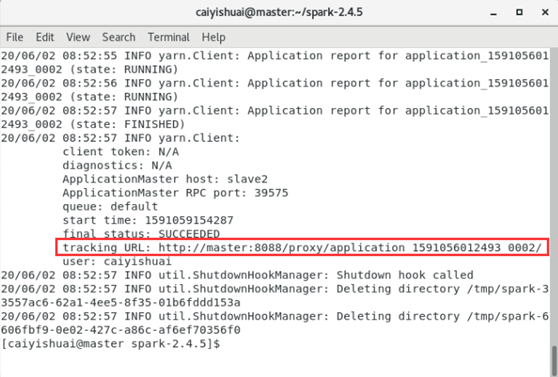
- 当出现下图结果是表示运行成功,并在浏览器中输入结果中的URL,查看结果。
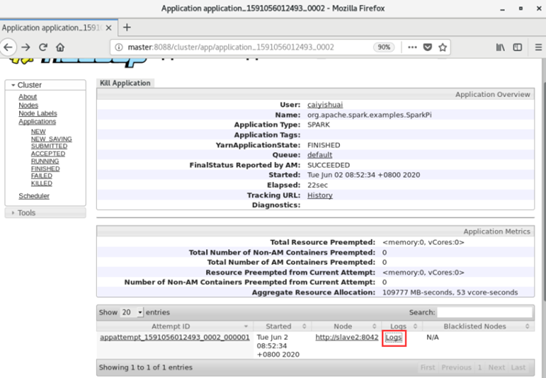
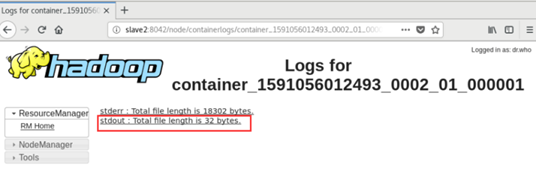
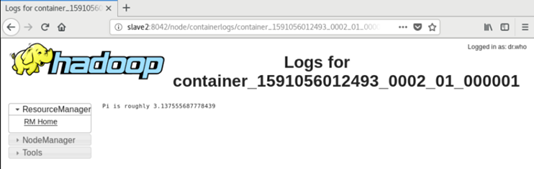
- 如下图所示,结果在"Logs"中的"stdout"里。
- RDD创建
- RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
- 目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储。
- RDD提供了一组丰富的操作以支持常见的数据运算,分为"动作"(Action)和"转换"(Transformation)两种类型。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。
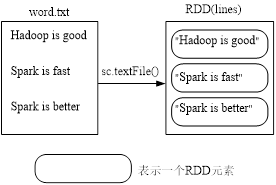
- Spark采用textFile()方法来从文件系统中加载数据创建RDD。该方法把文件的URI作为参数,这个URI可以是:
- 本地文件系统的地址
- 或者是分布式文件系统HDFS的地址
- 或者是Amazon S3的地址等等
2.1 从文件系统中加载数据创建RDD
2.1.1 从本地文件系统中加载数据创建RDD
- scala> val lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
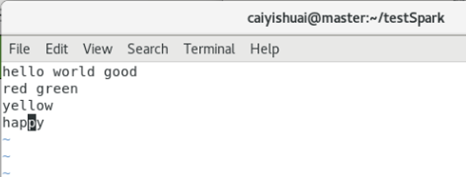
文件中的信息如下图所示:
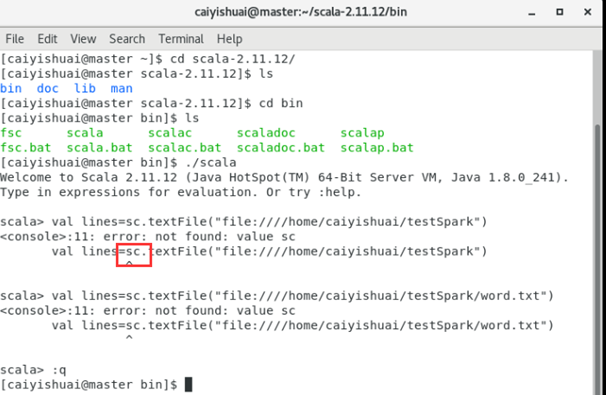
- 直接在scala下"sc"会出问题,因为scala下并没有封装spark的上下文。要在spark下编程。
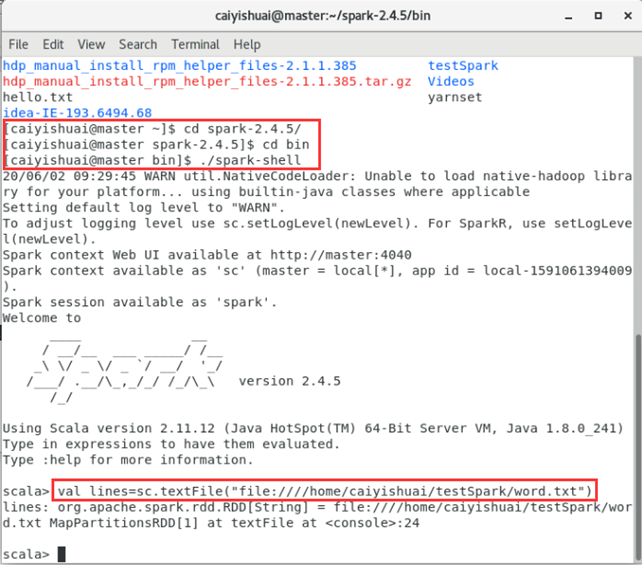
- 如下图所示,运行成功,但这只是一个转化操作,它只是记录了以下。
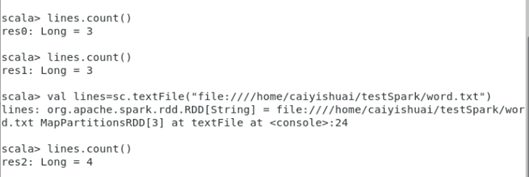
- 执行一个action操作,检查是否可以正常运行。用lines.count(),返回的是文件中的行数,因为RDD是一行行读取文件信息的,如下图所示。
 、
、
- 从分布式文件系统HDFS中加载数据
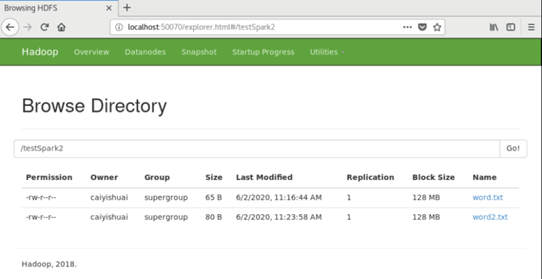
- 在hdfs文件系统中新建文件夹,再上传文件。
hadoop fs –mkdir testSpark
hadoop fs –put word.txt /testSpark
在浏览器中输入master:50070可以查看hdfs详细信息。

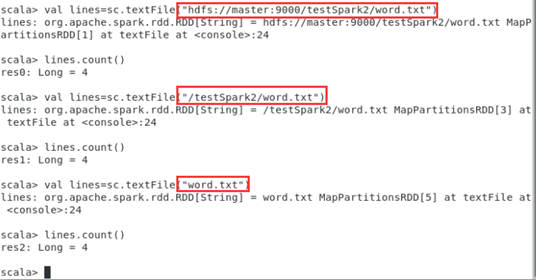
- 输入转换命令,以下三条语句完全等价,可以选择任何一种。
scala> val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")
scala> val lines = sc.textFile("/user/hadoop/word.txt")
scala> val lines = sc.textFile("word.txt")
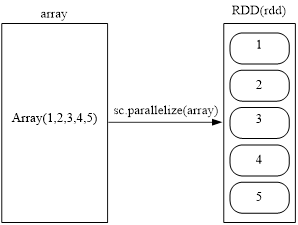
- 通过并行集合(数组)创建RDD
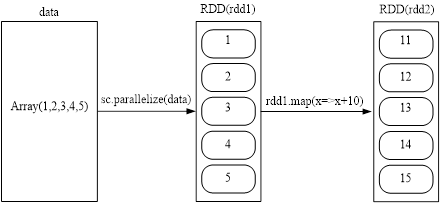
- 可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。从数组创建RDD示意图如下图所示。
scala>val array = Array(1,2,3,4,5)
scala>val rdd = sc.parallelize(array)
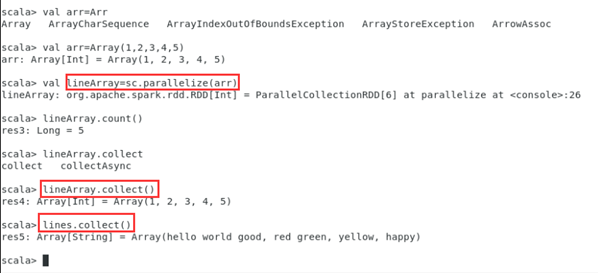
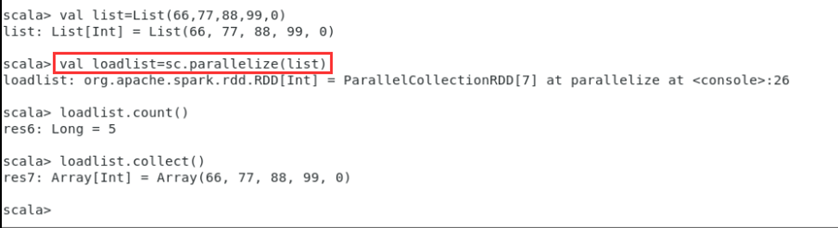
- 或者,也可以从列表中创建。
scala>val list = List(1,2,3,4,5)
scala>val rdd = sc.parallelize(list)
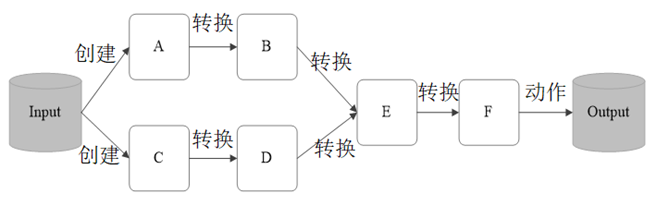
- RDD操作
2.3.1 转化操作
- 下表是常用的RDD转换操作API

- 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个"转换"使用。转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。如下图所示。
- filter(func)
- filter()操作实例执行过程示意图如下。
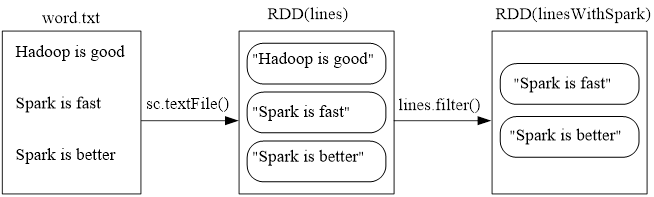
- 命令如下:
scala> val lines =sc.textFile(file:///usr/local/spark/mycode/rdd/word.txt)
scala> val linesWithSpark=lines.filter(line => line.contains("Spark"))
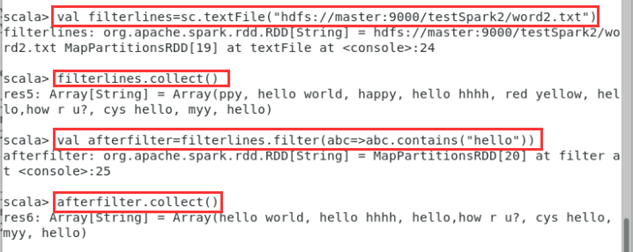
- 尝试一个例子,挑出所有还有"hello"这个词的行,并输出。文件内容如图所示。

- 命令如下
scala>val filterlines=sc.textFile("hdfs://master:9000/testSpark2/word2.txt")
scala>filterlines.collect()
scala> val filterlines=sc.textFile("hdfs://master:9000/testSpark2/word2.txt")
scala> filterlines.collect()
scala> val afterfilter=filterlines.filter(abc=>abc.contains("hello"))
scala> afterfilter.collect()
(2)map(func)
- map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。
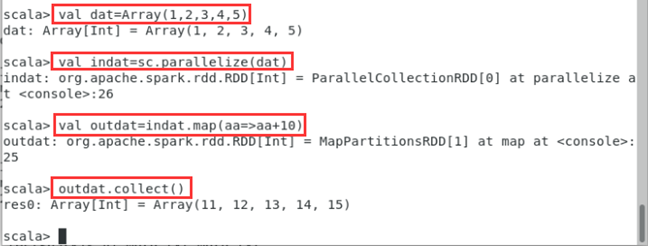
- map操作的例子如下图所示。
scala> val dat=Array(1,2,3,4,5)
scala> val indat=sc.parallelize(dat)
scala> val outdat=indat.map(aa=>aa+10)
scala> outdat.collect()
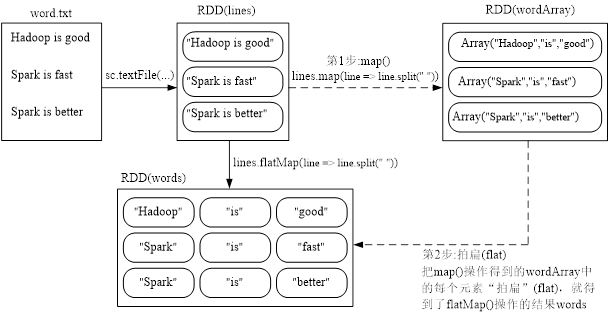
(3) flatMap(func)
- flatMap()操作实例执行过程示意图如下图所示。
- 尝试一个例子,命令和结果如下。
scala> filterlines.collect()
scala> val afterflatmap=filterlines.flatMap(x=>x.split(" "))
scala> afterflatmap.collect()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号