


高能预警: -------->>>>>>>>>>> 以下内容仅供参考
Hive相关
- 什么是metastore?
-
- metadata是元数据,包含数据库、表、字段、分区等信息。作用:客户端连接MetaStore服务,metastore再去连接MySQL数据库存储元数据,有了metastore服务可以实现多客户端同时连接MySQL。
- metastore三种配置:内嵌(Derby)、本地元存储、远程元存储
- Hive的元数据默认存储在Derby数据库,建议存储在像MySQL这种关系型数据库中。
- [为什么建议存储在关系型数据库中?]:默认的Derby数据库只能建立一个客户端连接,不能实现多客户端同时访问。不适合生产环境。
- metastore安装方式有什么区别?
-
- 内嵌:使用自带的Derby数据库存储元数据,不需要额外的MetaStore服务。一次仅能有一个客户端连接,适合实验环境,不适合生产环境
- 本地元存储:本地安装MySQL来存储元数据,hive服务和metastore服务运行在同一个进程中。
- 远程元存储:Hive服务和MetaStore服务在不同的进程中。
- 什么是Managed Table和External Table?
-
- Hive中有两种类型的表:Managed Table(内部表)和External Table(外部表)
- 内部表:hive的默认表类型,内部表的数据通常存放在/user/root/warehouse下
- 使用describe formatted 表名 来查看是内部表还是外部表
- 删除内部表时,存放在HDFS上的真实数据也一并删除。
- 外部表:适合于在hive之外使用表的数据的情况,删除外部表时,只是删除了元数据,真是数据并没有删除
- 什么时候使用Managed Table和External Table
-
- 内部表适用于临时创建的中间表
- 外部表数据多部门共享
-
hive有哪些复合数据类型
Map:key-value
Struct:不同数据类型的集合
Array:同类型元素的集合
UnionType:代表一个可以具有属于所选择的任何数据类型的值的列 -
hive分区有哪些好处
-
- 加速查询
- 使用分区列的名称来创建子目录,当使用where子句执行查询操作时,只会扫描特定的子目录,而不用扫描全表。还是加速查询
- hive分区和分桶的区别
-
- 分区:以字段的形式在表结构中存在,使用describe table_name 来查看字段是否存在,但是该字段不存放真实数据,仅仅是分区的表示(伪列)
- 分桶:一种细粒度的数据划分操作。实际生产中使用较少。[采用对列值哈希,然后除以桶的个数求余]
- hive如何动态分区
-
- 静态分区:加载数据时(显式)指定分区列
- 动态分区:将数据推送到Hive,Hive决定哪个值进入哪个分区。需要启动动态分区[hive.exec.dynamic.parition.mode=nostrict]
- map join优化手段
-
- Join时大表放在后面[执行join时,需要选择哪个表被流式传输,哪个表被缓存。Hive将Join语句中最后一个表用于流式传输,所以要确该表在两者之间是大的一方]
- Sort-Merge-Bucket(SMB) Map Join[使用前提:所有的表必须是桶分区(bucket)和已经排序的(sort)]
- 如何创建bucket表
-
- Hive默认是禁用分桶功能的,设置属性来强制使用分桶功能[hive.enforce.bucketing=true]
- hive有哪些file formats
-
- Text File Format:默认格式,不压缩数据,磁盘开销大。
- Sequence File Format:SF是Hadoop API提供的一种二进制文件支持。使用方便、可分割、可压缩。
Sequence File支持3中压缩格式:NONE、RECORD、BLOCK,建议使用BLOCK压缩。 - RC File Format:RC是一种行列存储相结合的存储方式。
- Parquet:列式数据存储
- AVRO:avro Schema数据序列化
- ORC:对RCFile做了优化,支持各种复杂的数据类型。
- hive最优的file formates是什么
ORC
-
- ORC将行的集合存储在一个文件中,且集合内的行数据将以列式存储。采用列式格式是为了压缩,从而降低存储成本。
- 查询:查询的是指定列而不是行,记录以列式存储
- ORC基于列创建索引,查询效率高。
- hive传参
-
- 使用--hivevar传入
- orderby 和 sortby的区别
-
- order by:全局排序,但是只能有一个partition
- sort by:局部排序,全局无序,partition内部有序,partition与partition之间没有关系。
- hive和hbase的区别
- hive支持SQL查询,Hbase不支持。
- hive不支持Record级别和删除操作。
- hive定义为数仓,HBase定义为NOSQL数据库。
Hive的概念
-
Hive是由Facebook开源,用于解决海量结构化日志(文本)的数据统计,它基于Hadoop工作
-
上面说的结构化日志(文本)值的是该文件中每一条记录的模样相似,比如:
| 张三 男 北京 21 本科 |
|---|
| 李四 男 上海 22 硕士 |
-
-
Hive的本质是: 将SQL语句翻译成MapReduce程序来执行
Hive工作原理图
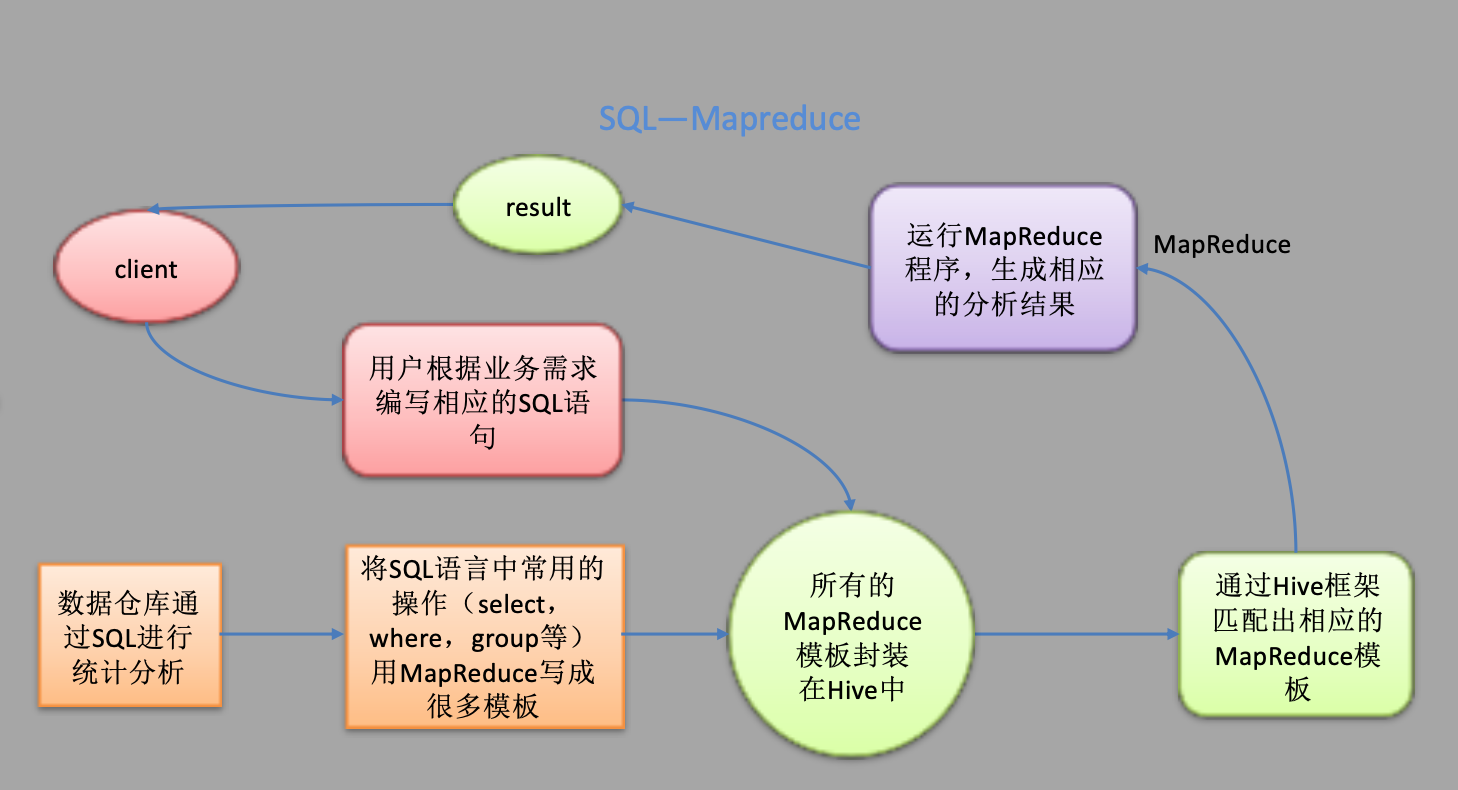
为什么说Hive基于Hadoop工作?
-
-
MR处理的数据的位置是HDFS,所以Hive依赖Hadoop是自然
-
MR的运行依赖YARN资源调度框架(YARN出现在Hadoop2.x的版本),所以Hive依赖Hadoop也是自然
Hive的优缺点
-
优点
1) 操作接口采用类SQL(HQL)语法,提供快速开发的能力(简单、容易上手)。
2) 避免了去写MapReduce,减少开发人员的学习成本。
3) Hive的执行延迟比较高,因此Hive常用于离线数据分析,对实时性要求不高的场合。
4) Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5) Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-
缺点
-
HQL表达能力有限
-
无法表达迭代式算法
-
不擅长数据挖掘
-
-
Hive的效率较低
-
Hive自动生成MR作业,通常不是很智能化
-
Hive调优比较困难,粒度粗
-
-
Hive架构
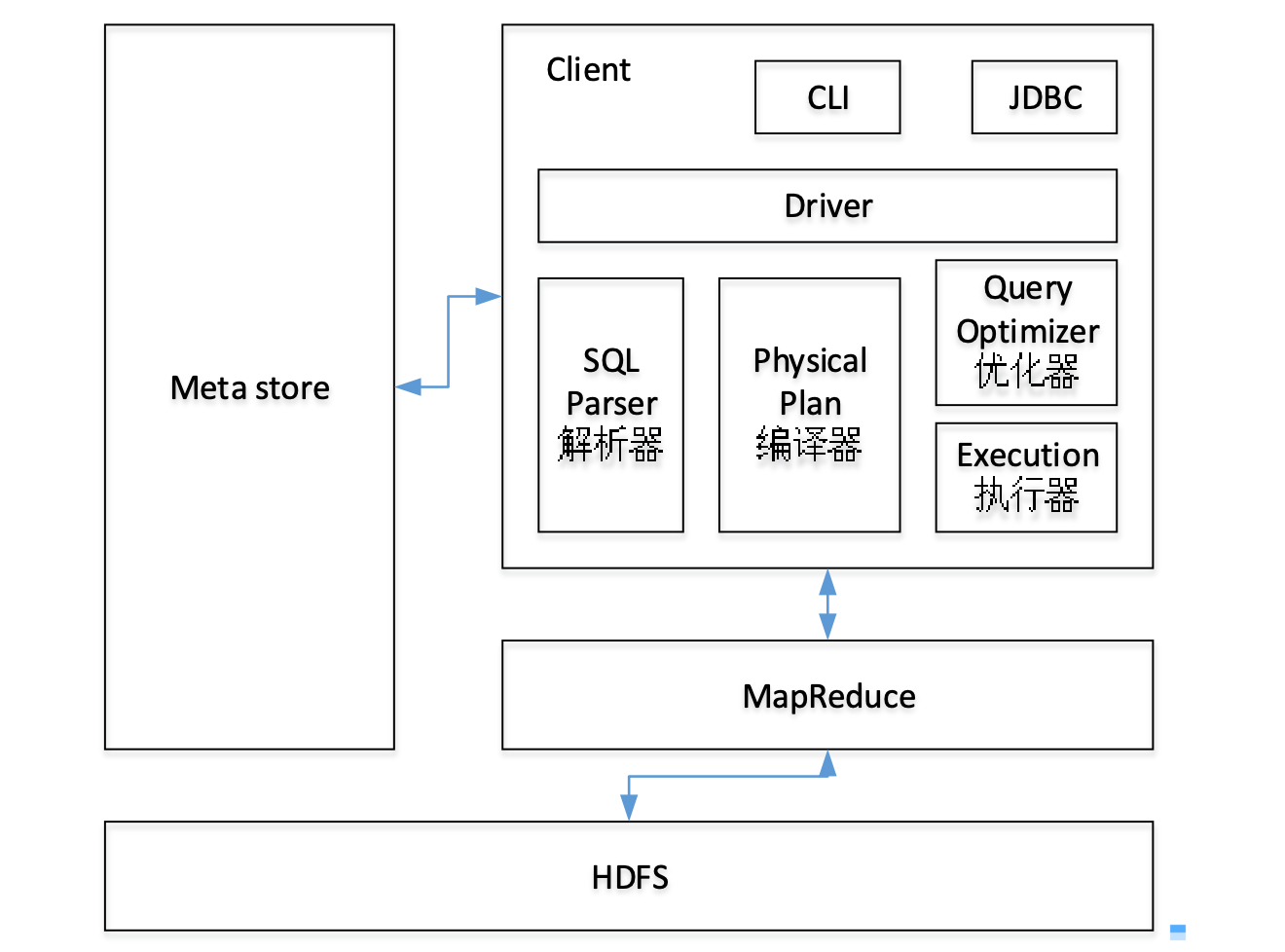
Hive组件
-
Client:用户接口,CLI(hive shell 交互式的命令窗口)、JDBC/ODBC(Java客户端访问hive)
-
Metastore:元数据,默认存储在自带的Derby数据库中,推荐使用MySQL存储MetaStore
-
Hadoop:使用HDFS存储,使用MR计算框架
-
Driver:驱动器
Hive和数据库比较
提示:Hive相当于一个翻译工具,将SQL翻译为MR计算任务。它不是数据库,只是在表现形式上和数据库有相似之处。
| 指标 | Hive | 数据库 |
|---|---|---|
| 查询语言 | HQL(类SQL) | SQL |
| 数据存储位置 | HDFS | 块设备或者本地磁盘 |
| 数据更新 | 读多写少,不建议数据改写 | |
| 索引 | 不建立索引,存在暴力访问 | 有索引 |
| 执行 | MR程序 | 自带引擎 |
| 执行延迟 | 扫描整表,延迟较高 | 数据量范围内毫秒级 |
| 可扩展性 | 易扩展 | 扩展性有限 |
| 数据规模 | 大规模数据 | 小规模数据 |
2019-07-12
There's no losing only learning
There's no falture only opportunities
There's no problem only solutions

 浙公网安备 33010602011771号
浙公网安备 33010602011771号