


软工项目技术规格说明书
概述&技术栈
产品概述
我们团队的社团管理系统继承自以前的版本,宏观架构上没有特别大的变化,但是会引入一些新的功能和特性,也会对新的平台进行更加完善的支持。
技术栈
本节将详细介绍本项目开发的技术栈结构。
前端框架
之前的项目中,并没有明确的前端框架,也就是说,是原生的js+css+html完成的整个前端。除了使用了jquery做了基本的前端行为控制,以及使用ueditor作为编辑器之外,没有明确的框架,也没有很明确的架构,可以说比较凌乱。
未来我们将考虑使用vue.js框架对于前端进行一次完整的重构,使得架构更加清晰,可维护性更强,未来的开发效率和潜力进一步提高。
后端框架
后端框架使用的是Ruby语言,采用的是最为主流的Ruby on Rails框架。
根据基本的观察,代码质量尚可,不过依然有很多缺乏注释的地方,之后可以考虑进行一些补全和重构,以及一些功能的添加。
数据库
数据库使用的是Mysql,具体是5.6还是5.7不太清楚,不过应该问题不是很大。
后端代码里面,并没有较多的明文sql拼接,所以正常来说,只要是mysql系数据库,都不会存在兼容性问题(mariadb应该也没大问题)。
web引擎
web引擎的话,可以有很多选择,Apache或者Nginx。
我们更倾向于使用Nginx,进行一次反向代理访问后端,以及前端也可以部署在同一个nginx下。
云环境
云环境的话,目前还没有完全确定,不知道华为云那边是否愿意提供足够的资源。
如果不考虑这个的话,一个比较理想的配置如下(腾讯云):
- Ubuntu环境云服务器,一个实例(理想配置2core4G,最低不得低于1core1G)
- MYSQL云数据库,一个实例(理想配置2G200Qps,最低不得低于1G100Qps)
- Redis缓存数据库,一个实例(理想配置1G400+Qps,最低不得低于1G100Qps)
- 对象存储服务,一个Bucket(常备模式即可,未来上了规模再考虑冷备Bucket,用于用户资源的存储)
- 内容分发网络服务(也就是CDN),两个域名
- 一个用于存储web前端的静态内容(js、css、图片等)
- 一个用于用户资源(比如文件等)存储
当然,最紧缩的状态下,那就只能:
- 一台微型服务器
- 数据库和缓存库部署在本机
- 存储内容也一概存储于本机路径下
产品设计

架构
宏观架构
宏观架构设计图
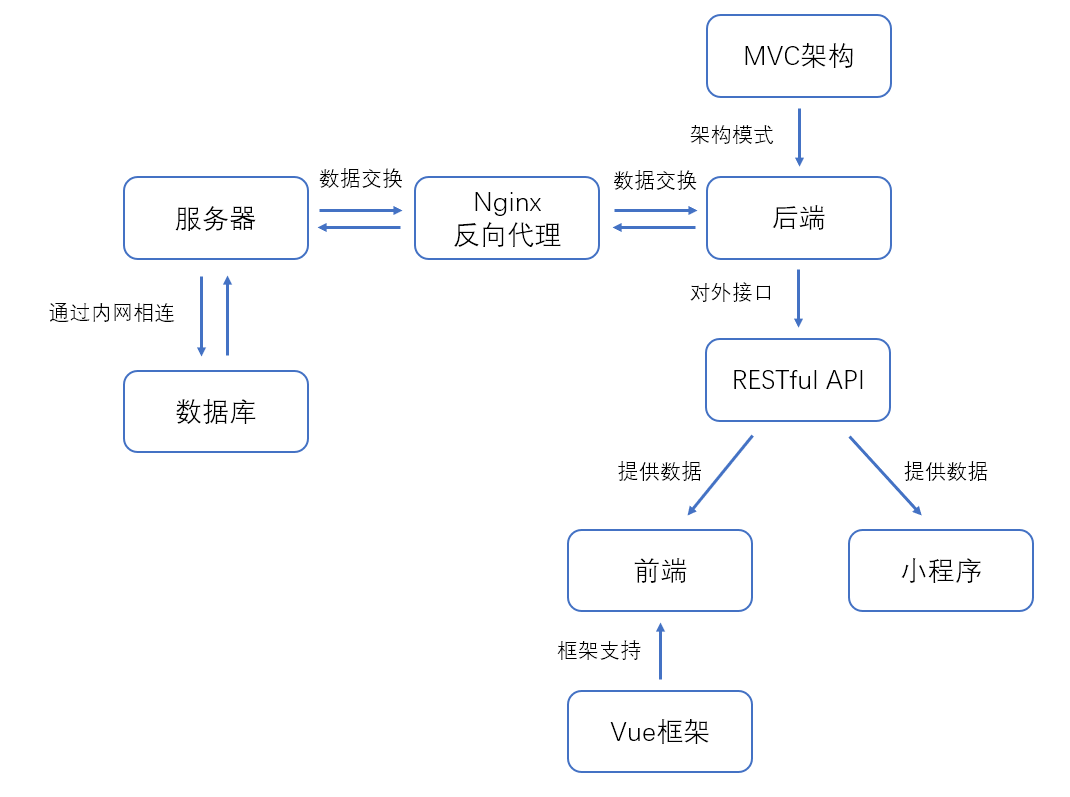
宏观技术架构浅析
-
从整体功能上看,我们的项目分为以下三个大的模块:
- 服务端(包括Server、Datebase及Nginx)
- 后端
- 用户交互端(前端+小程序)
-
服务端与后端的数据交换
考虑到软件后期用户量的上升及特殊时期(如百团大战)的用户访问需求,我们在后端与服务器之间加入了一层Nginx反向代理。当出现大量的用户请求时,服务器可以配置成集群的形式,用户在访问前端或小程序时,请求会先发送到Nginx服务器,Nginx再在服务器集群中选择一个压力较小的服务器,将该访问引入被选择的服务器,以达到负载均衡的效果。对于本项目而言,进行这样的准备无疑很有必要。
-
服务器与数据库的部署
本项目服务于广大社团,有着大量的图片及视频存储需求,把这些静态资源放在主服务器上显然不是一个明智的做法。我们采取了服务器和数据库分离的架构,静态资源将会通过OSS对象存储存放在一系列单独的云硬盘中,减轻服务器的空间压力。
-
RESTful API
为了使社团管理人员和社团用户具有不同的操作界面,我们在本项目中设置了用于管理社团信息的前端界面,和供普通用户操作的小程序。由于前端开发和小程序开发存在着很大的不同,因此传统的后端+模板引擎生成前端界面的方法就不适用了。为了解决这个问题,我们的后端将提供一系列RESTful API接口,这些接口对前端和小程序而言都有着相同的调用形式,用户交互端不需要考虑后端的内部细节,只需要按照约定调用这些API,就可以获得自己需要的数据。这样的框架设计将前端与后端完全解耦,也让前后端并行开发成为了可能。
接口规格(暂定)
| # | 请求方法 | 请求路径 | 路由指向 | 用途 |
|---|---|---|---|---|
| 1 | get |
/api/articles/:article_id/comments |
comments#getcomments |
获得当前文章评论 |
| 2 | post |
/api/users/phone_num/verify/code |
users#verify_phone_sendcode |
手机验证发送验证码 |
| 3 | post |
/api/users/phone_num/verify |
users#verify_phone |
验证验证码是否正确 |
| 4 | post |
/api/users/email/verify |
users#verify_email_send |
验证邮箱,给邮箱寄信 |
| 5 | get |
/api/users/email/verify/:uid/:hash_code |
users#verify_email |
验证邮箱,邮箱点击链接返回 |
| 6 | post |
/api/users/forgetpassword/email |
users#fp_email |
忘记密码,邮箱 |
| 7 | get |
/api/users/forgetpassword/email/verify/:uid/:hash_code |
users#fp_email_verify |
忘记密码,邮箱转跳 |
| 8 | post |
/api/users/forgetpassword/phone_num/send |
users#fp_phone_send |
忘记密码,手机 |
| 9 | post |
/api/users/forgetpassword/phone_num/verify |
users#fp_phone_verify |
忘记密码,手机 |
| 10 | get |
/api/clubs/members/all |
clubs#memberslist |
获取社团名单 |
| 11 | post |
api/clubs/users/export |
clubs#exportlist |
导出名单 |
| 12 | post |
/api/clubs/members/forcequit |
clubs#forcequit |
强制退社 |
| 13 | get |
/api/clubs/members/apply |
clubs#applicantlist |
申请人列表 |
| 14 | get |
/api/clubs/members/apply/accept/:user_id |
clubs#acceptapplication |
同意申请 |
| 15 | get |
/api/clubs/member/apply/refuse/:user_id |
clubs#refuseapplication |
拒绝申请 |
目前原代码控制器内的返回结构有点凌乱,未来我们将考虑抽象为如下基本格式:
{
"success": true, // 请求是否成功
"code": 0, // 错误码(success为false才有意义,否则均为0)
"message": "This is response message", // 返回信息
"data": { // 返回数据信息(可能为null或者Object类型)
// this is data content
}
}
分析
抽象&模块化
抽象与模块化的话,主要分为几层:
- 底层数据抽象化
- 即,将底层的数据库访问,封装成面向对象的形态(orm)
- 具体来说,分为三个点
- 将SQL的各类操作语句,封装成给予OOP的操作形态,甚至支持链式操作
- 将数据库内的数据信息,封装成OOP对象形态,方便进行读写操作
- 将数据库结构的变动,维护成数据库迁移对象(migration),方便日后的不断后续开发维护
- 数据行为模块化
- 将数据的调度行为,基于需求域进行分类
- 将不同类型的行为划分到不同的区域内(controller)
- 将同一controller内的不同行为,划分为不同的method
- 对于不同的method,定义各类前后缀操作,极大方便有些共性操作的拼装(这里需要用到一些AOP程序设计模式)
- 行为对外接口化
- 通过一个映射(route,路由表),将controller内的各个method映射至对外访问的api
- 通过路由表,将api传入的数据请求,进行基本的数据处理与封装之后,交给对应controller对应method执行
- method执行完毕后,返回请求response数据
海量数据适应性
对于海量数据适应性,其实有几个比较常见的做法,我们之后可以进行考虑。
-
数据库读写分离
- 这一机制适用于数据io很大,且存在读性能瓶颈的情况(实际上,这种情况对于webapp来说,相当常见)
- 设置主库和多个从库,主库主要负责写操作,从库负责读操作,且分担掉读压力
- 不过值得注意的是,需要有可靠的手段保证数据一致性(这也是分布式系统都必须面对的难题)
-
数据库冷热备份机制
- 这一机制适用于数据库存储数据量巨大,且真正活跃的数据大部分集中在近期的情况
- 使用一个热备份数据库,和一个(也可能是分布式)冷备份数据库
- 大部分操作均在热备份库进行,极少数读操作可能涉及到冷备份
- 同样的,对于table单位,也可以做出类似的机制
- 当然,在后端orm部分,可以考虑通过进一步的封装,以实现和普通单体数据库无差异的编程体验
-
服务端分布式化
- 将服务端做成分布式的形态(无数据冒险的单体处理架构,或者有充分的冒险控制机制)
- 由nginx或者其他解决方案进行负载均衡管理
-
数据上云,主要体现在以下几个方面:
- 对于前端,一些静态资源可以直接使用cdn进行分流,减轻原服务器压力
- 对于后端的静态资源,可以直接上传至公有云,读取时进行接口请求即可,减轻本地硬盘存储以及IO压力
信息封装和隐藏
后端Ruby On Rails
Ruby On Rails是一个基于Ruby的Web开发框架,由于Ruby本身就是一门极度面向对象的语言(甚至就连整数1都有可供调用的方法,例如1.times),因此Rails框架天然地实现了信息的封装与隐藏。在我们的设计中,后端的每一个Controller、Model和Helper都是一个类,在开发后端时,外部只能访问类中公开的方法,类持有自己的私密数据,外界无法访问。因此,后端采用的技术本身就很好地体现了信息的封装和隐藏。
前端Vue.js
在传统的网页开发中,一张网页通常由html, css和js这三个文件组成。以我们继承的版本为例,之前的团队使用了很纯粹的传统网页开发模式,一个项目里充斥了各种页面文件、样式文件和脚本文件,各种信息之间完全没有封装和隐藏,因此也就无法复用,为前端的开发带来了很大的困难。
在我们的设计中,前端将会使用Vue.js进行开发。Vue.js推崇的是“单文件组件”的组织结构,即一个.vue文件中同时包含了页面、样式和脚本代码,并且像其他编程语言的import一样,可以被其它组件所包含。组件对外提供一些数据访问接口,外界可以通过这些接口向组件传递参数或从组件中获取返回值,但无法获得组件内部的运行信息。通过使用组件,Vue做到了前端开发的面向对象化,即信息的封装与隐藏。我们采用Vue.js作为前端开发框架,也正是为了体现这一点。
RESTful API
传统的Web App是后端与前端写在一起,后端使用类似Java Servlet的技术操控http请求,而前端则使用JSP这样的模板引擎生成。这样做的缺点是,前端和后端互相透明,能够通过模板引擎中的参数随意修改对方的值。显然,这样的开发方式是不利于信息的封装的。
我们的设计使用了RESTful API,前端只需要在特定的时候调用后端提供的API,就可以获得其想要的数据,而无需也不能知道后端具体是如何工作的。同理,后端只需要为前端提供API,无法干涉前端的运作方式。如此这般,前后端都被各自封装起来,内部信息不会对外界暴露,只通过API来交换信息,做到了信息的封装和隐藏。
总结
总而言之,通过使用以下技术手段,我们的项目体现了很好的信息封装与隐藏:
- 面向对象语言与面向对象化的代码设计方法
- 前端将功能模块封装为单文件组件
- 前端与后端之间通过API交流,互相不暴露内部细节
前后端分离
上文中提到,我们的项目的用户展示层有面向社团管理人员和面向普通用户的两个版本。由于微信小程序的一些固有限制,社团管理的许多操作无法在小程序中完成,因此我们单独设置了一个前端界面用于社团管理。这就带来了一个问题,如果前后端不能分离的话,就必须要为小程序和前端界面各做一个后端,这显然会极大提高工作量。
我们采用的前后端分离方案,就是由后端提供统一的RESTful API接口,前端和小程序分别去调用以获得数据。虽然前端Vue.js和小程序的运行机制和代码结构都大相径庭,但由于接口是统一的,所以共用一套后端就可以。我们组的前端开发人员负责编写小程序和前端页面的代码,后端开发人员负责编写后端代码,两组人员之间没有交叠,可以并行开发,靠的就是这一套设计得当的API。RESTful API传递的是与语言环境无关的json格式数据,借此我们做到了完全的前后端分离。
灵活性
基于上文所述,由于前后端是分离开发的,因此在遇到新的需求或需求变更时,只需要新增或修改一下API接口,便可以前端后端同步进行开发,以实现新的需求。由于后端和前端都有良好的模块化特性,许多新需求变更只需要编写一个简单的模块,再将其嵌入整个系统便可以解决。例如,如果用户信息多加了一条“国籍”,只要在API约定的json格式数据中加一个字段,前端为表单加一项输入框,后端为数据库增加一个字段,就可以解决问题。如此这般,我们的项目体现出了高度的灵活性。
错误处理
前端
应对用户的错误输入是提高软件产品体验的重要一环。Vue.js和小程序对于表单验证提供了非常好的支持,可以实时检测用户的输入是否满足特定的格式,甚至可以通过调用后端提供的API连接数据库进行验证。错误的输入将不会作为一个请求发送。
当服务器出现意外,返回错误的信息时,前端和小程序会及时根据HTTP Status Code判断发生了什么异常,并给予用户弹窗提醒。对于最常见的没有找到目标对象的错误,前端会根据后端提供的信息,给用户以详细的提示和操作指导。
后端
对于目前的后端,实际上大部分错误都是一件事:
- 没有找到操作的目标对象
对于这样的错误,一般来说返回一个错误信息,并且配备status_code 404即可。
未来我们会考虑开发更加完备的接口体系。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号