


UniMrcp中asr超时逻辑
环境:FreeSwitch-1.10.7 unimrcp-1.6.0 webrtc-vad
默认情况下,仅有 SPEECH_COMPLETE,才会返回识别结果,修改为 【非 no_input_timeout 状态,都会返回识别结果】
1.默认超时逻辑
1.1 首先区分三个关键主体:
- FreeSwitch:识别发起方,提供语音流和识别超时参数
- recog_engine: 识别接收方,接受音频流并推送至ASR音频,处理超时参数
- mpf: 语音活动监测,使用超时参数控制检测流程
1.2 超时参数配置
识别开始时,在函数demo_recog_channel_recognize中识别FS发送的超时参数
/** Process RECOGNIZE request */ static apt_bool_t demo_recog_channel_recognize(mrcp_engine_channel_t *channel, mrcp_message_t *request, mrcp_message_t *response) { ****************** 忽略部分无关代码 ****************** /* get recognizer header */ recog_header = mrcp_resource_header_get(request); if(recog_header) { if(mrcp_resource_header_property_check(request,RECOGNIZER_HEADER_START_INPUT_TIMERS) == TRUE) { recog_channel->timers_started = recog_header->start_input_timers; } if(mrcp_resource_header_property_check(request,RECOGNIZER_HEADER_NO_INPUT_TIMEOUT) == TRUE) { apt_log(RECOG_LOG_MARK,APT_PRIO_INFO,"recog_header->no_input_timeout [%lu]", (unsigned long)recog_header->no_input_timeout); mpf_activity_detector_noinput_timeout_set(recog_channel->detector,recog_header->no_input_timeout); }else { mpf_activity_detector_noinput_timeout_set(recog_channel->detector,5000); } if(mrcp_resource_header_property_check(request,RECOGNIZER_HEADER_SPEECH_COMPLETE_TIMEOUT) == TRUE) { /** 非静音->静音所需时间,同时表示说话人已经停止说话,语音识别资源成功返回结果之间所必须消耗的时间 **/ apt_log(RECOG_LOG_MARK,APT_PRIO_INFO,"recog_header->speech_complete_timeout [%lu]", (unsigned long)recog_header->speech_complete_timeout); mpf_activity_detector_silence_timeout_set(recog_channel->detector,recog_header->speech_complete_timeout); }else { mpf_activity_detector_speech_timeout_set(recog_channel->detector,1000); } if(mrcp_resource_header_property_check(request,RECOGNIZER_HEADER_RECOGNITION_TIMEOUT) == TRUE) { /** 限定整个识别处理时间 **/ apt_log(RECOG_LOG_MARK,APT_PRIO_INFO,"recog_header->recognition_timeout [%lu]", (unsigned long)recog_header->recognition_timeout); mpf_activity_detector_recognition_timeout_set(recog_channel->detector,recog_header->recognition_timeout); }else { mpf_activity_detector_recognition_timeout_set(recog_channel->detector,30000); } } ****************** 忽略部分无关代码 ****************** }
FS发送的超时参数 speech_incomplete_timeout ,被 recog_engine 识别为 speech_complete_timeout,并在 mpf 中设置为 silence_timeout ,表示从 activity 转换为 inactivity 所需时间;
no_input_timeout ,在 recog_engine 和 mpf 中同名,表示从识别开始最大的无声音时间 ;
recognition_timeout ,默认未使用该参数,表示整个识别流程的最大时间。
1.3 mpf中超时参数使用
主要有两个函数:
mpf_activity_detector_level_calculate计算音频活动状态,有活动返回值>=1,无活动返回值<1
下面是采用webrtc-vad的检测代码
static apr_size_t mpf_activity_detector_level_calculate(const mpf_frame_t *frame) { apr_size_t samplesCount = frame->codec_frame.size/2; int per_ms_frames = 20; apr_size_t sampleRate = 8000; size_t samples = sampleRate * per_ms_frames / 1000; if (samples == 0) return -1; size_t nTotal = (samplesCount / samples); int16_t *input = frame->codec_frame.buffer; VadInst *vadInst; if (WebRtcVad_Create(&vadInst)) { return -1; } int status = WebRtcVad_Init(vadInst); if (status != 0) { WebRtcVad_Free(vadInst); return -1; } int16_t vad_mode = 1; status = WebRtcVad_set_mode(vadInst, vad_mode); if (status != 0) { WebRtcVad_Free(vadInst); return -1; } int cnt = 0; int i = 0; if(nTotal > 0) { for (i = 0; i < nTotal; i++) { //int keep_weight = 0; int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samples); //printf("==========%d=============== \n", nVadRet); if (nVadRet == -1) { WebRtcVad_Free(vadInst); return -1; } else { if (nVadRet >= 1) { cnt++; } } input += samples; } WebRtcVad_Free(vadInst); if (cnt < nTotal/10) { return 0; } else { return 1; } } if(nTotal == 0) { int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samplesCount); //printf("==========%d=============== \n", nVadRet); WebRtcVad_Free(vadInst); return nVadRet; } return 0; }
mpf_activity_detector_process,音频状态转换函数
MPF_DECLARE(mpf_detector_event_e) mpf_activity_detector_process(mpf_activity_detector_t *detector, const mpf_frame_t *frame) { apt_log(MPF_LOG_MARK,APT_PRIO_DEBUG,"[mpf webrtc]Activity Detector Process"); mpf_detector_event_e det_event = MPF_DETECTOR_EVENT_NONE; apr_size_t level = 0; if((frame->type & MEDIA_FRAME_TYPE_AUDIO) == MEDIA_FRAME_TYPE_AUDIO) { level = mpf_activity_detector_level_calculate(frame); #if 0 apt_log(MPF_LOG_MARK,APT_PRIO_DEBUG,"Activity Detector --------------------- [%"APR_SIZE_T_FMT"]",level); #endif } detector->total_duration += CODEC_FRAME_TIME_BASE; apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----channel detect speech total duration ---- [%d][%d]", detector->total_duration,detector->recognition_timeout); if(detector->total_duration >= detector->recognition_timeout) { apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----channel detect speech total duration ---------------- [%d]", detector->total_duration); det_event = MPF_DETECTOR_EVENT_RECOGNITION_TIMEOUT; return det_event; } if(detector->state == DETECTOR_STATE_INACTIVITY) { if(level >= 1) { //apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----DETECTOR_STATE_ACTIVITY_TRANSITION---------------- [%"APR_SIZE_T_FMT"]",level); mpf_activity_detector_state_change(detector, DETECTOR_STATE_ACTIVITY_TRANSITION); } else { detector->duration += CODEC_FRAME_TIME_BASE; if(detector->duration >= detector->noinput_timeout) { det_event = MPF_DETECTOR_EVENT_NOINPUT; } } } else if(detector->state == DETECTOR_STATE_ACTIVITY_TRANSITION) { if(level >= 1) { detector->duration += CODEC_FRAME_TIME_BASE; //apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----DETECTOR_STATE_ACTIVITY-------11111--------- [%"APR_SIZE_T_FMT"]",level); if(detector->duration >= detector->speech_timeout && detector->start_of_input == TRUE) { det_event = MPF_DETECTOR_EVENT_ACTIVITY; mpf_activity_detector_state_change(detector, DETECTOR_STATE_ACTIVITY); } } else { mpf_activity_detector_state_change(detector,DETECTOR_STATE_INACTIVITY); } } else if(detector->state == DETECTOR_STATE_ACTIVITY) { if(level >= 1) { //apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----DETECTOR_STATE_ACTIVITY--------2222-------- [%"APR_SIZE_T_FMT"]",level); detector->duration += CODEC_FRAME_TIME_BASE; } else { //apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----DETECTOR_STATE_INACTIVITY_TRANSITION---------------- [%"APR_SIZE_T_FMT"]",level); mpf_activity_detector_state_change(detector,DETECTOR_STATE_INACTIVITY_TRANSITION); } } else if(detector->state == DETECTOR_STATE_INACTIVITY_TRANSITION) { if(level >= 1) { mpf_activity_detector_state_change(detector,DETECTOR_STATE_ACTIVITY); } else { detector->duration += CODEC_FRAME_TIME_BASE; if(detector->duration >= detector->silence_timeout) { //apt_log(MPF_LOG_MARK,APT_PRIO_INFO,"Activity Detector ----DETECTOR_STATE_INACTIVITY---------------- [%"APR_SIZE_T_FMT"]",level); det_event = MPF_DETECTOR_EVENT_INACTIVITY; mpf_activity_detector_state_change(detector,DETECTOR_STATE_INACTIVITY); } } } return det_event; }
此函数会返回处理后的当前音频状态,recog_engine 接收处理结果后,进一步控制识别流程
下图为识别流程状态机:
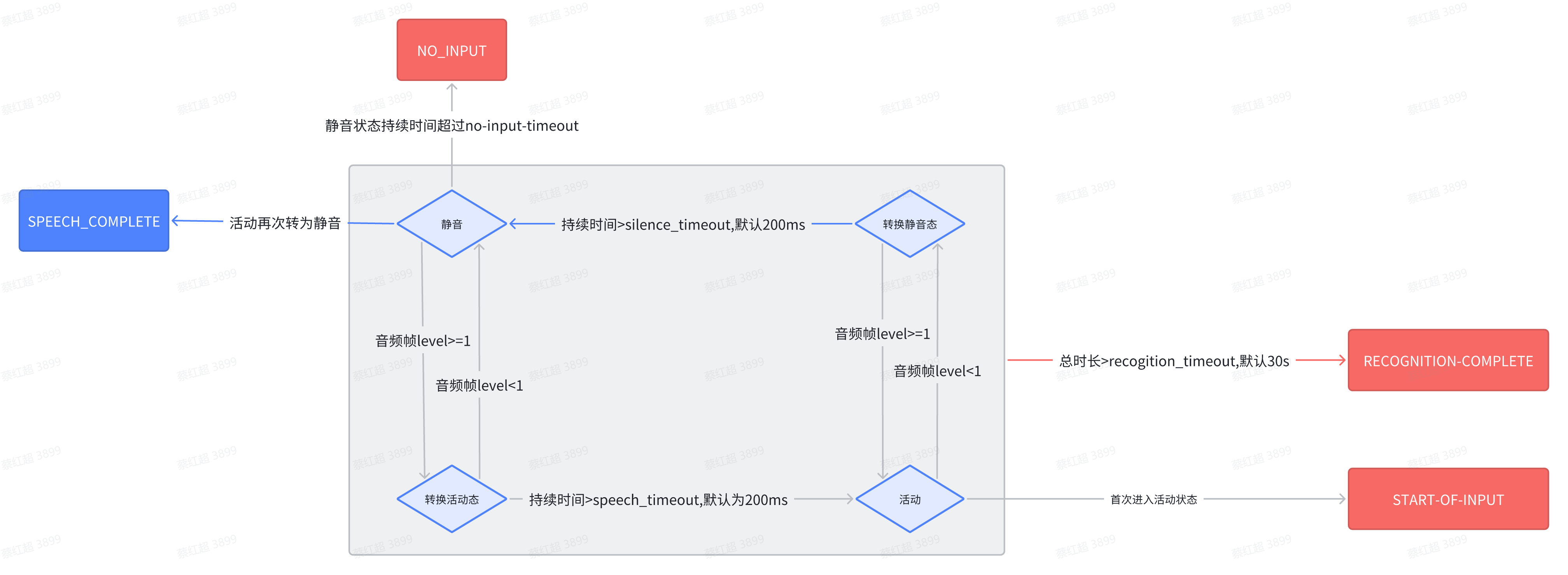
备注:
1.音频帧长度为10ms,8000采样率为160字节
2.音频帧level算法采用webrtc方案,level<1为静音
3.每次状态变化都会重新计算状态持续时长
4.首次进入活动状态,会触发start_of_input,返回给FS,FS收到后会停止放音(play_and_detect_speech)优化点
4.speech_complete_timeout 非静音->静音所需时间,同时表示说话人已经停止说话,
语音识别资源成功返回结果之间所必须消耗的时间,对应mrcp中silence_timeout
5.必须由转换静音态再次进入静音态,才会触发speech_complete,此时为正常mrcp流程的识别结束
6.必须一直处于静音状态,才会触发no_input
7.总识别时长(无论什么状态)>recogition_timeout,会触发识别超时RECOGNITION-COMPLETE,
(原生mrcp协议header,默认未使用,个人改造开启)
8.除no_input_timeout外,其余均会正常返回识别结果
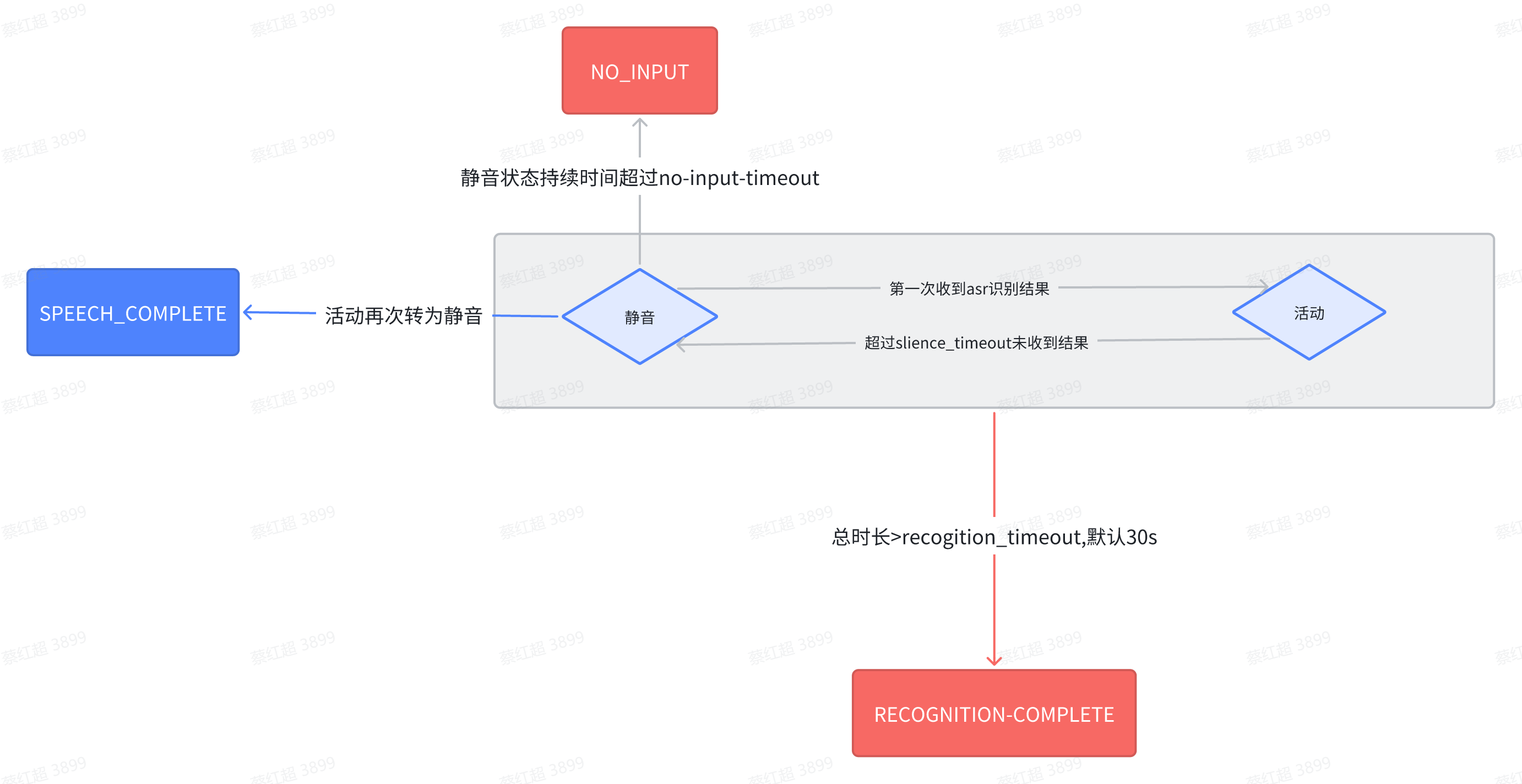
2.优化后超时逻辑
2.1优化原因:环境噪音也会触发start_of_input,打断FS放音,使用效果很差
2.2 优化逻辑:修改状态转换逻辑,只有收到ASR识别结果才会认为开始输入
2.3 优化后的识别流程状态机


 浙公网安备 33010602011771号
浙公网安备 33010602011771号