

Kaggle-pandas(1)
Creating-reading-and-writing
教程
1.创建与导入
DataFrame
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
生成的表如下:
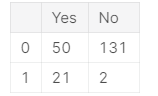
我们正在使用pd.DataFrame()构造函数来生成这些DataFrame对象。 声明新字典的语法是字典,其关键字是列名(在此示例中为Yes和No),其值是条目列表。 这是构造新DataFrame的标准方法,也是您最有可能遇到的一种方法。
字典列表构造函数将值分配给列标签,但仅对行标签使用从0(0、1、2、3,...)开始的递增计数。 有时这可以,但是通常我们会自己分配这些标签。
DataFrame中使用的行标签列表称为索引。 我们可以通过在构造函数中使用index参数来为其赋值:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])

Series
相比之下,系列是数据值的序列。 如果DataFrame是表,则Series是列表。 实际上,您可以创建一个只包含一个列表的列表:
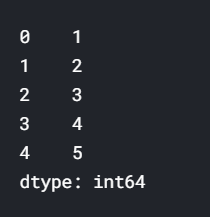
本质上,Series是DataFrame的单个列。 因此,您可以使用索引参数,以与以前相同的方式将列值分配给Series。 但是,系列没有列名,只有一个整体名:
Series和DataFrame密切相关。 认为DataFrame实际上只是一堆“胶合在一起”的Series很有帮助。 我们将在本教程的下一部分中看到更多信息。
2.读取数据文件
能够手动创建DataFrame或Series很方便。 但是,在大多数情况下,我们实际上不会手工创建自己的数据。 相反,我们将使用已经存在的数据。
数据可以多种不同形式和格式存储。 到目前为止,最基本的是不起眼的CSV文件。 当您打开CSV文件时,您将获得如下所示的内容:

因此,CSV文件是由逗号分隔的值表。 因此,名称为:“逗号分隔值(Comma-Separated Values")”或CSV。
现在让我们搁置玩具数据集,看看当我们将其读入DataFrame时真实数据集的外观。 我们将使用pd.read_csv()函数将数据读取到DataFrame中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号