
集群方式有三种:Replica Set、Sharding、Master-Slaver三种方式
常用的主要是副本集和主从模式,主从模式比较好理解,即一个master和一个slave节点,master节点负责读写,slave在master宕机的时候可以提供读服务,当然也可以通过配置参数实现在访问量高的时候让slave节点也提供读服务;
而副本集模式比较特殊,但这种模式也是比较稳定,可靠,同时在一定的情况下能够实现自动容错的机制,它主要包括如下几部分,Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
下面我们在三台虚拟机上模式搭建一下mongodb的这种副本集模式的集群:
1、环境准备,提前安装好docker和docker-compose
192.168.81.131(主)、192.168.81.132(备)、192.168.81.131(仲裁)
2、pull下mongo镜像
docker pull mongo
3、编辑mongod.conf配置文件(三个节点配置相同)
dbpath=/data/db logappend=true journal=true port=27017 replSet=test
4、编辑docker-compose.yaml文件(其中第三步的mongd.conf是存放在./configdb目录下的,配置文件内容还可完善)
version: "3" services: mongo: image: mongo container_name: mongo ports: - "27017:27017" volumes: - "./db:/data/db" - "./configdb:/data/configdb" environment: - TZ=Asia/Shanghai command: --bind_ip_all --config /data/configdb/mongod.conf restart: always logging: driver: "json-file" options: max-size: "10m" max-file: "3" networks: - mynet networks: mynet: external: true
5、docker-compose启动三台主机的容器
docker-compose up -d
6、配置集群信息
进入容器,执行mongo命令以进入mongo的shell模式,然后执行:
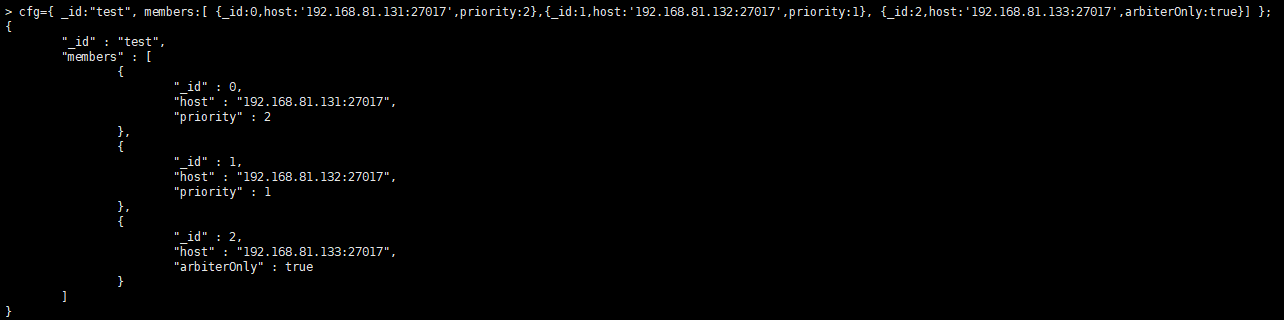
cfg={ _id:"test", members:[ {_id:0,host:'192.168.81.131:27017',priority:2},{_id:1,host:'192.168.81.132:27017',priority:1}, {_id:2,host:'192.168.81.133:27017',arbiterOnly:true}] };
其中priority为权重,数字越大,权重越大,最大者为主节点
然后加载配置:
rs.initiate(cfg);

然后执行rs.status()命令即可查看当前状态了
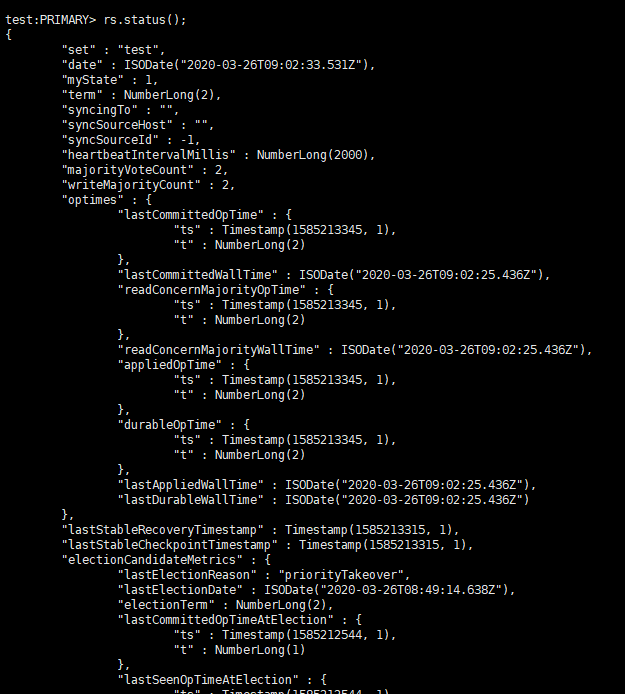
当前复制集配置完成了
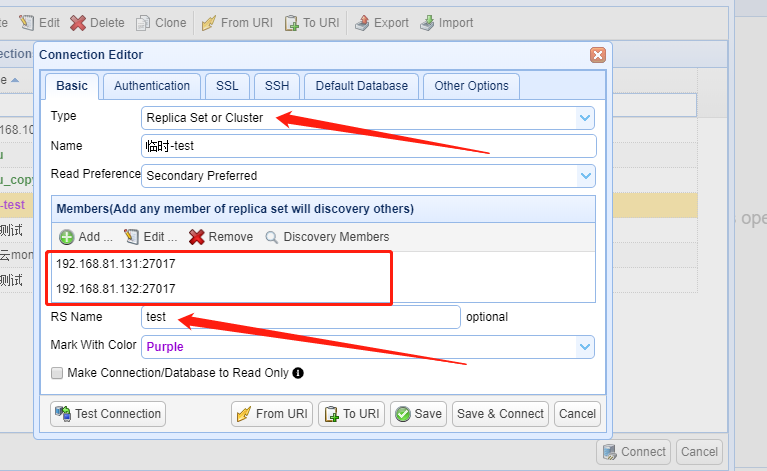
7、关于mongo客户端连接:
本人采用NoSQLBooster for MongoDB客户端来连接Mongo,在创建连接的时候,需要注意下面的需要写对
8、关于如何配置读写分离的配置:
但在官方文档中:http://docs.mongoing.com/manual-zh/core/read-preference.html,指出一般设置不要使用secondary和secondaryPreferred,因为此时读到的数据可能存在不一致。
db.collection.insert({x: 1}, {writeConcern: {w: 1}})
MongoDB支持的WriteConncern选项如下
-
w: <number>,数据写入到number个节点才向用客户端确认
- {w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景
- {w: 1} 默认的writeConcern,数据写入到Primary就向客户端发送确认
- {w: "majority"} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能
-
j: <boolean> ,写入操作的journal持久化后才向客户端确认
- 默认为"{j: false},如果要求Primary写入持久化了才向客户端确认,则指定该选项为true
-
wtimeout: <millseconds>,写入超时时间,仅w的值大于1时有效。
- 当指定{w: }时,数据需要成功写入number个节点才算成功,如果写入过程中有节点故障,可能导致这个条件一直不能满足,从而一直不能向客户端发送确认结果,针对这种情况,客户端可设置wtimeout选项来指定超时时间,当写入过程持续超过该时间仍未结束,则认为写入失败。
{w:"majority"}解析
{w: 1}、{j: true}等writeConcern选项很好理解,Primary等待条件满足发送确认;但{w: "majority"}则相对复杂些,需要确认数据成功写入到大多数节点才算成功,而MongoDB的复制是通过Secondary不断拉取oplog并重放来实现的,并不是Primary主动将写入同步给Secondary,那么Primary是如何确认数据已成功写入到大多数节点的?
- Client向Primary发起请求,指定writeConcern为{w: "majority"},Primary收到请求,本地写入并记录写请求到oplog,然后等待大多数节点都同步了这条/批oplog(Secondary应用完oplog会向主报告最新进度)。
- Secondary拉取到Primary上新写入的oplog,本地重放并记录oplog。为了让Secondary能在第一时间内拉取到主上的oplog,find命令支持一个awaitData的选项,当find没有任何符合条件的文档时,并不立即返回,而是等待最多maxTimeMS(默认为2s)时间看是否有新的符合条件的数据,如果有就返回;所以当新写入oplog时,备立马能获取到新的oplog。
- Secondary上有单独的线程,当oplog的最新时间戳发生更新时,就会向Primary发送replSetUpdatePosition命令更新自己的oplog时间戳。
- 当Primary发现有足够多的节点oplog时间戳已经满足条件了,向客户端发送确认。
local能读取任意数据,这个是默认设置majority只能读取到『成功写入到大多数节点的数据』
readConcern 的初衷在于解决『脏读』的问题,比如用户从 MongoDB 的 primary 上读取了某一条数据,但这条数据并没有同步到大多数节点,然后 primary 就故障了,重新恢复后 这个primary 节点会将未同步到大多数节点的数据回滚掉,导致用户读到了『脏数据』。
当指定 readConcern 级别为 majority 时,能保证用户读到的数据『已经写入到大多数节点』,而这样的数据肯定不会发生回滚,避免了脏读的问题。需要注意的是,readConcern 能保证读到的数据『不会发生回滚』,但并不能保证读到的数据是最新的,这个官网上也有说明。
有用户误以为,readConcern 指定为 majority 时,客户端会从大多数的节点读取数据,然后返回最新的数据。实际上并不是这样,无论何种级别的 readConcern,客户端都只会从『某一个确定的节点』(具体是哪个节点由 readPreference 决定)读取数据,该节点根据自己看到的同步状态视图,只会返回已经同步到大多数节点的数据。
MongoDB 要支持 majority 的 readConcern 级别,必须设置replication.enableMajorityReadConcern参数,加上这个参数后,MongoDB 会起一个单独的snapshot 线程,会周期性的对当前的数据集进行 snapshot,并记录 snapshot 时最新 oplog的时间戳,得到一个映射表。
| 最新 oplog 时间戳 | snapshot | 状态 |
|---|---|---|
| t0 | snapshot0 | committed |
| t1 | snapshot1 | uncommitted |
| t2 | snapshot2 | uncommitted |
| t3 | snapshot3 | uncommitted |
只有确保 oplog 已经同步到大多数节点时,对应的 snapshot 才会标记为 commmited,用户读取时,从最新的 commited 状态的 snapshot 读取数据,就能保证读到的数据一定已经同步到的大多数节点。
关键的问题就是如何确定『oplog 已经同步到大多数节点』?
primary 节点
secondary 节点在 自身oplog发生变化时,会通过 replSetUpdatePosition 命令来将 oplog 进度立即通知给 primary,另外心跳的消息里也会包含最新 oplog 的信息;通过上述方式,primary 节点能很快知道 oplog 同步情况,知道『最新一条已经同步到大多数节点的 oplog』,并更新 snapshot 的状态。比如当t2已经写入到大多数据节点时,snapshot1、snapshot2都可以更新为 commited 状态。(不必要的 snapshot也会定期被清理掉)
secondary 节点
secondary 节点拉取 oplog 时,primary 节点会将『最新一条已经同步到大多数节点的 oplog』的信息返回给 secondary 节点,secondary 节点通过这个oplog时间戳来更新自身的 snapshot 状态。
注意事项
- 目前
readConcern主要用于跟 mongos 与 config server 的交互上,参考MongoDB Sharded Cluster 路由策略 - 使用
readConcern需要配置replication.enableMajorityReadConcern选项 - 只有支持 readCommited 隔离级别的存储引擎才能支持
readConcern,比如 wiredtiger 引擎,而 mmapv1引擎则不能支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号