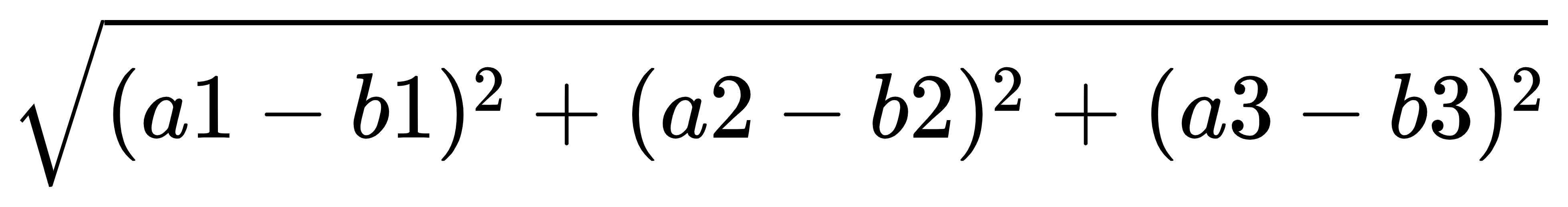什么是k-近邻算法
K-近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。简单来说就是根据邻居的特征来判断样本的特征。
k-近邻算法的优缺点
优点:
1.k近邻算法是一种在线技术,新数据可以直接加入数据集而不必进行重新训练,
2.k近邻算法理论简单,容易实现。
3.准确性高,对异常值和噪声有较高的容忍度。
4.k近邻算法天生就支持多分类,区别与感知机、逻辑回归、SVM。
缺点:
1.基本的 k近邻算法每预测一个“点”的分类都会重新进行一次全局运算,对于样本容量大的数据集计算量比较大。
2.K近邻算法容易导致维度灾难,在高维空间中计算距离的时候,就会变得非常远;样本不平衡时,预测偏差比较大,k值大小的选择得依靠经验或者交叉验证得到。k的选择可以使用交叉验证,也可以使用网格搜索。k的值越大,模型的偏差越大,对噪声数据越不敏感,当 k的值很大的时候,可能造成模型欠拟合。k的值越小,模型的方差就会越大,当 k的值很小的时候,就会造成模型的过拟合。
k-近邻算法的公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
比如:a(a1,a2,a3)和b(b1,b2,b3)的距离