
结对第2次作业——WordCount进阶需求
软工实践第五次作业-爬虫和自定义词频统计
题目地址:https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1816W/homework/2160
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 600 | 750 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 40 | 50 |
| • Design Spec | • 生成设计文档 | 10 | 20 |
| • Design Review | • 设计复审 | 10 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| • Design | • 具体设计 | 60 | 100 |
| • Coding | • 具体编码 | 400 | 550 |
| • Code Review | • 代码复审 | 10 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 200 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 10 | 10 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结,并提出过程改进计划 | 30 | 40 |
| 合计 | 630 | 1050 |
分工
使用工具:Java
傅海涛:爬虫,词频统计
黄家雄:词频统计
解题思路
爬虫
网站源码查看分析

爬虫实现分析
-
- 获取全部代码
- 获取Title和摘要url:筛选<dt> 标签,得到的内容contents清洗掉所有html标签,剩下的就是Title的内容,存到名为titles的List里.在把之前得到的content中筛选 <a> 标签的 href属性,存到名为urls的List里.
- 将得到的urls传到封装好的函数中进行爬虫.操做和上面差不多,筛选<div id="abstract">的内容,在清洗掉html的标签就可以获得所有的摘要.把内容存到 名为abstracts的List里.
- 将获得的titles和abstracts进行拼接并生成到result.txt中.

获取title和url
//获取title和url
public static void getTitle(String content){
Pattern r = Pattern.compile("<dt [^>]*?>[\\w\\W]*?<\\/dt>");
Matcher m = r.matcher(content);
while ( true ) {
if (m.find()) {
Pattern r2 = Pattern.compile("<a [^>]*?>[\\w\\W]*?<\\/a>");
Matcher m2 = r2.matcher(m.group(0));
//输出标题
if (m2.find()) {
String url = GetContent.match(m2.group(0), "a", "href");
// System.out.println(url);
urls.add(url);
//筛除html标签
String title = outHtml(m2.group(0));
titles.add(title);
// System.out.println(title);
}
} else {
break;
}
}
}获取html标签里面的某个属性值
//获取html标签里面的某个属性值
public static String match(String source, String element, String attr) {
String result = new String();
String reg = "<" + element + "[^<>]*?\\s" + attr + "=['\"]?(.*?)['\"].*?>";
Matcher m = Pattern.compile(reg).matcher(source);
while (m.find()) {
String r = m.group(1);
result = r;
}
return result;
}清除html标签
//筛除html标签
public static String outHtml(String cont){
String con =cont.replaceAll("</?[^>]+>", "");
return con;
}词频统计
分析
-
- 主要功能和之前的一次作业要求一样,在此基础上添加新的自定义命令,之前的统计只是把单词的数量累加,就好比权重为1,只需要把按照命令把title的累加*10.至于输出n个就只需在原来的基础上面封装个函数并把n传进.至于词组统计则需要将原来单词统计上修改判断单词数量并拼接输出.
- 关键代码分析
单词统计时候调用的内函数,把每一次的title和abstract一次作为str传入,依据weight计算权值,aNum是词组的个数,不是词组的话为0
public static int strCount(int wordNum,int weight,String str,int aNum){
String regex = "[^0-9A-Za-z]";
String[] contns = null;
//把内容已“|”分割
String contentString = str.toLowerCase().replaceAll(regex, "|");
contns = contentString.split("\\|");
int i = 0;
int[] wordnumS = new int[500];
int wnum = 0;
//单词切割后进行判断单词
for (; i < contns.length; i++) {
if (contns[i].length() >= 4) {
if (Character.isLetter(contns[i].charAt(0))) {
if (Character.isLetter(contns[i].charAt(1))) {
if (Character.isLetter(contns[i].charAt(2))) {
if (Character.isLetter(contns[i].charAt(3))) {
wordNum++;
if(aNum == 0){
ma = Maps(ma,contns[i],weight);
}else {
wordnumS[wnum] = i;
wnum++;
}
}
}
}
}
}
}
Boolean flag = false;
//如果是词组的话进行单词重组,匹配符合的词组在找到之前替换的字符
if(aNum > 0){
if(aNum <= wnum){
for(int j = 0;j < wnum + 1 - aNum;j++){
//0到1
flag = false;
String s = new String();
for (int k = j ; k < j + aNum; k++ ){
if(wordnumS[k] == wordnumS[j] + k - j){
// s += contns[wordnumS[j]];
s += contns[wordnumS[k]];
if(k != j + aNum -1) {
s += "[\\w\\W]";
}else {
flag = true;
}
}
}
if (flag) {
Pattern r = Pattern.compile(s);
Matcher m = r.matcher(str.toLowerCase());
if(m.find()) {
ma = Maps(ma , m.group() , weight);
}
}
}
}
}
return wordNum;
}附加题的设计和展示
设计的创意独到之处
对每篇论文的标题,摘要,链接,作者.对同一篇论文的作者进行关联,输出一个csv文件,用Gephi的可视化处理生成关系图谱.
实现思路
和获取标题摘要的实现原理类似,将网页源代码文本先筛选出内容所在的标签部分,对获取的清洗掉html标签.
实现成果展示
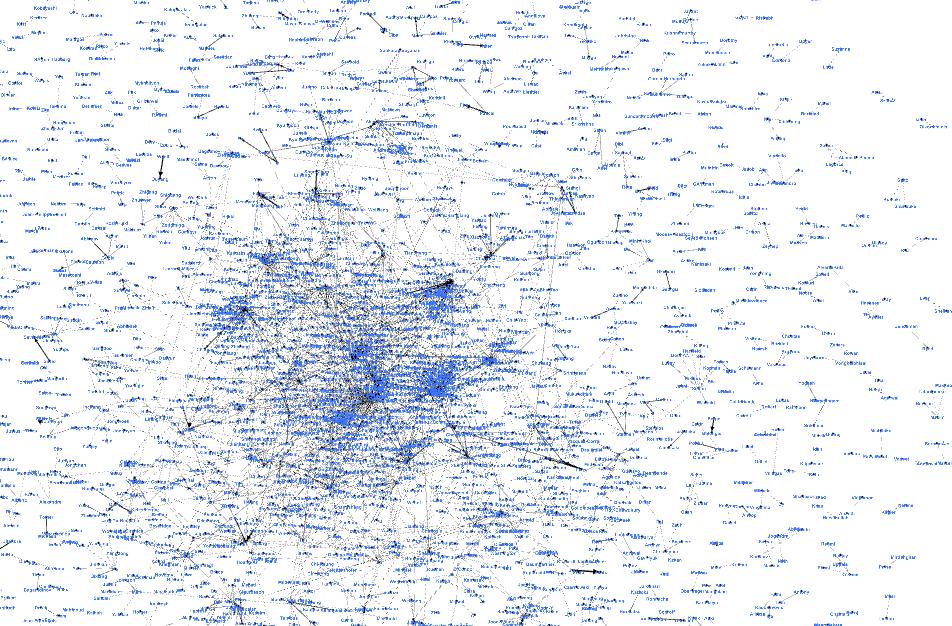

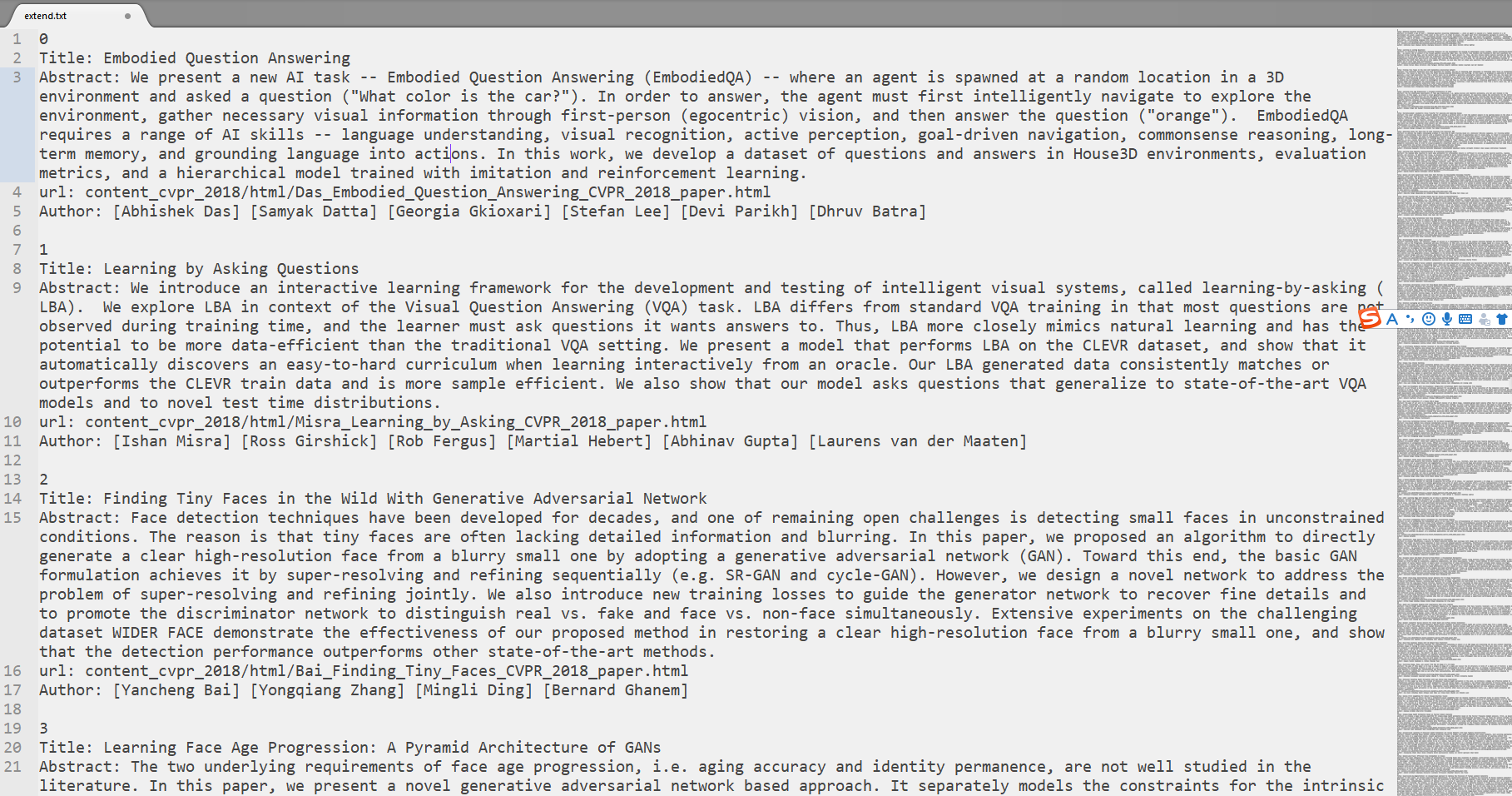
性能分析与改进
性能分析
爬虫部分,获取title和url由于在同一个页面比较好处理,而摘要处于子页面中,所以到对得到的url依次进行爬取对应的摘要内容,所花的时间大部分用于爬取论文摘要上面
词频分析部分,我主要对文档title和abstract获取其内容,依次将内容进行单词判断和第一次wordcount相比,直接对所有文档进行清洗筛选相比,所花时间大大增加.
改进
在单词判断上,和第一次相比改进比较大,将原先的比较固话的函数重新构造成由参数决定功能的函数,使代码的可用性更强
遇到的代码模块异常或结对困难及解决方法
在电脑上运行的时候不知道出现什么错误,程序不能运行,怀疑电脑配置问题
最后队友帮忙解决
有时候请教别人能学的很快
评价你的队友
技术高超、刻苦专研
希望还是要更多体验生活
学习进度条
| 第N周 | 新增代码行 | 累计代码行 | 本周学习(时) | 重要成长 |
|---|---|---|---|---|
| 4 | 150 | 150 | 9 | java爬虫 |
| 5 | 800 | 800 | 11 | 代码规范 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号