

GO并发调度GPM概述及源码解读
1、架构图
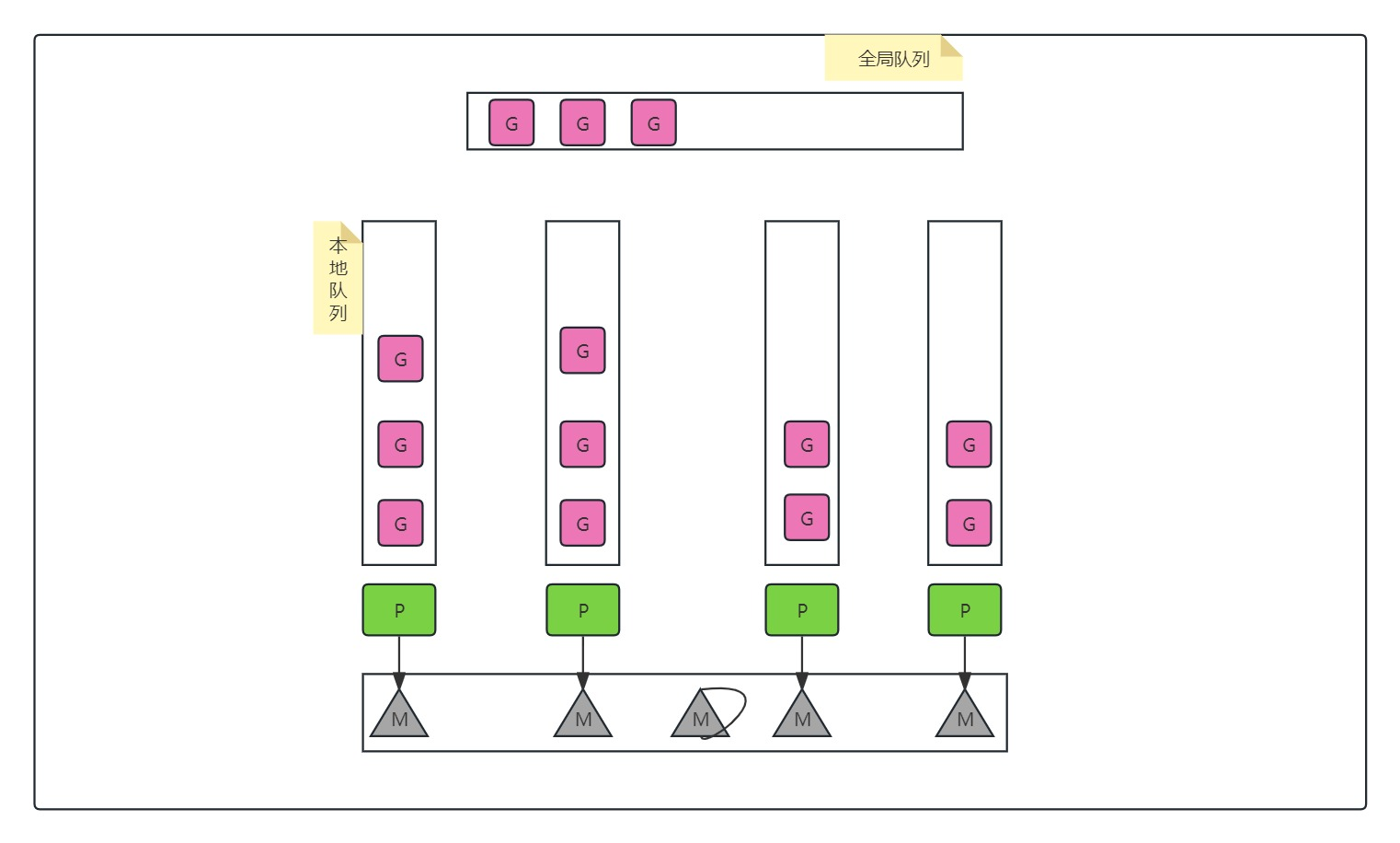
2、基本概念
- G:gorutine协程,由go关键字创建。主要作用是执行逻辑代码。
- P:Processor处理器,最多有 GOMAXPROCS个。主要作用是维护调度G。
- M: 操作系统线程的抽象结构,维护着内核线程信息,代码的实际执行者。
3、调度概述
go程序启动时,会根据GOMAXPROCS配置,创建GOMAXPROCS个P,每个P有一个本地队列,最多可放置256个G。当用go 关键字创建一个G后,G会被放入一个P的本地队列,如果P的本地队列已满,则会将本地队列的一半G移动到全局队列,供其他P消费。go程序启动后,会开始调度,寻找一个可执行的G和一个空闲的M,如果没有空闲的M,则会创建一个新的M,然后M执行G。G执行完成后,会重复调度步骤,循环调度。
4、源码解读
src/runtime/runtime2.go 简化字段后
1.G 的结构
type g struct { stack stack //栈信息 offset known to runtime/cgo m *m //关联的m current m; offset known to arm liblink atomicstatus uint32 // 协程状态 goid int64// 协程id }
2. P的结构
type p struct {
id int32
status uint32 // 状态 one of pidle/prunning/...
m muintptr // 关联的M back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32 //本地队列头
runqtail uint32 //本地队列尾
runq [256]guintptr //本地队列 长度256
runnext guintptr //下一个要执行的G
// Available G's (status == Gdead)
gFree struct { //空闲的G
gList
n int32
}
}
3. M的结构
type m struct { g0 *g //g0协程,每个M都有一个g0 负责非业务代码 跟随M一起创建 goroutine with scheduling stack // Fields not known to debuggers. curg *g //当前执行的协程 current running goroutine p puintptr //关联的P attached p for executing go code (nil if not executing go code) id int64 mOS //操作系统线程信息 }
4.1gotutine的创建
代码路径:src/runtime/proc.go
// Create a new g running fn. // Put it on the queue of g's waiting to run. // The compiler turns a go statement into a call to this. func newproc(fn *funcval) { gp := getg() pc := getcallerpc() systemstack(func() { newg := newproc1(fn, gp, pc) _p_ := getg().m.p.ptr() runqput(_p_, newg, true) if mainStarted { wakep() } }) }
如果开启了随机调度,newproc调用runqput时,next传的是true,所以有一半的可能会走retryNext逻辑,尝试将P的runnext改为新加入的G,以前的runnext指向的G放入常规队列。另一半会直接走retry逻辑,如果本地队列未满,则会放入本地队列尾部,如果满了,则会执行runqputslow
// Put g and a batch of work from local runnable queue on global queue. // Executed only by the owner P. func runqputslow(_p_ *p, gp *g, h, t uint32) bool { var batch [len(_p_.runq)/2 + 1]*g // First, grab a batch from local queue. n := t - h n = n / 2 if n != uint32(len(_p_.runq)/2) { throw("runqputslow: queue is not full") } for i := uint32(0); i < n; i++ { batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr() } if !atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume return false } batch[n] = gp if randomizeScheduler { for i := uint32(1); i <= n; i++ { j := fastrandn(i + 1) batch[i], batch[j] = batch[j], batch[i] } } // Link the goroutines. for i := uint32(0); i < n; i++ { batch[i].schedlink.set(batch[i+1]) } var q gQueue q.head.set(batch[0]) q.tail.set(batch[n]) // Now put the batch on global queue. lock(&sched.lock) globrunqputbatch(&q, int32(n+1)) unlock(&sched.lock) return true }
从本地队列取出一半数量的G,放入全局队列中
// Tries to add one more P to execute G's. 唤醒一个P来执行G // Called when a G is made runnable (newproc, ready). func wakep() { if atomic.Load(&sched.npidle) == 0 { return } // be conservative about spinning threads if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) { return } startm(nil, true) }
func startm(_p_ *p, spinning bool) {
// Disable preemption.
//
// Every owned P must have an owner that will eventually stop it in the
// event of a GC stop request. startm takes transient ownership of a P
// (either from argument or pidleget below) and transfers ownership to
// a started M, which will be responsible for performing the stop.
//
// Preemption must be disabled during this transient ownership,
// otherwise the P this is running on may enter GC stop while still
// holding the transient P, leaving that P in limbo and deadlocking the
// STW.
//
// Callers passing a non-nil P must already be in non-preemptible
// context, otherwise such preemption could occur on function entry to
// startm. Callers passing a nil P may be preemptible, so we must
// disable preemption before acquiring a P from pidleget below.
mp := acquirem()
lock(&sched.lock)
if _p_ == nil {
_p_ = pidleget()
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// The caller incremented nmspinning, but there are no idle Ps,
// so it's okay to just undo the increment and give up.
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
releasem(mp)
return
}
}
nmp := mget()
if nmp == nil {
// No M is available, we must drop sched.lock and call newm.
// However, we already own a P to assign to the M.
//
// Once sched.lock is released, another G (e.g., in a syscall),
// could find no idle P while checkdead finds a runnable G but
// no running M's because this new M hasn't started yet, thus
// throwing in an apparent deadlock.
//
// Avoid this situation by pre-allocating the ID for the new M,
// thus marking it as 'running' before we drop sched.lock. This
// new M will eventually run the scheduler to execute any
// queued G's.
id := mReserveID()
unlock(&sched.lock)
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
newm(fn, _p_, id)
// Ownership transfer of _p_ committed by start in newm.
// Preemption is now safe.
releasem(mp)
return
}
unlock(&sched.lock)
if nmp.spinning {
throw("startm: m is spinning")
}
if nmp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(_p_) {
throw("startm: p has runnable gs")
}
// The caller incremented nmspinning, so set m.spinning in the new M.
nmp.spinning = spinning
nmp.nextp.set(_p_)
notewakeup(&nmp.park)
// Ownership transfer of _p_ committed by wakeup. Preemption is now
// safe.
releasem(mp)
}
获取一个空闲的P,如果没有,则返回。获取到空闲的P后,再获取一个空闲的M,如果没有空闲M,则创建一个新的M,将M和P绑定,执行循环调度,获取G来执行。
4.2 循环调度
主要代码
// One round of scheduler: find a runnable goroutine and execute it. // Never returns. func schedule() { _g_ := getg() top: pp := _g_.m.p.ptr() pp.preempt = false checkTimers(pp, 0) var gp *g var inheritTime bool if gp == nil { // 每调度61次,检查一下全局队列是否有待执行的G,避免全局队列里面的G饿死 // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp = globrunqget(_g_.m.p.ptr(), 1) unlock(&sched.lock) } } if gp == nil { gp, inheritTime = runqget(_g_.m.p.ptr())//从本地队列获取一个可运行的G // We can see gp != nil here even if the M is spinning, // if checkTimers added a local goroutine via goready. } if gp == nil { gp, inheritTime = findrunnable() // 从其他队列获取一个可运行的G blocks until work is available } execute(gp, inheritTime)//执行G }
如果本地队列没有G了,则执行findrunnable查找可执行的G
// Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from local or global queue, poll network. func findrunnable() (gp *g, inheritTime bool) { _g_ := getg() top: _p_ := _g_.m.p.ptr() now, pollUntil, _ := checkTimers(_p_, 0) // local runq 从本地队列找可执行的G if gp, inheritTime := runqget(_p_); gp != nil { return gp, inheritTime } // global runq 从全局队列找可执行的G ,偷取数量n := sched.runqsize/gomaxprocs + 1,最多可偷取全局队列的一半, if sched.runqsize != 0 { lock(&sched.lock) gp := globrunqget(_p_, 0) unlock(&sched.lock) if gp != nil { return gp, false } } // 从netpoll 找可执行的G if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { if list := netpoll(0); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } } //M进入自旋状态,从其他p的本地队列里面偷取一半的G procs := uint32(gomaxprocs) if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) { if !_g_.m.spinning { _g_.m.spinning = true atomic.Xadd(&sched.nmspinning, 1) } gp, inheritTime, tnow, w, newWork := stealWork(now) now = tnow if gp != nil { // Successfully stole. return gp, inheritTime } if newWork { // There may be new timer or GC work; restart to // discover. goto top } if w != 0 && (pollUntil == 0 || w < pollUntil) { // Earlier timer to wait for. pollUntil = w } } }
调度的主要步骤
1、寻找一个可执行的G
2、M执行G
3、循环执行
5.思考问答
5.1GMP分别在什么时候创建,可以创建多少个?
G 在使用go关键字时创建,可以成千上万个
P 在程序启动时,根据gomaxprocs配置,创建gomaxprocs个P
M 在调度时需要空闲M来执行G,没有空闲M时则创建新的M。程序启动时,设置了sched.maxmcount = 10000,理论上最大10000个,但是也受操作系统限制
5.2 新的G创建后,有多个P,放入哪一个P的队列?
从源码分析看到,新G是放入当前G的P的队列里面的,即调用go关键字那个G关联的P。整体流程猜想如下:main函数启动第一个G,绑定P0,在main函数里面用go创建新的G1,G1放入P0,然后触发wakep函数,会唤醒新的空闲P1,P1执行findrunnable从P0偷取G1执行。G1内部再用go创建G2,G2则放入P1。
5.3 P和M如何关联?
wakep函数执行时,会找一个空闲的P和一个空闲的M关联上
5.4 M和操作系统内核线程如何关联?
M就是内核线程的逻辑描述,M结构体内存储了内核线程的信息,可以通过M调起内核线程
6、go程序整个调度过程概述
go程序启动,创建个P,创建M0,启动第一个G来执行main函数,后续新建的G加入不同P的队列,唤起空闲的P绑定M执行循环调度,调度可执行的G执行。每个M都有一个特殊的协程G0,G0不执行业务代码,只负责调度、系统调用等工作,每个G的调用栈底都有一个goexit函数,G最后都会执行goexit切换到G0,G0又会调用调度函数,以此循环。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号