
JPEG图像压缩算法流程详解
JPEG图像压缩算法流程详解
JPEG代表Joint Photographic Experts Group(联合图像专家小组)。此团队创立于1986年,1992年发布了JPEG的标准而在1994年获得了ISO10918-1的认定。
JPEG是一种有损压缩。
色彩空间转换
图片由RGB色彩空间转换到YUV色彩空间,转换关系如下

一般来说U,V是有符号的数字,但这里通过加上128,使其变为无符号数,方便存储和计算
采样
研究发现,人眼对亮度变换的敏感度比色彩变换的敏感度高。因此,可以认为Y分量比U,V分量更为重要。故采样时通常会降低U,V分量的采样率,这里采用411采样方式,即Y,U,V三个分量的取样比例为4:1:1,其含义为在2*2的单元中,Y分量采样4次,U,V分量各采样一次。这样采样的优点是虽然损失了一定精度,但也在人眼几乎不可见的前提下减小了数据存储量。
分块
DCT变换是对8 * 8的子块进行处理的,且U,V分量在2 * 2的单元中采样一次,故在DCT变换之前将原图像长宽分别用0补齐到16的倍数。之后再对Y,U,V三个分量分别分为8*8的块便进行后续操作。
离散余弦变换
离散余弦变化的公式为
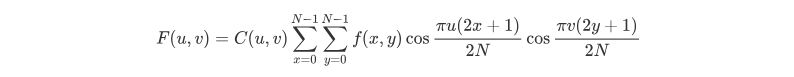
其中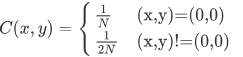
由于已经明确每次进行离散余弦变化的矩阵大小为8*8,故这里不再采用上述方法进行离散余弦变换,而是利用DCT变换矩阵实现DCT变换以降低运算量。
DCT变换矩阵计算公式为

故8*8的DCT变换矩阵

其转置矩阵
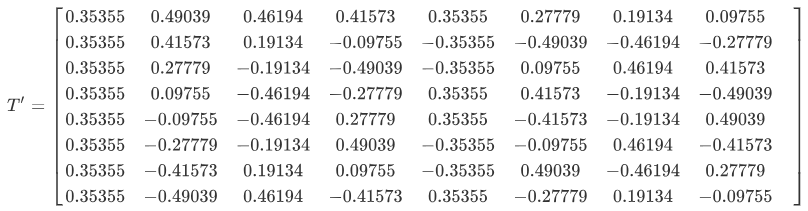
DCT可简化为T * B * T',其中B为8*8的原矩阵。
实施二维DCT可将图像的能量集中在极少的几个系数之上,其他系数相比于这些系数,绝对值要小很多。这些系数大都集中在左上角,即低频分量区。
数据量化
量化是JPEG算法中损失图像精度的根源, 也是产生压缩效果的源泉。
人类眼睛在一个相对大范围区域,辨别亮度上细微差异是相当的好,但是在一个高频率亮度变动之确切强度的分辨上,却不是如此地好。这个事实让我们能在高频率成分上极佳地降低信息的数量。简单地把频率领域上每个成分,除以一个对于该成分的常量就可完成,且接着舍位取最接近的整数。这是整个过程中的主要有损运算。以这个结果而言,经常会把很多更高频率的成分舍位成为接近0,且剩下很多会变成小的正或负数。
JPEG提供的量化算法如下
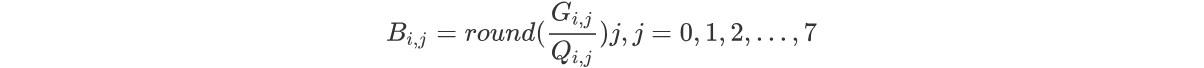
其中G是我们需要处理的图像矩阵,Q称作量化系数矩阵 ,round函数是取整函数。JPEG算法提供了两张标准的量化系数矩阵,分别用于处理亮度数据Y和色差数据U以及V。
标准亮度量化表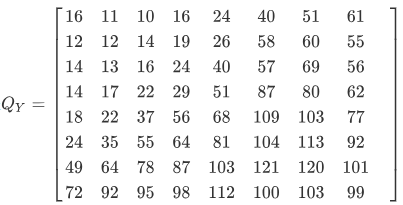
标准色差量化表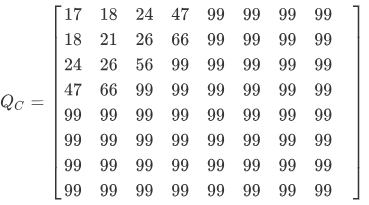
DCT系数矩阵中的不同位置的值代表了图像数据中不同频率的分量,这两张表中的数据时人们根据人眼对不不同频率的敏感程度的差别所积累下的经验制定的,一般来说人眼对于低频的分量比高频分量更加敏感,所以两张量化系数矩阵左上角的数值明显小于右下角区域。 这样就使得量化后的矩阵更多地保留高频信息。
量化后的一个8*8矩阵:
通常一张图片中的一个8*8矩阵经过上述变化之后,矩阵都如上矩阵一样,其中的一大部分数据都会变成0,这非常有利于后面数据的压缩。
编码
差值编码和Zig-zag扫描
量化后矩阵左上角的值被称为直流分量DC,其他63个值被称为交流分量AC。其中DC不参与Z字形扫描,而是与前一矩阵的DC系数进行差分编码(DPCM);AC分量则采用Z字形扫描排列并进行游程长度编码(RLE)。
游程长度编码(Run-Length Encoding, RLE)
量化AC系数的特点是包含很多连续的0,故使用RLE对其进行编码。JPEG使用了1个字节的高4位来表示连续的0的个数,而使用其低四位来表示下一个非0系数需要的位数,紧随其后的是量化AC系数的值。
假设Zig-zag扫描后的一组向量的AC分量为
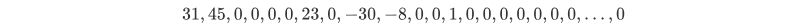
经RLE压缩后如下
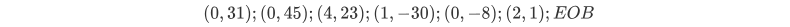
其中EOB表示后面都是0。实际上,用(0,0)表示EOB。若这组数字不以0结束,则不需要EOB。
Huffman编码
JEPG压缩编码时,通过查表实现霍夫曼编码器,本次实验中我使用了ISO/IEC International Standard 10918-1中JPEG推荐的典型霍夫曼表(Typical Huffman tables),我已经将4张表格发表在个人博客,篇幅所限这里就不再给出了。
之所以需要四张Huffman 编码表,是因为编码时每个矩阵数据的1个DC值与63个AC值分别使用不同的Huffman 编码表,而且亮度Y与色度U,V也要使用不同的Huffman 编码表。
为提高储存效率,JEPEG里并不直接保存数值,而是将数值按实际值所需要的位数分成16组,如下表所示
| Value | Size | Bits |
|---|---|---|
| 0 | 0 | - |
| -1, 1 | 1 | 0, 1 |
| -3, -2, 2, 3 | 2 | 00, 01, 10, 11 |
| -7, -6, -5, -4, 4, 5, 6, 7 | 3 | 000, 001, 010, 011, 100, 101, 110, 111 |
| -15, …, -8, 8, …, 15 | 4 | 0000, …, 0111, 1000, …, 1111 |
| -31, …, -16, 16, …, 31 | 5 | 0 0000, …, 0 1111, 1 0000, …, 1 1111 |
| -63, …, -32, 32, …, 63 | 6 | 00 0000, …, …, 11 1111 |
| -127, …, -64, 64, …, 127 | 7 | 000 0000, …, …, 111 1111 |
| -255, …, -128, 128, …, 255 | 8 | 0000 0000, …, …, 1111 1111 |
| -511, …, -256, 256, …, 511 | 9 | 0 0000 0000, …, …, 1 1111 1111 |
| -1023, …, -512, 512, …, 1023 | 10 | 00 0000 0000, …, …, 11 1111 1111 |
| -2047, …, -1024, 1024, …, 2047 | 11 | 000 0000 0000, …, …, 111 1111 1111 |
| -4095, …, -2048, 2048, …, 4095 | 12 | 0000 0000 0000, …, …, 1111 1111 1111 |
| -8191, …, -4096, 4096, …, 8191 | 13 | 0 0000 0000 0000, …, …, 1 1111 1111 1111 |
| -16383, …, -8192, 8192, …, 16383 | 14 | 00 0000 0000 0000, …, …, 11 1111 1111 1111 |
| -32767, …, -16348, 16348, …, 32767 | 15 | 000 0000 0000 0000, …, …, 111 1111 1111 1111 |
设一个一维化后的亮度的数据块为
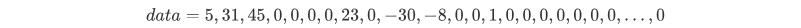
其中第一个数字代表本数据块DC值与前一数据块DC值之差为5。
那么RLE压缩后的data变为
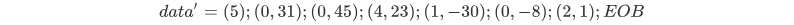
其中EOB = (0,0)。
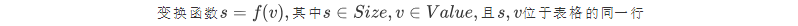
对data'中每个数对的第二个数v求对应的s值,并将s置于数对中v之前,得到data''
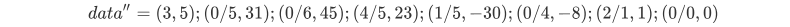
其中第一个数对为DC分量运算得到的结果。
由于假设该以为数据由亮度数据块变换得来,因此对于DC和AC分量,分别对data''数对中的第一个数字查Huffman DC亮度表和Huffman AC亮度表,再对数对中的第二个数字查上表,即可得到一维数据块data编码后的序列。data''查表的结果为:\(100,101;11010,11111;111000,101101;1111111110011000,10111;11111110110,00001;1011,0111;11100,1;1010\)
其中的标点是为了方便对照,实际编码中没有标点。
压缩比
最终共用70973bit保存压缩后的数据,压缩前的数据大小为256 * 256 * 8+256 * 256/4 * 2 * 8 = 786432bit,故压缩比为70973/786432 * 100% =9.02% 。
解码
解码过程为编码过程的逆过程,这里不再赘述。
解码后的图片与原图片比较


可以看出,处理后的图片与原图片有一定差异,推测差异是在量化和反量化过程中产生的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号