Ubuntu kylin优麒麟下配置Hive环境
Ubuntu kylin优麒麟下配置Hive环境
Hive简介
- 什么是Hive
hive是基于Hadoop的一个数据仓储工具,可以将结构化的数据文件映射为一张数据表,并提供SQL查询功能,可以将SQL语句转化为MapReduce任务进行执行。hive是基于Hadoop的一个数据仓储工具,可以将结构化的数据文件映射为一张数据表,并提供SQL查询功能,可以将SQL语句转化为MapReduce任务进行执行。 - Hive的优点
学习成本年低,可以通过类SQL语句快速实现简单的MapReduce统计计算,不必开发专门的MapReduce,十分适合数据仓储的统计与分析。 - Hive的缺点
虽然用类SQL简化了操作,但是实际上还是在hdfs上调用了MapReduce,这样的话,效率还是有所降低的。 - Hive数据仓储与数据库的区别
Hive:数据仓储
Hive:解释器、编译器、优化器等。
Hive:运行时,元数据存储在关系型数据库里面。
数据仓储主要用来保存数据,对数据进行分析计算,一次写入,多次读取,不能修改,不能删除单条数据,除非把整个文件删除。我们用的修改其实是覆盖,先把整个文件下载下来,修改后重新上传。
Hive的主要功能可以将一条数据转换为MapReduce,Hive依赖于HDFS和Yarn。
Hive架构
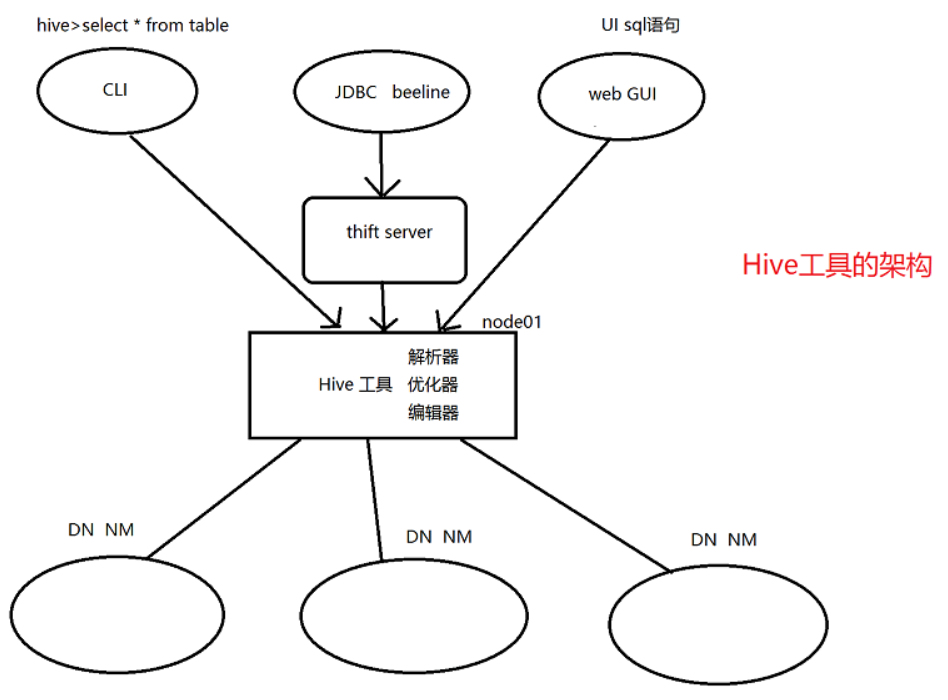
- 用户接口:包括CLI,JDBC/ODBC,web UI
- 元数据存储,通常是存储在关系型数据库中mysql,derby中
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hive的真实数据(源数据)存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive与传统数据库进行比较
| 查询语言 | HQL | SQL |
|---|---|---|
| 数据存储位置 | HDFS | 本地FS |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 新版本有,但弱 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符 (”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
环境配置
1、下载Hive安装包
2、将hive文件上传到HADOOP集群,并解压
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local

3、配置环境变量,编辑/etc/profile
vim /etc/profile

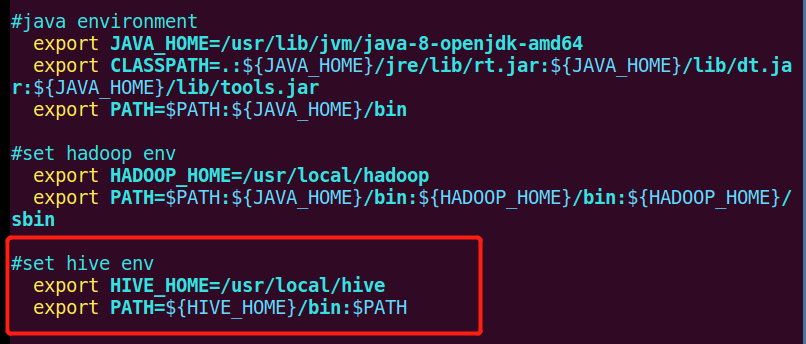
#set hive env export HIVE_HOME=/usr/local/hive export PATH=${HIVE_HOME}/bin:$PATH
#让环境变量生效
source /etc/profile
4、修改hive配置文件
- 进入配置文件的目录
cd /usr/local/hive/conf/
- 修改hive-env.sh文件(如果没有就新建)
cp hive-env.sh.template hive-env.sh
vim /hive-env.sh
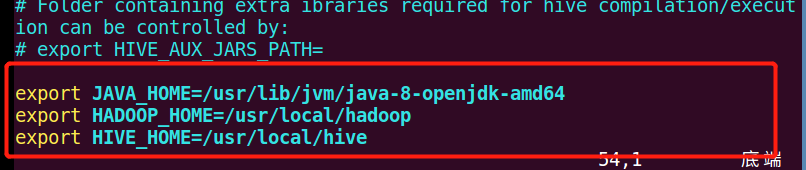
将以下内容写入到hive-env.sh文件中
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_HOME=/usr/local/hadoop export HIVE_HOME=/usr/local/hive
- 修改log4j文件(如果没有就新建)
cp hive-log4j.properties.template hive-log4j.properties

- 配置远程登录模式
vim hive-site.xml
将以下信息写入到hive-site.xml文件中
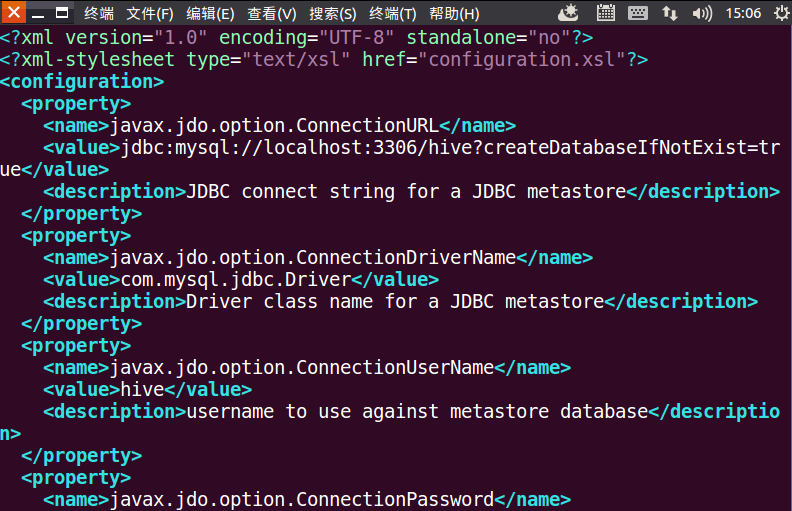

<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> </configuration>
安装mysql
安装mysql并配置hive数据库及权限
- 安装mysql数据库及客户端
yum install mysql-server
yum install mysql
servicemysqld start
- 配置hive元数据库
mysql-u root -p
create database hivedb;
- 对hive元数据库进行赋权,开放远程连接,开放localhost连接
grant all privileges on *.* to root@"%" identified by "root" with grant option;
grant all privileges on *.* tshoo root@"localhost" identified by "root" with grant option;
6、运行hive命令即可启动hive
hive
愿路途漫长,以后莫失莫忘。 愿你不骄不躁,安稳顺心。
作者:菜鸟-传奇
本文版权归作者和博客园共有,重在学习交流,不以任何盈利为目的,欢迎转载。
敲敲小黑板:《刑法》第二百八十五条 【非法侵入计算机信息系统罪;非法获取计算机信息系统数据、非法控制计算机信息系统罪】违反国家规定,侵入国家事务、国防建设、尖端科学技术领域的计算机信息系统的,处三年以下有期徒刑或者拘役。违反国家规定,侵入前款规定以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,或者对该计算机信息系统实施非法控制,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号