
XORing Elephants: Novel Erasure Codes for Big Data
RS基础上做了改进,通过增加存储冗余,优化性能
1. INTRODUCTION
介绍了多副本,纠删码。
纠删码的修复主要问题是,带宽开销,假如是(10,4),修复一块需要10倍块大小的带宽
提出了LRC的概念
1.1. Importance of Repair
分析了Facebook的相关数据得出降低网络带宽代价是重要的结论
efficiently repairable重要的原因
-
degraded reads
很多瞬时错误并不会丢失永久性数据,但是会造成数据不可用,这个时候读编码的条块会读降级。
这个时候可以通过修复过程重建数据块,但是目的不是容错,而是为了更高的数据可用性。重建的块不必写入磁盘
所以efficient and fast repair 可以提高数据可用性
-
efficient node decommissioning
Hadoop可以让故障节点退役
Functional data必须在退役之前从节点中复制出来,这是一个复杂且耗时的过程
Fast repairs可以把节点退役视为定期修复,并且重新创建块,不会产生非常大的网络流量
-
repair influences the performance of other concurrent MapReduce jobs
因为修复需要占用一定的网络带宽,与数据中心的网络带宽相比,存储空间的增长速度不成比例地快。所以这个问题会越来越严重,所以local repairs显得越发重要
-
local repair would be a key in facilitating geographically distributed file systems across data centers
RS在跨地理的程度上是不可行的 因为high bandwidth requirements across wide area networks
local repair是可行的
复制可以很好的处理上面的问题,但是存储开销较大。MDS开销小,但是会遇到上面的问题。
本文可以看作是牺牲了一些存储效率,来达到其他指标
2. THEORETICAL CONTRIBUTIONS
MDS在通信和存储领域应用非常广泛
MDS是最低恢复冗余
两个定义
-
Minimum Code Distance
-
Block Locality
locality和good distance是矛盾的
LRC(k, n−k, r)
2.1. LRC implemented in Xorbas
Ci的选择有要求 线性无关,不能为0
设计了一个随机算法和确定算法,可以生成系数
有个优化S3不用存储,构造出来S1+S2+S3=0
系数的构造
3. SYSTEM DESCRIPTION
在HDFS-RAID上实现
RaidNode
负责创建和维护校验块
BlockFixer
用来修复块
ErasureCode
实现编码和解码功能,上面两个组件都依赖于他
HDFS-Xorbas 在HDFS-RAID基础上增加了LRC
3.1. HDFS-Xorbas
3.1.1. 编码
RaidNode 将一个文件分成10块,然后编码出4块。可能一个文件可能不够10块,默认剩下的填充为0,依旧是10块
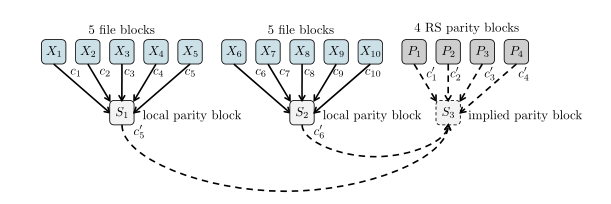
LRC会额外计算两个块,如上图所示
3.1.1.2 解码和修复
RaidNode
light-decoder
针对于每个条带单个块的错误
heavy-decoder
light-decoder失败的时候使用
BlockFixer
检测到块失败,决定LRC恢复需要的5个块
light-decoding尝试恢复
如果出现multiple failures,可能没有需要的5个块, light-decoder失败, heavy-decoder启动
heavy-decoder跟RS恢复过程一样,将结果发送和存储到数据节点
4.RELIABILITY ANALYSIS
mean-time to data loss (MTTDL) 可靠性分析的依据
可以容忍的故障数
修复的速度
弹性增加和修复时间减小,MTTDL也会增加
结果LRC,RS比复制高了很多,但是复制的数据可用性比LRC和RS强
5. EVALUATION
两种环境性能
Amazon’s Elastic Compute Cloud
a test cluster in Facebook
5.1 评价指标
HDFS Bytes Read
对应于为修复而启动的作业所读取的总数据量
collected from the statistics-reports of the jobs spawned following a failure event
Network Traffic
the total amount of data communicated from nodes in the cluster
单位为GB
用下面这个工具来监测
Amazon’s A WS Cloudwatch monitoring tools
Repair Duration
the time interval between the starting time of the first repair job and the ending time of the last repair job.
5.2 EC2
two Hadoop clusters
HDFS-Xorbas
HDFS-RS
Each cluster
51 instances of type m1.small
1 master hosting Hadoop’s NameNode, JobTracker and RaidNode daemons
50 slave as DataNode and a TaskTracker daemon
file size 640 MB
block size 64MB
每个文件两个集群中分别生成14和16块
故障包括一个数据节点或者多个数据节点的终止
四个故障事件是单节点错误,两个三节点错误,两个两节点错误
文件数量(20,100,200)
5.2.1 HDFS Bytes Read
HDFS-Xorbas 比HDFS-RS好41%-52%
读的平均块数从11.5降到5.8
5.2.2 Network Traffic
网络流量和读取的字节数基本上一致,二倍的关系
5.2.3 Repair Time
Xorbas比HDFS-RS快25%到45%
实验里面带宽没满,实际环境中带宽可能跑满,时间表现可能更好
5.2.4 Repair under Workload
为了演示修复性能对集群负载的影响。
创建了两个集群
每个集群15个从节点
块故障时不可用,LRC相比RS延迟小
5.3 Facebook’s cluster
区别点在于利用的集群中现有的数据集
块大小为256MB
94%文件3块 剩下10块 平均3.4块
由于块大小比较小,Xorbas比HDFS-RS存储开销大了27%(最好应为13%)
6. RELATED WORK
functional repair
虽然块可以恢复,但是这个时候确实不可使用,需要其他k块来恢复
exact repair
使用更小网络代价来修复是有可能的
low rate
high rate
这部分涉及到的工作还挺多的,有时间可以看一看具体内容
7. CONCLUSIONS
LRC降低带宽开销2倍,增加存储开销14%
提出了想法,应用在宽条带上,RS在宽条带上不可行,因为带宽要求随着块大小增长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号