队列+流量整形+限流策略
一.为什么要流量整形(削峰填谷)
流量冲击(高并发情况下带来的突发流量):
上游调用方(push)不限速,很可能会把下游压垮 eg:上游发起下单操作,下游完成秒杀业务逻辑(库存检查,库存枷锁,余额检查,余额枷锁,订单生成,余额扣减,库存扣减,生成流水,余额解锁,库存解锁)
上游业务简单,每秒发起了10000个请求,下游业务复杂,每秒只能处理2000个请求,上游不限速的下单,导致下游系统被压垮,引发雪崩。
常见的优化方案有两种:
1)上游队列缓冲(put阻塞),限速发送
2)下游队列缓冲(定时或者批量拉取pull,可以起到削平流量),限速执行
如果上游发送流量过大,MQ提供拉模式确实可以起到下游自我保护的作用,会不会导致消息在MQ中堆积?
答:下游MQ-client拉取消息,消息接收方能够批量获取消息,需要下游消息接收方进行优化(提供批处理,比如批量写),否则整体吞吐量低,也会造成mq堆积
二.高并发系统保护策略
1.缓存:
缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。大型网站一般主要是“读”,先走DB再走缓存。在大型“写”系统中,先走缓存,再走DB,对DB进行批处理操作。(累积一些数据,批量写入;内存里面的缓存队列,mq像是一种缓存队列)
2.降级:
根据服务器压力,指定某些服务或者页面的级别(需求不同,降级策略不同),以此释放服务器资源,保证核心任务的正常运行
根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。
根据服务范围:可以砍掉某个功能,可以砍掉某些模块。
主要的目的就是提供有损服务,以保证服务正常运行。
3.限流:
限制系统的输入和输出流量已达到保护系统的目的。
一般来说系统的吞吐量是可以被测算的,一旦达到阈值,就需要限制流量。比如:延迟处理,拒绝处理,部分拒绝处理等等
实际场景中常用的限流策略:
- Nginx前端限流
按照一定的规则如IP、账号、调用逻辑等在Nginx层面做限流
- 业务应用系统限流
1、客户端限流(验证码;获取动态请求路径pathvariable,到达接口地址隐藏的效果)
2、服务端限流(redis限速器,延迟队列)
- 数据库限流
数据库链接池化,Mysql(如max_connections)、Redis(如tcp-backlog)都会有类似的限制连接数的配置。 //backlog:待办事项列表
三.限流算法:
1.计数器算法
@1使用JUC工具包下的AtomicInteger或Semaphore:
public class AtomicIntegerDemo { private static AtomicInteger count = new AtomicInteger(0); public static void exec() { if (count.get() >= 5) { System.out.println("请求用户过多,请稍后在试!"+System.currentTimeMillis()/1000); } else { count.incrementAndGet();//或者单纯的increment try { //处理核心逻辑 TimeUnit.SECONDS.sleep(1); System.out.println("--"+System.currentTimeMillis()/1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { count.decrementAndGet(); } } } }
public class SemaphoreDemo { private static Semaphore semphore = new Semaphore(50);//限流阈值50 public static void exec() { if(semphore.getQueueLength()>100){ //获取等待中的请求数 System.out.println("当前等待排队的任务数大于100,请稍候再试..."); } try { semphore.acquire(); // 处理核心逻辑 TimeUnit.SECONDS.sleep(1); System.out.println("--" + System.currentTimeMillis() / 1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { semphore.release();//释放信号量,给等待队列 } } }
semaphore相对Atomic优点:如果是瞬时的高并发,可以使请求在阻塞队列中排队,而不是马上拒绝请求,从而达到一个流量削峰的目的。
@2使用redis:
将用户id+请求路径(对接口限流)做key,将访问次数count做value,加入过期时间,原理同AtomicInteger
还可以基于redis的列表,用户id做key,value为访问路径,并设置过期时间,当list的长度大于阈值,拒绝 //rpushx(如果list不存在,插入失败),rpush,expire,llen等命令
2.漏桶(leaky bucket)

漏桶算法的主要概念如下:
-
任意速率水滴流入漏桶
- 固定容量的漏桶,按照固定速率流出水滴
-
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。
- 漏桶为空,则无水滴可留
通过它,突发流量可以被整形以便为网络提供一个稳定的流量。 漏桶算法比较好实现,在单机系统中可以使用队列来实现
这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞!!的大小(rate)。
漏桶算法对于存在突发特性的流量来说缺乏效率.
3.令牌桶(Token Bucket)
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。 当桶满时,新添加的令牌被丢弃或拒绝。
令牌桶算法基本可以用下面的几个概念来描述:
- 令牌将按照固定的速率被放入令牌桶中。比如每秒放10个。
- 令牌桶容量固定,超出容量的令牌被丢弃
- 当一个n个字节大小的数据包(请求,突发流量)到达,将从桶中删除m个令牌,接着数据包被发送到网络上(上游发送至下游)。
- 如果桶中的令牌不足m个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
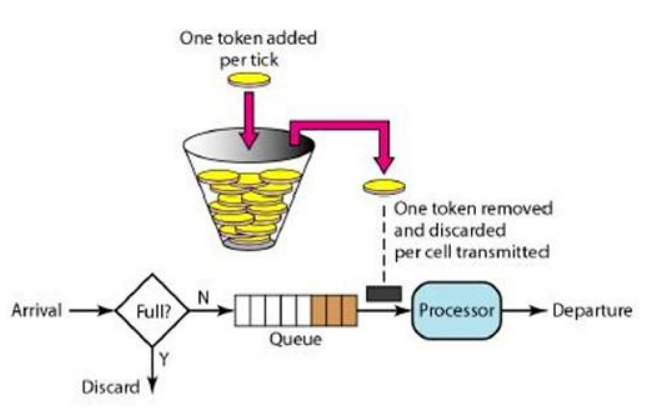
核心:令牌算法是根据向桶中放令牌的速率去控制输出的速率
漏桶和令牌桶的比较
令牌桶可以在运行时控制和调整数据处理的速率,并很好的处理某时的突发流量。
提升数据整体处理速度:放令牌的频率增加(令牌桶),提高漏洞大小(漏桶)
降低整体数据处理速度:增加每次获取令牌的个数(请求大小,多少)或者放令牌的频率减小(令牌桶)。
整体而言,令牌桶算法更优,但是实现更为复杂一些。
限流实战效果
- 生产环境背景
1、服务商接口所能提供的服务上限是400条/s
2、业务方调用服务方QPS可能达到800/s,1200/s,或者更高
3、当服务商接口访问频率超过400/s时,超过的量将拒绝服务,业务方丢失数据
4、业务方为多节点布置(分布式),但调用的是同一个服务商接口 - 限流策略
1、使用guava 的RateLimtier(令牌桶实现者),但是只能用于单机,分布式不可控
2、使用DelayQueue的过程相对较麻烦,耗时可能比较长,而且达不到精准限流的效果
3、使用redis的计数器,精准限流,编写简单,适用于分布式,ok
应用级限流:
应用配置:
对于一个应用系统来说一定会有极限并发/请求数,即总有一个TPS/QPS阀值
Tomcat,其Connector 其中一种配置有如下几个参数:
acceptCount:如果Tomcat的线程都忙于响应,新来的连接会进入队列排队,如果超出排队大小,则拒绝连接;
maxConnections: 瞬时最大连接数,超出的会排队等待;
maxThreads:Tomcat能启动用来处理请求的最大线程数,如果请求处理量一直远远大于最大线程数则可能会僵死。
这里对nginx限流做了解:
Nginx自身有的请求限制模块、流量限制模块(基于令牌桶算法),可以方便的控制令牌速率,自定义调节限流,实现基本的限流控制。
vi /export/servers/nginx/conf/nginx.conf limit_zone one $binary_remote_addr 20m; limit_req_zone $binary_remote_addr zone=req_one:20m rate=12r/s; limit_conn one 10; limit_req zone=req_one burst=120;
可以使用池化技术来限制总资源数:连接池、线程池。比如分配给每个应用的数据库连接是100,那么本应用最多可以使用100个资源,超出了可以等待或者抛异常。
参考:
https://blog.csdn.net/syc001/article/details/72841951
https://www.cnblogs.com/softidea/p/6229543.html
https://www.cnblogs.com/mr-amazing/p/4935672.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号