
Spark学习笔记3:键值对操作
键值对RDD通常用来进行聚合计算,Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为pair RDD。pair RDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
Spark中创建pair RDD的方法:存储键值对的数据格式会在读取时直接返回由其键值对数据组成的pair RDD,还可以使用map()函数将一个普通的RDD转为pair RDD。
- Pair RDD的转化操作
- reduceByKey() 与reduce类似 ,接收一个函数,并使用该函数对值进行合并,为每个数据集中的每个键进行并行的归约操作。返回一个由各键和对应键归约出来的结果值组成的新的RDD。例如 :上一章中单词计数的例子:val counts = words.map(word => (word,1)).reduceByKey{ case (x,y) => x + y}
- foldByKey()与fold()类似,都使用一个与RDD和合并函数中的数据类型相同的零值最为初始值。val counts = words.map(word => (word,1)).foldByKey{ case (x,y) => x + y}
- combineByKey()是最为常用的基于键进行聚合的函数,可以返回与输入类型不同的返回值。
理解combineByKey处理数据流程,首先需要知道combineByKey的createCombiner()函数用来创建那个键对应的累加器的初始值,mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并。mergeCombiners()方法将各个分区的结果进行合并。
使用combineByKey进行单词计数的例子:
import org.apache.spark.{SparkConf, SparkContext}
object word {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("word")
val sc = new SparkContext(conf)
val input = sc.parallelize(List(("coffee",1),("coffee",2),("panda",3),("coffee",9)))
val counts = input.combineByKey(
(v) => (v,1),
(acc:(Int,Int) ,v) => (acc._1 + v,acc._2+1),
(acc1:(Int,Int),acc2:(Int,Int)) => (acc1._1 + acc2._1,acc1._2 + acc2._2)
)
counts.foreach(println)
}
}
输出结果:
这个例子中的数据流示意图如下:
简单说过程就是,将输入键值对数据进行分区,每个分区先根据键计算相应的值以及键出现的次数。然后对不同分区进行合并得出最后的结果。
4.groupByKey()使用RDD中的键来对数据进行分组,对于一个由类型K的键和类型V的值组成的RDD,所得到的结果RDD类型会是[K, Iterable[V] ]
例如:
import org.apache.spark.{SparkConf, SparkContext}
object word {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("word")
val sc = new SparkContext(conf)
val input = sc.parallelize(List("scala spark scala core scala python java spark scala"))
val words = input.flatMap(line => line.split(" ")).map(word => (word,1))
val counts = words.groupByKey()
counts.foreach(println)
}
}
输出:

5、cogroup函数对多个共享同一个键的RDD进行分组,对两个键类型均为K而值类型分别为V和W的RDD进行cogroup时,得到的结果RDD类型为[(K,(Iterable[V],Iterable[W]))]
6、join(other)这样的连接是内连接,只有在两个pair RDD中都存在的键才输出。若一个输入对应的键有多个值时,生成的pair RDD会包括来自两个输入RDD的每一组相对应的记录。理解这句话看下面的例子:
val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) val other = sc.parallelize(List((3,9))) val joins = rdd.join(other)
输出结果:

7、leftOuterJoin(other)左外连接和rightOuterJoin(other)右外连接都会根据键连接两个RDD,但是允许结果中存在其中的一个pair RDD所缺失的键。
val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) val other = sc.parallelize(List((3,9))) val join1 = rdd.rightOuterJoin(other)
输出结果:
val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) val other = sc.parallelize(List((3,9))) val join2 = rdd.leftOuterJoin(other)
输出结果:

8、sortByKey()函数接收一个叫做ascending的参数,表示想要让结果升序排序还是降序排序。
val input = sc.parallelize(List("scala spark scala core scala python java spark scala"))
val words = input.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((x,y)=>x+y)
val counts = words.sortByKey()
输出结果:

- Pair RDD的行动操作
- countByKey() 对每个键对应的元素分别计数。
- collectAsMap()将结果以映射表的形式返回,注意后面的value会覆盖前面的。
val num = sc.parallelize(List((1,2),(3,4),(3,6))) println(num.collectAsMap().mkString(" "))输出结果:
![]()
- lookup(key)返回给定键对应的所有值。
- 数据分区
Spark程序可以通过控制RDD分区方式来减少通信开销。
运行下面这段代码,用来查看用户查阅了自己订阅的主题的页面的数量,结果返回3:
val list1 =List(Tuple2("Mike",List("sports","math")),Tuple2("Jack",List("travel","book")))//UserID用户ID,UserInfo用户订阅的主题
val list2= List(Tuple2("Mike","sports"),Tuple2("Mike","stock"),Tuple2("Jack","travel"),Tuple2("Jack","book"))//UserID,LinkInfo用户访问情况
val userData = sc.parallelize(list1)
val events = sc.parallelize(list2)
userData.persist()
val joined = userData.join(events)
val results = joined.filter({
case (id, (info, link)) =>
info.contains(link)
}
).count()
println(results)
上面这段代码中,用到了join操作,会将两个数据集中的所有键的哈希值都求出来,将该哈希值相同的记录通过网络传到同一台机器上,然后在那台机器上对所有键相同的记录进行连接操作。
假如userdata表很大很大,而且几乎是不怎么变化的,那么每次都对userdata表进行哈希值计算和跨节点的数据混洗,就会产生很多的额外开销。
如下:
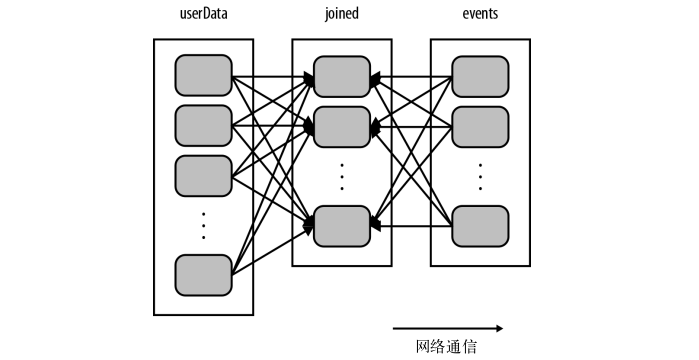
解决这一产生额外开销的方法就是,对userdata表使用partitionBy()转化操作,将这张表转为哈希分区。修改后的代码如下:
val list1 =List(Tuple2("Mike",List("sports","math")),Tuple2("Jack",List("travel","book")))//UserID用户ID,UserInfo用户订阅的主题
val list2= List(Tuple2("Mike","sports"),Tuple2("Mike","stock"),Tuple2("Jack","travel"),Tuple2("Jack","book"))//UserID,LinkInfo用户访问情况
val userData = sc.parallelize(list1)
val events = sc.parallelize(list2)
userData.partitionBy(new DomainNamePartitioner(10)).persist()
val joined = userData.join(events)
val results = joined.filter({
case (id, (info, link)) =>
info.contains(link)
}
).count()
println(results)
构建userData时调用了partitionBy(),在调用join()时,Spark只会对events进行数据混洗操作,将events中特定UserID的记录发送到userData的对应分区所在的那台机器上。这样,通过网络传输的数据就大大减少,程序运行速度也可以显著提升。partitionBy()是一个转化操作,因此它的返回值是一个新的RDD。
新的数据处理过程如下:
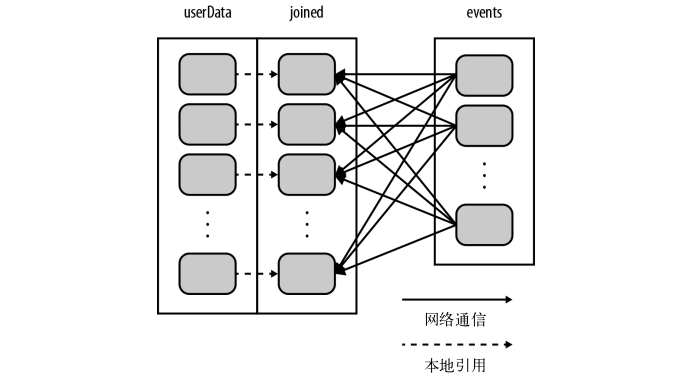
scala可以使用RDD的partitioner属性来获取RDD的分区方式,它会返回一个scala.Option对象。
可以从数据分区中获益的操作有cogroup() , groupWith() , join() , leftOuterJoin() , rightOuterJoin() , groupByKey() , reduceByKey() , combineByKey()以及lookup()。
实现自定义分区器,需要继承org.apache.spark.Partitioner类并实现下面的三个方法:
- numPartitions: Int :返回创建出来的分区数
- getPartition(key: Any):Int : 返回给定键的分区编号(0 到 numPartitions - 1)
- equals() : Java判断相等的方法,Spark用这个方法来检查分区器对象是否和其他分区器实例相同,这样Spark才可以判断两个RDD的分区方式是否相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号