
RocketMQ
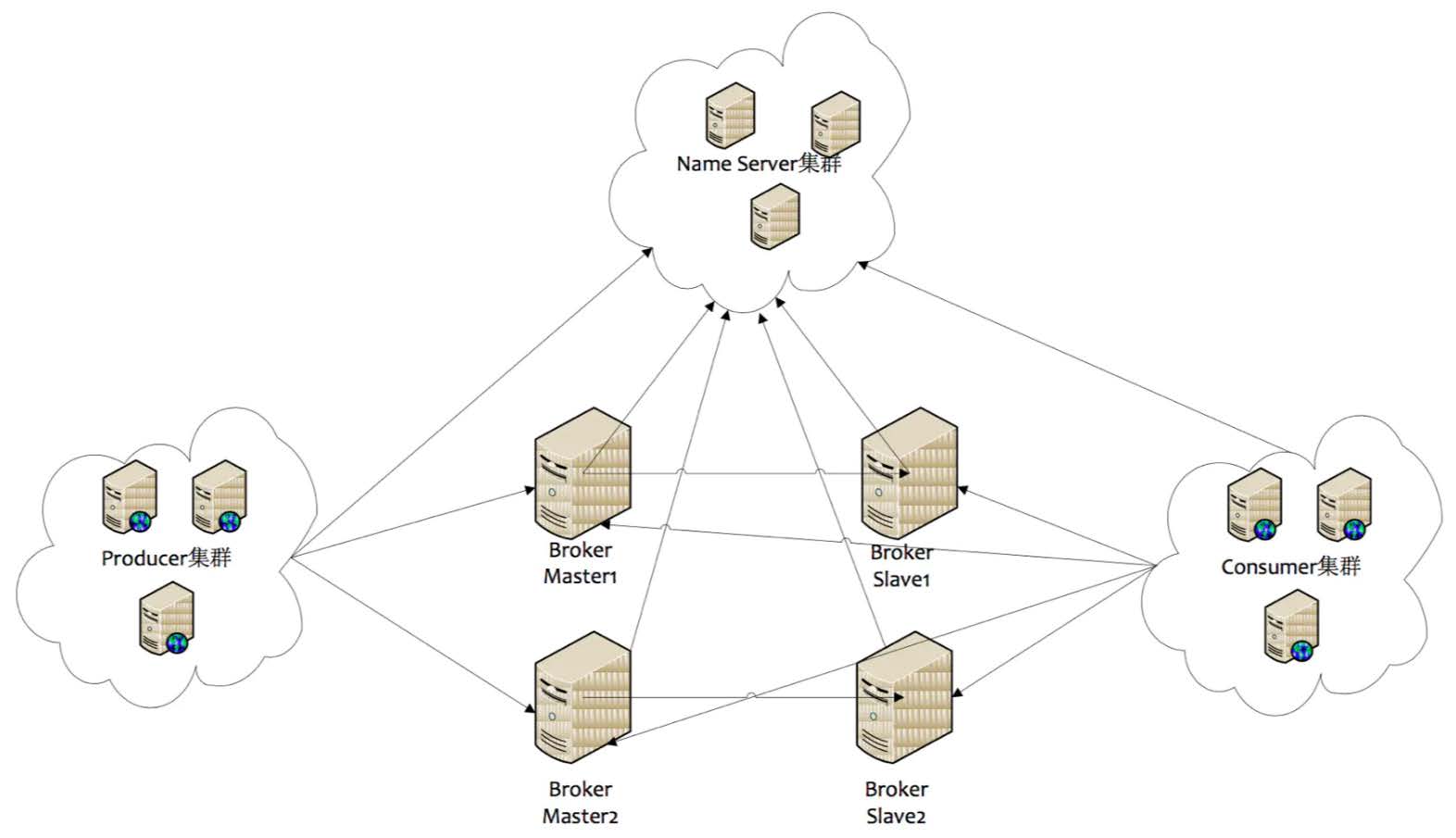
1.1 角色介绍
Producer:消息的发送者;举例:发信者
Consumer:消息接收者;举例:收信者
Broker:暂存和传输消息;举例:邮局
NameServer:管理Broker;举例:各个邮局的管理机构
Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
Message Queue:相当于是Topic的分区;用于并行发送和接收消息
执行流程
1. 启动NameServer,NameServer起来后监听端口,等待Broker、Producer、Consumer连上来,相当于一个路由控制中心。
2. Broker启动,跟所有的NameServer保持长连接,定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系。
3. 收发消息前,先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic。
4. Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,轮询从队列列表中选择一个队列,然后与队列所在的Broker建立长连接从而向Broker发消息。
5. Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息。
1.2 RocketMQ 特性
订阅与发布:消息的发布是指某个生产者向某个topic发送消息;消息的订阅是指某个消费者关注了某个topic中带有某些tag的消息。
消息顺序:消息有序指的是一类消息消费时,能按照发送的顺序来消费。例如:一个订单产生了三条消息分别是订单创建、订单付款、订单完成。消费时要按照这个顺序消费才能有意义,但是同时订单之间是可以并行消费的。RocketMQ可以严格的保证消息有序。
消息过滤:RocketMQ的消费者可以根据Tag进行消息过滤,也支持自定义属性过滤。消息过滤目前是在Broker端实现的。
消息可靠性:RocketMQ在这两种情况下,通过异步复制,可保证99%的消息不丢。通过同步双写技术可以完全避免,同步双写会影响性能,适合对消息可靠性要求极高的场合,例如与Money相关的应用。
至少一次:至少一次(At least Once)指每个消息必须投递一次。Consumer先Pull消息到本地,消费完成后,才向服务器返回ack,如果没有消费一定不会ack消息。
回溯消费:Broker在向Consumer投递成功消息后,消息仍然需要保留。并且重新消费一般是按照时间维度,例如由于Consumer系统故障,恢复后需要重新消费1小时前的数据,那么Broker要提供一种机制,可以按照时间维度来回退消费进度。RocketMQ支持按照时间回溯消费,时间维度精确到毫秒。
事务消息:RocketMQ的事务消息提供类似 X/Open XA 的分布事务功能,通过事务消息能达到分布式事务的最终一致性。
定时消息:定时消息(延迟队列)是指消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic。broker有配置项messageDelayLevel,默认值为“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”,18个level。
消息重试:1) retryTimesWhenSendFailed:同步发送失败重投次数,默认为2,因此生产者会最多尝试发送retryTimesWhenSendFailed + 1次。不会选择上次失败的broker,尝试向其他broker发送,最大程度保证消息不丢失。超过重投次数,抛异常,由客户端保证消息不丢失。当出现RemotingException、MQClientException和部分MQBrokerException时会重投。
2) retryTimesWhenSendAsyncFailed:异步发送失败重试次数,异步重试不会选择其他broker,仅在同一个broker上做重试,不保证消息不丢。
3) retryAnotherBrokerWhenNotStoreOK:消息刷盘(主或备)超时或slave不可用(返回状态非SEND_OK),是否尝试发送到其他broker,默认false。十分重要消息可以开启。
流量控制:生产者流控,因为broker处理能力达到瓶颈;消费者流控,因为消费能力达到瓶颈。
1) 生产者流控:
commitLog文件被锁时间超过osPageCacheBusyTimeOutMills时,参数默认为1000ms,发生流控。如果开启transientStorePoolEnable = true,且broker为异步刷盘的主机,且transientStorePool中资源不足,拒绝当前send请求,发生流控。broker每隔10ms检查send请求队列头部请求的等待时间,如果超过waitTimeMillsInSendQueue,默认200ms,拒绝当前send请求,发生流控。broker通过拒绝send 请求方式实现流量控制。注意,生产者流控,不会尝试消息重投。
2) 消费者流控:消费者本地缓存消息数超过pullThresholdForQueue时,默认1000。消费者本地缓存消息大小超过pullThresholdSizeForQueue时,默认100MB。消费者本地缓存消息跨度超过consumeConcurrentlyMaxSpan时,默认2000。消费者流控的结果是降低拉取频率。
死信队列:死信队列用于处理无法被正常消费的消息。(如确认没有问题后,可在控制台重新发送消息)
消费模式:RocektMQ支持Push和Pull模式,Push模式也是采用消费端主动拉取的方式,轮询从broker拉取消息。
1.3 RocketMQ高级特性及原理
提升写入的性能:1.可靠性要求不高的场景如日志收集可以采用Oneway方式发送。Oneway方式不等待应答,写入客户端的socket缓冲区就返回。2.增加Producer的并发量,使用多个Producer发送消息。(多个Producer同时写不会造成性能问题,RocketMQ采用顺序写可以保证高性能)。
提升消费的性能:1.增加Consumer实例,设置单个Consumer并行处理的线程数(consumeThreadMin和consumeThreadMax)。 2. 批量方式消费,设置consumeMessageBatchMaxSize,设置为n,每次收到的是一个长度为n的消息链表。3. 检测延时情况,跳过不重要的消息。
消息存储:RocketMQ是用文件系统做的持久化,采用顺序写保证写入速度。CommitLog负责存储消息文件,每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件, 存储的是指向物理存储的地址。
过滤消息方式:1. Tag过滤方式。2.SQL92(conf/broker.conf-enablePropertyFilter=true)
零拷贝: 数据拷贝方式只有2次,同kafka。
同步复制/异步复制:主从复制的俩种方式。
高可用:分布式集群是通过Master和Slave的配合达到高可用的。brokerId的值为0表明这个Broker是Master,大于0是Slave。Master支持读写,Slave支持读。Master繁忙或不可用时,会自动切换到Slave读,这就达到了消费高可用。创建Topic的时候,把Topic的多个Message Queue创建在多个Broker组上,某些Broker发生故障后,其它组的Master仍可发消息。(暂不支持Slave自动变Master,需要重启改配置文件)
负载均衡:发送消息可以采取轮询的方式发送,可以自定义选择发到某个队列。
限流:消费端设置最大消费线程数,每次拉取消息条数等。PushConsume如果发现大量消息未消费,就会间隔一段时间再拉取消息。使用Sentinel做限流。Sentinel可以把突然到来的大量请求以匀速的形式均摊,以固定的间隔时间让请求通过,以稳定的速度逐步处理这些请求,起到“削峰填谷”的效果,从而避免流量突刺造成系统负载过高。
NameServer: NameServer互相独立,彼此没有通信关系,单台NameServer挂掉,不影响其他NameServer。NameServer不去连接别的机器,不主动推消息。
单个Broker(Master、Slave)每隔30s向所有NameServer发送心跳,心跳包含了自身的topic配置信息。Consumer随机与一个NameServer建立长连接,如果该NameServer断开,则从NameServer列表中查找下一个进行连接。Producer随机与一个NameServer建立长连接,每隔30秒(此处时间可配置)从NameServer获取Topic的最新队列情况。
RocketMQ为什么不使用ZooKeeper而自己开发NameServer?
根据CAP理论,同时最多只能满足两个点,而zookeeper满足的是CP,也就是说zookeeper并不能保证服务的可用性,zookeeper在进行选举的时候,整个选举的时间太长,期间整个集群都处于不可用的状态,而这对于一个注册中心来说肯定是不能接受的,作为服务发现来说就应该是为可用性而设计。
基于性能的考虑,NameServer本身的实现非常轻量,而且可以通过增加机器的方式水平扩展,增加集群的抗压能力,而zookeeper的写是不可扩展的,实现水平扩展比较复杂。
持久化的机制带来的问题,ZooKeeper的ZAB协议对每一个写请求,会在每个ZooKeeper节点上写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,而对于一个简单的服务发现的场景来说,这其实没有太大的必要,这个实现方案太重了。而且本身存储的数据应该是高度定制化的。
消息发送应该弱依赖注册中心,而RocketMQ的设计理念也正是基于此,生产者在第一次发送消息的时候从NameServer获取到Broker地址后缓存到本地,如果NameServer整个集群不可用,短时间内对于生产者和消费者并不会产生太大影响。
RocketMQ为什么这么快?
是因为使用了顺序存储、Page Cache和异步刷盘。我们在写入commitlog的时候是顺序写入的,这样比随机写入的性能就会提高很多写入commitlog的时候并不是直接写入磁盘,而是先写入操作系统的PageCache。最后由操作系统异步将缓存中的数据刷到磁盘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号