BUAA面向对象设计与构造第一单元总结
1. 基于度量的程序结构分析
第一次作业:
一共实现了两个类:ClassMain类和Monomial类。ClassMain类负责接受输入,处理字符串,将多项式拆分成单项式并传递到Monomial,并合并HashMap结果,化简输出。而Monomial类负责拆分传入的单项式并分解成因子相乘,并经过处理得到一个项的最终系数,指数,放入HashMap,并在指数相同的时候进行系数合并。可以看出,此处我基本上采用的是面向过程的设计。
程序UML图:

度量分析:
1) 方法(method):
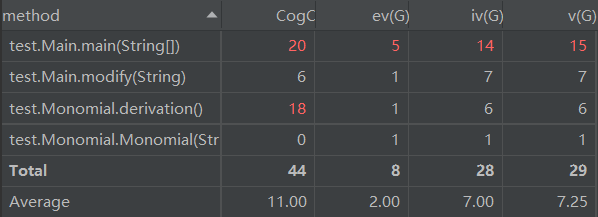
2) 类(class):
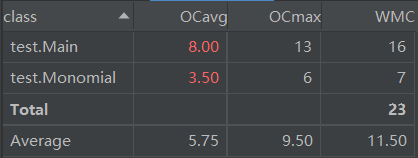
可以看到,第一次的代码无论是从方法层面分析还是从类层面上分析复杂度都有点高,可以看到好几处标红的地方。当一个代码的度量分析交高的时候,就意味着改代码可维护性较差,而且可扩展性等重要指标也相应较差。回到我的代码,由于第一次我并没有怎么深思就上手,导致我将大量的代码都堆在了一起,整体代码显的复杂,臃肿,而且由于本身按照面对过程的思想写的,故可扩展性等也自然不高。这次的分析也直观的反映了这些问题。
第二次作业
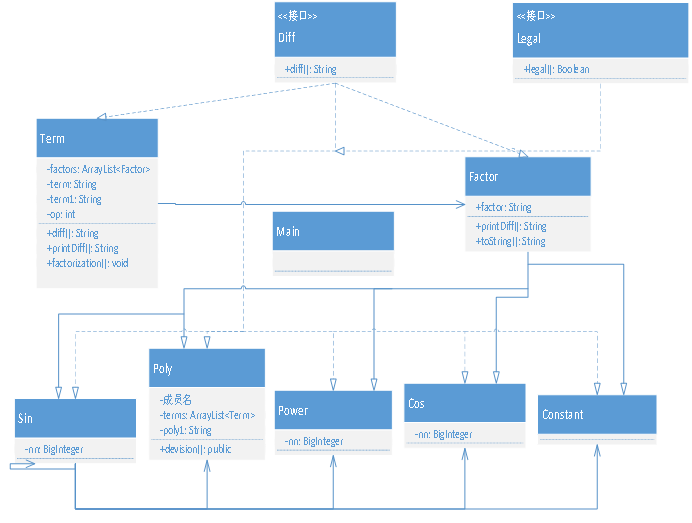
本次作业创建了8个类:Constant, Cos, Factor, Main, Poly, Power, Sin和Term,以及1个接口:Diff。其中,Main类在这次作业中功能十分简单,只是对于输入进行一下简单的处理即可。另外其余7个类可以分成2个大类,即Term类和Factor类,Constant,Cos等其余及各类都继承自Factor类,这是由本题所规定的结构决定的。Factor为一个抽象类,其中规定了基本方法:printDiff()和toString(),分别为将求导结果进行进行字符串形式输出和将factor本身进行字符串输出。而Term类也是规定了一些私有的变量,用来存放Factor及一些必要信息,和需要的相关函数diff(), printDiff(), factorization()(因式分解以填充factor的arraylist)。接口Diff为求导接口,由于每个类都要实现求导这个行为,故单独做出一个接口以实现行为上的继承。而其余几个类分别继承了Factor,并进行了重写相关方法,并补充了其独有的方法。
程序UML图:
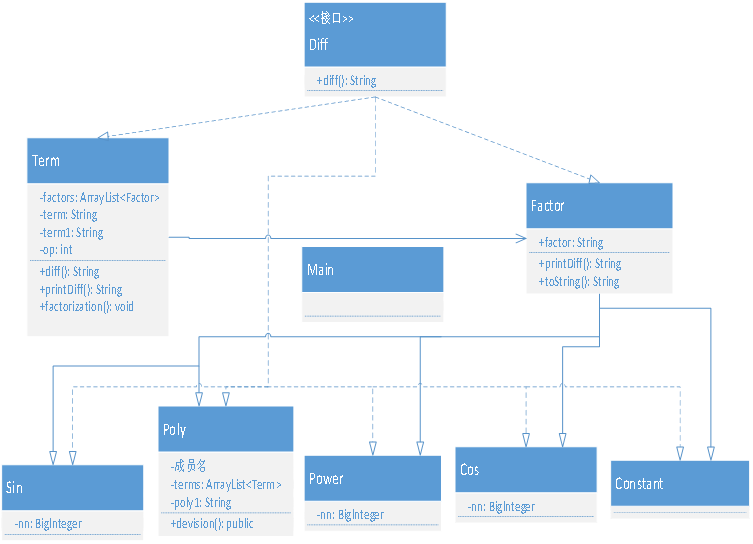
度量分析:
1) 方法method):
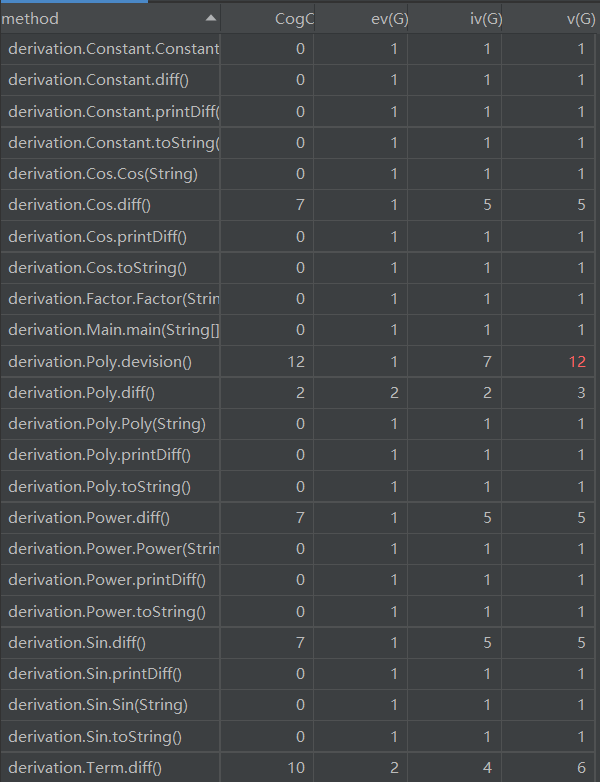
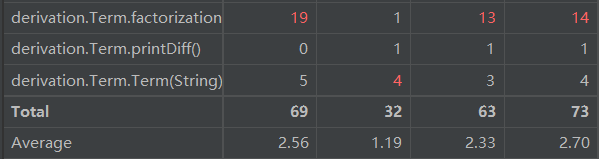
2) 类(class):
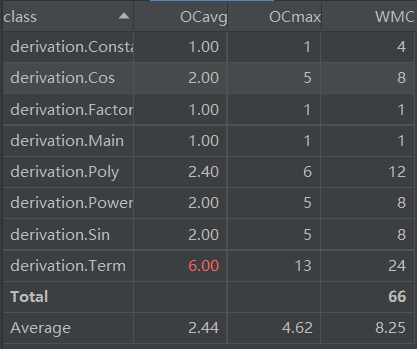
第二次作业和第一次的作业形成了比较鲜明的对比。可以看懂,类和方法的复杂度均下降明显。其原因我认为便是由于采用了面向对象的思想,将一个任务合理均匀的分到了各个对象身上,各司其职,所以单独分析每个类和方法都复杂度较低。当然,也可以看到,Term这个类和方法和其他类相比,显地比较复杂,这是因为,在Term类我要因式分解为各种不同的因子,因子可以为Sin,Cos,Constant,Poly,Power,分支较多,且分解的方法和控制相对而言比较复杂。所以如果可以优化,一般可以考虑在这里做。
第三次作业
本次作业创建了8个类和2个接口,相较于第二次作业仅增加了一个Legal接口,用来判断是否合法。所有的类都实现了该类的行为方法。其余的部分和第二次基本一模一样,只不过Sin和Cos两个类根据题意要求增加了后续的递归操作,关联了所有其他类(除Term)。
度量分析:
1) 方法(method):
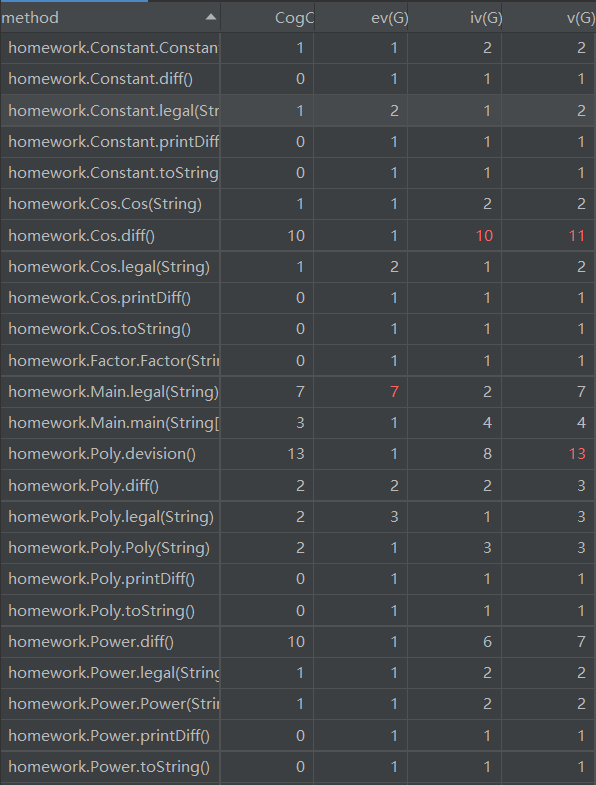
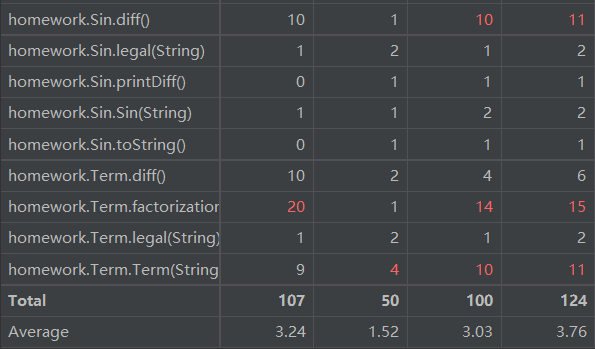
2) 类(class):
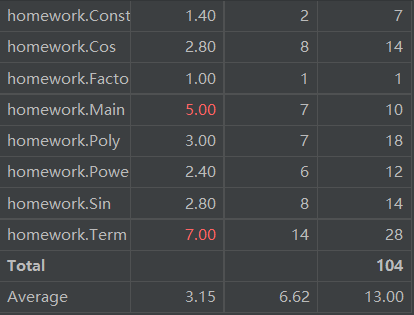
第三次作业和第二次相比复杂度又稍微高了起来,而这个也是在我的预期之内的。原因是我并没有在第二次的框架上做优化,只是在第二次的框架上加了其它功能的代码,比如判断是否合法等。所以也可以看到,复杂度变得高了起来,但是相对于第一次而言,还是效果比较好的。这也说明,我的程序在框架上还有不足之处,如果做一些变动,可以让该程序变得更“OO”一些。
2. 分析程序bug
1. 第一次作业
1) 出现的bug:没有考虑连续加减符号出现的情况
2) 出现原因:没有完全读懂题目的多项式结构就开始做题,忽略了连续三个加减号在中间出现的可能
3) 问题所在的类或方法:出现在了对输入字符串进行化简处理的函数中
4) 原始代码和修改后代码的对比分析:
修改前:
public static String modify(String s) {
String ss = "";
ss = s.replace(" ", "");
ss = ss.replace("\t", "");
ss = ss.replace("**", "^");
ss = ss.replace("++", "+");
ss = ss.replace("--", "+");
ss = ss.replace("+-", "-");
ss = ss.replace("-+", "-");
ss = ss.replace("^+", "^");
ss = ss.replace("*+", "*");
return ss;
}
修改后:
public static String modify(String s) {
String ss = "";
ss = s.replace(" ", "");
ss = ss.replace("\t", "");
ss = ss.replace("**", "^");
Pattern p = Pattern.compile("\\+\\+|\\-\\-|\\+\\-|\\-\\+");
Matcher matcher = p.matcher(ss);
while (matcher.find()) {
//System.out.println(1);
ss = ss.replace("++", "+");
ss = ss.replace("--", "+");
ss = ss.replace("+-", "-");
ss = ss.replace("-+", "-");
matcher = p.matcher(ss);
}
ss = ss.replace("^+", "^");
ss = ss.replace("*+", "*");
return ss;
}
代码行:在代码行数上,并没有什么显著的增加,其实只要把原来的加减号替换策略的四行适当修改增添,写成一个循环即可实现。
圈复杂度:该修改并没有增加该模块函数的控制流语句,故没有增加该函数的圈复杂度,也没有增加整个代码的圈复杂度。
2. 第二次作业
该次作业没有查出bug
3. 第三次作业
强测错误输入:+6*cos((cos(x)*x++1*(x**+0*x*7-+x*x**+8*sin(+ 030))))**+7*x
导致出bug的代码:
//由于空白导致的非法常数
String pattern3 = "[-+]\\s*[-+]\\s*[-+]\\s+\\d+|[*^]\\s*[-+]\\s+\\d+|\\d+\\s+\\d+";
Pattern p3 = Pattern.compile(pattern3);
Matcher m3 = p3.matcher(poly);
if (m3.find()) {
//System.out.println(1);
return false;
}
//do something else
poly = poly.replaceAll("[ \t]+", "");
上面两端是两个不同位置的代码,他们综合起来导致了错误。错误的原因很简单,检查由空白导致的非法常数的时候只考虑了单独常数的情况,没有想到sin()中套了一个看似合法但是却在该次作业的规则下违法的常数形式。归根到底还是对于格式的理解不正确,也是因为我当时为了省事并没有采用正式的递归下降先从头判断一遍格式的原因。
尝试修改后的代码:
在判断格式的情况下单独针对这次错误加一种判断:
String pattern5 = "sin\\(\\s*[-+]\\s+\\d+\\)|cos\\(\\s*[-+]\\s+\\d+\\)";
Matcher m5 = p5.matcher(poly);
if (m5.find()) {
return false;
}
由于我并没有老老实实的用递归下降的方法先来判断格式,所以这只能是说这个bug解决了,不能保证不会因为其他的格式bug而导致错误。这也是我这次设计的最大的一个不足。这也告诉我日后不要因为省事而使程序的正确性打折扣。
代码行:该种解决方法并没有大量增加代码行数。
圈复杂度:从程序总体上来看,并没有增加多余的分支,故圈复杂度并没有改变。
3. 发现别人的bug的策略
我本人基本上没有怎么过多的参与互测这个环节,但是也有一些想法想来分享:
1.黑盒测试
刚开始,我一般不会研读每个人的具体代码,而是会随便试上若干组我认为容易出错的数据点来进行盲测。也就是先不管别人的代码的结构、正确性等问题,而仅从其能否按照题目说明的规定来有效输出来判断该程序的正确性。这样做虽然是没有目的性的,但是对于这道单线程的程序来说,其实通过这一步就能够发现许多乃至全部的可能问题。当然,也有些人创建了自动评测机来进行评测,我是没有这么做。
2. 白盒测试
在互测中,我们可以下载阅读其他人的代码,其实就相当于我们要进行测试的程序对我们而言是透明的。正因为如此,我们可以仔细研读别人的代码,分析它的内部运行逻辑,检查其有无逻辑上的漏洞,并进行逻辑上的覆盖测试。当然,这里的白盒测试并不严谨,在这里就是指通过阅读代码,清晰了对方代码的逻辑后进行的有针对性地全面严格检查。这种方法我认为是对一个人的代码在这里进行能够进行的最强测试,能够最大可能的提高找到bug的能力。但是,在一系列的题目中,我认为综合效果并不如黑盒测试。原因就是改题目虽然复杂,但是其运行过程和逻辑大部分人写的并不复杂,极端情况和易错情况就那么多,而且也不太可能出现那种像多线程那样地不可复现地错误。与其花大量的时间读懂对方的代码,在从逻辑上分析其可能出现的错误,我认为还不如手动或自动生成有针对性地数据进行挨个检查效果来的快。
3.黑盒测试数据生成策略
1) 这里想说的其实就是代码如何在黑盒测试中手动生成尽可能全面,有针对性的数据。在假定生成测试集全部正确的前提下,首先我们要做的就是想一些满足题目要求但容易被人所忽略的情况。就比如第一次作业的测试,包括我在内的很多人初次读题,对于有效格式理解的并不深刻。而有些看似错误的正确格式,就是hack别人的一大利器。就比如符合规范要求的“1+++1”,这三个+连在一起且还不是在开头,会让人多人都开始认为是错误的。而由于题目保证输入的合法性,那么自然很多人的程序在处理这个输入的时候就会出错(当然,1+-+2这种加减相间的效果更好)。
2) 尽量上一些较为极端特殊的数据。这其实是抓别人的化简漏洞所产生的bug分。有些人在尝试化简的时候,往往会因为考虑不周而打破了正确的格式,从而得到了错误的结果。在做这个的时候,我们要想哪些可能在化简的时候处理出错。有些人可能常数项求导不输出,那么我们就单独输入一个常数,比如“1”,如果他没有想到最后检查结果字符串是否长度为0,那么就会输出一个空的字符串,bug就查出来了。还有很多的这种例子,如果在化简上花了较多精力的人可以多在这方面花功夫。
4. 重构经历总结
本次作业我做了3次重构,首先第一次我几乎没有想着按面向对象的思想来做,只是想着用熟悉的面向过程的思想来解决使作业有效即可。其实我之所以第一次分成了两个类还是因为想到这门课是叫做面向对象,所以最终还是造了另外一个类,可以说这就是老师上课说的“披着面向对象外衣的面向过程”,而且外衣也不怎么好看。这也导致了第二次作业我的重构。其实,在第二次作业的最终代码成型前,我还做了一次不成熟的重构,由于代码已被删除,故不多提。第二次重构并不能很好的解决这个问题,所以我又进行了重构,这次在重构前,我详细分析了题目的要求,多项式,单项式,幂函数,常数,三角函数等包含关系详细分析了一番,最终根据该关系创建了总的两大类,以及继承的子类,并采用类似于递归下降的方法成功解决了第二次作业。而因为我在第三次的时候想到了三角函数和幂函数可能会也支持函数的嵌套等操作,故在第二次重构的时候也详细思考了如果第三次作业有了这个要求我的这个构架是否合理,在说服了我自己之后,我进行了重构,并果然在第三次作业得时候基本上的大的框架基本上没有变,只是多了一个判断合理的接口,以及增添了早已想到的三角嵌套。所以第三次的作业我基本上没有花什么太多而时间就搞定了。
第一次类图:

第二次类图
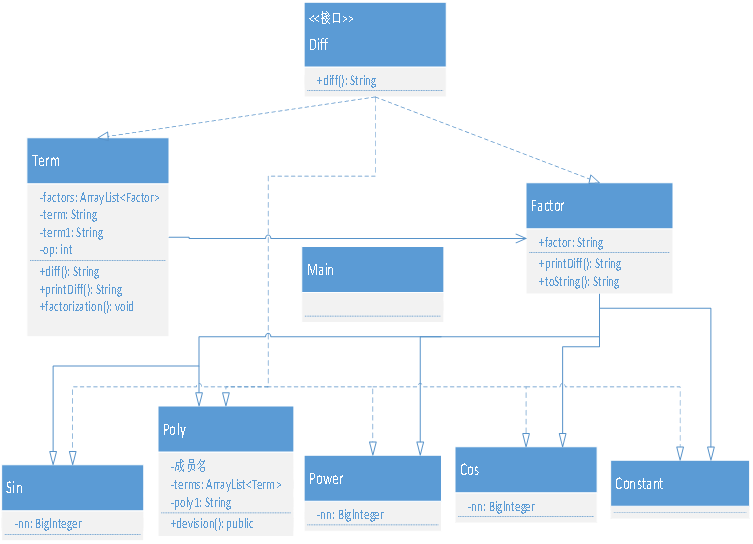
对比上面两个,可以看到第一次的类非常的少,且关系非常的简单。其实,如果观看源代码的话,大多数的操作都是在MainClass类中执行,该结构缺乏弹性,可扩展性也非常非常的差,基本上也就仅限解决第一次作业这种简单的问题。第二次作业的类和接口明显多了起来,且每个类既有自己的独有的方法,也有从父类继承下来的方法。这次重构单独看每个类的代码量都不是很多,就是这些本身不是很复杂的对象结合在一起,实现了比第一次要复杂多的功能。在我看来,这两次的区别就是从视角的改变。
第三次类图
可以参考第一个模块的图,通过与第二次对比发现基本上没什么改变,就是简单的增添了一些互相之间的关系,但是,每个类在第二次实现的函数基本上没有改变,所以第三次作业严格来说不叫重构,而是叫在原有的结构上添枝加叶。这里也可以看出,如果采用了一个比较好的面向对象的架构,我们可以做小的修改而满足新的要求。而这个在实际应用中应付客户的种种奇怪要求是很重要的。
5. 心得体会
在自身开始学习这门课之前,我就好奇的从知乎等软件上查询了一下往届学长的对这门课的看法。当时我发现所有的评论可以分为两派,一种是坚决的“反对派”,一种是坚决的”拥护派“(貌似助教居多)。而且让我没有想到的是这种问题下的回答有时候火药味很浓,让我最印象深刻的是有意见不同的人还互喷了起来。为了不让我提前战队,我就没有继续深入查看各方的评论,决心自己先体验一番再来评价。当然,从各方人的评论中,我就已经知道这门课一定是很有难度,有挑战性的课,也为下学期的苦战做好了一定的心理准备。
现在,经历了这近一个月的OO课程的学习,我发现我当初的初步心理预判是比较准确的。首先,这门课的的确确是很有难度的,它不是像大一的C语言一样,老师先从最基本的常量,变量等知识点开始讲起,代码结构一步步变得复杂起来。这门课主要是借助java语言本身易于面向对象的特性,向我们传输面向对象的思想方法。换句话说,这门课是假定你拥有比较好的java基础的。所以,第一次的作业即使比较简单,但是也仍需要掌握最基本的java语法和一些例如HashMap,ArrayList的容器才可以顺利做完。所以我也很庆幸寒假预习了一下java,并完成了Pre的任务,才让我在完成第一次的作业中不那么被动。
但是,仅仅掌握语法是不足以应付这一系列的作业的。这门课之所以叫面向对象设计与构造,就是要让你用面向对象而不是大一所熟悉的面向过程的思想来解题,而为了让像我这种懒的学习新知识的人学习这些思想并运用,那自然就是出一些只能用面向对象思想方法才能比较容易解决的问题才可以。所以即使我第一次作业没有用什么面向对象的思想就实现了,第二次作业的出现无疑强迫我推倒重构,尽可能地用面向对象地思想来实现。而第三次作业,我觉得其实难度地跃升远远小于第二次作业,它对我而言更像是告诉我面向对象地的设计的优越性,使我基本上不用修改太多的代码就可以满足第三次作业的要求(为OS赢得了时间)。为了完成这一单元的学习,我是花了很多的精力才得以实现,但是就我个人而言,我认为课程组的这三次作业安排还是比较合理的,第一次让人熟悉用法和学习必备的知识,第二次开始强迫你用面向对象的设计来解决问题,而第三次让你体会到面向对象的优越性。我从这一轮的学习中学到了很多,即使自身没有在化简等方面花时间,但是我仍觉得收获颇多。
最后,我也发现这门课程的设计比起以前进步了许多。就拿互测来说,基本上是可以保证一个房间里面的人是水平相同的,基本不会出现一个大佬出现在一群菜鸡或一个菜鸡出现在一群大佬之中的”惨剧“。我从知乎上大致可以看出,在几年前这门课或许处于一个”黑暗时期“,有许许多多的不合理的制度,也因此有许多人在疯狂的吐槽。但对我而言,最起码这三次作业给我的体验还算比较良好,也基本公平,从这里也可以看出课程组是花了大量的精力不断优化这门课的。再过不久又要开启多线程的学习,我也希望能够在新的一轮征途中学习到有用的知识,就像许多人说的一样,痛苦着并快乐着……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号