selenium爬取煎蛋网
selenium爬取煎蛋网
直接上代码
from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as ES import requests import urllib.request import os from lxml import etree t = 0 class Custer(object): driver_path = r"D:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe" def __init__(self): self.driver = webdriver.Chrome(executable_path=self.driver_path) self.url = "http://jandan.net/ooxx" def run(self): self.driver.get(self.url) while True: all_source = self.driver.page_source html = etree.HTML(all_source) self.xqy(html) WebDriverWait(self.driver,10).until( ES.presence_of_element_located((By.XPATH,"//div[@class='cp-pagenavi']/a[last()]")) ) try: Btn = self.driver.find_element_by_xpath("//div[@class='cp-pagenavi']/a[last()]") if "Older Comments" in Btn.get_attribute("title"): Btn.click() else: break except: print("出现异常") def xqy(self,html): all_content = html.xpath("//div[@class='row']//div") all_author = all_content[0].xpath("//div[@class='author']/strong/text()") #作者列表 #*****************给自己的重点********************** #给列表重复元素加工 如果不加工进入字典会少很多元素 for index,item in enumerate(all_author): global t if item in all_author[0:index]: #判断当前元素是否与之前元素重复 如果重复,则重命名 t=t+1 all_author[index] = item+str(t) #如多个重命名使作者加上字符1 依次类推 #*************************************************** WebDriverWait(self.driver, 10).until( ES.presence_of_element_located((By.XPATH, "//div[@class='text']//img")) ) all_img = all_content[1].xpath("//div[@class='text']//img//@src") #图片列表 #解决有个张图片没有http:协议 for index,item in enumerate(all_img): if 'http:' not in item: all_img[index] = 'http:'+item dic = dict(zip(all_author,all_img)) #多个列表生产字典 #遍历字典保存图片 for key in dic: hz = os.path.splitext(dic[key])[1] #取出后缀名.jpg/.png filename = key+hz #文件名(标题+后缀名) urllib.request.urlretrieve(dic[key],'images/'+filename) def main(): rea = Custer() rea.run() if __name__ == '__main__': main()
爬取的图片
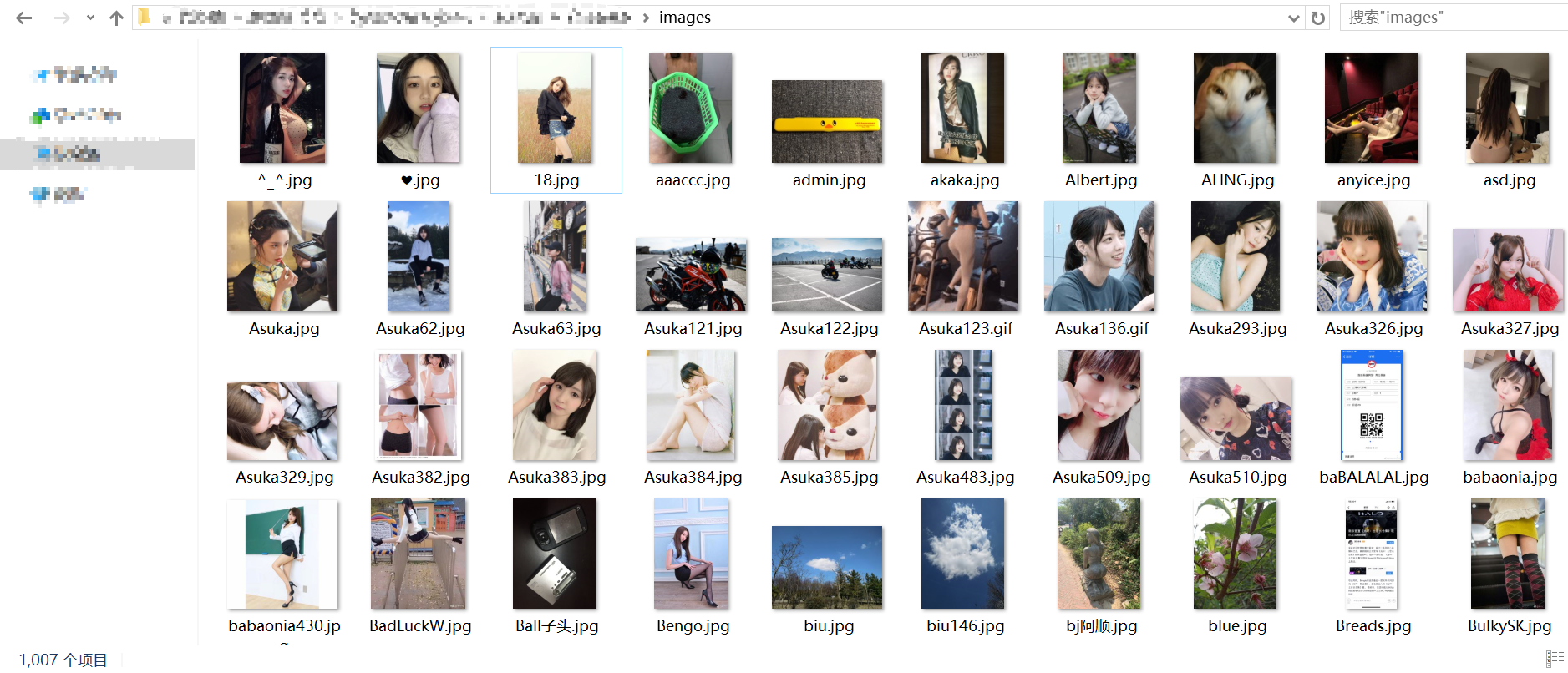
进阶
个人用了个多线程 但不知道是不是多线程爬取 感觉爬取速度快多了
from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as ES import requests import threading import urllib.request import os from lxml import etree t = 0 gCondition = threading.Condition() class Custer(threading.Thread): driver_path = r"D:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) url = "http://jandan.net/ooxx" def run(self): self.driver.get(self.url) while True: all_source = self.driver.page_source html = etree.HTML(all_source) self.xqy(html) WebDriverWait(self.driver,10).until( ES.presence_of_element_located((By.XPATH,"//div[@class='cp-pagenavi']/a[last()]")) ) gCondition.acquire() #加上锁(如果不加锁那么多个线程可能同时请求一个或多个图片) try: Btn = self.driver.find_element_by_xpath("//div[@class='cp-pagenavi']/a[last()]") if "Older Comments" in Btn.get_attribute("title"): gCondition.release() #解锁 Btn.click() else: break except: print("出现异常") def xqy(self,html): all_content = html.xpath("//div[@class='row']//div") all_author = all_content[0].xpath("//div[@class='author']/strong/text()") #作者列表 #*****************给自己的重点********************** #给列表重复元素加工 如果不加工进入字典会少很多元素 for index,item in enumerate(all_author): global t if item in all_author[0:index]: #判断当前元素是否与之前元素重复 如果重复,则重命名 t=t+1 all_author[index] = item+str(t) #如多个重命名使作者加上字符 依次类推 #*************************************************** WebDriverWait(self.driver, 10).until( ES.presence_of_element_located((By.XPATH, "//div[@class='text']//img")) ) all_img = all_content[1].xpath("//div[@class='text']//img//@src") #图片列表 #解决有个张图片没有http:协议 for index,item in enumerate(all_img): if 'http:' not in item: all_img[index] = 'http:'+item dic = dict(zip(all_author,all_img)) #多个列表生产字典 #遍历字典保存图片 for key in dic: hz = os.path.splitext(dic[key])[1] #取出后缀名.jpg/.png filename = key+hz #文件名(标题+后缀名) urllib.request.urlretrieve(dic[key],'images/'+filename) def main(): for i in range(9): rea = Custer() rea.start() if __name__ == '__main__': main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号