Postman
预备知识:django的CBV和FBV
CBV(class based view):多用,简单回顾一下
FBV(function based view):
CBV模式的简单操作:来个登陆页面吧
login.html文件内容如下:

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <form action="{% url 'login' %}" method="post"> {% csrf_token %} 用户名: <input type="text" name="username"> 密码: <input type="text" name="password"> <input type="submit"> </form> </body> </html>
url.py内容如下
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^login/', views.LoginView.as_view(),name='login'), ]
views.py
from django.shortcuts import render,HttpResponse,redirect # Create your views here. from django.views import View class LoginView(View): def get(self,request): return render(request,'login.html') def post(self,request): return HttpResponse('post')
大家还记得CBV的这个视图函数,为什么get请求就能找到类的get方法,post请求就能找到post方法,其内部有个dispatch方法来进行分发,这又怎么玩呢,看源码啦,从哪里看呢?那里先执行,就从哪里看
views.LoginView.as_view()这个东西是不是先执行啊,url接收到请求,调用了它对不对,as_view()类方法,这个类方法给你返回了一个叫view的方法,就是说这个url对应这个一个view方法,当用户访问login页面的时候是不是就是执行了view(request),大家进去看看源码吧。
然后你就可以玩dispatch方法了,看代码:
from django.shortcuts import render,HttpResponse,redirect # Create your views here. from django.views import View class LoginView(View): def dispatch(self, request, *args, **kwargs): print('something...') res = super().dispatch(request, *args, **kwargs) #注意,不用传self,为什么呢,因为super已经帮你吧self放进去啦 print('someting....') return res def get(self,request): return render(request,'login.html') def post(self,request): return HttpResponse('post')
为什么要说它呢,因为后面咱们的drf学习,就要用它啦。
摘自:http://www.ruanyifeng.com/blog/2014/05/restful_api.html
1. 什么是RESTFUl
RESTful 是目前最流行的 API 设计规范,用于 Web 数据接口的设计。
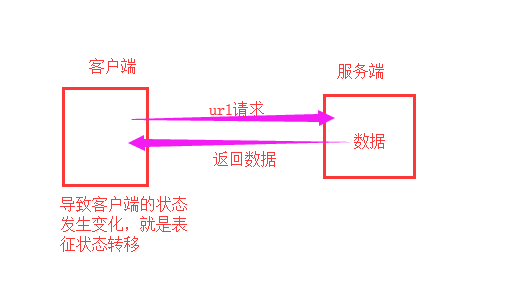
REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移”
REST从资源的角度类审视整个网络,它将分布在网络中某个节点的资源通过URL进行标识,客户端应用通过URL来获取资源的表征,获得这些表征致使这些应用转变状态
所有的数据,不过是通过网络获取的还是操作(增删改查)的数据,都是资源,将一切数据视为资源是REST区别与其他架构风格的最本质属性
对于REST这种面向资源的架构风格,有人提出一种全新的结构理念,即:面向资源架构(ROA:Resource Oriented Architecture)
另外还有其他两种,简单了解。

远程过程调用(RPC) 远程过程调用为 Web 服务提供一个分布式函数/方法接口供用户调用。这是一种较传统的方式。通常,在 WSDL 中对 RPC 接口进行定义(类似于早期的XML-RPC)。本质上,RPC 方式利用一个简单映射,把用户请求直接转化成一个特定语言编写的函数/方法。现在,该方式已不再使用。 面向服务架构(SOA) 面向服务架构现在,业界比较关注的是遵从面向服务架构(Service-oriented architecture,SOA)来构建 Web 服务。该方式中,通讯是由消息驱动,而不再是某个动作(方法调用)。这种 Web 服务也称为“面向消息的服务”。
网络应用程序,分为前端和后端两个部分。当前的发展趋势,就是前端设备层出不穷(手机、平板、桌面电脑、其他专用设备......)。
因此,必须有一种统一的机制,方便不同的前端设备与后端进行通信。这导致API构架的流行,甚至出现"API First"的设计思想。RESTful API是目前比较成熟的一套互联网应用程序的API设计理论。还有一篇《理解RESTful架构》,探讨如何理解这个概念。
表征状态转移大概图解:
2.RESTFUl API设计
2.1 使用协议
API与用户的通信协议,总是使用HTTPs协议。
2.2 使用域名
应该尽量将API部署在专用域名之下,意思就是给API专门做一个服务器。
https://api.example.com
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
https://example.org/api/
2.3 版本提示
网站的API可能一直在更新,那么应该将API的版本号放入URL。
https://api.example.com/v1/
另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。Github采用这种做法。
2.4 路径写法
路径又称"终点"(endpoint),表示API的具体网址。
在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
举例来说,有一个API提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
https://api.example.com/v1/zoos https://api.example.com/v1/animals https://api.example.com/v1/employees
2.5 HTTP动词
对于资源的具体操作类型,由HTTP动词表示,请求方式时动词,我们后端基于请求方式来分发对应的视图函数来进行逻辑处理和数据处理、提取、加工等操作,但是URL中不能出现动词。
常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性,更新部分资源的意思)。他和put用哪个都可以,没有太大的区别,我们用put方式偏多
DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词。
HEAD:获取资源的元数据。
OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的
下面是一些例子。RESTful 的核心思想就是,客户端发出的数据操作指令都是"动词 + 宾语"的结构。比如,GET /articles这个命令,GET是动词,/articles是宾语。根据 HTTP 规范,动词一律大写。
GET /zoos:列出所有动物园 POST /zoos:新建一个动物园 GET /zoos/ID:获取某个指定动物园的信息 PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息) PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息) DELETE /zoos/ID:删除某个动物园 GET /zoos/ID/animals:列出某个指定动物园的所有动物 DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
动词覆盖:
有些客户端只能使用GET和POST这两种方法。服务器必须接受POST模拟其他三个方法(PUT、PATCH、DELETE)。
这时,客户端发出的 HTTP 请求,要加上X-HTTP-Method-Override属性,告诉服务器应该使用哪一个动词,覆盖POST方法。
POST /api/Person/4 HTTP/1.1
X-HTTP-Method-Override: PUT
上面代码中,X-HTTP-Method-Override指定本次请求的方法是PUT,而不是POST。
宾语必须是名字:
宾语就是 API 的 URL,是 HTTP 动词作用的对象。它应该是名词,不能是动词。比如,/articles这个 URL 就是正确的,而下面的 URL 不是名词,所以都是错误的。
/getAllCars /createNewCar /deleteAllRedCars
既然 URL 是名词,那么应该使用复数,还是单数?
这没有统一的规定,但是常见的操作是读取一个集合,比如GET /articles(读取所有文章),这里明显应该是复数。
为了统一起见,建议都使用复数 URL,比如GET /articles/2要好于GET /article/2。

2.6 过滤信息(filtering,或称查询参数)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
?limit=10:指定返回记录的数量 ?offset=10:指定返回记录的开始位置。 ?page=2&per_page=100:指定第几页,以及每页的记录数。 ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。 ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
常见的情况是,资源需要多级分类,因此很容易写出多级的 URL,比如获取某个作者的某一类文章。
GET /authors/12/categories/2
这种 URL 不利于扩展,语义也不明确,往往要想一会,才能明白含义。
更好的做法是,除了第一级,其他级别都用查询字符串表达。
GET /authors/12?categories=2
下面是另一个例子,查询已发布的文章。你可能会设计成下面的 URL。
GET /articles/published
查询字符串的写法明显更好
GET /articles?published=true
2.7 状态码
2.7.1 状态码必须精确
客户端的每一次请求,服务器都必须给出回应。回应包括 HTTP 状态码和数据两部分。
HTTP 状态码就是一个三位数,分成五个类别。
1xx:相关信息
2xx:操作成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误
这五大类总共包含100多种状态码,覆盖了绝大部分可能遇到的情况。每一种状态码都有标准的(或者约定的)解释,客户端只需查看状态码,就可以判断出发生了什么情况,所以服务器应该返回尽可能精确的状态码。
API 不需要1xx状态码,下面介绍其他四类状态码的精确含义。
2.7.2 2xx状态码
200状态码表示操作成功,但是不同的方法可以返回更精确的状态码。
GET: 200 OK POST: 201 Created PUT: 200 OK PATCH: 200 OK DELETE: 204 No Content
上面代码中,POST返回201状态码,表示生成了新的资源;DELETE返回204状态码,表示资源已经不存在。
此外,202 Accepted状态码表示服务器已经收到请求,但还未进行处理,会在未来再处理,通常用于异步操作。下面是一个例子。
HTTP/1.1 202 Accepted { "task": { "href": "/api/company/job-management/jobs/2130040", "id": "2130040" } }
2.7.3 3xx状态码
API 用不到301状态码(永久重定向)和302状态码(暂时重定向,307也是这个含义),因为它们可以由应用级别返回,浏览器会直接跳转,API 级别可以不考虑这两种情况。
API 用到的3xx状态码,主要是303 See Other,表示参考另一个 URL。它与302和307的含义一样,也是"暂时重定向",区别在于302和307用于GET请求,而303用于POST、PUT和DELETE请求。收到303以后,浏览器不会自动跳转,而会让用户自己决定下一步怎么办。下面是一个例子。
HTTP/1.1 303 See Other
Location: /api/orders/12345
2.7.4 4xx状态码
4xx状态码表示客户端错误,主要有下面几种。
400 Bad Request:服务器不理解客户端的请求,未做任何处理。 401 Unauthorized:用户未提供身份验证凭据,或者没有通过身份验证。 403 Forbidden:用户通过了身份验证,但是不具有访问资源所需的权限。 404 Not Found:所请求的资源不存在,或不可用。 405 Method Not Allowed:用户已经通过身份验证,但是所用的 HTTP 方法不在他的权限之内。 410 Gone:所请求的资源已从这个地址转移,不再可用。 415 Unsupported Media Type:客户端要求的返回格式不支持。比如,API 只能返回 JSON 格式,但是客户端要求返回 XML 格式。 422 Unprocessable Entity :客户端上传的附件无法处理,导致请求失败。 429 Too Many Requests:客户端的请求次数超过限额。
2.7.5 5xx状态码
5xx状态码表示服务端错误。一般来说,API 不会向用户透露服务器的详细信息,所以只要两个状态码就够了。
500 Internal Server Error:客户端请求有效,服务器处理时发生了意外。
503 Service Unavailable:服务器无法处理请求,一般用于网站维护状态。
总结一下常用状态码及对应的描述
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。301状态码(永久重定向)302状态码(暂时重定向,307也是这个含义) 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。 更多看这里:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
2.8 服务器响应
2.8.1 响应数据格式
API 返回的数据格式,不应该是纯文本,而应该是一个 JSON 对象,因为这样才能返回标准的结构化数据。所以,服务器回应的 HTTP 头的Content-Type属性要设为application/json。
客户端请求时,也要明确告诉服务器,可以接受 JSON 格式,即请求的 HTTP 头的ACCEPT属性也要设成application/json。下面是一个例子。
GET /orders/2 HTTP/1.1
Accept: application/json
2.8.2 发生错误时的响应
发生错误时不要响应200状态码,有一种不恰当的做法是,即使发生错误,也返回200状态码,把错误信息放在数据体里面,就像下面这样。
HTTP/1.1 200 OK Content-Type: application/json { "status": "failure", "data": { "error": "Expected at least two items in list." } }
上面代码中,解析数据体以后,才能得知操作失败。
这张做法实际上取消了状态码,这是完全不可取的。正确的做法是,状态码反映发生的错误,具体的错误信息放在数据体里面返回。下面是一个例子。
HTTP/1.1 400 Bad Request Content-Type: application/json { "error": "Invalid payoad.", "detail": { "surname": "This field is required." } }
2.8.3 响应结果
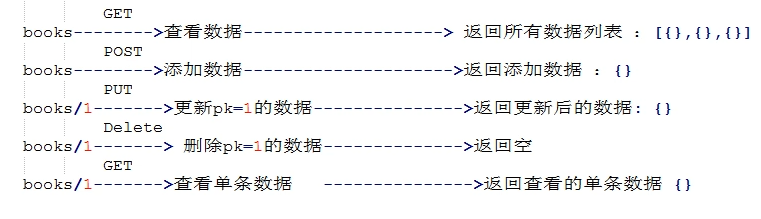
针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组),一般是[{"id":1,"name":"a",},{"id":2,name:"b"},]这种类型 GET /collection/resource:返回单个资源对象, 一般是查看的单条数据 {"id":1,"name":'a'} POST /collection:返回新生成的资源对象 , 一般是返回新添加的数据信息, 格式一般是{} PUT /collection/resource:返回完整的资源对象 一般时返回更新后的数据,{} PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档 一般返回一个空字符串
例如:
2.9 Hypermedia API,提供链接
RESTful API最好做到Hypermedia,即返回结果中提供链接,API 的使用者未必知道,URL 是怎么设计的。一个解决方法就是,在回应中,给出相关链接,便于下一步操作。这样的话,用户只要记住一个 URL,就可以发现其他的 URL。这种方法叫做 HATEOAS。
举例来说,GitHub 的 API 都在 api.github.com 这个域名。访问它,就可以得到其他 URL。
{ ... "feeds_url": "https://api.github.com/feeds", "followers_url": "https://api.github.com/user/followers", "following_url": "https://api.github.com/user/following{/target}", "gists_url": "https://api.github.com/gists{/gist_id}", "hub_url": "https://api.github.com/hub", ... }
上面的回应中,挑一个 URL 访问,又可以得到别的 URL。对于用户来说,不需要记住 URL 设计,只要从 api.github.com 一步步查找就可以了。
HATEOAS 的格式没有统一规定,上面例子中,GitHub 将它们与其他属性放在一起。更好的做法应该是,将相关链接与其他属性分开。
HTTP/1.1 200 OK Content-Type: application/json { "status": "In progress", "links": {[ { "rel":"cancel", "method": "delete", "href":"/api/status/12345" } , { "rel":"edit", "method": "put", "href":"/api/status/12345" } ]} }
再比如:当用户向api.example.com的根目录发出请求,会得到这样一个文档。
{"link": {
"rel": "collection https://www.example.com/zoos",
"href": "https://api.example.com/zoos",
"title": "List of zoos",
"type": "application/vnd.yourformat+json"
}}
上面代码表示,文档中有一个links属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型。
2.10 其他
(1)API的身份认证应该使用OAuth 2.0框架。
(2)服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
drf是django发展来的一个符合restful接口规范的一个东西,啥东西呢,就是django的一个app,还记得app是啥不。DRF官网地址,但是大家记住一句话,即便是没有这drf,我们照样能做前后端分离的项目,自己做规范的数据接口,返回json数据,都是没问题的昂,那为什么还用drf啊,这个更nb。
在官网中我们看一下这里:
首先下载安装,django是必须要的,不过咱们的django已经下载好了,如果没下载好,那么pip install django,执行一下:
pip install django pip install djangorestframework //执行这句话,下载drf # Set up a new project with a single application django-admin startproject tutorial . # Note the trailing '.' character cd tutorial django-admin startapp quickstart cd ..
1.先基于djangoCBV,不用DRF来写个接口,看看效果
好,接下来我们创建一个django项目,models中创建一个表,添加一些数据,然后写一个数据接口来获取一下这些数据,返回json数据类型,按照我们CBV的模式来写,但是下面还没有用到我们的drf昂,只是告诉大家,没有drf,你也能做。
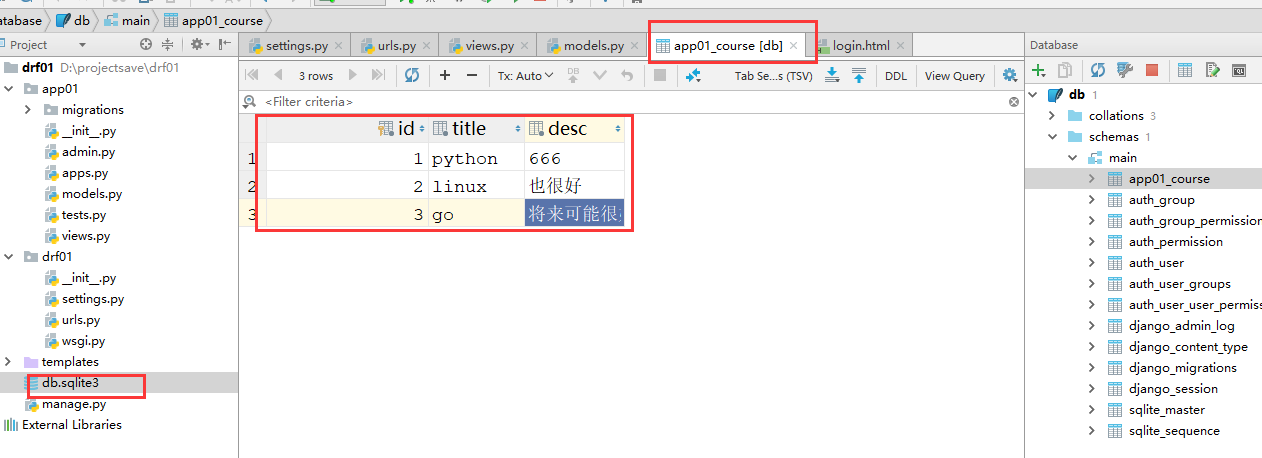
views.py文件内容如下:
from django.shortcuts import render,HttpResponse,redirect import json # Create your views here. from django.views import View from app01 import models class CourseView(View): def get(self,request): #拿到queryset类型的数据,要加工成[{},{}]这种数据类型 course_obj_list = models.Course.objects.all() ret = [] for course_obj in course_obj_list: ret.append({ "title":course_obj.title, "desc":course_obj.desc, }) return HttpResponse(json.dumps(ret,ensure_ascii=False)) #ensure_ascii=False是告诉json不要对中文进行编码,不然返回给前端的数据中如果有中文的话会被编码成unicode类型的数据,导致前端看不到中文
urls.py内容如下:
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ #url(r'^admin/', admin.site.urls), url(r'^courses/', views.CourseView.as_view(),name='courses'), #接口就写好啦 ]
然后启动项目,在浏览器中一访问,就看到了我们后端返回的json数据:

有人就又说了,我们这么写也ok啊,要drf干嘛,上面这个例子是个简单的例子,数据简单、逻辑简单,你这样写当然看着没有问题啦,但是数据量很大,结构很复杂的时候,你这样写的时候就头疼了。
所以上面这个例子你就作为了解吧,我们玩一下drf。
玩DRF之前,我们先说一下我们DRF中有哪些内容:
咱们玩下面10个组件:
a.APIView (*****) b.序列化组件 (*****) c.试图类(mixin) (*****) d.认证组件 (*****) e.权限组件 f.频率组件 g.分页组件 h.解析器组件 (*****) i.相应其组件 j.url控制器
2.基于DRF来写接口
2.1 APIView组件
在我们的视图中,通过CBV来写视图的时候,继承APIView,url不变,还是上面那个,通过浏览器访问,照样能够看到我们返回的数据,
views.py内容如下:
from django.shortcuts import render,HttpResponse,redirect import json from django.views import View from app01 import models #引入APIView,APIView是继承的django的View,也就是APIView在View的基础上添加了一些其他的功能 from rest_framework.views import APIView class CourseView(APIView): def get(self,request): course_obj_list = models.Course.objects.all() ret = [] for course_obj in course_obj_list: ret.append({ "title":course_obj.title, "desc":course_obj.desc, }) return HttpResponse(json.dumps(ret, ensure_ascii=False))
urls.py内容如下:
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^courses/', views.CourseView.as_view(),name='courses'), ]
页面访问url效果:

照样拿到了数据,那么怎么回事儿呢,我们看源码,知道一下APIView的流程就行。
2.2 解析器组件
知识准备,还记得一个叫做contentType的http请求头的东西吗?回想一下。
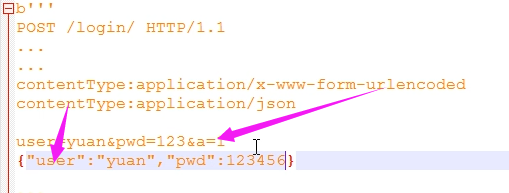
后端根据contentType的类型来找到对应的解析数据的方法来解析数据,提取数据
但是django没有内置的自动解开json数据类型的方法,那么只能去request.body里面拿原始的bytes类型的数据,然后自己解,其实很简单,但是django没有,可能是早先没有考虑到。

django自动通过contentType来解析数据的那些方法就叫做django的解析器,能解的是urlencode和文件的那个mutipart/form-data类型的数据,然后将数据放到了request.POST方法里面。
def post(self,request): print(request.POST) print(type(request)) #通过这个对象的类型(类对象),找到它的源码看看 return HttpResponse('POST')
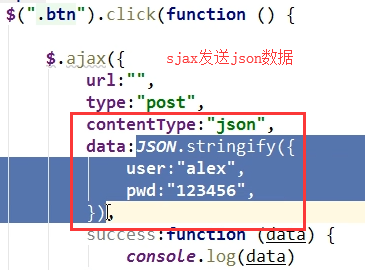
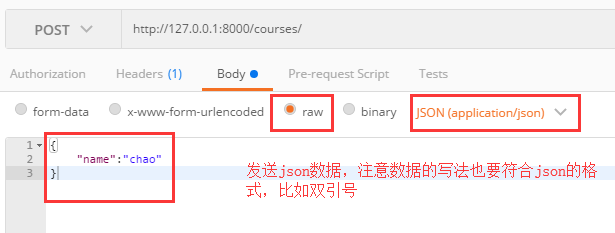
而DRF通过自己的解析器,帮我们给request里面封装了一个request.data属性,获取请求体里面的数据,然后解析,并且这个解析器基本上能够解析所有的数据类型,包括django不能自动解析的json数据类型,我们通过Postman(关于Postman工具的使用,看下面那个章节)来调试一下,看看效果
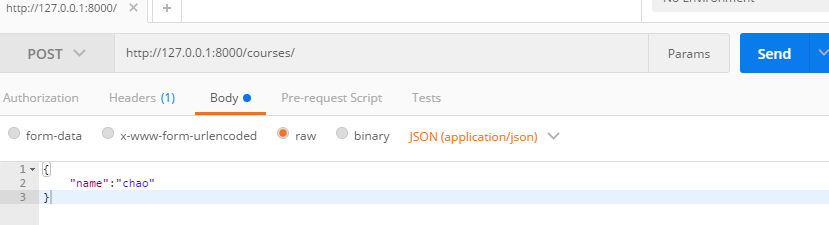
def post(self,request): print(request.data) #打印结果是:{'name': 'chao'} return HttpResponse('POST')
我们接着往下看:首先我们给我们的试图类添加一个类变量,这些类变量是用来控制我们视图类里面的各个组件
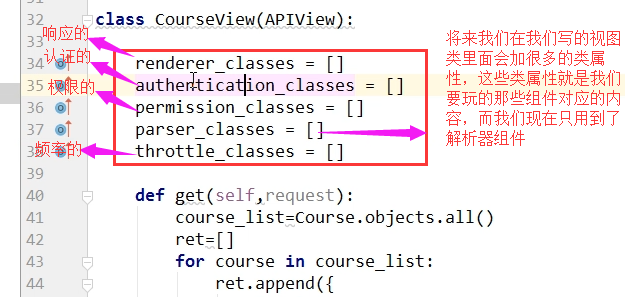
看一下代码:
from django.shortcuts import render,HttpResponse,redirect import json from django.views import View from app01 import models from rest_framework.views import APIView #导入解析器 from rest_framework.parsers import JSONParser,FormParser,MulTiPartParser # JSONParser:解析json数据的额 # FormParser:解析urlencoded数据的 # FileUploadParser:解析文件数据的 class CourseView(APIView): #写一个类属性,名字必须是parser_classes parser_classes = [JSONParser,] #里面存放我们上面导入的那几个解析器,如果我们里面写了一个JSONParser,那么解析器只能解析前端发送过来的json数据,存放到request.data里面,可以通过postman测试一下看看效果,为什么?看源码吧 def get(self,request): course_obj_list = models.Course.objects.all() ret = [] for course_obj in course_obj_list: ret.append({ "title":course_obj.title, "desc":course_obj.desc, }) return HttpResponse(json.dumps(ret, ensure_ascii=False)) def post(self,request):
print('ok') #你会发现,即便是发送的数据类型不对,post方法也走了,但是request.data没有东西,那么肯定是它出了问题 print(request.data) #request.data对我们的数据进行解析的,那么说明data不是一个变量,而是一个属性方法,还记得属性方法吗 return HttpResponse('POST')
源码看着比较复杂,这里我就不列举了,反正你要知道的是,我们的解析器的查找使用顺序是:
自己写的类里面的parser_classes = [JSONParser,]---->然后找settings中的----->然后找默认的,只要找到,就用了。其他的组件也都是这么个顺序,所以其他的咱们就不看了。
Postman是一个模拟发送请求并获得响应结果的工具,不用这个工具的时候,我们写web项目,调试接口返回数据的时候,是不是都要启动项目,通过浏览器访问,然后查看数据啊,有了这个工具我们就可以不用启动浏览器来,通过这个工具就能进行调试,首先下载安装
下载地址:https://www.getpostman.com/downloads/
安装,然后使用,直接看图吧,一看就明白:
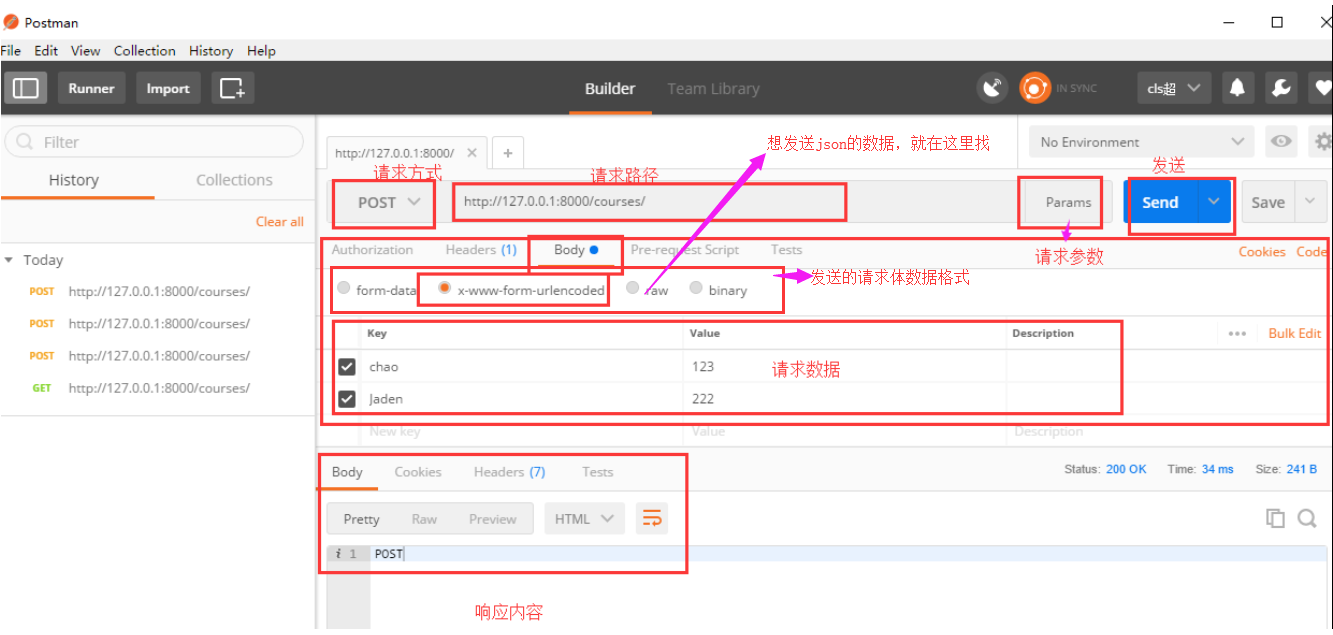
首先按照restful规范咱们创建一些api接口,按照下面这些形式写吧:
Courses --- GET ---> 查看数据----->返回所有数据列表[{},{},]
Courses--- POST --->添加数据 -----> 返回添加的数据{ }
courses/1 ---PUT---> 更新pk=1的数据 ----->返回更新后的数据{ }
courses/1 --- DELETE---> 删除pk=1的数据 -----> 返回空
courses/1 --- GET --->查看单条数据 -----> 返回单条数据 { }
这样,我们先看一个drf给我们提供的一个类似于Postman功能的页面,首先我们创建一个django项目,创建一个Course表,然后添加一些数据,然后按照下面的步骤操作,
第一步:引入drf的Response对象
from django.shortcuts import render,HttpResponse,redirect import json from django.views import View from app01 import models from rest_framework.views import APIView #引用drf提供的Response对象 from rest_framework.response import Response
#写我们的CBV视图 class CourseView(APIView): #返回所有的Course数据 def get(self,request): course_obj_list = models.Course.objects.all() ret = [] for course_obj in course_obj_list: ret.append({ "title":course_obj.title, "desc":course_obj.desc, }) # return HttpResponse(json.dumps(ret, ensure_ascii=False)) return Response(json.dumps(ret, ensure_ascii=False)) #这里使用Response来返回消息 def post(self,request): print(request.data) return HttpResponse('POST')
第二步:配置App,在我们的settings配置文件中配置
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01.apps.App01Config', 'rest_framework', #将它注册成App ]
第三步,配置我们的路由
""" from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^courses/', views.CourseView.as_view(),name='courses'), ]
第四步:启动项目,通过浏览器访问我们的路由(必须是浏览器访问才能看到对应的功能),看效果:
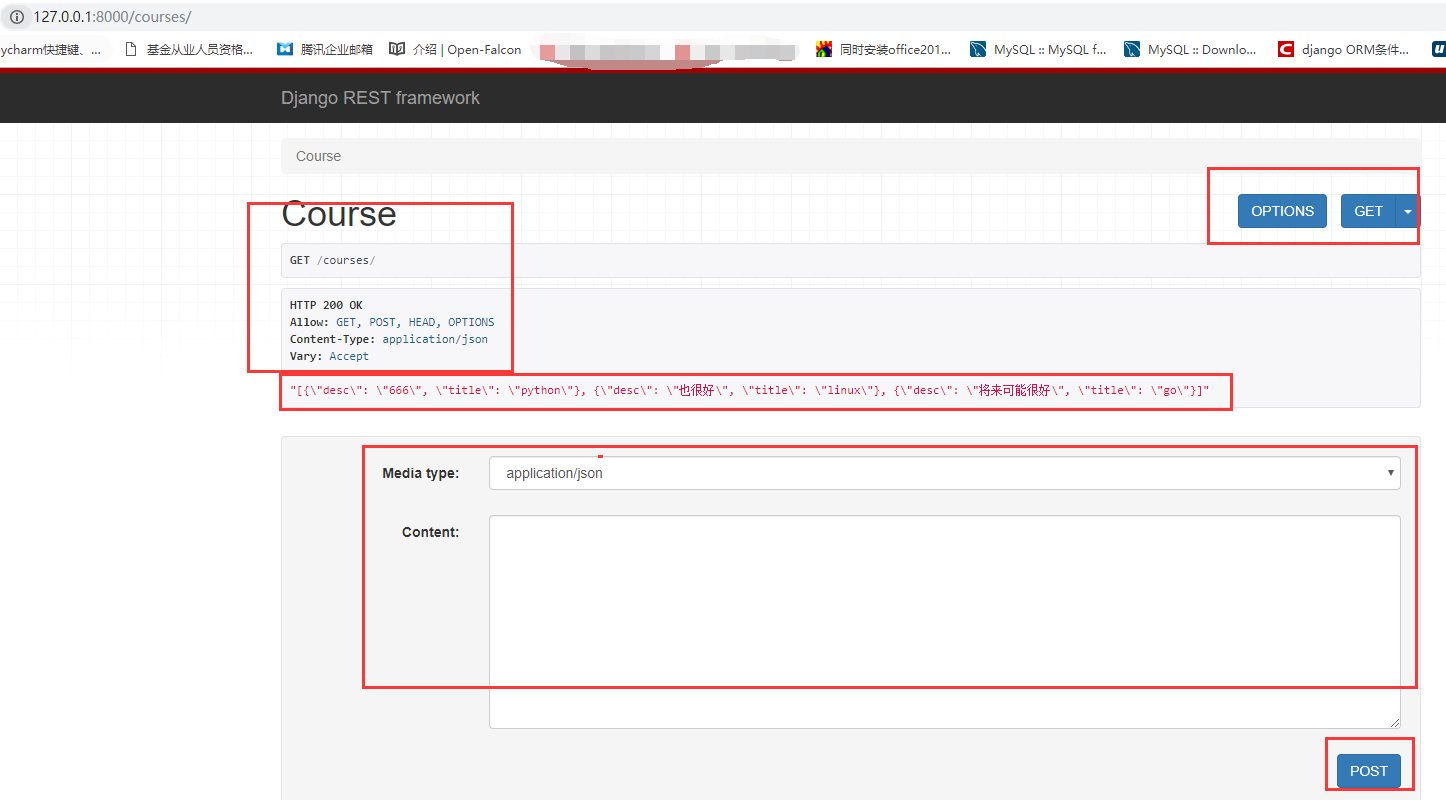
这里面我们可以发送不同类型的请求,看到对应的返回数据,类似于Postman,但是没有Postman好用,所以以后调试我们还是用Postman工具,但是我们知道一下昂。
上面的数据,我们通过json自己进行的序列化,其实django也给我们提供了一个简单的序列化组件,看用法:
from django.shortcuts import render,HttpResponse,redirect import json from django.views import View from app01 import models from rest_framework.views import APIView from django.core.serializers import serialize #django的序列化组件,不是我们要学的drf的序列化组件昂 #不用json自己来序列化了,太麻烦,我们使用drf提供的序列化组件 from rest_framework.response import Response class CourseView(APIView): def get(self,request): course_obj_list = models.Course.objects.all() # ret = [] # for course_obj in course_obj_list: # ret.append({ # "title":course_obj.title, # "desc":course_obj.desc, # }) # return HttpResponse(json.dumps(ret, ensure_ascii=False)) # return Response(json.dumps(ret, ensure_ascii=False) se_data = serialize('json',course_obj_list,ensure_ascii=False) print(se_data)#也拿到了序列化之后的数据,简洁很多 #[{"model": "app01.course", "pk": 1, "fields": {"title": "python", "desc": "666"}}, {"model": "app01.course", "pk": 2, "fields": {"title": "linux", "desc": "\u4e5f\u5f88\u597d"}}, {"model": "app01.course", "pk": 3, "fields": {"title": "go", "desc": "\u5c06\u6765\u53ef\u80fd\u5f88\u597d"}}] return Response(se_data)
那么我们知道了两个序列化方式了,这个序列化是不是就简单很多啊,但是drf给我们做了一个更牛逼的序列化组件,功能更强大,而且不仅仅能做序列化,还能做其他的事情,所以呢,做api的时候,我们还是用drf提供的序列化组件。
json序列化时间日期格式的时候的方法
接下来重点到了,我们玩一下drf提供的数据序列化组件:
1.我们通过GET方法,来查看所有的Course数据。
from django.shortcuts import render,HttpResponse,redirect import json from django.views import View from app01 import models from rest_framework.views import APIView from django.core.serializers import serialize #django的序列化组件,不是我们要学的drf的序列化组件昂
#from rest_framework import status #返回指定状态码的时候会用到
#return Response(se_data,status=status=HTTP_400_BAD_REQUEST)
#或者这种方式返回来指定状态码:return JsonResponse(serializer.data, status=201)
from rest_framework.response import Response # 序列化方式3,1.引入drf序列化组件 from rest_framework import serializers # 2.首先实例化一个类,继承drf的serializers.Serializer,类似于我们的form组件和models的用法 class CourseSerializers(serializers.Serializer): #这里面也要写对应的字段,你写了哪些字段,就会对哪些字段的数据进行序列化,没有被序列化的字段,不会有返回数据,你可以注释掉一个,然后看返回的数据是啥 title = serializers.CharField(max_length=32,required=False) #序列化的时候还能校验字段 desc = serializers.CharField(max_length=32) class CourseView(APIView): def get(self,request): course_obj_list = models.Course.objects.all() # 3.使用我们创建的序列化类 cs = CourseSerializers(course_obj_list, many=True) # 序列化多个对象的时候,需要些many=True参数 #4.通过返回对象的data属性就能拿到序列化之后的数据 se_data = cs.data print(se_data) #[OrderedDict([('title', 'python'), ('desc', '666')]), OrderedDict([('title', 'linux'), ('desc', '也很好')]), OrderedDict([('title', 'go'), ('desc', '将来可能很好')])] 列表嵌套的有序字典。 #还记得创建字典的另外一种写法吗?这个没啥用昂,给大家回顾一下之前的知识 # d1 = {'name':'chao'} # d2 = dict([('name','chao'),('age',18)]) # print(d1) #{'name': 'chao'} # print(d2) #{'age': 18, 'name': 'chao'} # # 有序字典 # from collections import OrderedDict # d3 = OrderedDict([('name','Jaden'),('age',22)]) # print(d3) #OrderedDict([('name', 'Jaden'), ('age', 22)]) return Response(se_data) #drf的Response如果返回的是drf序列化之后的数据,那么客户端拿到的是一个有格式的数据,不再是一行显示了
看效果:
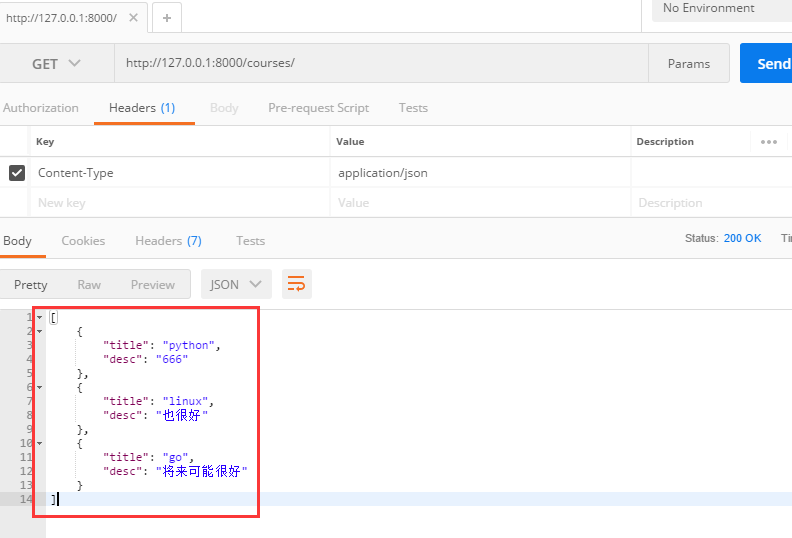
2.通过POST方法来添加一条数据:
from django.shortcuts import render,HttpResponse,redirect from django.views import View from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers class CourseSerializers(serializers.Serializer): title = serializers.CharField(max_length=32) desc = serializers.CharField(max_length=32) class CourseView(APIView): def get(self,request): course_obj_list = models.Course.objects.all() cs = CourseSerializers(course_obj_list, many=True) se_data = cs.data return Response(se_data) def post(self,request): # print(request.data) #{'desc': 'java也挺好', 'title': 'java'} #发送过来的数据是不是要进行验证啊,drf的序列化组件还能校验数据 cs = CourseSerializers(data=request.data,many=False) #注意必须是data=这种关键字参数,注意,验证单条数据的时候写上many=False参数,而且我们还要序列化这个数据,因为我们要给客户端返回这个数据 # print(cs.is_valid()) #True ,如果少数据,得到的是False if cs.is_valid(): print(cs.data) models.Course.objects.create(**cs.data)#添加数据 return Response(cs.data) #按照post添加数据的api规则,咱们要返回正确的数据 else: # 假如客户端发送过来的数据是这样的,少title的数据 # { # "desc": "java也挺好" # } cs_errors = cs.errors # print(cs_errors) #{'title': ['This field is required.']} return Response(cs_errors) # postman上我们看到的效果是下面这样的 # { # "title": [ # "This field is required." # ] # }
然后添加一些数据,好,接下来我们玩一些有关联关系的表
class Author(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) age=models.IntegerField() class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True) birthday=models.DateField() telephone=models.BigIntegerField() addr=models.CharField( max_length=64) class Publish(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) city=models.CharField( max_length=32) email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True) title = models.CharField( max_length=32) publishDate=models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2) publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #多对一到Publish表 authors=models.ManyToManyField(to='Author',) #多对多到Author表
看序列化代码:
from django.shortcuts import render,HttpResponse,redirect from django.views import View from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers class BookSerializers(serializers.Serializer): #我们先序列化写两个字段的数据,别忘了这里面的字段和model表中的字段变量名要一样 title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) #一对多的处理 # publish = serializers.CharField(max_length=32) #返回对象 publish_email = serializers.CharField(max_length=32, source='publish.email') # source指定返回的多对一的那个publish对象的email数据,并且我们现在找到书籍的email,所以前面的字段名称就可以不和你的publish对应好了,随便取名字 publish_name = serializers.CharField(max_length=32, source='publish.name') # source指定返回的多对一的那个publish对象的其他字段数据,可以接着写字段,也就是说关联的所有的字段的数据都可以写在这里进行序列化 #对多对的处理 # authors = serializers.CharField(max_length=32) #bookobj.authors拿到的类似于一个models.Authors.object,打印的时候这是个None # authors = serializers.CharField(max_length=32,source="authors.all") #这样写返回的是queryset类型的数据,这样给前端肯定是不行的,所以按照下面的方法写 authors = serializers.SerializerMethodField() #序列化方法字段,专门给多对多字段用的,然后下面定义一个方法,方法名称写法是这样的get_字段名,名字必须是这样 def get_authors(self,obj): #参数写一个obj,这个obj是一个一个的书籍对象,然后我们通过书籍对象来返回对应的数据 # author_list_values = obj.authors.all().values() #返回这样类型的数据也行,那么具体你要返回什么结构的数据,需要和前端人员沟通清楚,然后这里对数据进行加工 #假如加工成的数据是这种类型的[ {},{} ],就可以按照下面的逻辑来写,我简单写的,肯定有更好的逻辑来加工这些数据 author_list_values = [] author_dict = {} author_list = obj.authors.all() for i in author_list: author_dict['name'] = i.name author_list_values.append(author_dict) return author_list_values class BookView(APIView): def get(self,request): book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data) def post(self,request): pass
其实serializer在内部就做了这点事儿,伪代码昂。
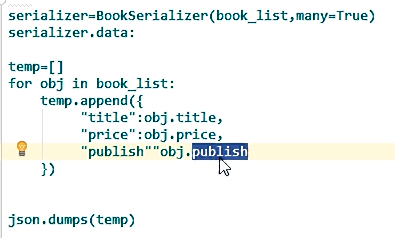
urls.py是这样写的:
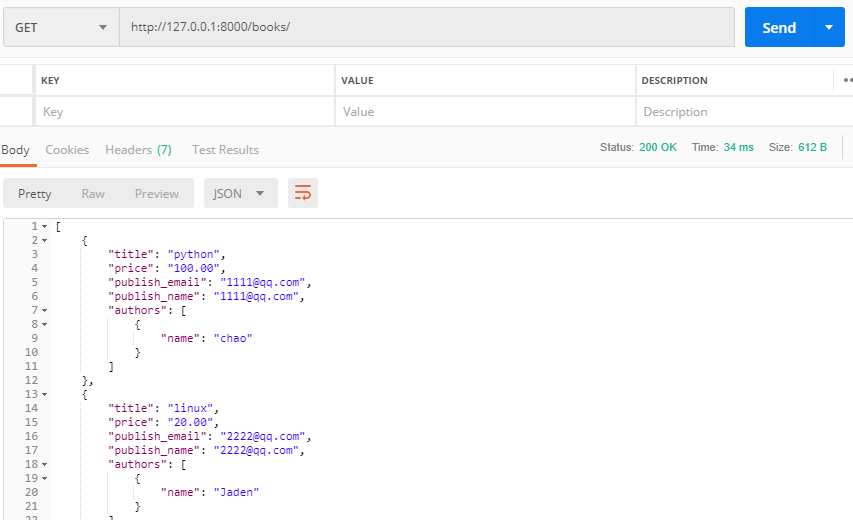
urlpatterns = [ #url(r'^admin/', admin.site.urls), #做一些针对书籍表的接口 url(r'^books/', views.BookView.as_view(),), ]
然后看Postman返回的数据:
那么我们就能够完成各种数据的序列化了,但是你会发现,这样写太累啦,这只是一张表啊,要是上百张表咋整啊,所以还有一个更简单的方式(类似于form和modelform的区别)。
我们使用ModelSerializer,看代码:
#ModelSerializer class BookSerializers(serializers.ModelSerializer): class Meta: model=models.Book # fields=['title','price','publish','authors'] fields = "__all__" # 如果直接写all,你拿到的数据是下面这样的,但是如果人家前端和你要的作者的id和名字,你是不是要处理一下啦 # [ # { # "nid": 3, # "title": "go", # "publishDate": null, # "price": "122.00", # "publish": 2, # "authors": [ # 2, # 1 # ] # } # ] #那么没办法,只能自己再进行加工处理了,按照之前的方式 authors = serializers.SerializerMethodField() def get_authors(self,obj): author_list_values = [] author_dict = {} author_list = obj.authors.all() for i in author_list: author_dict['id'] = i.pk author_dict['name'] = i.name author_list_values.append(author_dict) return author_list_values #这个数据就会覆盖上面的序列化的authors字段的数据 # 那么前端拿到的数据就这样了 # [ # { # "nid": 3, # "authors": [ # { # "name": "chao", # "id": 1 # }, # { # "name": "chao", # "id": 1 # } # ], # "title": "go", # "publishDate": null, # "price": "122.00", # "publish": 2 # } # ] # 那如果一对多关系的那个publish,前端想要的数据是名字怎么办呢?还是老办法,source # publish_name = serializers.CharField(max_length=32, source='publish.name')#但是你会发现序列化之后的数据有个publish:1对应个id值,如果我不想要他怎么办,那么可以起个相同的变量名来覆盖它,比如下面的写法 publish = serializers.CharField(max_length=32, source='publish.name') class BookView(APIView): def get(self,request): book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data) def post(self,request): pass
上面我们完成了get请求来查看所有的书籍信息,接下来我们玩一个post请求添加一条book数据,直接上代码吧:
class BookSerializers(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" # 注意先把下面这些注释掉,不然由于get和post请求我们用的都是这个序列化组件,会出现多对多变量冲突的问题,所以一般都将读操作和写操作分成两个序列化组件来写 # authors = serializers.SerializerMethodField() #也可以用来处理一对多的关系字段 # def get_authors(self,obj): # author_list_values = [] # author_dict = {} # author_list = obj.authors.all() # for i in author_list: # author_dict['id'] = i.pk # author_dict['name'] = i.name # author_list_values.append(author_dict) # return author_list_values # publish = serializers.CharField(max_length=32, source='publish.name') class BookView(APIView): def get(self,request): book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data) def post(self,request): b_serializer = BookSerializers(data=request.data,many=False) if b_serializer.is_valid(): print('xxxx') b_serializer.save() #因为这个序列化器我们用的ModelSerializer,并且在BookSerializers类中我们指定了序列化的哪个表,所以直接save,它就知道我们要将数据保存到哪张表中,其实这句话执行的就是个create操作。 return Response(b_serializer.data) #b_serializer.data这就是个字典数据 else: return Response(b_serializer.errors)
上面我们完成了GET和POST请求的接口写法,下面我们来完成PUT、DELETE、GET查看单条数据的几个接口。

#一个读序列化组件,一个写序列化组件 class BookSerializers1(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" def create(self, validated_data): print(validated_data) #{'publishDate': datetime.date(2012, 12, 12), 'publish': <Publish: Publish object>, 'authors': [<Author: Author object>, <Author: Author object>], 'title': '老酒3', 'price': Decimal('15.00')} authors = validated_data.pop('authors') obj = models.Book.objects.create(**validated_data) obj.authors.add(*authors) return obj class BookSerializers2(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" authors = serializers.SerializerMethodField() def get_authors(self,obj): print('sssss') author_list_values = [] author_dict = {} author_list = obj.authors.all() for i in author_list: author_dict['id'] = i.pk author_dict['name'] = i.name author_list_values.append(author_dict) return author_list_values publish = serializers.CharField(max_length=32, source='publish.name') class BookView(APIView): def get(self,request): book_obj_list = models.Book.objects.all() s_books = BookSerializers2(book_obj_list,many=True) return Response(s_books.data) def post(self,request): b_serializer = BookSerializers1(data=request.data,many=False) if b_serializer.is_valid(): print('xxxx') b_serializer.save() return Response(b_serializer.data) else: return Response(b_serializer.errors)
urls.py内容如下:
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), # url(r'^courses/', views.CourseView.as_view()), #做一些针对书籍表的接口 #GET和POST接口的url url(r'^books/$', views.BookView.as_view(),), #别忘了$符号结尾 #PUT、DELETE、GET请求接口 url(r'^books/(\d+)/', views.SBookView.as_view(),), ]
views.py代码如下:
from django.shortcuts import render,HttpResponse,redirect from django.views import View from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers class BookSerializers(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" class BookView(APIView): def get(self,request): ''' 查看所有书籍 :param request: :return: ''' book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data) def post(self,request): ''' 添加一条数据 :param request: :return: ''' b_serializer = BookSerializers(data=request.data,many=False) if b_serializer.is_valid(): b_serializer.save() return Response(b_serializer.data) else: return Response(b_serializer.errors) #因为更新一条数据,删除一条数据,获取一条数据,都有个单独的参数(获取一条数据的,一般是id,所以我将put、delete、get写到了一个视图类里面,也就是说结合上面那个BookView视图类,完成了我们的那些接口) class SBookView(APIView): def get(self,request,id): ''' 获取单条数据 :param request: :param id: :return: ''' book_obj = models.Book.objects.get(pk=id)#获取这条数据对象 #接下来序列化单个model对象,序列化单个对象返回的是一个字典结构 {},序列化多个对象返回的是[{},{}]这种结构 book_serializer = BookSerializers(book_obj,many=False) return Response(book_serializer.data) def put(self,request,id): ''' 更新一条数据 :param request:request.data更新提交过来的数据 :param id: :return: ''' book_obj = models.Book.objects.get(pk=id) b_s = BookSerializers(data=request.data,instance=book_obj,many=False) #别忘了写instance,由于我们使用的ModelSerializer,所以前端提交过来的数据必须是所有字段的数据,当然id字段不用 if b_s.is_valid(): b_s.save() #翻译成的就是update操作 return Response(b_s.data) #接口规范要求咱们要返回更新后的数据 else: return Response(b_s.errors) def delete(self,request,id): ''' 删除一条数据 :param request: :param id: :return: ''' book_obj = models.Book.objects.get(pk=id).delete() return Response("") #别忘了接口规范说最好返回一个空
好,五个接口写完,咱们的序列化组件就算是讲完了,别忘了看这一节最后的那个坑。
重写save的create方法
class BookSerializers(serializers.ModelSerializer): class Meta: model=Book fields="__all__" # exclude = ['authors',] # depth=1 def create(self, validated_data): authors = validated_data.pop('authors') obj = Book.objects.create(**validated_data) obj.authors.add(*authors) return obj
超链接API,Hyperlinked
class BookSerializers(serializers.ModelSerializer): publish= serializers.HyperlinkedIdentityField( view_name='publish_detail', lookup_field="publish_id", lookup_url_kwarg="pk") class Meta: model=Book fields="__all__" #depth=1
serializer的属性和方法:
1.save() 在调用serializer.save()时,会创建或者更新一个Model实例(调用create()或update()创建),具体根据序列化类的实现而定,如: 2.create()、update() Serializer中的create()和update()方法用于创建生成一个Model实例,在使用Serializer时,如果要保存反序列化后的实例到数据库,则必须要实现这两方法之一,生成的实例则作为save()返回值返回。方法属性validated_data表示校验的传入数据,可以在自己定义的序列化类中重写这两个方法。 3. is_valid() 当反序列化时,在调用Serializer.save()之前必须要使用is_valid()方法进行校验,如果校验成功返回True,失败则返回False,同时会将错误信息保存到serializer.errors属性中。 4.data serializer.data中保存了序列化后的数据。 5.errors 当serializer.is_valid()进行校验后,如果校验失败,则将错误信息保存到serializer.errors属性中。
serializer的Field:
1.CharField 对应models.CharField,同时如果指定长度,还会负责校验文本长度。 max_length:最大长度; min_length:最小长度; allow_blank=True:表示允许将空串做为有效值,默认False; 2.EmailField 对应models.EmailField,验证是否是有效email地址。 3.IntegerField 对应models.IntegerField,代表整数类型 4.FloatField 对应models.FloatField,代表浮点数类型 5.DateTimeField 对应models.DateTimeField,代表时间和日期类型。 format='YYYY-MM-DD hh:mm':指定datetime输出格式,默认为DATETIME_FORMAT值。 需要注意,如果在 ModelSerializer 和HyperlinkedModelSerializer中如果models.DateTimeField带有auto_now=True或者auto_add_now=True,则对应的serializers.DateTimeField中将默认使用属性read_only=True,如果不想使用此行为,需要显示对该字段进行声明: class CommentSerializer(serializers.ModelSerializer): created = serializers.DateTimeField() class Meta: model = Comment 6.FileField 对应models.FileField,代表一个文件,负责文件校验。 max_length:文件名最大长度; allow_empty_file:是否允许为空文件; 7.ImageField 对应models.ImageField,代表一个图片,负责校验图片格式是否正确。 max_length:图片名最大长度; allow_empty_file:是否允许为空文件; 如果要进行图片处理,推荐安装Pillow: pip install Pillow 8.HiddenField 这是serializers中特有的Field,它不根据用户提交获取值,而是从默认值或可调用的值中获取其值。一种常见的使用场景就是在Model中存在user_id作为外键,在用户提交时,不允许提交user_id,但user_id在定义Model时又是必须字段,这种情况下就可以使用HiddenField提供一个默认值: class LeavingMessageSerializer(serializers.Serializer): user = serializers.HiddenField( default=serializers.CurrentUserDefault() )
serializer的公共参数:
所谓公共参数,是指对于所有的serializers.<FieldName>都可以接受的参数。以下是常见的一些公共参数。 1.read_only read_only=True表示该字段为只读字段,即对应字段只用于序列化时(输出),而在反序列化时(创建对象)不使用该字段。默认值为False。 2.write_only write_only=True表示该字段为只写字段,和read_only相反,即对应字段只用于更新或创建新的Model时,而在序列化时不使用,即不会输出给用户。默认值为False。 3.required required=False表示对应字段在反序列化时是非必需的。在正常情况下,如果反序列化时缺少字段,则会抛出异常。默认值为True。 4.default 给字段指定一个默认值。需要注意,如果字段设置了default,则隐式地表示该字段已包含required=False,如果同时指定default和required,则会抛出异常。 5.allow_null allow_null=True表示在序列化时允许None作为有效值。需要注意,如果没有显式使用default参数,则当指定allow_null=True时,在序列化过程中将会默认default=None,但并不会在反序列化时也默认。 6.validators 一个应用于传入字段的验证函数列表,如果验证失败,会引发验证错误,否则直接是返回,用于验证字段,如: username = serializers.CharField(max_length=16, required=True, label='用户名', validators=[validators.UniqueValidator(queryset=User.objects.all(),message='用户已经存在')]) 7.error_message 验证时错误码和错误信息的一个dict,可以指定一些验证字段时的错误信息,如: mobile= serializers.CharField(max_length=4, required=True, write_only=True, min_length=4, label='电话', error_messages={ 'blank': '请输入验证码', 'required': '该字段必填项', 'max_length': '验证码格式错误', 'min_length': '验证码格式错误', }) 7.style 一个键值对,用于控制字段如何渲染,最常用于对密码进行密文输入,如: password = serializers.CharField(max_length=16, min_length=6, required=True, label='密码', error_messages={ 'blank': '请输入密码', 'required': '该字段必填', 'max_length': '密码长度不超过16', 'min_length': '密码长度不小于6', }, style={'input_type': 'password'}, write_only=True) 9.label 一个简短的文本字串,用来描述该字段。 10.help_text 一个文本字串,可用作HTML表单字段或其他描述性元素中字段的描述。 11.allow_blank allow_blank=True 可以为空 设置False则不能为空 12.source source='user.email'(user表的email字段的值给这值) 设置字段值 类似default 通常这个值有外键关联属性可以用source设置 13.validators 验证该字段跟 单独的validate很像 UniqueValidator 单独唯一 validators=[UniqueValidator(queryset=UserProfile.objects.all()) UniqueTogetherValidator: 多字段联合唯一,这个时候就不能单独作用于某个字段,我们在Meta中设置。 validators = [UniqueTogetherValidator(queryset=UserFav.objects.all(),fields=('user', 'course'),message='已经收藏')] 14.error_messages 错误消息提示 error_messages={ "min_value": "商品数量不能小于一", "required": "请选择购买数量" }) 7.ModelSerializers ModelSerializers继承于Serializer,相比其父类,ModelSerializer自动实现了以下三个步骤: 1.根据指定的Model自动检测并生成序列化的字段,不需要提前定义; 2.自动为序列化生成校验器; 3.自动实现了create()方法和update()方法。 使用ModelSerializer方式如下: class StudentSerializer(serializers.ModelSerializer): class Meta: # 指定一个Model,自动检测序列化的字段 model = StudentSerializer fields = ('id', 'name', 'age', 'birthday') 相比于Serializer,可以说是简单了不少,当然,有时根据项目要求,可能也会在ModelSerializer中显示声明字段,这些在后面总结。 model 该属性指定一个Model类,ModelSerializer会根据提供的Model类自动检测出需要序列化的字段。默认情况下,所有Model类中的字段将会映射到ModelSerializer类中相应的字段。
关于同一个序列化组件在做get(获取数据)和post(添加数据)时候的一些坑,直接上代码吧(等我再深入研究一下,再给出更好的答案~~):
class BookSerializers(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" # 下面这个extra_kwargs暂时忽略 # extra_kwargs = { # # 'publish': {'write_only': True}, #让publish和authors字段的数据只往数据库里面写,但是查询展示的时候,不显示这两个字段,因为我们下面配置了publish要返回的数据叫做publish_name # # 'authors': {'write_only': True} # }
#read_only属性的意思是,这个字段名称的数据只能查看,不保存,如果用户提交的数据中有这个字段的数据,将会被剔除。 #在我们的BookSerializers类下面可以重写create和update方法,但是validated_data这个数据是在用户提交完数据过来,并且经过序列化校验之后的数据,序列化校验除了一些required等基础校验之外,还会会根据咱们写的这个序列化组件中设置的字段中有read_only=True属性的字段排除掉,这也是为什么我们在面写多对多和一对多字段时,如果字段名称和model表中多对多或者一对多的字段名称相同,那么用户提交过来的数据中以这个字段命名的数据会被剔除,那么validated_data里面就没有多对多和一对多字段的数据了,那么再执行create方法的时候validated_data.pop('authors')这里就会报错,说找不到authors属性。 # def create(self, validated_data): # print(validated_data) # authors = validated_data.pop('authors') # for i in authors: # print(i.pk) # obj = models.Book.objects.create(**validated_data) # obj.authors.add(*authors) # return obj authors_list = serializers.SerializerMethodField() #注意,当你用这个序列化组件既做查询操作,又做添加数据的操作,那么这个字段的名字不能和你models中多对多字段的名字相同,这里也就不能叫做authors # authors = serializers.SerializerMethodField() # authors_list = A() #报错:{"authors_list": ["This field is required."]},也就是说,如果我们将SerializerMethodField中的read_only改成False,那么在进行字段验证的时候,这个字段就没有被排除,也就是说,必须传给我这个authors_list名字的数据,但是如果我们前端给的数据中添加了这么一个数据authors_list:[1,2]的话,你会发现还是会报错,.is_valid()这里报错了,为什么呢,因为,序列化组件校验的时候,在model表中找不到一个叫做authors_list的字段,所以还是报错,所以,在这里有个办法就是将这个序列化组件中的这个字段改个名字,不能和authors名字一样,并且使用默认配置(也就是read_only=true) # def get_authors_list(self,obj): def get_authors_list(self,obj): author_list_values = [] author_list = obj.authors.all() for i in author_list: author_dict = {} author_dict['id'] = i.pk author_dict['name'] = i.name author_list_values.append(author_dict) return author_list_values # publish = serializers.CharField(max_length=32, source='publish.name',read_only=True) #如果这个字段名字和数据表中外键字段名称相同,并且设置了read_only=True属性,那么当用户提交数据到后端保存的时候,就会报错NOT NULL constraint failed: app01_book.publish_id,1.要么你将这个名字改成别的名字,2.要么去数据库表中将这个字段设置一个null=True,但是第二种方式肯定是不太好的,记住,当你获取数据时,使用这个序列化组件,即便是这个字段的名字和数据表中字段名字相同,也是没有问题的,只有在用户提交数据保存的时候才会有问题,所以最好的解决方式就是加read_only属性,并且改一下字段名字,不要和数据表中这个字段的名字相同 publish_name = serializers.CharField(max_length=32, source='publish.name',read_only=True)
按照我们上面的序列化组件的视图,接着写,我们上面只说了一个Book表的几个接口操作,但是我们是不是还有其他表呢啊,如果我们将上面的四个表都做一些序列化的接口操作,我们是不是按照下面的方式写啊
from rest_framework.views import APIView from rest_framework.response import Response from .models import * from django.shortcuts import HttpResponse from django.core import serializers from rest_framework import serializers class BookSerializers(serializers.ModelSerializer): class Meta: model=Book fields="__all__" #depth=1 class PublshSerializers(serializers.ModelSerializer): class Meta: model=Publish fields="__all__" depth=1 class BookViewSet(APIView): def get(self,request,*args,**kwargs): book_list=Book.objects.all() bs=BookSerializers(book_list,many=True,context={'request': request}) return Response(bs.data) def post(self,request,*args,**kwargs): print(request.data) bs=BookSerializers(data=request.data,many=False) if bs.is_valid(): print(bs.validated_data) bs.save() return Response(bs.data) else: return HttpResponse(bs.errors) class BookDetailViewSet(APIView): def get(self,request,pk): book_obj=Book.objects.filter(pk=pk).first() bs=BookSerializers(book_obj,context={'request': request}) return Response(bs.data) def put(self,request,pk): book_obj=Book.objects.filter(pk=pk).first() bs=BookSerializers(book_obj,data=request.data,context={'request': request}) if bs.is_valid(): bs.save() return Response(bs.data) else: return HttpResponse(bs.errors) class PublishViewSet(APIView): def get(self,request,*args,**kwargs): publish_list=Publish.objects.all() bs=PublshSerializers(publish_list,many=True,context={'request': request}) return Response(bs.data) def post(self,request,*args,**kwargs): bs=PublshSerializers(data=request.data,many=False) if bs.is_valid(): # print(bs.validated_data) bs.save() return Response(bs.data) else: return HttpResponse(bs.errors) class PublishDetailViewSet(APIView): def get(self,request,pk): publish_obj=Publish.objects.filter(pk=pk).first() bs=PublshSerializers(publish_obj,context={'request': request}) return Response(bs.data) def put(self,request,pk): publish_obj=Publish.objects.filter(pk=pk).first() bs=PublshSerializers(publish_obj,data=request.data,context={'request': request}) if bs.is_valid(): bs.save() return Response(bs.data) else: return HttpResponse(bs.errors)
好,这样,我们看一下面向对象多继承的用法:
class Animal: def __init__(self,name,age): self.name = name self.age = age def eat(self): print('吃') def drink(self): print('喝') #eat和drink才是动物共有的,下面三个不是共有的,所以直接这么些就不合适了,所以看下面的写法,单独写一些类,其他一部分动物有的,放到一个类里面,在多继承 # def eatshit(self): # print('吃s') # def zhiwang(self): # print('织网') # def flying(self): # print('飞') class Eatshit: def eatshit(self): print('吃s') class Zhiwang: def zhiwang(self): print('织网') class Flying: def zhiwang(self): print('织网') class Jumping: def zhiwang(self): print('跳') class Dog(Animal,Eatshit):pass class Spider(Animal,Zhiwang):pass class Bird(Animal,Flying):pass class Daishu(Animal,Flying,Jumping):pass
那好,基于这种继承形式,我们是不是就要考虑了,我们上面对每个表的那几个接口操作,大家的处理数据的逻辑都差不多啊,而且你会发现,这么多表,我每个表的GET、PUT、DELETE、POST操作其实都差不多,基本上就两个地方再发生变化,这里我们称为两个变量。
publish_list=Publish.objects.all() #表所有的数据
bs=PublshSerializers(publish_list,many=True,context={'request': request}) #序列化组件
Mixin混合类
关于数据逻辑处理的操作,drf帮我们封装好了几个Mixin类,我们来玩一下就行了,看代码:
from django.shortcuts import render,HttpResponse,redirect from django.views import View from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers #将序列化组件都放到一个单独的文件里面,然后引入进来 from app01.serializer import BookSerializers,PublishSerializers from rest_framework import generics from rest_framework.mixins import ListModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin # ListModelMixin 查看所有数据,对应着咱们上面的get查看所有数据的接口 # CreateModelMixin 添加数据的操作,封装了一个create操作,对应着上面的POST添加数据的几口 # UpdateModelMixin 更新 # DestroyModelMixin 销毁(删除) # RetrieveModelMixin 获取单条数据 # 我们自己提炼出,说,每个表的操作基本都是上面的get、post、delete、put操作,所以我们想将这几个方法提炼出来,将来供其他类来继承使用,那么drf帮我们封装好了,就是这几个Minin类 class PublishView(ListModelMixin,CreateModelMixin,generics.GenericAPIView): ''' GenericAPIView肯定继承了APIView,因为APIView里面的功能是我们必须的,而这个GenericAPIView是帮我们做衔接用的,把你的APIView的功能和我们的Minin类的功能衔接、调度起来的 ''' #继承完了之后,我们需要将我们前面各个表的序列化中提炼的两个不同的变量告诉咱的类,注意,下面的两个变量名就是他们俩,不能改,并且必须给 queryset = models.Publish.objects.all() serializer_class = PublishSerializers def get(self,request): ''' 分发找到对应的请求方法,就是咱的get方法,而处理数据的逻辑是继承的那个ListModelMixin类里面的list方法做了,所以我们只需要return self.list(request方法就行了,处理数据的逻辑就不要我们自己再写了 :param request: :return: ''' return self.list(request) #list方法帮我们做了序列化 #post方法添加一条数据,我们只需要执行一下CreateModelMixin类中的create方法就行了 def post(self,request): return self.create(request) class SPublishView(UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin,generics.GenericAPIView): #下面这两个变量和对应数据是必须给的 queryset = models.Publish.objects.all() serializer_class = PublishSerializers # def get(self,request,id):#id就不需要传了,因为人家要求在url中添加的命名分组的pk参数自动来做了 def get(self,request, *args, **kwargs): #*args, **kwargs是为了接收url的那些参数的,咱们写的有个pk参数。 return self.retrieve(request, *args, **kwargs) def put(self, request, *args, **kwargs): return self.update(request, *args, **kwargs) def delete(self, request, *args, **kwargs): return self.destroy(request, *args, **kwargs)
序列化组件的类我们放到了一个单独的文件中,名字叫做serializer.py,内容如下
from app01 import models from rest_framework import serializers class BookSerializers(serializers.ModelSerializer): class Meta: model=models.Book fields = "__all__" class PublishSerializers(serializers.ModelSerializer): class Meta: model=models.Publish fields = "__all__"
urls.py内容如下:
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [#publish表的接口 url(r'^publishs/$', views.PublishView.as_view(),), # url(r'^publishs/(\d+)/', views.SPublishView.as_view(),), #使用UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin这类Mixin类的时候,人家要求必须有个命名分组参数,名字叫做pk,名字可以改,但是先这样用昂 url(r'^publishs/(?P<pk>\d+)/', views.SPublishView.as_view(),), ]
玩了这些drf混合类之后,你会发现,处理数据的相同的逻辑部分被省略了,代码简化了不少。
但是你看,我们上面只是写了一个publish表的操作,咱们还有好多其他表呢,他们的操作是不是也是GET、POST、DELETE、PUT等操作啊,所以你想想有没有优化的地方
####################Author表操作########################## ListCreateAPIView类就帮我们封装了get和create方法 class AuthorView(generics.ListCreateAPIView): queryset = models.Author.objects.all() serializer_class = AuthorSerializers #RetrieveUpdateDestroyAPIView这个类封装了put、get、patch、delete方法 class SAuthorView(generics.RetrieveUpdateDestroyAPIView): queryset = models.Author.objects.all() serializer_class = AuthorSerializers
然后你再看,还有优化的地方,上面这两个类里面的东西是一样的啊,能不能去重呢,当然可以了,一个类搞定,看写法
#####################再次封装的Author表操作########################## from rest_framework.viewsets import ModelViewSet #继承这个模块 class AuthorView(ModelViewSet): queryset = models.Author.objects.all() serializer_class = AuthorSerializers
但是url要改一改了,看url的写法:
#这两个url用的都是上面的一个类
url(r'^authors/$', views.AuthorView.as_view({"get":"list","post":"create"}),), url(r'^authors/(?P<pk>\d+)/', views.AuthorView.as_view({ 'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy' }),),
然后大家重启一下自己的程序,通过postman测一下,肯定可以的。
好,那这个东西怎么玩呢?有兴趣的,可以去看看源码~~~
其实源码中最关键的点是这个:
def view(request, *args, **kwargs): self = cls(**initkwargs) # We also store the mapping of request methods to actions, # so that we can later set the action attribute. # eg. `self.action = 'list'` on an incoming GET request. self.action_map = actions # Bind methods to actions # This is the bit that's different to a standard view
#就下面这三句,非常巧妙 for method, action in actions.items(): {'get':'list',} handler = getattr(self, action) #肯定能找到对应的方法list handler = self.list setattr(self, method, handler) #self.get = self.list
后面再执行dispatch方法之后,那个handler = getattr(self,request.method.lower()) #找到的是list方法去执行的,因为self.get等于self.list了,然后执行list方法,返回对应的内容
咱们上面做的都是数据接口,但是还有逻辑接口,比如登陆,像这种数据接口就直接写个 class Login(APIView):pass这样来搞就行了,封装的越简单,内部逻辑越复杂,自定制来就越复杂,所以关于不同的逻辑,我们就自己单写。
补充点知识,助你看源码
然后大家好奇吗,想不想去看看put\get\delete的操作中,url里面的那个pk命名路由,到底为啥叫pk,并且,它自己在内部怎么通过pk值找到对应的那个更新之前的原来的model对象的啊?
1. 局部认证组件
我们知道,我们不管路由怎么写的,对应的视图类怎么写的,都会走到dispatch方法,进行分发,
在咱们看的APIView类中的dispatch方法的源码中,有个self.initial(request, *args, **kwargs),那么认证、权限、频率这三个默认组件都在这个方法里面了,如果我们自己没有做这三个组件的配置,那么会使用源码中默认的一些配置。进源码去看看你就会看到下面三个东西:
# Ensure that the incoming request is permitted #实现认证 self.perform_authentication(request) #权限判断 self.check_permissions(request) #控制访问频率 elf.check_throttles(request)
目前为止大家知道的认证机制是不是有cookie、session啊,session更安全一些,但是你会发现session的信息都存到咱们的服务器上了,如果用户量很大的话,服务器压力是比较大的,并且django的session存到了django_session表中,不是很好操作,但是一般的场景都是没有啥问题的,现在生产中使用的一个叫做token机制的方式比较多,现在我们是不是就知道个csrf_token啊,其实token有很多种写法,如何加密,你是hashlib啊还是base64啊还是hmac啊等,是不是加上过期时间啊,是不是要加上一个secret_key(客户端与服务端协商好的一个字符串,作为双方的认证依据),是不是要持续刷新啊(有效时间要短,不断的更新token,如果在这么短的时间内还是被别人拿走了token,模拟了用户状态,那这个基本是没有办法的,但是你可以在网络或者网络设备中加安全,存客户的ip地址等,防黑客)等等。
大致流程图解:
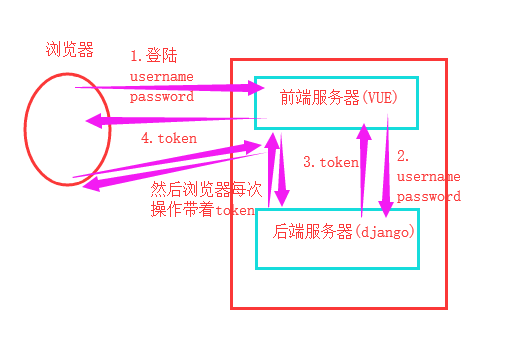
首先我们需要创建一个表,用户表,里面放一个token字段,其实一般我都是放到两个表里面,和用户表是一个一对一关系的表,看代码:
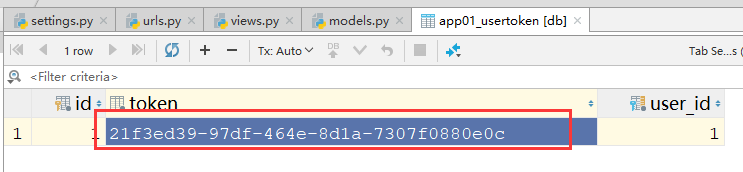
################################# user表 ############################### class User(models.Model): user = models.CharField(max_length=32) pwd = models.CharField(max_length=32) type_choice=((1,"VIP"),(2,"SVIP"),(3,"SSVIP")) user_type = models.IntegerField(choices=type_choice) class UserToken(models.Model): user = models.OneToOneField(to=User) #一对一到用户表 token = models.CharField(max_length=128) #设置的长度大一些 # expire_time = models.DateTimeField() #如果做超时时间限制,可以在这里加个字段来搞,这里我没有写昂,简单搞了
urls.py内容如下:
#登陆认证接口 url(r'^login/$', views.LoginView.as_view(),), #别忘了$符号结尾
views.py内容如下:自己写一个每次登陆成功之后刷新token值
###################login逻辑接口####################### #关于逻辑接口而不是提供数据的接口,我们不用ModelViewSet,而是直接写个类,继承APIView,然后在类里面直接写咱的逻辑 import uuid import os import json class LoginView(APIView): #从前后端分离的项目来讲,get请求不需要写,因为get就是个要登陆页面的操作,vue就搞定了,所以我们这里直接写post请求就可以了 def post(self,request): # 一般,请求过来之后,我们后端做出的响应,都是个字典,不仅包含错误信息,还有要状态码等,让客户端明白到底发生了什么事情 # 'code'的值,1表示成功,0表示失败,2表示其他错误(自己可以做更细致的错误代码昂) res = {'code': 1, 'msg': None, 'user': None,'token':None} print(request.data) try: user = request.data.get('user') pwd = request.data.get('pwd') # 数据库中查询 user_obj = models.User.objects.filter(user=user, pwd=pwd).first() if user_obj: res['user'] = user_obj.user # 添加token,用到咱们usertoken表 # models.UserToken.objects.create(user=user,token='123456') # 创建token随机字符串,我写了两个方式,简写的昂,最好再加密一下 random_str = uuid.uuid4() # random_str = os.urandom(16) bytes类型的16位的随机字符串 models.UserToken.objects.update_or_create( user=user_obj, # 查找筛选条件 defaults={ # 添加或者更新的数据 "token": random_str, } ) res['token'] = random_str res['msg'] = '登陆成功' else: res['code'] = 0 res['msg'] = '用户名或者密码错误' return Response(res) except Exception as e: res['code'] = 2 res['msg'] = str(e) return Response(res)
通过上面的代码我们将token返回给了用户,那么以后用户不管发送什么请求,都要带着我给它的token值来访问,认证token通过才行,并且更新token。
下面我们玩一下drf提供的认证组件的玩法。
DRF的认证组件
将来有些数据接口是必须要求用户登陆之后才能获取到数据,所以将来用户登陆完成之后,每次再过来请求,都要带着token来,作为身份认证的依据。
from app01.serializer import BookSerializers #####################Book表操作########################## class UserAuth():
def authenticate_header(self,request):
pass
#authenticate方法固定的,并且必须有个参数,这个参数是新的request对象,不信,看源码 def authenticate(self,request): if 1: #源码中会发现,这个方法会有两个返回值,并且这两个返回值封装到了新的request对象中了,request.user-->用户名 和 request.auth-->token值,这两个值作为认证结束后的返回结果 return "chao","asdfasdfasdf" class BookView(APIView): #认证组件肯定是在get、post等方法执行之前执行的,还记得源码的地方吗,这个组件是在dispatch的地方调用的,我们是上面写个UserAuth类 authentication_classes = [UserAuth,] #认证类可以写多个,一个一个的顺序验证 def get(self,request): ''' 查看所有书籍 :param request: :return: ''' #这样就拿到了上面UserAuth类的authenticate方法的两个返回值 print(request.user) print(request.auth) book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data)
def _authenticate(self): """ Attempt to authenticate the request using each authentication instance in turn. """ for authenticator in self.authenticators: try: user_auth_tuple = authenticator.authenticate(self) except exceptions.APIException: self._not_authenticated() raise if user_auth_tuple is not None: self._authenticator = authenticator #值得注意的是,self是APIView封装的新的request对象 self.user, self.auth = user_auth_tuple return #退出了这个函数,函数就不会执行了,不会再循环了,所以如果你的第一个认证类有返回值,那么第二个认证类就不会执行了,所以别忘了return是结束函数的意思,所以如果你有多个认证类,那么返回值放到最后一个类里面
好,我们写一写获取token值,然后校验的功能,看views.py的代码:
from django.shortcuts import render,HttpResponse,redirect from django.views import View from rest_framework import serializers from app01 import models from rest_framework.views import APIView from rest_framework.response import Response #将序列化组件都放到一个单独的文件里面,然后引入进来 from app01.serializer import BookSerializers,PublishSerializers,AuthorSerializers #drf提供的认证失败的异常 from rest_framework.exceptions import AuthenticationFailed class UserAuth(): #每个认证类,都需要有个authenticate_header方法,并且有个参数request def authenticate_header(self,request): pass #authenticate方法固定的,并且必须有个参数,这个参数是新的request对象,不信,看源码 def authenticate(self,request): # token = request._request.GET.get("token") #由于我们这个request是新的request对象,并且老的request对象被封装到了新的request对象中,名字是self._request,所以上面的取值方式是没有问题的,不过人家APIView不仅封装了老的request对象,并且还给你加了query_params属性,和老的request.GET得到的内容是一样的,所以可以直接按照下面的方式来写 token = request.query_params.get("token") #用户请求来了之后,我们获取token值,到数据库中验证 usertoken = models.UserToken.objects.filter(token=token).first() if usertoken: #验证成功之后,可以返回两个值,也可以什么都不返回 return usertoken.user.user,usertoken.token #源码中会发现,这个方法会有两个返回值,并且这两个返回值封装到了新的request对象中了,request.user-->用户名 和 request.auth-->token值,这两个值作为认证结束后的返回结果 else: #因为源码内部进行了异常捕获,并且给你主动返回一个forbiden错误,所以我们在这里主动抛出异常就可以了 raise AuthenticationFailed("认证失败")
urls.py内容如下:
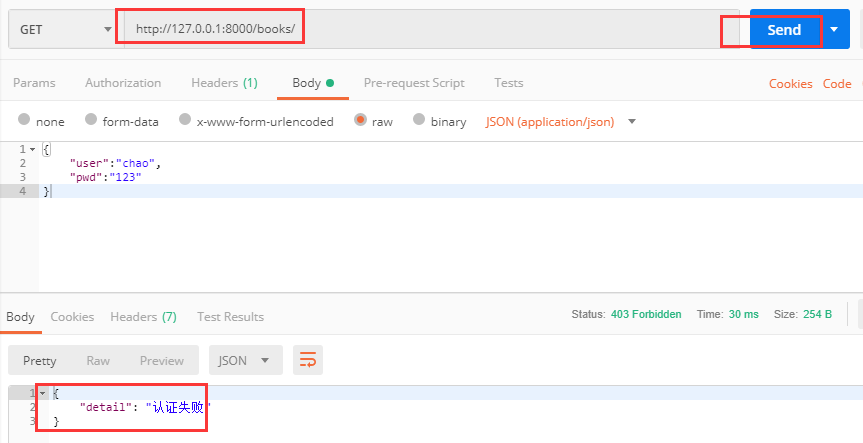
url(r'^books/$', views.BookView.as_view(),),
通过postman发送请求,你会发现错误:
如果我们请求中带了数据库中保存的token值,那么就会成功获取数据,看数据库中的token值:
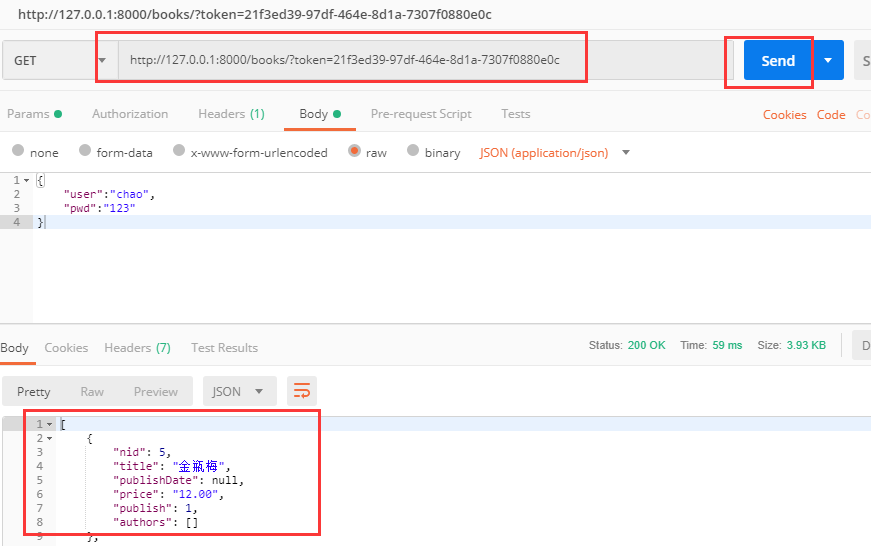
然后通过postman再请求,带着token值,看效果,成功了:
继承drf的BaseAuthentication认证类的写法:
from app01 import models from rest_framework.views import APIView from rest_framework.response import Response #将序列化组件都放到一个单独的文件里面,然后引入进来 from app01.serializer import BookSerializers,PublishSerializers,AuthorSerializers #drf提供的认证失败的异常 from rest_framework.exceptions import AuthenticationFailed from rest_framework.authentication import BaseAuthentication #继承drf的BaseAuthentication类 class UserAuth(BaseAuthentication): # 继承了BaseAuthentication类之后,这个方法就不用写了 # def authenticate_header(self,request): # pass def authenticate(self,request): # token = request._request.GET.get("token") token = request.query_params.get("token") #有request对象,那么不仅仅可以认证token,还可以认证请求里面的其他内容 usertoken = models.UserToken.objects.filter(token=token).first() if usertoken: #验证成功之后 return usertoken.user.user,usertoken.token else: raise AuthenticationFailed("认证失败") class BookView(APIView): #通过源码看,认证类的查找过程,和解析组件的查找过程是一样的 authentication_classes = [UserAuth,] def get(self,request): ''' 查看所有书籍 :param request: :return: ''' print(request.user) print(request.auth) book_obj_list = models.Book.objects.all() s_books = BookSerializers(book_obj_list,many=True) return Response(s_books.data)
带时间戳的随机字符串:
def get_random_str(user): import hashlib,time ctime=str(time.time()) md5=hashlib.md5(bytes(user,encoding="utf8")) md5.update(bytes(ctime,encoding="utf8")) return md5.hexdigest()
全局视图认证组件:
在settings.py文件中配置:如果我再app01文件夹下的service文件夹下的auth文件夹下写了我们自己的认证类,那么全局配置的写法就按照下面的方式写。
REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",] #里面是路径字符串 }
认证组件就说这些,看权限组件吧。
局部视图权限:
在app01.service.permissions.py中
from rest_framework.permissions import BasePermission class SVIPPermission(BasePermission): message="SVIP才能访问!" #变量只能叫做message def has_permission(self, request, view): #重写has_permission方法,自己写权限逻辑,看看源码就明白了,这个view是咱当前类的实例化对象,一般用不到,但是必须给个参数写在这里。 if request.user.user_type==3: return True #通过权限 return False #没有通过
在views.py:
from app01.service.permissions import * class BookViewSet(generics.ListCreateAPIView): permission_classes = [SVIPPermission,] queryset = Book.objects.all() serializer_class = BookSerializers
全局视图权限:
settings.py配置如下:
REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",], "DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",] }
局部视图throttle,反爬,防攻击
在throttles.py中:
from rest_framework.throttling import BaseThrottle,SimpleRateThrottle import time from rest_framework import exceptions visit_record = {} class VisitThrottle(BaseThrottle): # 限制访问时间 VISIT_TIME = 10 VISIT_COUNT = 3 # 定义方法 方法名和参数不能变 def allow_request(self, request, view): # 获取登录主机的id id = request.META.get('REMOTE_ADDR') self.now = time.time() if id not in visit_record: visit_record[id] = [] self.history = visit_record[id] # 限制访问时间 while self.history and self.now - self.history[-1] > self.VISIT_TIME: self.history.pop() # 此时 history中只保存了最近10秒钟的访问记录 if len(self.history) >= self.VISIT_COUNT: return False else: self.history.insert(0, self.now) return True def wait(self): return self.history[-1] + self.VISIT_TIME - self.now
在views.py中:
from app01.service.throttles import * class BookViewSet(generics.ListCreateAPIView): throttle_classes = [VisitThrottle,] queryset = Book.objects.all() serializer_class = BookSerializers
全局视图throttle
REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",], "DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",], "DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",] }
内置throttle类
在throttles.py修改为:
class VisitThrottle(SimpleRateThrottle): scope="visit_rate" def get_cache_key(self, request, view): return self.get_ident(request)
settings.py设置:
REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",], "DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",], "DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",], "DEFAULT_THROTTLE_RATES":{ "visit_rate":"5/m", } }
帮我们自动生成4个url,和我们自己写的差不多:
from django.conf.urls import url,include from django.contrib import admin from app01 import views from rest_framework import routers router = routers.DefaultRouter() #自动帮我们生成四个url router.register(r'authors', views.AuthorView) router.register(r'books', views.BookView) urlpatterns = [ # url(r'^books/$', views.BookView.as_view(),), #别忘了$符号结尾 # url(r'api/', include(router.urls)), url(r'', include(router.urls)), #http://127.0.0.1:8000/books/ 也可以这样写:http://1270.0..1:8000/books.json/ #登陆认证接口 url(r'^login/$', views.LoginView.as_view(),), #别忘了$符号结尾 ]
但是有个前提就是,我们用的是:ModelViewSet序列化组件。
from rest_framework.viewsets import ModelViewSet class AuthorView(ModelViewSet): queryset = models.Author.objects.all() serializer_class = AuthorSerializers class BookView(ModelViewSet): queryset = models.Book.objects.all() serializer_class = BookSerializers
所以,这个url注册器其实并没有那么好用,当然啦,看需求.
简单看看就行啦:
from rest_framework.viewsets import ModelViewSet from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer #如果我们没有在自己的视图类里面配置,那么源码里面默认就用的这两个JSONRenderer,BrowsableAPIRenderer #BrowsableAPIRenderer 是当客户端为浏览器的时候,回复的数据会自动给你生成一个页面形式的数据展示,一般开发的时候,都不用页面形式的 #JSONRenderer:回复的是json数据 class BookView(ModelViewSet): # renderer_classes = [JSONRenderer,] #其实默认就是这个JSONRenderer,所以一般不用在这里配置了 queryset = models.Book.objects.all() serializer_class = BookSerializers
简单使用:
#引入分页 from rest_framework.pagination import PageNumberPagination class BookView(APIView): # 通过源码看,认证类的查找过程,和解析组件的查找过程是一样的 # authentication_classes = [UserAuth,] # throttle_classes = [VisitThrottle,] def get(self,request): ''' 查看所有书籍 :param request: :return: ''' book_obj_list = models.Book.objects.all() #创建分页器对象,PageNumberPagination类中除了PAGE_SIZE属性之外,还有个page属性,这个page属性是第几页,用法是http://127.0.0.1:8000/books/?page=1 pnb = PageNumberPagination() #通过分页器对象的paginate_queryset方法进行分页, paged_book_list = pnb.paginate_queryset(book_obj_list,request,) #将分页的数据进行序列化 s_books = BookSerializers(paged_book_list,many=True) return Response(s_books.data)
settings配置文件:
REST_FRAMEWORK={ # "DEFAULT_THROTTLE_RATES":{ # "visit_rate":"5/m", # }, 'PAGE_SIZE':5, #这是全局的一个每页展示多少条的配置,但是一般不用它,因为不同的数据展示可能每页展示的数量是不同的 }
如果我们不想用全局的page_size配置,我们自己可以写个类来继承分页类组件,重写里面的属性:
#引入分页 from rest_framework.pagination import PageNumberPagination class MyPagination(PageNumberPagination): page_size = 3 #每页数据显示条数 page_query_param = 'pp' #http://127.0.0.1:8000/books/?pp=1,查询哪一页的数据 page_size_query_param = 'size' #如果我们显示的一页数据不够你用的,你想临时的多看展示一些数据,可以通过你设置的这个page_size_query_param作为参数来访问:http://127.0.0.1:8000/books/?pp=2&size=5 #那么你看到的虽然是第二页,但是可以看到5条数据,意思是将page_size的数字临时扩大了,每页展示的数据就多了或者少了,看你的page_size_query_param设置的值 max_page_size = 10 #最大每页展示多少条,即便是你前端通过page_size_query_param临时调整了page_size的值,但是最大也不能超过我们设置的max_page_size的值 class BookView(APIView): def get(self,request): ''' 查看所有书籍 :param request: :return: ''' book_obj_list = models.Book.objects.all() pnb = MyPagination() paged_book_list = pnb.paginate_queryset(book_obj_list,request,) s_books = BookSerializers(paged_book_list,many=True) return Response(s_books.data)
还有我们玩的继承了ModelViewSet类的试图类使用分页器的写法:
from rest_framework.viewsets import ModelViewSet from rest_framework.pagination import PageNumberPagination class MyPagination(PageNumberPagination): page_size = 3 page_query_param = 'pp' page_size_query_param = 'size' max_page_size = 10 class BookView(ModelViewSet): queryset = models.Book.objects.all() serializer_class = BookSerializers pagination_class = MyPagination #配置我们自己写的分页类
还有个偏移分页,了解一下就行了
from rest_framework.pagination import LimitOffsetPagination

 浙公网安备 33010602011771号
浙公网安备 33010602011771号