python高级应用课程设计
(一)
主题:探究影响北京二手房价格的元素
预期目标:分析当今人们喜欢的户型,为公司在二手房的销售做出合理推断,为业务发展提供指导意义
(二)
主题式网络爬虫名称:北京二手房爬虫
主题式网络爬虫爬取的内容与数据特征分析:二手房的总价,多少元每平方下限,面积下限,户型,关注数
设计思路:利用requests库爬取页面内容,bs4提取数据,python文件写入,
技术难点:爬取大量数据时,可能会有反爬措施,在爬取过程中我遇到被封ip的现象,因此在循环访问每一页的数据时候,使用了time库,每次延迟了1s,其次,查看一两页的数据格式远远不够,只能在爬取中慢慢让代码更加严谨,爬取更多正常解析的数据
(三)页面结构分析
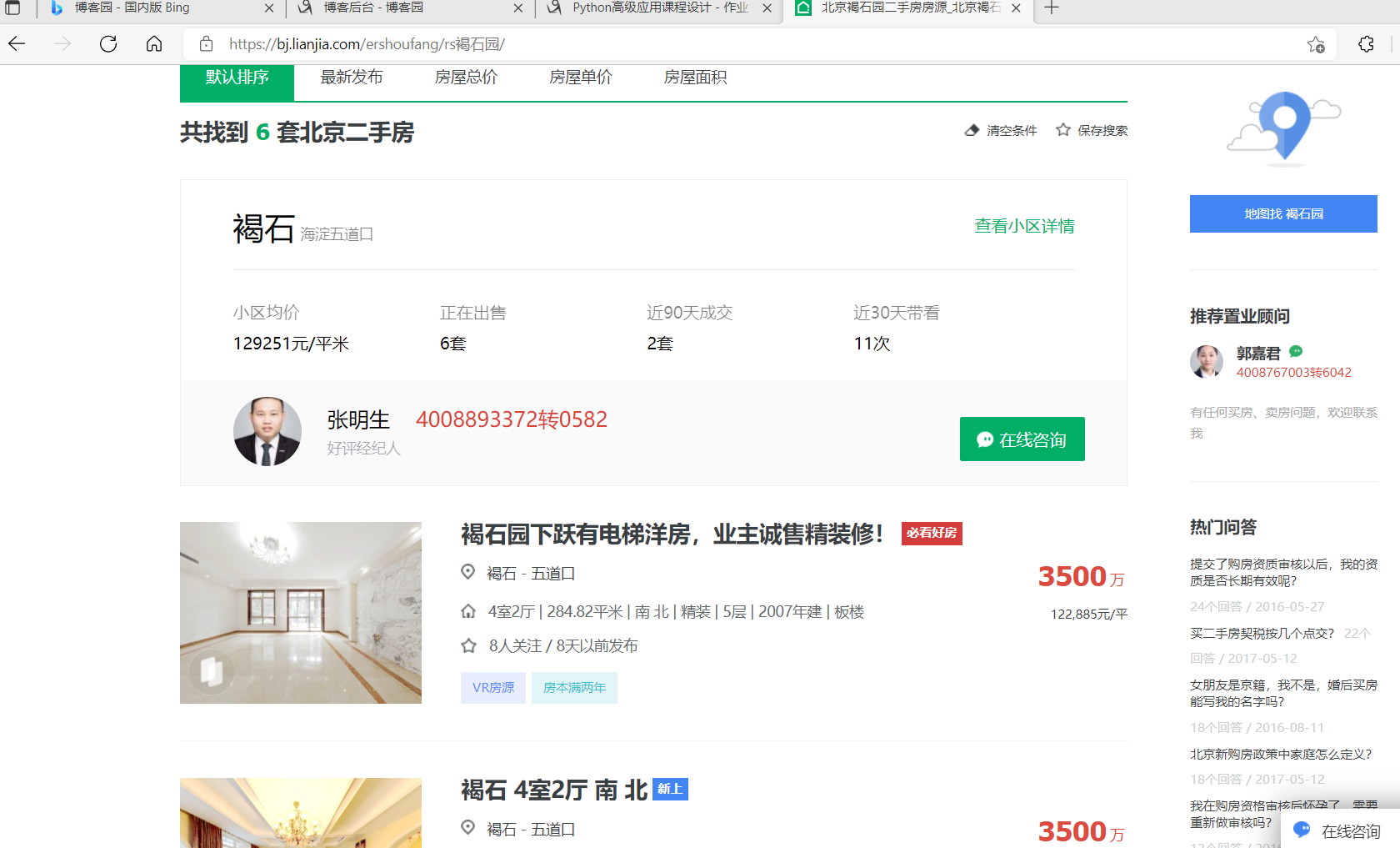
每条数据都在class为info clear的div中
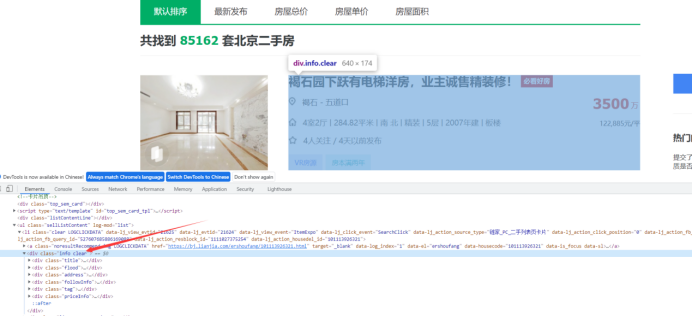
总价在class为totalPrice totalPrice2的div中的span标签中
每平方价在class为 unitPrice的div中的span标签中

户型在class为houseInfo中,可以用字符串分割|,列表第一个提出房型
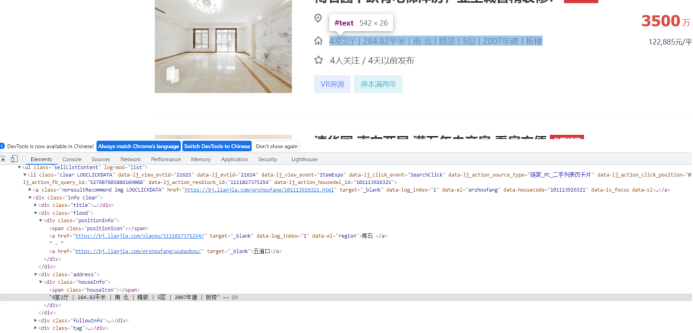
关注数在class为followInfo的div中
(四)爬虫程序设计
1.数据爬取与采集(requests+bs4)
1 import requests 2 3 import time 4 5 from bs4 import BeautifulSoup 6 7 #定义覆盖写方法 8 9 def write(content,isstart=True): 10 11 with open("ershoufang.csv", "w" if isstart else "a" , encoding="utf-8") as file: 12 13 file.write(content) 14 15 startflag=True 16 17 #写入数据头 18 19 write("totalprice,price,area,type,stars\n") 20 21 startflag=False 22 23 #循环构建分页爬虫 24 25 for i in range(100): 26 27 print("=======================正在爬取第{}页=====================".format(i+1)) 28 29 url="https://bj.lianjia.com/ershoufang/pg{}/".format(i+1) 30 31 # 获取链接响应结果 32 33 res = requests.get(url, headers={ 34 35 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}) 36 37 bs = BeautifulSoup(str(res.content, "utf-8"), "html.parser") 38 39 for item in bs.find_all("div", class_="info clear"): 40 41 areatag = item.find("div", class_="houseInfo") 42 43 areatext=areatag.get_text() 44 45 area=areatext.split("|")[1].strip().replace("平米", "") 46 47 fangxintag = item.find("div", class_="houseInfo") 48 49 fangxingtext=fangxintag.get_text() 50 51 fangxin=fangxingtext.split("|")[0].strip() 52 53 totalpricetag = item.find("div", class_="totalPrice totalPrice2") 54 55 totalprice=totalpricetag.find("span").string 56 57 pricetag=item.find("div",class_="unitPrice").find("span") 58 59 pricetext=pricetag.string 60 61 price=pricetext.replace(",","").replace("元/平","") 62 63 typetag=item.find("div", class_="houseInfo") 64 65 typetext=typetag.get_text() 66 67 type=typetext.split("|")[0].strip() 68 69 startag=item.find("div",class_="followInfo") 70 71 startext=startag.get_text() 72 73 star=startext.split("人关注")[0] 74 75 write("{},{},{},{},{}\n".format(totalprice,price,area,fangxin,star),startflag) 76 77 time.sleep(1) 78 79 print("=======================爬完了=====================")
运行结果,部分结果截图
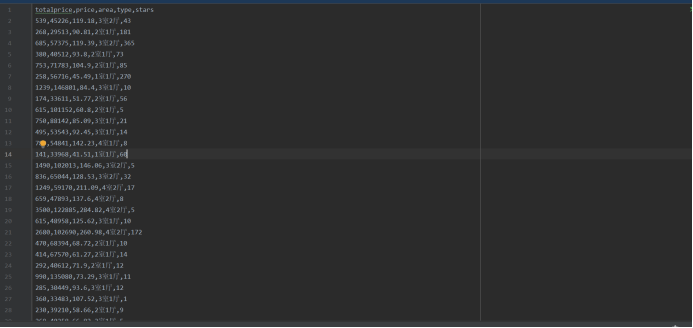

2.数据清洗
1 #清洗 2 3 import pandas as pd 4 5 data=pd.read_csv("ershoufang.csv") 6 7 old=len(data) 8 9 data.dropna(inplace=True) 10 11 print("清洗掉{}条数据".format(len(data)-old))s
结果
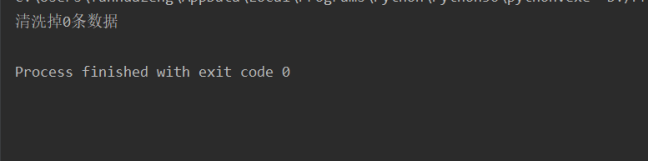
表明无空数据
3、数据分析与可视化(pandas+pyechats)
1 房型占比 2 3 import pandas as pd 4 5 data=pd.read_csv("ershoufang.csv") 6 7 from pyecharts.charts import Bar 8 9 from pyecharts import options as opts 10 11 12 13 bar = Bar() 14 15 #指定柱状图的横坐标 16 17 bar.add_xaxis(data['type'].value_counts().index.tolist()) 18 19 #指定柱状图的纵坐标,而且可以指定多个纵坐标 20 21 bar.add_yaxis( "房型",data['type'].value_counts().tolist()) 22 23 #指定柱状图的标题 24 25 bar.set_global_opts(title_opts=opts.TitleOpts(title="房型数量柱状图")) 26 27 #参数指定生成的html名称 28 29 bar.render('num.html')
结果
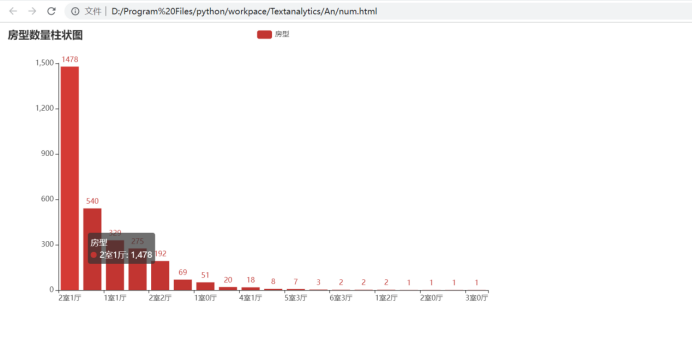
表明2室一厅占大多数
1 高价房型占比 2 3 #分析可视化 4 5 from pyecharts.charts import Pie 6 7 import pyecharts.options as opts 8 9 import pandas as pd 10 11 data=pd.read_csv("ershoufang.csv") 12 13 14 15 #将price分成5个区间 16 17 cutdata=pd.cut(data['price'],5) 18 19 #最后一个区间即为整体数据较高的一部分 20 21 left=cutdata.value_counts().index.tolist()[4].left 22 23 24 25 26 27 #分析较高单价房型占比 28 29 meandata=data[data.price>left] 30 31 meandata.reset_index(inplace=True) 32 33 34 35 36 37 num = data['type'].value_counts().tolist() 38 39 lab =data['type'].value_counts().index.tolist() #导入数据 40 41 42 43 ( 44 45 Pie(init_opts=opts.InitOpts(width='1400px', height='800px')) #指定画布大小 46 47 .add(series_name='', 48 49 radius=['20%', '40%'], #设置内、外环大小 50 51 data_pair=[(j, i) for i, j in zip(num, lab)]) #遍历数据 52 53 .set_global_opts(title_opts=opts.TitleOpts(title="高价房型占比",pos_left='center'), 54 55 legend_opts=opts.LegendOpts(pos_bottom=True)) 56 57 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) 58 59 ).render('view2.html')
结果
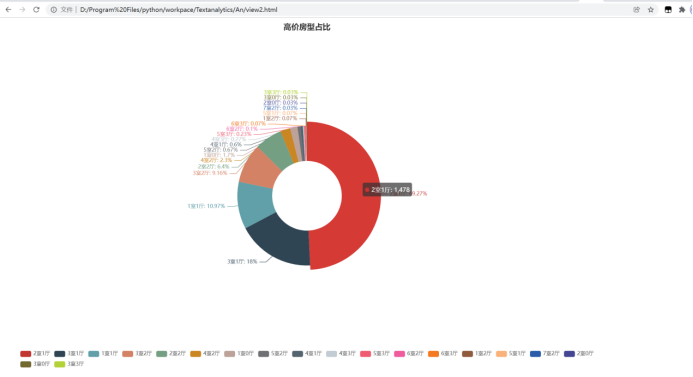
2室一厅比例有所减小,但还是占大部分
数量前五房型数据箱线图+数量散点
1 #各房型箱线图 2 3 import pandas as pd 4 5 6 7 import pyecharts.options as opts 8 9 from pyecharts.charts import Grid, Boxplot, Scatter 10 11 data=pd.read_csv("ershoufang.csv") 12 13 #数量前五房型数据箱线图+数量散点 14 15 #得到数量前五房型 16 17 types=data["type"].value_counts().head(5).index.tolist() 18 19 #筛选出前五房型数据 20 21 filterdata1=data[data.type==types[0]] 22 23 filterdata2=data[data.type==types[1]] 24 25 filterdata3=data[data.type==types[2]] 26 27 filterdata4=data[data.type==types[3]] 28 29 filterdata5=data[data.type==types[4]] 30 31 price1=filterdata1["price"].values.tolist() 32 33 price2=filterdata2["price"].values.tolist() 34 35 price3=filterdata3["price"].values.tolist() 36 37 price4=filterdata4["price"].values.tolist() 38 39 price5=filterdata5["price"].values.tolist() 40 41 meanprice=data['price'].mean() 42 43 #均价作为散点 44 45 # 46 47 y_data = [price1,price2,price3,price4,price5] 48 49 scatter_data = data["type"].value_counts().head(5).values.tolist() #有点像自定义打点,然后使得重合 50 51 52 53 box_plot = Boxplot() #这个使得两个箱线图重合 54 55 box_plot = ( 56 57 box_plot.add_xaxis(xaxis_data=types) 58 59 .add_yaxis(series_name="房型", y_axis=box_plot.prepare_data(y_data)) 60 61 .set_global_opts( 62 63 title_opts=opts.TitleOpts( 64 65 pos_left="left", title="数量前五房型前五房型数据箱线图" 66 67 ), 68 69 xaxis_opts=opts.AxisOpts( 70 71 type_="category", 72 73 boundary_gap=True, 74 75 splitline_opts=opts.SplitLineOpts(is_show=False), #分割线显示与否 76 77 ), 78 79 yaxis_opts=opts.AxisOpts( #y轴 80 81 type_="value", 82 83 name="元/每平方米", 84 85 splitarea_opts=opts.SplitAreaOpts( 86 87 is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1) 88 89 ), 90 91 ), 92 93 ) 94 95 .set_series_opts(tooltip_opts=opts.TooltipOpts(formatter="{b}: {c}")) #按照名称/最小值/Q1/中值/Q3/最大值 展示 96 97 ) 98 99 scatter = ( 100 101 Scatter() 102 103 .add_xaxis(xaxis_data=types)# 这个可以不输入值 104 105 .add_yaxis(series_name="数量", y_axis=scatter_data) 106 107 .set_global_opts( 108 109 110 111 title_opts=opts.TitleOpts( #标题 112 113 pos_left="10%", 114 115 pos_top="90%", 116 117 title="upper: Q3 + 1.5 * IQR \n\nlower: Q1 - 1.5 * IQR", 118 119 title_textstyle_opts=opts.TextStyleOpts( 120 121 border_color="#999", border_width=1, font_size=14 122 123 ), 124 125 126 127 ), 128 129 legend_opts=opts.LegendOpts(pos_bottom=True), 130 131 yaxis_opts=opts.AxisOpts( 132 133 axislabel_opts=opts.LabelOpts(is_show=False), 134 135 axistick_opts=opts.AxisTickOpts(is_show=False), 136 137 ), 138 139 ) 140 141 ) 142 143 grid = ( 144 145 Grid(init_opts=opts.InitOpts(width="1000px", height="600px")) # 设置长宽 146 147 #箱线图的位置 调整数值之后可使得两者不交叠,可以不输入 148 149 .add( 150 151 box_plot, 152 153 grid_opts=opts.GridOpts(pos_left="10%", pos_right="10%", pos_bottom="15%"), 154 155 ) 156 157 #点点的位置 调整数值之后可使得两者不交叠,可以不输入 158 159 .add( 160 161 scatter, 162 163 grid_opts=opts.GridOpts(pos_left="10%", pos_right="10%", pos_bottom="15%"), 164 165 ) 166 167 .render("view3.html") 168 169 )
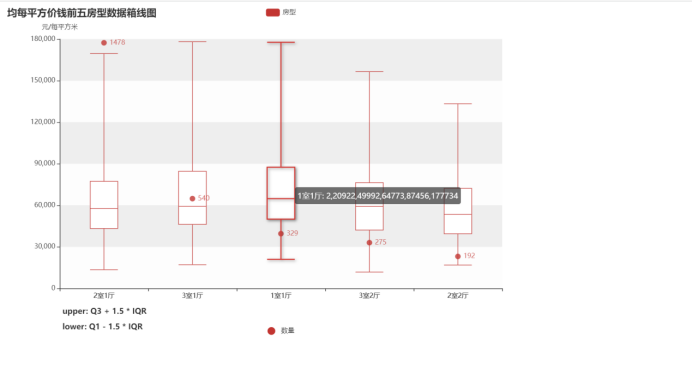
一室一厅最低价,最高价,平均价都比其它房型高
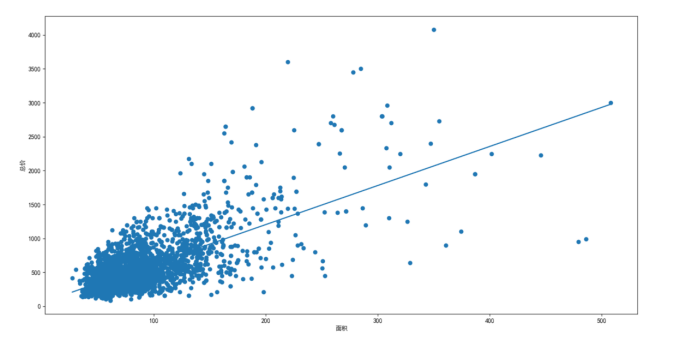
4、使用最小二乘法构建出面积和总价的关系并画出线性回归图像
1 import pandas as pd 2 3 import matplotlib.pyplot as plt 4 5 def leastSquare(x, y): 6 7 if len(x) == 2: 8 9 # 此时x为自然序列 10 11 sx = 0.5 * (x[1] - x[0] + 1) * (x[1] + x[0]) 12 13 ex = sx / (x[1] - x[0] + 1) 14 15 sx2 = ((x[1] * (x[1] + 1) * (2 * x[1] + 1)) 16 17 - (x[0] * (x[0] - 1) * (2 * x[0] - 1))) / 6 18 19 x = np.array(range(x[0], x[1] + 1)) 20 21 else: 22 23 sx = sum(x) 24 25 ex = sx / len(x) 26 27 sx2 = sum(x ** 2) 28 29 30 31 sxy = sum(x * y) 32 33 ey = np.mean(y) 34 35 36 37 a = (sxy - ey * sx) / (sx2 - ex * sx) 38 39 b = (ey * sx2 - sxy * ex) / (sx2 - ex * sx) 40 41 return a, b 42 43 44 45 46 47 data=pd.read_csv("ershoufang.csv") 48 49 area=data["area"].values 50 51 totalprice=data["totalprice"].values 52 53 a,b=leastSquare(area,totalprice) 54 55 plt.rcParams['font.sans-serif']=['SimHei'] 56 57 plt.scatter(area,totalprice) 58 59 plt.xlabel("面积") 60 61 plt.ylabel("总价") 62 63 plt.plot(area,a*area+b) 64 65 plt.show()
结果
5、持久化数据代码
1 #定义覆盖写方法 2 def write(content,isstart=True): 3 with open("ershoufang.csv", "w" if isstart else "a" , encoding="utf-8") as file: 4 file.write(content)
1 import requests 2 import time 3 from bs4 import BeautifulSoup 4 #定义覆盖写方法 5 def write(content,isstart=True): 6 with open("ershoufang.csv", "w" if isstart else "a" , encoding="utf-8") as file: 7 file.write(content) 8 startflag=True 9 #写入数据头 10 write("totalprice,price,area,type,stars\n") 11 startflag=False 12 #循环构建分页爬虫 13 for i in range(100): 14 print("=======================正在爬取第{}页=====================".format(i+1)) 15 url="https://bj.lianjia.com/ershoufang/pg{}/".format(i+1) 16 # 获取链接响应结果 17 res = requests.get(url, headers={ 18 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}) 19 bs = BeautifulSoup(str(res.content, "utf-8"), "html.parser") 20 for item in bs.find_all("div", class_="info clear"): 21 areatag = item.find("div", class_="houseInfo") 22 areatext=areatag.get_text() 23 area=areatext.split("|")[1].strip().replace("平米", "") 24 fangxintag = item.find("div", class_="houseInfo") 25 fangxingtext=fangxintag.get_text() 26 fangxin=fangxingtext.split("|")[0].strip() 27 totalpricetag = item.find("div", class_="totalPrice totalPrice2") 28 totalprice=totalpricetag.find("span").string 29 pricetag=item.find("div",class_="unitPrice").find("span") 30 pricetext=pricetag.string 31 price=pricetext.replace(",","").replace("元/平","") 32 typetag=item.find("div", class_="houseInfo") 33 typetext=typetag.get_text() 34 type=typetext.split("|")[0].strip() 35 startag=item.find("div",class_="followInfo") 36 startext=startag.get_text() 37 star=startext.split("人关注")[0] 38 write("{},{},{},{},{}\n".format(totalprice,price,area,fangxin,star),startflag) 39 time.sleep(1) 40 print("=======================爬完了=====================") 41 #清洗 42 import pandas as pd 43 data=pd.read_csv("ershoufang.csv") 44 old=len(data) 45 data.dropna(inplace=True) 46 print("清洗掉{}条数据".format(len(data)-old)) 47 #分析可视化 48 #各种房型数量 49 import matplotlib.pyplot as plt 50 import pandas as pd 51 data=pd.read_csv("ershoufang.csv") 52 from pyecharts.charts import Bar 53 from pyecharts import options as opts 54 55 bar = Bar() 56 #指定柱状图的横坐标 57 bar.add_xaxis(data['type'].value_counts().index.tolist()) 58 #指定柱状图的纵坐标,而且可以指定多个纵坐标 59 bar.add_yaxis( "房型",data['type'].value_counts().tolist()) 60 #指定柱状图的标题 61 bar.set_global_opts(title_opts=opts.TitleOpts(title="房型数量柱状图")) 62 #参数指定生成的html名称 63 bar.render('view.html') 64 #分析可视化 65 from pyecharts.charts import Pie 66 import pyecharts.options as opts 67 import pandas as pd 68 data=pd.read_csv("ershoufang.csv") 69 print(data) 70 #将price分成5个区间 71 cutdata=pd.cut(data['price'],5) 72 #最后一个区间即为整体数据较高的一部分 73 left=cutdata.value_counts().index.tolist()[4].left 74 75 76 #分析较高单价房型占比 77 meandata=data[data.price>left] 78 meandata.reset_index(inplace=True) 79 80 81 num = data['type'].value_counts().tolist() 82 lab =data['type'].value_counts().index.tolist() #导入数据 83 84 ( 85 Pie(init_opts=opts.InitOpts(width='1400px', height='800px')) #指定画布大小 86 .add(series_name='', 87 radius=['20%', '40%'], #设置内、外环大小 88 data_pair=[(j, i) for i, j in zip(num, lab)]) #遍历数据 89 .set_global_opts(title_opts=opts.TitleOpts(title="高价房型占比",pos_left='center'), 90 legend_opts=opts.LegendOpts(pos_bottom=True)) 91 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) 92 ).render('view2.html') 93 #各房型箱线图 94 import pandas as pd 95 96 import pyecharts.options as opts 97 from pyecharts.charts import Grid, Boxplot, Scatter 98 data=pd.read_csv("ershoufang.csv") 99 #数量前五房型数据箱线图+数量散点 100 #得到数量前五房型 101 types=data["type"].value_counts().head(5).index.tolist() 102 #筛选出前五房型数据 103 filterdata1=data[data.type==types[0]] 104 filterdata2=data[data.type==types[1]] 105 filterdata3=data[data.type==types[2]] 106 filterdata4=data[data.type==types[3]] 107 filterdata5=data[data.type==types[4]] 108 price1=filterdata1["price"].values.tolist() 109 price2=filterdata2["price"].values.tolist() 110 price3=filterdata3["price"].values.tolist() 111 price4=filterdata4["price"].values.tolist() 112 price5=filterdata5["price"].values.tolist() 113 meanprice=data['price'].mean() 114 #均价作为散点 115 # 116 y_data = [price1,price2,price3,price4,price5] 117 scatter_data = data["type"].value_counts().head(5).values.tolist() #有点像自定义打点,然后使得重合 118 119 box_plot = Boxplot() #这个使得两个箱线图重合 120 box_plot = ( 121 box_plot.add_xaxis(xaxis_data=types) 122 .add_yaxis(series_name="房型", y_axis=box_plot.prepare_data(y_data)) 123 .set_global_opts( 124 title_opts=opts.TitleOpts( 125 pos_left="left", title="数量前五房型前五房型数据箱线图" 126 ), 127 xaxis_opts=opts.AxisOpts( 128 type_="category", 129 boundary_gap=True, 130 splitline_opts=opts.SplitLineOpts(is_show=False), #分割线显示与否 131 ), 132 yaxis_opts=opts.AxisOpts( #y轴 133 type_="value", 134 name="元/每平方米", 135 splitarea_opts=opts.SplitAreaOpts( 136 is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1) 137 ), 138 ), 139 ) 140 .set_series_opts(tooltip_opts=opts.TooltipOpts(formatter="{b}: {c}")) #按照名称/最小值/Q1/中值/Q3/最大值 展示 141 ) 142 scatter = ( 143 Scatter() 144 .add_xaxis(xaxis_data=types)# 这个可以不输入值 145 .add_yaxis(series_name="数量", y_axis=scatter_data) 146 .set_global_opts( 147 148 title_opts=opts.TitleOpts( #标题 149 pos_left="10%", 150 pos_top="90%", 151 title="upper: Q3 + 1.5 * IQR \n\nlower: Q1 - 1.5 * IQR", 152 title_textstyle_opts=opts.TextStyleOpts( 153 border_color="#999", border_width=1, font_size=14 154 ), 155 156 ), 157 legend_opts=opts.LegendOpts(pos_bottom=True), 158 yaxis_opts=opts.AxisOpts( 159 axislabel_opts=opts.LabelOpts(is_show=False), 160 axistick_opts=opts.AxisTickOpts(is_show=False), 161 ), 162 ) 163 ) 164 grid = ( 165 Grid(init_opts=opts.InitOpts(width="1000px", height="600px")) # 设置长宽 166 #箱线图的位置 调整数值之后可使得两者不交叠,可以不输入 167 .add( 168 box_plot, 169 grid_opts=opts.GridOpts(pos_left="10%", pos_right="10%", pos_bottom="15%"), 170 ) 171 #点点的位置 调整数值之后可使得两者不交叠,可以不输入 172 .add( 173 scatter, 174 grid_opts=opts.GridOpts(pos_left="10%", pos_right="10%", pos_bottom="15%"), 175 ) 176 .render("view3.html") 177 ) 178 #探究关系 179 import numpy as np 180 import pandas as pd 181 import matplotlib.pyplot as plt 182 def leastSquare(x, y): 183 if len(x) == 2: 184 # 此时x为自然序列 185 sx = 0.5 * (x[1] - x[0] + 1) * (x[1] + x[0]) 186 ex = sx / (x[1] - x[0] + 1) 187 sx2 = ((x[1] * (x[1] + 1) * (2 * x[1] + 1)) 188 - (x[0] * (x[0] - 1) * (2 * x[0] - 1))) / 6 189 x = np.array(range(x[0], x[1] + 1)) 190 else: 191 sx = sum(x) 192 ex = sx / len(x) 193 sx2 = sum(x ** 2) 194 195 sxy = sum(x * y) 196 ey = np.mean(y) 197 198 a = (sxy - ey * sx) / (sx2 - ex * sx) 199 b = (ey * sx2 - sxy * ex) / (sx2 - ex * sx) 200 return a, b 201 202 data=pd.read_csv("ershoufang.csv") 203 area=data["area"].values 204 totalprice=data["totalprice"].values 205 a,b=leastSquare(area,totalprice) 206 plt.rcParams['font.sans-serif']=['SimHei'] 207 plt.scatter(area,totalprice) 208 plt.xlabel("面积") 209 plt.ylabel("总价") 210 plt.plot(area,a*area+b) 211 plt.show()
(五)总结
1、经过对主题数据的分析与可视化,可以得到那些结论?是否达到预期的目标?
在之前二室一厅在北京的二手房里占大多数,虽然现在有所减少,但还是占大部分,一室一厅一室一厅最低价,最高价,平均价都比其它房型高。达到了了解分析当今人们喜欢的户型,为相关公司在二手房的销售做出合理推断,为业务发展提供指导意义。
2、在完成此设计过程中,得到哪些收获?以及要改进的建议?
在此次设计过程中,更加了解了相关知识,也让我知道了出去所学知识之外的一些实用性较高的知识,也让我知道了更多关于python相关的软件,如pycharm,也让我发现了一些新的、有趣的东西,让我对python更加感兴趣了,但在完成这个设计时,也是有很多碰壁的地方,像有些图像要显示时总是无法体现,也是查了许多资料才慢慢变得熟练,也希望下次能做得更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号