HDFS相关操作 &MapReduce
DHFS 常用命令
hadoop fs
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop/a.txt
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst # 与hadoop fs -put 功能类似
hadoop fs -moveFromLocal localsrc dst # 将本地文件上传到 hdfs,同时删除本地文件
hadoop dfsadmin
dfsadmin 客户端
# 报告文件系统的基本信息和统计信息
hadoop dfsadmin -report
hadoop dfsadmin -safemode enter | leave | get | wait
# 安全模式维护命令。安全模式是 Namenode 的一个状态,这种状态下,Namenode
# 1. 不接受对名字空间的更改(只读)
# 2. 不复制或删除块
# Namenode 会在启动时自动进入安全模式,当配置的块最小百分比数满足最小的副本数条件时,会自动离开安全模式。安全模式可以手动进入,但是这样的话也必须手动关闭安全模式。
hadoop fsck
HDFS 文件系统检查工具。
hadoop fsck [GENERIC_OPTIONS] <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
MapReduce介绍
【什么是Map/Reduce】
看看下面的各种解释:
(1)MapReduce是hadoop的核心组件之一,hadoop要实现分布式需要包括两部分,一部分是分布式文件系统hdfs,一部分是分布式计算框架mapreduce,缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程。
(2)Mapreduce是一种编程模型,是一种方法,抽象理论。
(3)下面是一个关于一个程序员是如何跟妻子讲解什么是MapReduce,文章很长请耐心的
————————————————
版权声明:本文为CSDN博主「奋斗的小炎」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Little_Fire/article/details/80605233
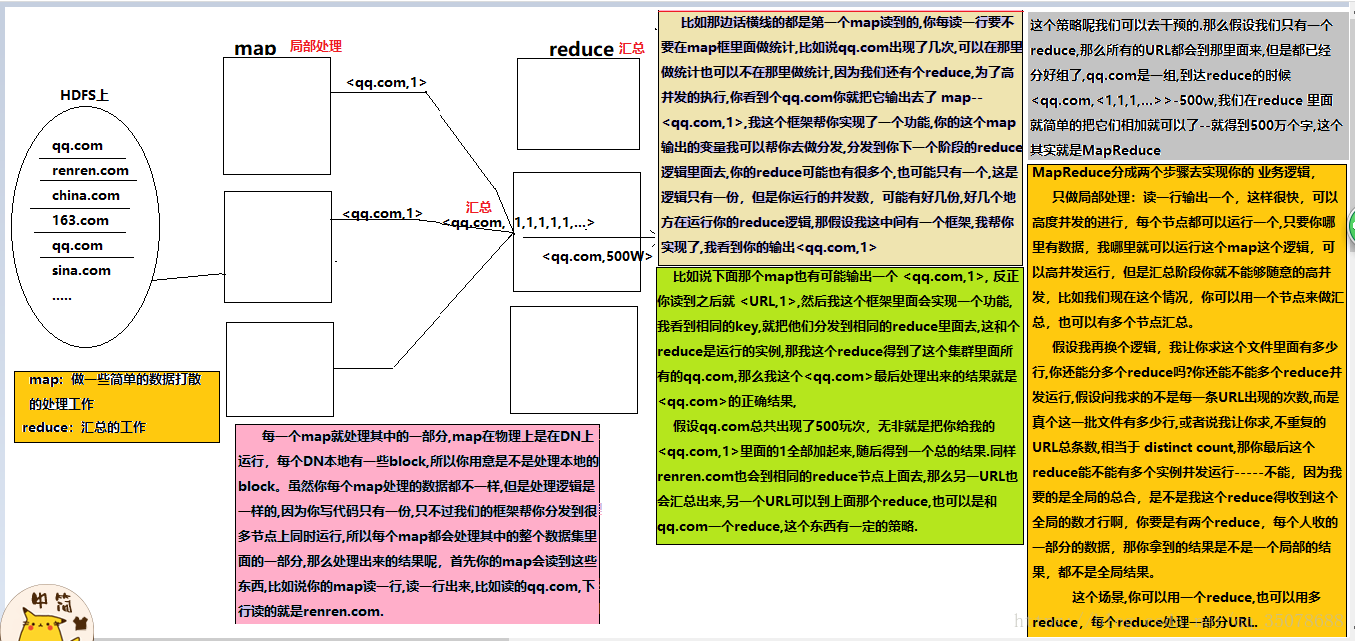
如果让你统计日志里面的出现的某个URL的总次数,让你自己去写个单机版的程序,写个逻辑:无非就是读这个文件一行,然后把那个地方截取出来,截取出来之后,然后可以把它放到一个HashMap里面,用Map去重,看到一条新的URL ,就把它put进去,然后+1,如果下次看到再有就直接+1,没有就put进去,单机版的话逻辑是很好实现,但是数据量一大,你觉得单机版本还能搞定吗?
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是 Google 公司,而 Google 的灵感则来自于函数式编程语言,如 LISP、Scheme、ML 等。
MapReduce 框架的核心步骤主要分两部分:Map 和 Reduce。当你向 MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个 Map 任务,然后分配到不同的节点上去执行,每一个 Map 任务处理输入数据中的一部分,当 Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为 Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个 Map 的输出汇总到一起并输出。
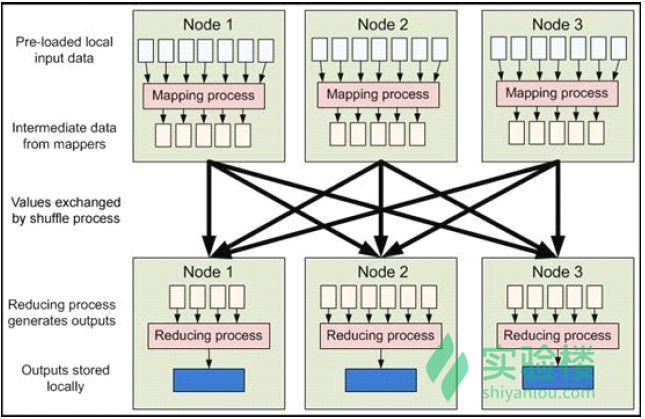
就说你的代码,你的任意一个逻辑实现都要分成这么两个步骤:
1)Map
2)Reduce
比如说我们统计日志文件里面,相同URL出现的总次数
如下图:
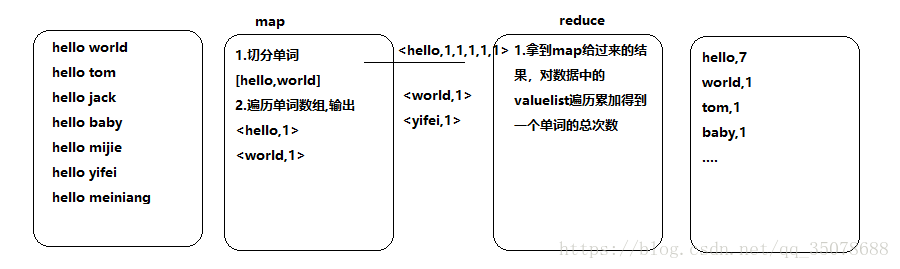
例子:
————————————————
版权声明:本文为CSDN博主「哪有天生的学霸,一切都是厚积薄发」
的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35078688/article/details/83240661
最通俗易懂 的mapreduce介绍

【MapReduce工作原理】
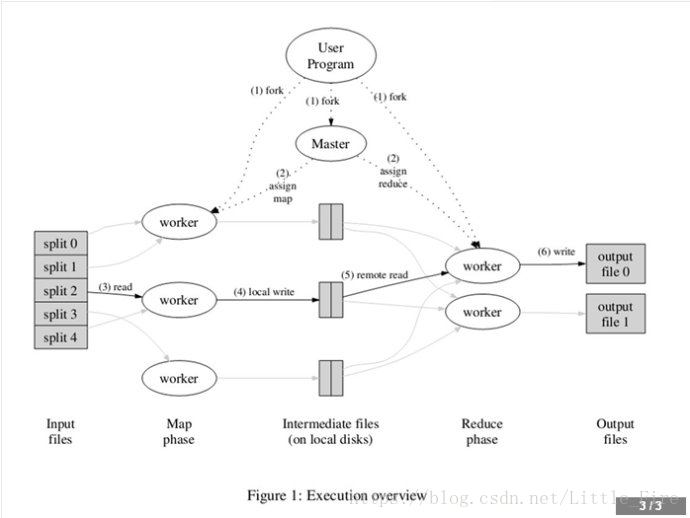
上图是论文里给出的MapReduce流程图。一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
(1)MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~split4;然后使用fork将用户进程拷贝到集群内其它机器上。
(2)user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
(3)被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中(环形缓冲区kvBuffer)。
(4)缓存的中间键值对会被定期写入本地磁盘(spill),而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
(5)master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业,所以排序是必须的。
(6)reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
(7)当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据来自底层分布式文件系统(hdfs),中间数据是放在本地文件系统的,最终输出数据是写入hdfs的。注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
————————————————
版权声明:本文为CSDN博主「奋斗的小炎」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Little_Fire/article/details/80605233
MAP reduce 工作机制:
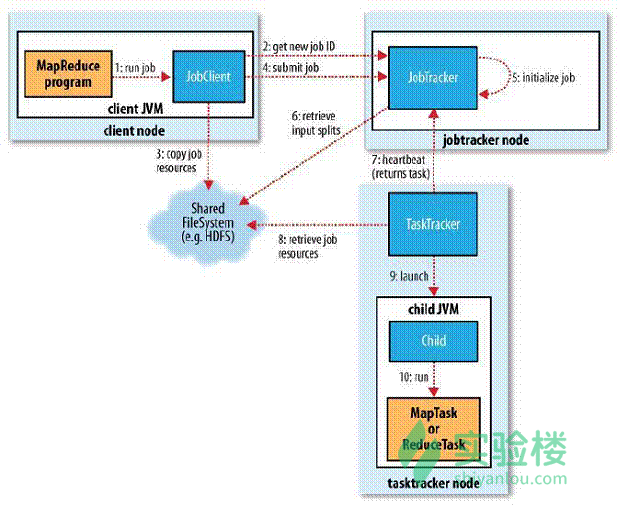
1.在集群中的任意一个节点提交 MapReduce 程序;
2.JobClient 收到作业后,JobClient 向 JobTracker 请求获取一个 Job ID;
3.将运行作业所需要的资源文件复制到 HDFS 上(包括 MapReduce 程序打包的 JAR 文件、配置文件和客户端计算所得的输入划分信息),这些文件都存放在 JobTracker 专门为该作业创建的文件夹中,文件夹名为该作业的 Job ID;
4.获得作业 ID 后,提交作业;
5.JobTracker 接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个 map 任务,并将 map 任务分配给 TaskTracker 执行;
6.对于 map 和 reduce 任务,TaskTracker 根据主机核的数量和内存的大小有固定数量的 map 槽和 reduce 槽。这里需要强调的是:map 任务不是随随便便地分配给某个 TaskTracker 的,这里有个概念叫:数据本地化(Data-Local)。意思是:将 map 任务分配给含有该 map 处理的数据块的 TaskTracker 上,同时将程序 JAR 包复制到该 TaskTracker 上来运行,这叫“运算移动,数据不移动”;
7.TaskTracker 每隔一段时间会给 JobTracker 发送一个心跳,告诉 JobTracker 它依然在运行,同时心跳中还携带着很多的信息,比如当前 map 任务完成的进度等信息。当 JobTracker 收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当 JobClient 查询状态时,它将得知任务已完成,便显示一条消息给用户;
8.运行的 TaskTracker 从 HDFS 中获取运行所需要的资源,这些资源包括 MapReduce 程序打包的 JAR 文件、配置文件和客户端计算所得的输入划分等信息;
9.TaskTracker 获取资源后启动新的 JVM 虚拟机;
10.运行每一个任务;
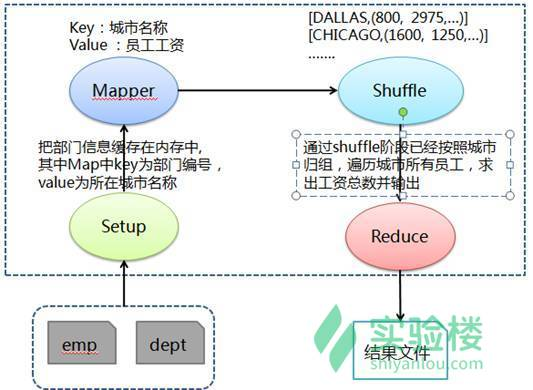
问题示例:通过该示例我们可以知道怎么来写mapreduce的代码
求各个城市员工的总工资,需要得到各个城市所有员工的工资,通过对各个城市所有员工工资求和得到总工资。首先和测试例子 1 类似在 Mapper 的 Setup 阶段缓存部门对应所在城市数据,然后在 Mapper 阶段抽取出 key 为城市名称(利用缓存数据把部门编号对应为所在城市名称),value 为员工工资,接着在 Shuffle 阶段把传过来的数据处理为城市名称对应该城市所有员工工资,最后在 Reduce 中按照城市归组,遍历城市所有员工,求出工资总数并输出。
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Q4SumCitySalary extends Configured implements Tool {
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {
// 用于缓存 dept文件中的数据
private Map<String, String> deptMap = new HashMap<String, String>();
private String[] kv;
// 此方法会在Map方法执行之前执行且执行一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader in = null;
try {
// 从当前作业中获取要缓存的文件
Path[] paths = DistributedCache.getLocalCacheFiles(context.getConfiguration());
String deptIdName = null;
for (Path path : paths) {
if (path.toString().contains("dept")) {
in = new BufferedReader(new FileReader(path.toString()));
while (null != (deptIdName = in.readLine())) {
// 对部门文件字段进行拆分并缓存到deptMap中
// 其中Map中key为部门编号,value为所在城市名称
deptMap.put(deptIdName.split(",")[0], deptIdName.split(",")[2]);
}
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 对员工文件字段进行拆分
kv = value.toString().split(",");
// map join: 在map阶段过滤掉不需要的数据,输出key为城市名称和value为员工工资
if (deptMap.containsKey(kv[7])) {
if (null != kv[5] && !"".equals(kv[5].toString())) {
context.write(new Text(deptMap.get(kv[7].trim())), new Text(kv[5].trim()));
}
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, LongWritable> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 对同一城市的员工工资进行求和
long sumSalary = 0;
for (Text val : values) {
sumSalary += Long.parseLong(val.toString());
}
// 输出key为城市名称和value为该城市工资总和
context.write(key, new LongWritable(sumSalary));
}
}
@Override
public int run(String[] args) throws Exception {
// 实例化作业对象,设置作业名称
Job job = new Job(getConf(), "Q4SumCitySalary");
job.setJobName("Q4SumCitySalary");
// 设置Mapper和Reduce类
job.setJarByClass(Q4SumCitySalary.class);
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
// 设置输入格式类
job.setInputFormatClass(TextInputFormat.class);
// 设置输出格式类
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 第1个参数为缓存的部门数据路径、第2个参数为员工数据路径和第3个参数为输出路径
String[] otherArgs = new GenericOptionsParser(job.getConfiguration(), args).getRemainingArgs();
DistributedCache.addCacheFile(new Path(otherArgs[0]).toUri(), job.getConfiguration());
FileInputFormat.addInputPath(job, new Path(otherArgs[1]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
job.waitForCompletion(true);
return job.isSuccessful() ? 0 : 1;
}
/**
* 主方法,执行入口
* @param args 输入参数
*/
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new Q4SumCitySalary(), args);
System.exit(res);
}
}
本文章是个人学习记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号