Python抓取第一网贷中国网贷理财每日收益率指数
链接:http://www.p2p001.com/licai/index/id/147.html
所需获取数据链接类似于:http://www.p2p001.com/licai/shownews/id/454.html:
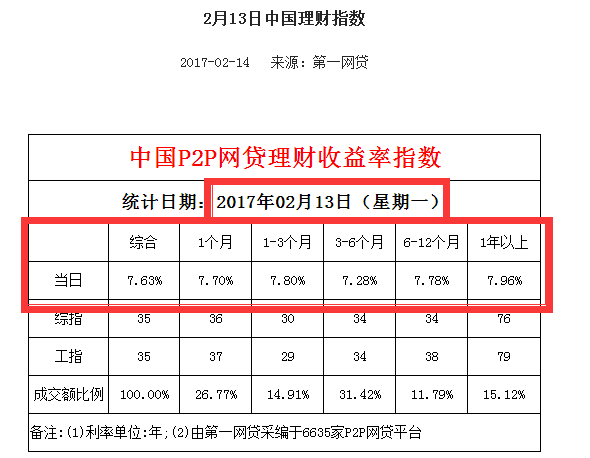
库:
requests (For human)
re (正则)
pandas (用来处理数据)
BeautifulSoup (用来解析网页文本)
此次抓取逻辑思维在代码之后
上代码:
#coding utf-8 import requests import re import pandas from bs4 import BeautifulSoup user_agent = 'User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)' headers = {'User-Agent':user_agent} #定义函数,得到每日报的链接,并以列表形式返回 def get_newsurl(): newsurl=[] url1='http://www.p2p001.com/licai/index/id/147/p/' num=1 url2='.html' while num<=22: url=url1+str(num)+url2 try: r1=requests.get(url,headers=headers) except: print ('wrong %s' % url) else: s1=BeautifulSoup(r1.text,'lxml') for x in s1.find_all(href=re.compile('licai/shownews')): newsurl.append(x['href']) num=num+1 return newsurl #定义函数,得到的数据,以字典形式返回 def get_info(): url='http://www.p2p001.com' date=[] zonghe=[] one=[] one_three=[] three_six=[] six_twelve=[] twelve_most=[] for y in get_newsurl(): try: main_url=url+y r2=requests.get(main_url,headers=headers) except: print ('wrong %s' % main_url) else: s2=BeautifulSoup(r2.text,'lxml') date.append(s2.find(text=re.compile('统计日期'))[5:]) rate=s2.find_all('td') zonghe.append(rate[10].string) one.append(rate[11].string) one_three.append(rate[12].string) three_six.append(rate[13].string) six_twelve.append(rate[14].string) twelve_most.append(rate[15].string) p={'Date':date, '综合':zonghe, '1个月':one, '1-3个月':one_three, '3-6个月':three_six, '6-12个月':six_twelve, '12个月及以上':twelve_most} return p #pandas存储数据 p=pd.DataFrame(get_info())
p.to_csv('f://1//rate1.csv',index=False,
columns=['Date','综合','1个月','1-3个月','3-6个月','6-12个月','12个月及以上'],
header=['Date','综合','1个月','1-3个月','3-6个月','6-12个月','12个月及以上'])
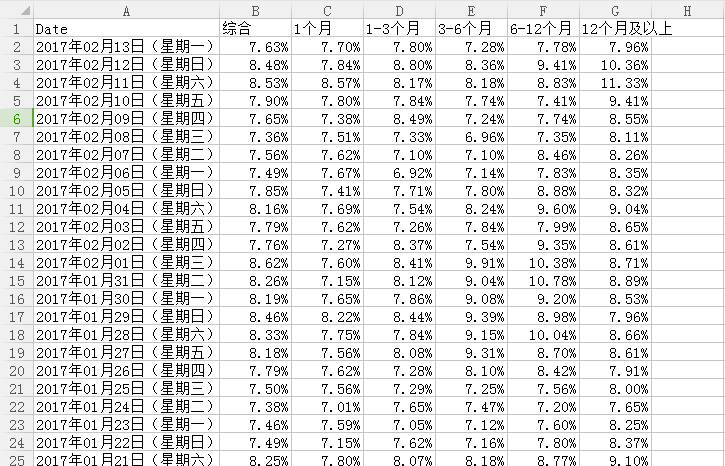
此次学习总结及反思:
1.为了方便处理,并没有使用数据库来存储数据,而是使用pandas将数据以csv格式保存在本地硬盘F
2.定义第一个函数对象get_newsurl,以列表形式返回理财指数日报链接,第二个函数遍历第一个函数的返回值,进行数据的采集
3.为什么不将pandas的一系列操作放在函数对象get_info中,从而直接完成一系列的操作呢?
当时考虑了效率和灵活性考虑。
one:如果将pandas的数据操作丢在get_info中,那么调用get_info()的时候,整个效率将会降低很多很多
two:拿出来单独处理,灵活性大大提高,调用get_info(),以字典形式返回我需要的数据,拿到这个数据后,我可以做任何我想做的处理,而不是用一个函数将整个采集下来的数据直接打入地牢,让这些数据没有了自由。
4.抓取思路
①先发现日报的链接规律,也就是说共有22页,每页20份日报指数数据,因为只做一次简单的抓取,所以这个值这个可以写死
这个就是第一个函数做的事,返回这些href的值
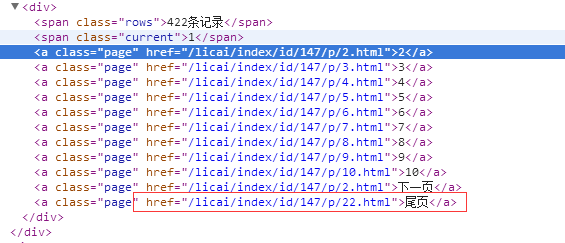
②进入具体的日报页面,抓取我们所需要的数据,并以字典形式返回![]()
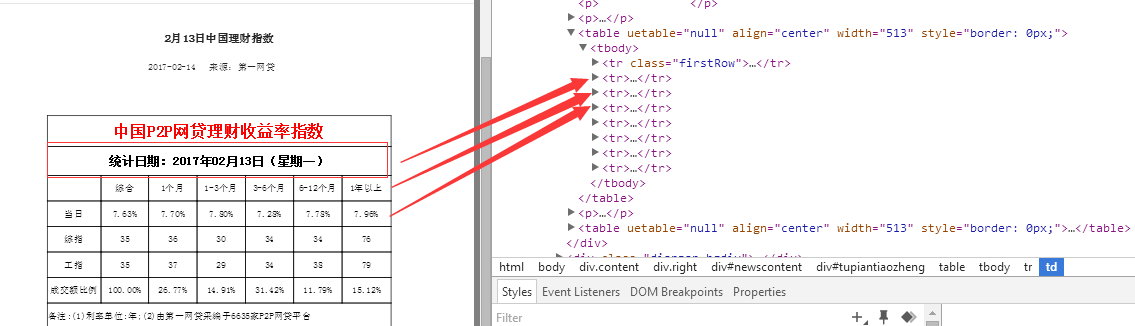
③处理并存储数据(pandas)
注明:数据来源于第一网贷http://www.p2p001.com/
小白一枚,能力有限,做的不好的地方,尤其是逻辑与思维上的东西,需要大神们看到了多多指教和斧正buddyquan。
QQ:1749061919 小白爬虫求带

 浙公网安备 33010602011771号
浙公网安备 33010602011771号