软件工程结对编程作业
软件工程结对编程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2019春季计算机学院软件工程(罗杰)(北京航空航天大学) |
| 这个作业的要求在哪里 | 结对项目-最长单词链 |
| 我在这个课程的目标是 | 学习软件工程方法与相关工具,提升自己的工程能力,锻炼自己与他人协同开发以及开发较大项目的能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 学习并尝试实践了结对编程,锻炼了代码尤其测试方面的基础 |
Github地址: LongestWordChain
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate · | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 400 |
| · Design Spec | · 生成设计文档 | 60 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 120 | 90 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| · Design | · 具体设计 | 180 | 180 |
| · Coding | · 具体编码 | 600 | 720 |
| · Code Review | · 代码复审 | 250 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 300 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 200 | 150 |
| · Size Measurement | · 计算工作量 | 60 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 2045 | 2250 |
2. 关于Information Hiding, Interface Design和Loose Coulpling
- Information Hiding
信息隐藏我认为即是封装的概念,在我们实现过程中,我们将界面模块(Base)和计算模块(Core)中的操作均封装为接口,并且Core中的core和graph两个类也分别进行封装,从而外部仅能调用Core模块的接口,而Base暴露的也仅仅是开始运行的方法。
- Interface Design
接口设计我们严格参照了作业的要求,即Core模块只暴露两个函数int gen_chain_word(char* words[], int len, char* result[], char head, char tail, bool enable_loop)和int gen_chain_char(char* words[], int len, char* result[], char head, char tail, bool enable_loop)。其中需要注意的是两者的返回值均是单词链的单词个数(作业中的“单词链长度”)。
- Loose Coulpling
我们从开始编程时便有意地为松耦合做准备,具体操作便是开始时将Base和Core分开,并且Base也仅仅调用以上约定的两个函数。在将Core封装为dll后Base的代码几乎可以直接应用,并且最终仅需要更换Core.dll文件便可切换计算模块。
3. 计算模块Core的详细设计
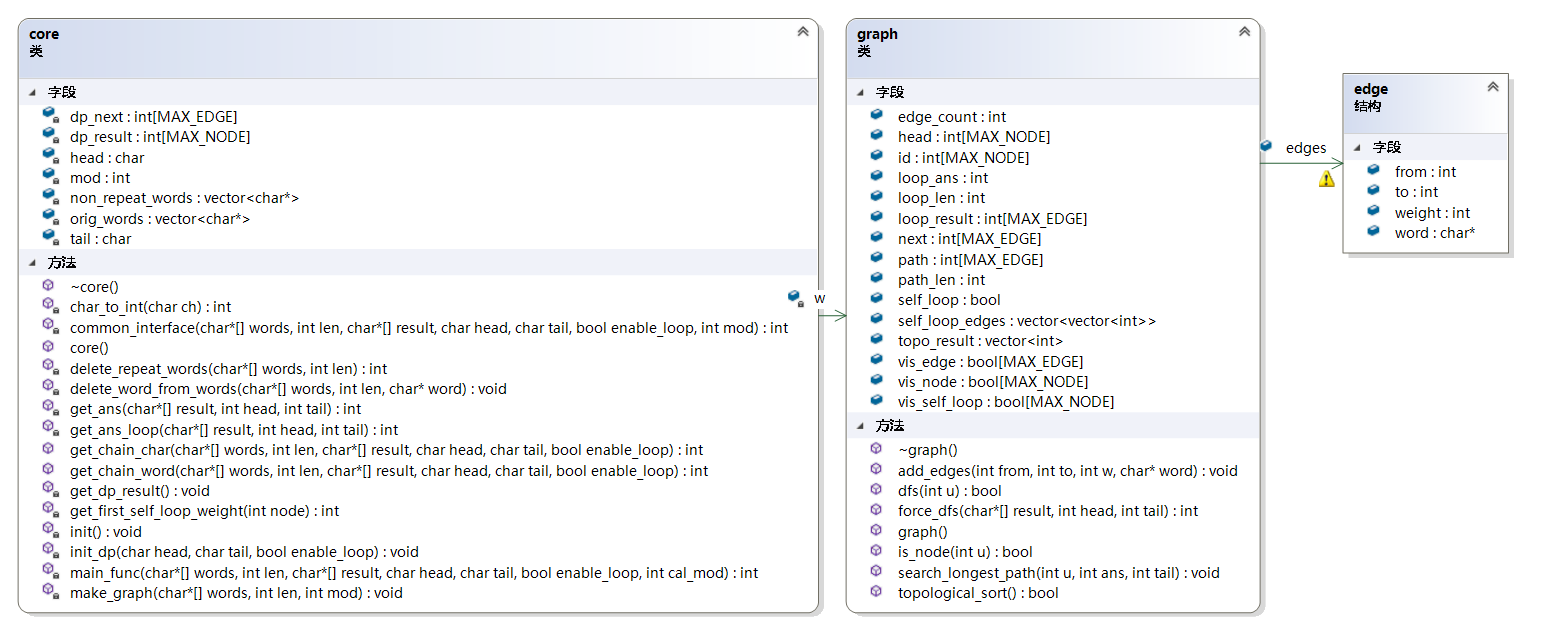
计算模块主要由两个类实现,分别是core和graph。其中core主要负责参数的读入以及动态规划算法的实现,而graph主要负责图的建立以及图论方面算法的实现,例如拓扑排序和DFS主要在graph中完成。
core类中,由于暴露在外的两个接口gen_chain_word和gen_chain_char仅仅是在初始化图的时候有所不同(word函数将图的边权值全部初始化为1,而char函数按单词长度初始化权值),因此最终我们选择使用一个公共的函数作为内部的实现,通过一个参数区分调用的是哪一个接口。
算法流程图:
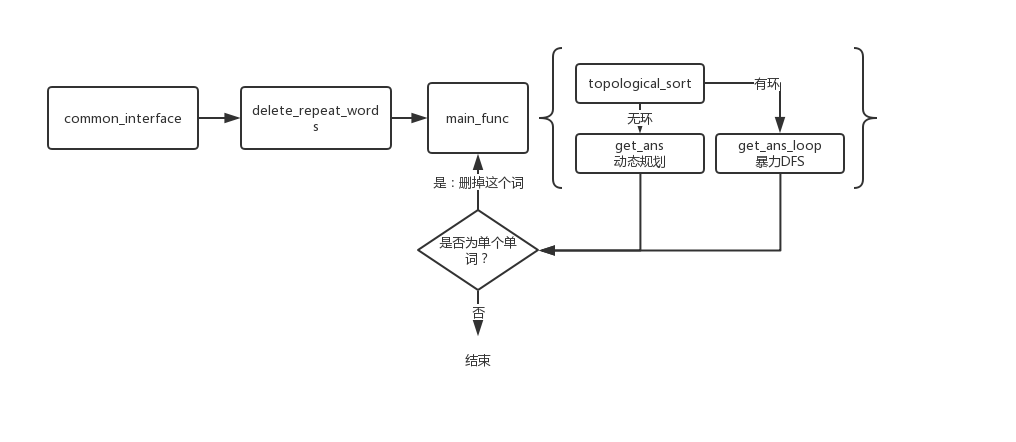
具体实现中,首先在单词进入Core前就要对words数组进行检查,若其中包含非法字符则报错,否则将所有字母转为小写再进入具体算法。之后进入delete_repeat_words将重复的单词删掉,因为单词链中不允许出现重复单词。
接下来进入main_func,这里需要按照单词列表和输入的模式建立图,并初始化好各个数据结构。之后对图进行拓扑排序,若有环且没有指定-r则报错,否则按照图中所示分别选择两中不同的算法进行计算。
在计算结束后需要检查答案是否是一个词,因为动态规划仅能找到最长的边链条,但并不能排除存在单个词非常长的情况,因此如果答案符合这种形式仍需要删掉这个词并重新计算。
算法的独到之处:
- 使用邻接表存储图结构,但并没有使用指针,从实现过程上讲不容易出现指针的问题
- 使用动态规划完成了拓扑排序和无环情况下的链查找,并且利用动态规划的初始化解决了开头和结尾字母的问题,从而实现上更为简洁
- 有环算法中使用数组模拟堆栈,减少单位访存的时间
4. UML图
5. 计算接口的性能改进
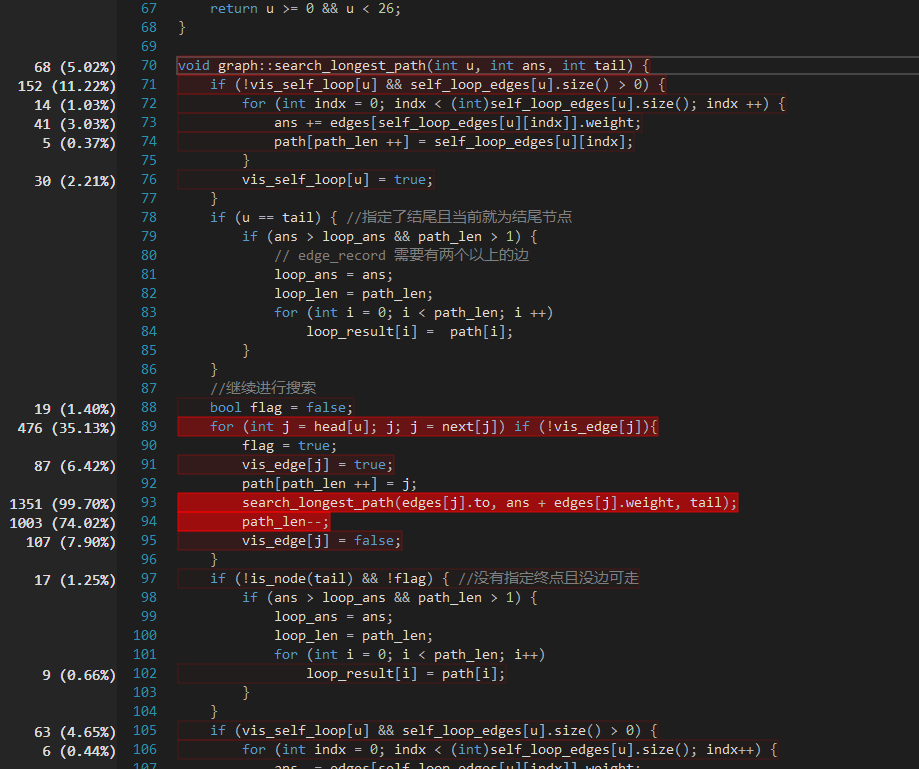
这一部分中我们花费了约3-4小时。我们主要针对有环情况的算法进行改进。由于在一个有向有环图中寻找最长的路径是一个NP问题,从算法本身的角度来看无论如何都逃不开NP这个坑,因此我们使用了普通的DFS来进行。我们优化的地方在于将算法中访存的消耗尽可能降低。起初我们使用了vector作为路径存储的数据结构,在经过一次性能分析后我们发现递归部分中退栈操作很多,因此我们将vector改为一维数组,将原先的pop_back变成栈顶指针的--操作,从而降低了时间消耗。
下图为有环情况下消耗CPU最多的函数,即DFS的主函数
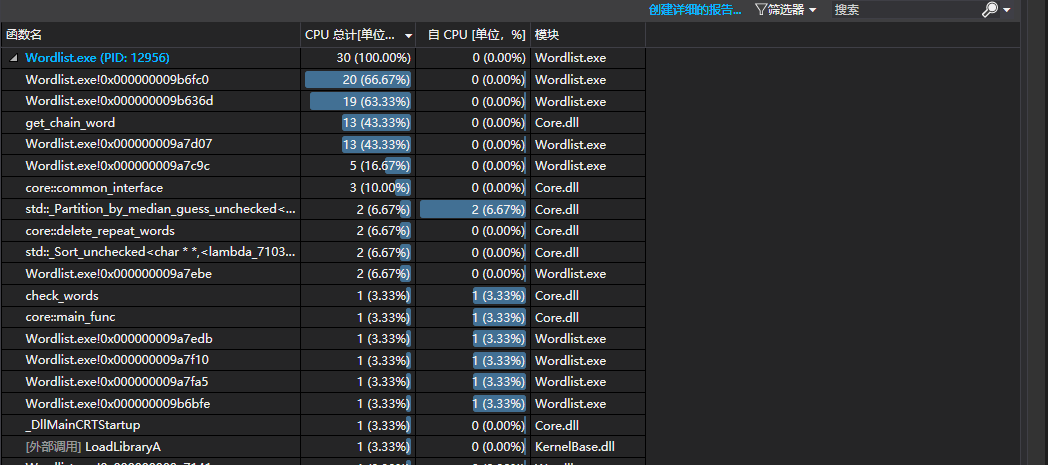
我们使用一个9000余词的文件对于无环情况进行了测试,结果发现算法在无环情况下表现良好,gen_chain_word/char中消耗最多的部分实际上是接口中进行malloc的部分。
6. Design by Contract, Code Contract
契约式设计的主要思路是设计接口时提供接口的先验条件、后验条件和不变式,这让我想起了OO课上学习的JSF。
契约式设计的优点有:
- 为编程者提供的良好的思路,并且能在编程的过程中尽早发现可能出现的问题
- 契约式设计有助于后续的测试,使一些不必要的Bug不会出现在测试中
- 契约式设计能够契合文档,使得新的开发者在阅读文档时对代码有更加深入的理解
契约式设计的缺点是上手较难,一开始不容易严格按照要求实现,并且部分逻辑较为复杂的函数使用契约时也比较麻烦。
在我们实现的过程中,我们对函数运行前后的状态事先进行了约定,从而能顺利地将不同的函数串接起来形成完整的程序。但我们并没有在实际实现中添加断言等来进行严格的约束。
7. 计算模块的单元测试
单元测试范例
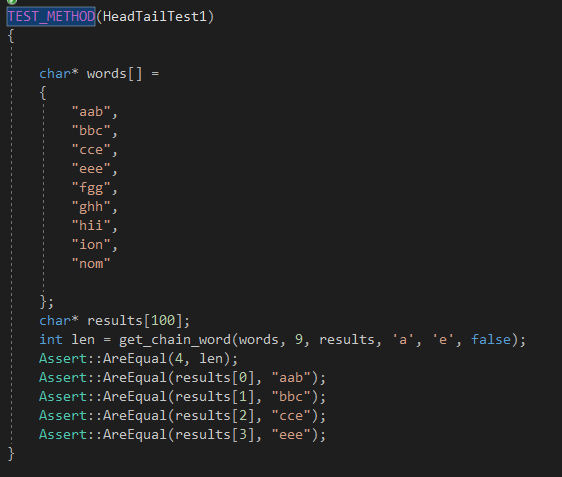
单元测试部分我们分别对无环和有环以及各种异常情况进行了测试,共构造了19个单元测试。
构造测试的思路大体上是尽可能覆盖各个分支。由于char和word两个接口在具体运行时仅仅是初始化权值不同,因此测试中我们更注重于各种特殊情况的测试,如开头和结尾的自环等。
单元测试的分支覆盖率为97%,其中包含了各种异常测试的覆盖。
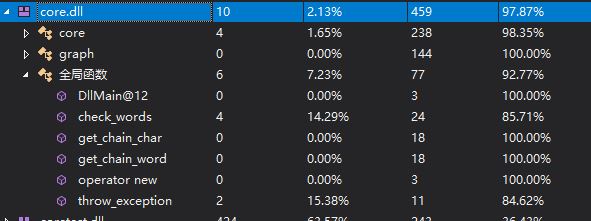
8. 计算模块异常处理设计
计算模块由于仅仅将两个函数接口暴露给用户,从而用户在调用函数时可以存在各种不合法的输入。主要的不合法输入包括以下几点
- words数组不合法,其中的单词存在不合法字符(非字母字符)
- head和tail不合法,输入为非字母字符
- len不合法,输入的len过小或过大(我们规定了输入单词个数在10000个)
- 输入单词存在环,却没有指定-r参数
针对以上的错误我们分别构造了如下测试
void invalid_char_test() //不合法字符
{
char* words[] =
{
"a12345",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, true);
}
void empty_string() //空串
{
char* words[] =
{
"",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, false);
}
void not_enough_words() //单词不够(一个词不成链)
{
char* words[] =
{
"a"
};
char* results[100];
int len = gen_chain_word(words, 1, results, 0, 0, true);
}
void has_loop() //(存在环)
{
char* words[] =
{
"aba",
"aca",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, false);
}
void invalid_head() /(非法头部)
{
char* words[] =
{
"aba",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 1, 0, false);
}
void invalid_tail() //(非法尾部)
{
char* words[] =
{
"aa",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 1, false);
}
}
并且使用诸如以下格式的接口进行单元测试
TEST_METHOD(WordsException9)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::invalid_head(); });
try
{
exception_test::invalid_head();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: invalid head or tail", e.what());
}
}
(在参阅了一些同学的博客后我感觉这种单元测试的写法有点别扭,实际上仅仅是为了调用ExceptException接口而搞得如此复杂……)
9. 界面模块(命令行)的设计与实现
界面主要分为两大部分:命令行参数读取解析及文件读取。
在命令行参数解析部分,由于目前已有很多的开源库可供使用,本着不重复造轮子的原则我们使用了一个较为轻量的头文件库cxxopts来处理命令行参数。
Github地址:https://github.com/jarro2783/cxxopts/
简单的使用介绍:
引入头文件库:
#include <cxxopts.hpp>
创建一个cxxopts的Option实例,输入参数是程序名和程序的描述
cxxopts::Options options("MyProgram", "One line description of MyProgram");
使用add_options方法添加参数,其中括号内第一个参数为短参数和长参数名,第二个参数是描述,可选的第三个参数是选项后输入的实参。
options.add_options()
("d,debug", "Enable debugging")
("f,file", "File name", cxxopts::valuestd::string())
;
使用parse方法对输入的参数进行分析,其中这里输入的两个参数为main函数读取的argc和argv。
auto result = options.parse(argc, argv);
使用 result.count("option") 获取名为“option”的参数出现的次数,并使用:
result["option"].as
来获取其值。注意到如果option不存在会抛出异常。
(以上内容摘自项目Github主页)
这个库可以自动将各个参数的值读出并对不合法的情况抛出异常。但由于其涉及的不合法情况较为朴素,我对一些相对复杂的不合法输入进行了处理,例如同时输入-w和-c、或输入了两个-w的情况。
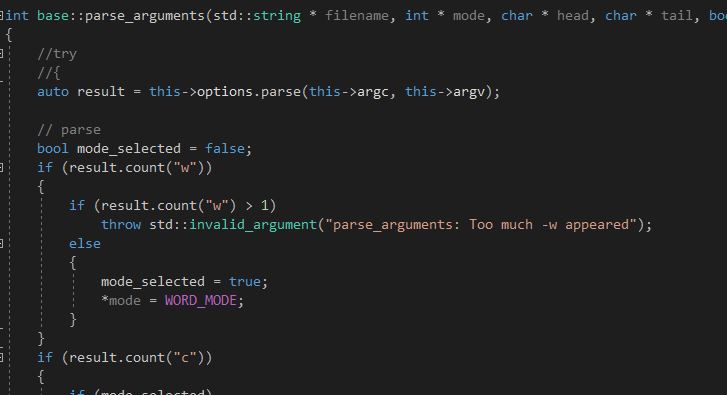
最终我将命令行参数读取和分析封装在base类的parse_arguments函数中,函数通过参数将读取到的值返回。
在文件读取部分,我设计的思路是按字符从文件头开始向后扫描,并在出现特殊字符的位置断开,从而将文件中的合法单词分隔出来。
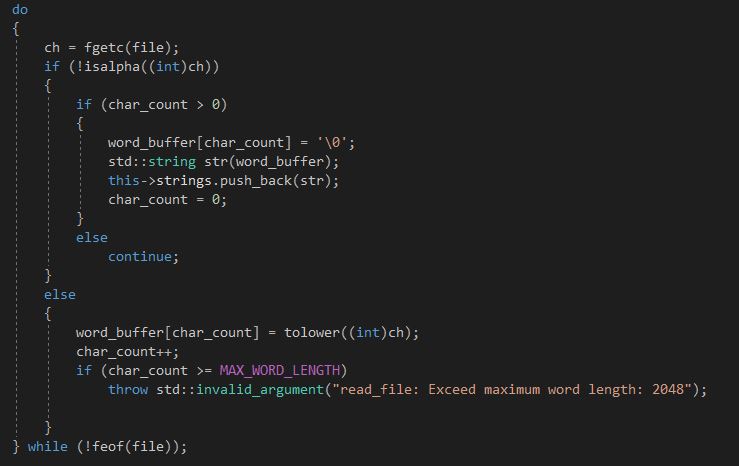
注意到在读文件过程中我对单词的长度也做了约束,如读到长度过长的单词则会抛出异常。最终将以上单词保存在base类成员中的数组内即可。
界面模块的单元测试
界面模块我也写了一些单元测试,主要测试以上的两个函数。其中大部分测试均针对命令行参数的解析。例如:
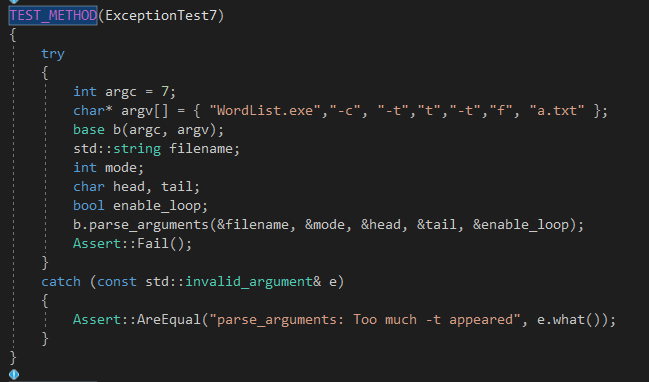
10. 界面模块与计算模块的对接
dll模块对接方面我使用了Base模块显式调用Dll的方法(即仅借助dll文件,不借助lib文件)。通过windows.h中的LoadLibrary和GetProcAddress实现。最终将调用的过程与开头读文件、解析参数等过程结合,形成完整的运行程序。
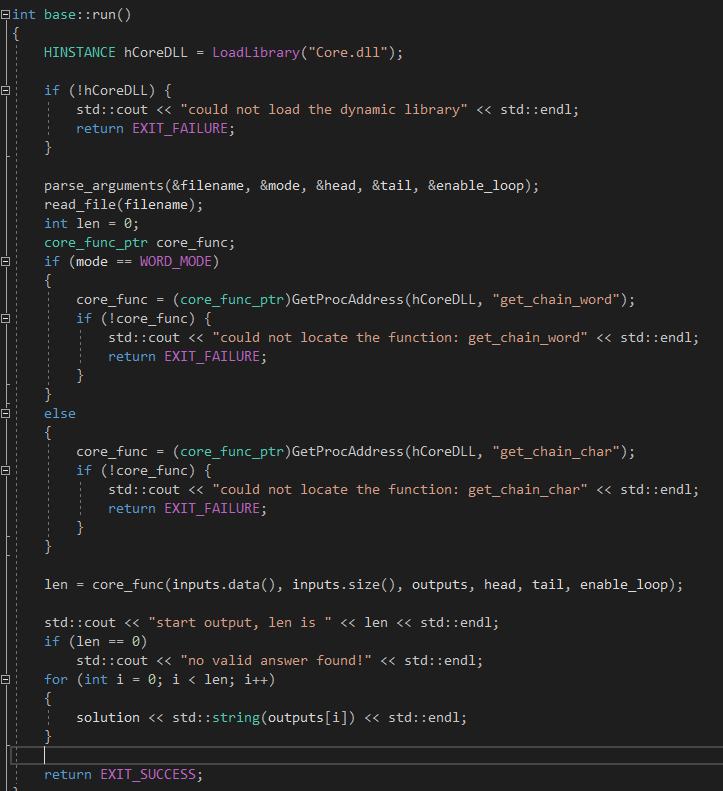
最终只要将Core.dll文件放置在可执行文件同一目录下,便可以运行程序计算结果。
松耦合测试及遇到的问题
我们与16101061、16061118组互换了Core.dll进行测试。
我们的dll文件可以在对方的界面模块下运行
但对方的Core模块并不能被我们的base模块调用。询问得知对方的Core以C#实现,当我使用dumpbin查看其中导出的函数时并不能查看到任何信息。
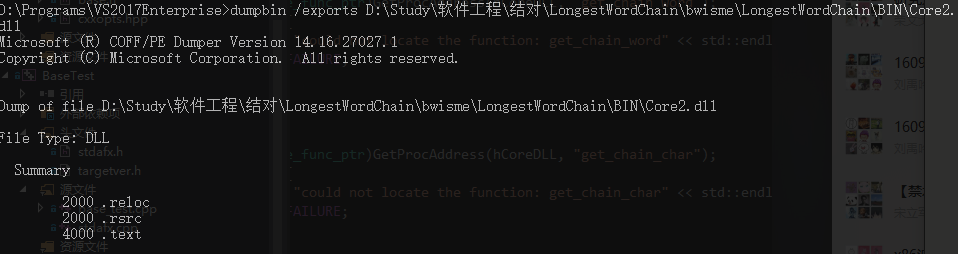
在上网查阅了一些资料后我了解到C++调用C#需要将dll转换为C#的类组件,貌似并没有类似于c++这样直接调用的方法。
11. 结对过程
我和我的结对队友由于宿舍距离很远,每次去咖啡厅又很贵,最终选择了使用Teamviewer+视频的方式进行结对合作。好在使用Teamviewer时网络很流畅,并且对方也可以在我的电脑上操作,甚至比两个人在线下结对还要方便一些。这也让我对结对编程有了更深的认识,结对不一定必须两个人坐在一起才能完成,只要沟通渠道方便、代码都可以看到,就能方便地进行结对编程。当然由于我们开始的晚了一些,中间某些时候也不得不采用了并行的方式。

12. 结对编程的优缺点
结对编程相比于个人开发和双人并行开发而言,好处是实时的复审可以避免很多小的问题。我在和队友结对编程的过程中,发生的一些笔误或者算法方面的疏忽都可以被及时地发现并改正。并且结对编程在讨论中进行,对于编程过程中模块间的约束也更加清晰。结对编程的缺点是假如两个人时间经常错开(假如有12小时时差),或两人的时间安排有差,则很难进行。
| 成员 | 优点 | 缺点 |
|---|---|---|
| 周博闻 | 1.能够较快解决各种工程方面的问题 2.能够想到一些易被忽略的点 3. 快速上手新知识并加以应用 | 有些地方不够细致,导致浪费很多时间找小bug |
| 庹东成 | 1.算法能力很强 2.思路清晰,遇到新的问题能找出很多办法 3.结对中效率高,对队友很友善 | 命名及代码格式有些不太规范 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号