
数据采集与融合技术第二次作业
数据采集与融合技术第二次作业
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
作业代码和图片:
点击查看代码
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)" ,(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows=self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0],row[1],row[2],row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode={"北京":"101010100","上海":"101020100","广州":"101280101","深圳":"101280601"}
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city+" code cannot be found")
return
url="http://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
req=urllib.request.Request(url,headers=self.headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self,cities):
self.db=WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
#self.db.show()
self.db.closeDB()
ws=WeatherForecast()
ws.process(["北京","上海","广州","深圳"])
print("completed")

实验心得:

📋 代码整体架构
这段代码由两个核心类组成:
WeatherDB - 负责数据库操作
WeatherForecast - 负责爬取天气数据
WeatherDB类是一个数据库管理器,专门负责与SQLite数据库进行交互。它封装了所有与数据存储相关的操作,包括创建数据库、插入天气数据、查询数据以及关闭连接等功能。
WeatherForecast类是一个网络爬虫,它的任务是从中国天气网抓取天气预报数据。这个类负责构建HTTP请求、解析HTML网页、提取有用信息,然后将数据交给数据库类进行存储。
编码问题解决后,程序将HTML字符串交给BeautifulSoup进行解析。BeautifulSoup使用lxml解析器将HTML转换成一个可以方便查询的对象树。然后程序用CSS选择器定位到特定的HTML元素:class为't clearfix'的ul标签下的所有li元素。这些li元素就是网页中显示每一天天气预报的卡片。
对于每一个li元素,程序提取三类信息。第一是日期,它在h1标签中,可能显示为"4日(今天)"这样的文字。第二是天气状况,它在class为"wea"的p标签中,可能是"晴"、"多云"、"雨"等描述。第三是温度信息,这稍微复杂一些,需要从class为"tem"的p标签中分别提取span标签(最高温)和i标签(最低温)的文本,然后用斜杠连接起来,形成"18/8℃"这样的格式
作业②
要求:用requests和json解析方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
作业代码和图片:
核心代码:
点击查看代码
def get_url(page):
url = (f"https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37105104315725764869_1761718278335"
"&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2"
"&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23"
"&fid=f3"
"&pn="+str(page)+"&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=")
return url
def get_data(url):
response = requests.get(url)
response.encoding = 'utf-8' # 防止乱码
response = response.text
data = parse_jsonp_simple(response)
return data
# 解析JSONP格式的响应为JSON字典
def parse_jsonp_simple(jsonp_str):
# 找到第一个左括号和最后一个右括号
start = jsonp_str.find('(')
end = jsonp_str.rfind(')')
if start != -1 and end != -1:
json_str = jsonp_str[start+1:end]
return json.loads(json_str)
else:
raise ValueError("无效的JSONP格式")
# 打印表头(按照要求的格式,单位在表头中)
print("=" * 150)
print(f"{'序号':<6}{'股票代码':<8}{'股票名称':<14}{'最新报价':<12}{'涨跌幅':<10}{'涨跌额':<10}{'成交量':<10}{'成交额':<14}{'振幅':<10}{'最高':<8}{'最低':<8}{'今开':<6}{'昨收':<10}")
print("=" * 150)
运行结果:(当日两只股票)



心得体会
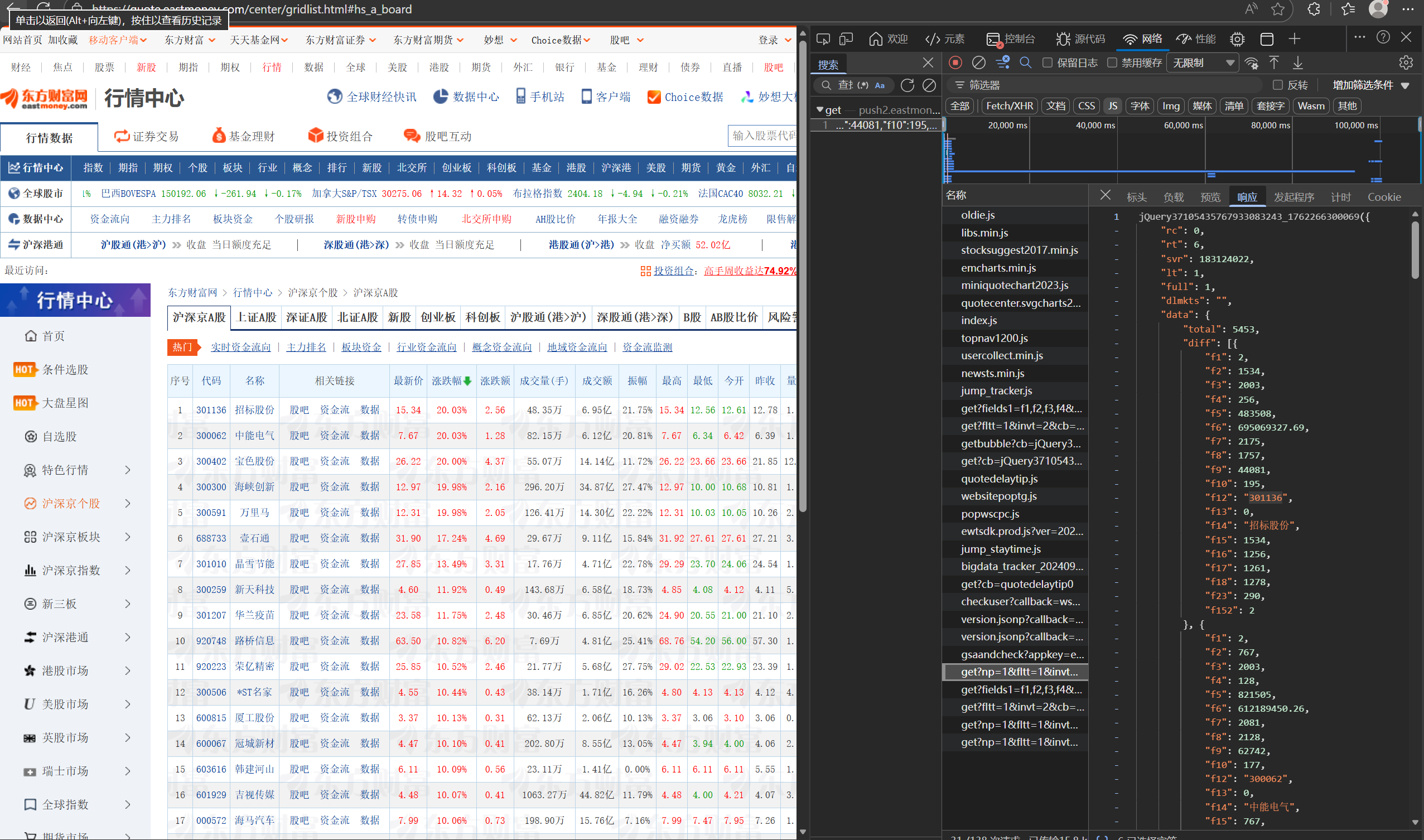

上图为找寻对应页面js文件的F12开发者模式,根据找到的url,我们发现到了规律,
fs指定市场类型,fields定义需要返回的字段。&pn后代表着对应股票第几页的股票页面,所以我们在写代码的时候,可以像我这样把这个具体数值定义为变量i,然后用for循环遍历从而实现爬取不同页面的详情对应序号头

作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
作业代码和图片
数据获取
点击查看代码
def build_variable_mapping(content):
"""构建变量到实际值的映射表(自动解析)"""
# 提取函数参数列表
func_match = re.search(r'function\(([^)]+)\)', content)
if not func_match:
return {}
params = [p.strip() for p in func_match.group(1).split(',')]
# 提取实际传入的值
last_call_idx = content.rfind('}(')
if last_call_idx < 0:
return {}
values_part = content[last_call_idx+2:]
end_idx = values_part.find('))')
if end_idx < 0:
return {}
values_str = values_part[:end_idx]
# 解析传入的值
# 将字符串按逗号分割,但要处理引号内的逗号
values = []
current_value = ''
in_quotes = False
for char in values_str:
if char == '"':
in_quotes = not in_quotes
elif char == ',' and not in_quotes:
values.append(current_value.strip())
current_value = ''
continue
current_value += char
if current_value.strip():
values.append(current_value.strip())
# 构建映射表
mapping = {}
for i, param in enumerate(params):
if i < len(values):
value = values[i]
# 解析不同类型的值
if value == 'true':
mapping[param] = True
elif value == 'false':
mapping[param] = False
elif value == 'null':
mapping[param] = None
elif value.startswith('"') and value.endswith('"'):
# 字符串值
mapping[param] = value[1:-1]
elif re.match(r'^-?\d+\.?\d*$', value):
# 数字值(整数或小数)
mapping[param] = float(value) if '.' in value else int(value)
else:
# 其他情况保持原样
mapping[param] = value
print(f"✓ 成功解析 {len(mapping)} 个变量映射")
# 显示一些映射示例(用于调试)
print(" 变量映射示例(前20个):")
for i, (k, v) in enumerate(list(mapping.items())[:20]):
if isinstance(v, str) and len(v) < 20:
print(f" {k} = {repr(v)}")
elif isinstance(v, (int, float, bool, type(None))):
print(f" {k} = {v}")
return mapping
def get_university_data_from_local():
"""从本地 payload.js 文件读取数据(包括省份和类型)"""
try:
with open('D:\数据采集\实践2\payload.js', 'r', encoding='utf-8') as f:
content = f.read()
# 构建变量映射表
var_mapping = build_variable_mapping(content)
pattern = r'univUp:"([^"]+)".*?univNameCn:"([^"]+)",univNameEn:(?:"([^"]*)"|(\w+)).*?univCategory:(\w+),province:(\w+),score:([\w.$]+)'
matches = re.findall(pattern, content)
if not matches:
print("未找到大学数据")
return None
# 转换为字典列表
univdata = []
skipped_count = 0
for match in matches:
# 新的捕获组:(univUp, nameCn, nameEn_str, nameEn_var, category, province, score)
univ_up, name_cn, name_en_str, name_en_var, category_var, province_var, score_val = match
# 处理univNameEn:可能是字符串或变量
if name_en_str:
# univNameEn是字符串形式
name_en = name_en_str
elif name_en_var:
# univNameEn是变量形式,尝试从映射表获取
name_en_from_map = var_mapping.get(name_en_var)
name_en = name_en_from_map if isinstance(name_en_from_map, str) else name_en_var
else:
name_en = ''
# 使用映射表转换变量
category = var_mapping.get(category_var, category_var)
province = var_mapping.get(province_var, province_var)
# 处理score:可能是数字或变量
if re.match(r'^\d+\.?\d*$', score_val):
# 直接是数字
score = float(score_val)
else:
# 是变量,需要从映射表中查找
score_from_map = var_mapping.get(score_val)
if isinstance(score_from_map, (int, float)):
score = float(score_from_map)
else:
# 无法解析的score,跳过或设为0
print(f" ⚠ 警告: {name_cn} 的score变量 {score_val} 无法解析,映射值={score_from_map}")
skipped_count += 1
score = 0.0 # 或者可以选择continue跳过这所大学
univdata.append({
'univUp': univ_up,
'univNameCn': name_cn,
'univNameEn': name_en,
'univCategory': category if isinstance(category, str) else '',
'province': province if isinstance(province, str) else '',
'score': score
})
print(f"✓ 成功从本地文件读取 {len(univdata)} 所大学的数据")
if skipped_count > 0:
print(f" ⚠ 有 {skipped_count} 所大学的score无法解析")
return univdata
点击查看代码
def display_universities(universities, n=30):
"""以表格形式显示大学数据"""
if not universities:
print("没有数据可显示")
return
print("\n" + "=" * 150)
print(f"{'序号':<6}{'排名':<8}{'学校名称':<28}{'省市':<12}{'类型':<10}{'总分':<10}")
print("=" * 150)
for uni in universities[:n]:
print(f"{uni['序号']:<8}{str(uni['排名']):<10}{uni['学校名称']:<26}{uni['省市']:<14}{uni['类型']:<12}{uni['总分']}")
print("=" * 150)
print(f"总共 {len(universities)} 所大学(显示前 {min(n, len(universities))} 所)\n")

心得体会

这段代码也和之前如出一辙,就是先像上图这样找到js文件,找到之后我们发现他存在一个映射关系,映射结果在结尾,
使用正则表达式提取大学信息(包括province和univCategory)
格式: {univUp:"xxx",...univNameCn:"xxx",univNameEn:"xxx"或univNameEn:var,...univCategory:x,province:y,...score:xxx,...}
注意:
1. univNameEn可以是字符串"xxx"或变量var(不带引号)
2. score可以是数字(123.4)也可以是变量(hT, j$等,包含$符号)
我们提取每一个大学的部分并一一对应即可,这个相比于上面几个其实就多了个结尾的映射其实方法大抵相同同时也要进行输出美化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号