
(19)python scrapy框架
安装scrapy
pycharm 建个纯python工程
settings里




环境变量设置
C:\Python27;C:\Python27\Scripts;
下载win32api
https://sourceforge.net/projects/pywin32/files/pywin32/
找到对应版本安装
import win32api
导入不报错就按成功
创建一个工程
在想要创建工程的位置点击 shift + 右键
scrapy startproject 工程名
目录
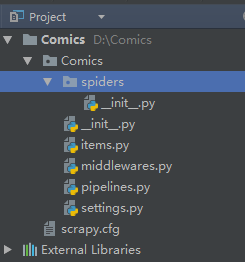
scrapy.cfg:项目的配置文件
spiders文件夹:存储爬虫编写爬虫的目录
Items.py:数据容器,用来存储提取到的数据
settings.py:项目的设置文件
快速生成一个爬虫模板
scrapy genspider 爬虫名 爬虫网址
scrapy genspider huhu http://www.huhumh.com/
它会自动在spiders的文件夹下自动生成一个 huhu.py的文件
# -*- coding: utf-8 -*- import scrapy class HuhuSpider(scrapy.Spider): name = 'huhu' allowed_domains = ['http://www.huhumh.com/'] start_urls = ['http://http://www.huhumh.com//'] def parse(self, response): pass
这个huh.py用来写爬虫的核心代码
运行爬虫程序
在pycharm里的 Terminal输入: scrapy crawl 爬虫名
scrapy crawl huhu
scrapy命令行指令
显示scrapy版本
scrapy version scrapy version -v #更全
帮助
scrapy --help
运行一个独立于Python文件的蜘蛛,无需创建一个项目
scrapy runspider myspider.py
查看有哪些当前工程下爬虫列表
scrapy list
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现
scrapy view http://www.example.com/some/page.html
些时候spider获取到的页面和普通用户看到的并不相同。 因此该命令可以用来检查spider所获取到的页面,并确认这是您所期望的。
获取给定的URL并使用工程的parse方法分析处理
scrapy parse http://www.example.com/some/page.html
如果您提供 --callback 选项,则使用spider的该方法处理,否则使用 parse 。
支持的选项:
--spider=SPIDER: 跳过自动检测spider并强制使用特定的spider--a NAME=VALUE: 设置spider的参数(可能被重复)--callbackor-c: spider中用于解析返回(response)的回调函数--pipelines: 在pipeline中处理item--rulesor-r: 使用CrawlSpider规则来发现用来解析返回(response)的回调函数--noitems: 不显示爬取到的item--nolinks: 不显示提取到的链接--nocolour: 避免使用pygments对输出着色--depthor-d: 指定跟进链接请求的层次数(默认: 1)--verboseor-v: 显示每个请求的详细信息
scrapy对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号