
RabbitMQ学习笔记
一、为什么使用消息中间件?
参考原文消息中间件优缺点https://blog.csdn.net/shi860715/article/details/109312417
场景1:A系统发送数据到BCD 三个系统,通过接口调用发送。如果E系统也要这个数据呢?那如果C系统现在不需要了呢?A系统负责人会崩溃,因为要一直不停的根据需求修改代码。
使用MQ: A系统生产一条数据发送到MQ中, 哪个系统需要数据就去MQ中消费,不需要就取消对MQ的消费。A系统不需要关系数据发给谁,也不需要考虑别人是否调用成功,失败超时等情况。也就是系统之间完成了解耦。
场景2:A系统 ,每天22个小时,每秒并发量在30个数据左右。只有在晚上8点-10点并发量在5k+左右。但是系统是基于MySQL数据库的,大量的数据请求涌入mysql,会导致mysql数据库崩溃。(一般mysql数据库也就是每秒2000个请求)
使用MQ:每秒5k请求写入MQ, A系统每秒中处理2k个请求。因为MYSQL的数据请求瓶颈的问题,所以A系统每秒从MQ中拉去2k个请求来处理。哪怕是业务高峰的时候来临,A系统也不会挂掉。因为它每秒就处理2k+请求。这种情况可以称之为流量削峰。
场景3:如果场景三描述的是A系统受到一个请求,需要写本地库,花费3ms,而其中还需要调用B系统,花费300ms,c系统 450ms,d系统 200ms。这样这个一个业务就要花费3+300+450+200=953ms。正常的用户请求正常控制在200ms内完成。等待1s 用户体验很差。
使用MQ: 请求写到本地库3ms, 发送消息5ms,其它系统异步调用, 用户只需等待8ms。 体现了异步调用的好处。
缺点: 引入MQ后,系统复杂性提高。消息中间件存在一些瓶颈和一致性问题, 对于开发来讲不直观且不易调试,有额外成本。
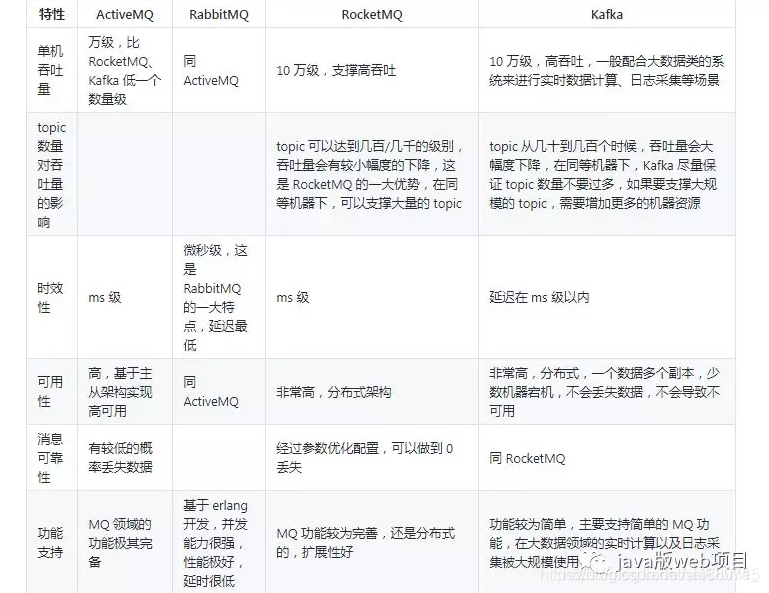
消息中间件对比:
二、RabbitMQ介绍、架构
2.1 整体逻辑架构
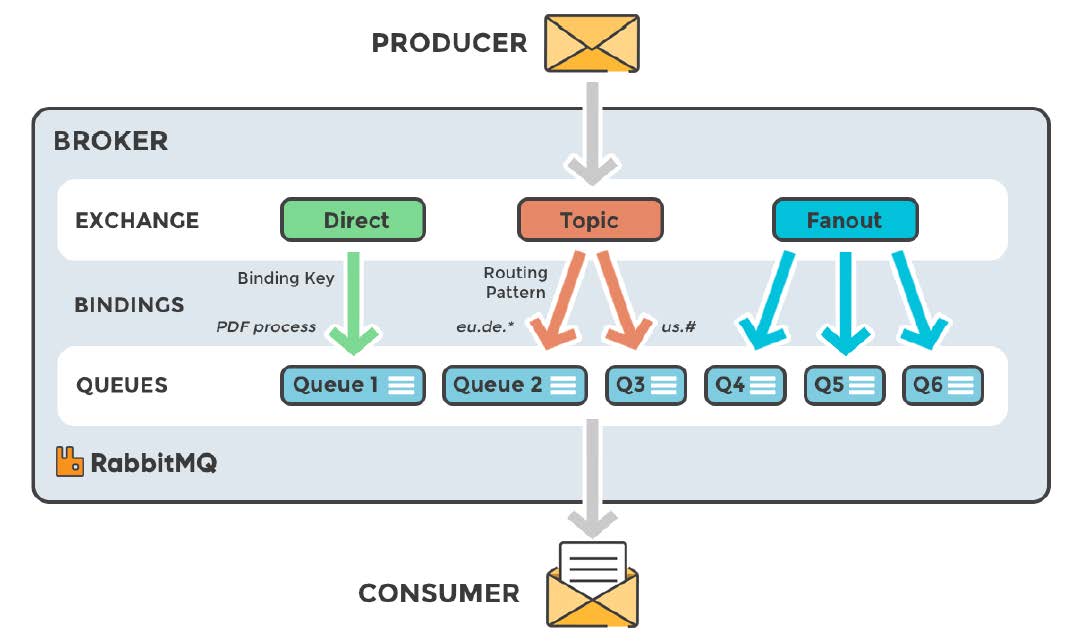
2.2 RabbitMQ Exchange类型
RabbitMQ常用的交换器类型有: fanout 、direct 、topic 、headers(性能差不实用) 四种。
Fanout: 会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列。
Direct: direct类型的交换器路由规则很简单,它会把消息路由到那些BindingKey和RoutingKey完全匹配的队列中。
Topic:topic类型的交换器在direct匹配规则上进行了扩展,也是将消息路由到BindingKey和RoutingKey相匹配的队列中,这里的匹配规则稍微不同,它约定:
BindingKey和RoutingKey一样都是由"."分隔的字符串;BindingKey中可以存在两种特殊字符“*”和“#”,用于模糊匹配,其中"*"用于匹配一个单词,"#"用于匹配多个单词(可以是0个)。
2.3 RabbitMQ数据存储
RabbitMQ有俩种消息类型:持久化消息和非持久化消息。持久化消息在到达队列时写入磁盘,同时会内存中保存一份备份,当内存吃紧时,消息从内存中清除。这会提高一定的性能。非持久化消息一般只存于内存中,当内存压力大时数据刷盘处理,以节省内存空间。
为什么消息的堆积导致性能下降?
在系统负载较高时,消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,这样会增加处理每个消息的平均开销。因为要花更多的时间和资源处理“堆积”的消息,如此用来处理新流入的消息的能力就会降低,使得后流入的消息又被积压到很深的队列中,继续增大处理每个消息的平均开销,继而情况变得越来越恶化,使得系统的处理能力大大降低。
应对这一问题一般有3种措施:1. 增加prefetch_count的值,即一次发送多条消息给消费者,加快消息被消费的速度。2. 采用multiple ack,降低处理ack带来的开销 3. 流量控制。
2.4 常用命令
//启用RabbitMQ的管理插件
rabbitmq-plugins enable 1 rabbitmq_management
//开启RabbitMQ
systemctl start rabbitmq-server 或 rabbitmq-server rabbitmq-server -detached(后台启动)
//停止RabbitMQ和Erlang VM
rabbitmqctl stop
//查看所有队列
rabbitmqctl list_queues
//查看所有虚拟主机
rabbitmqctl list_vhosts
//添加用户
rabbitmqctl add_user username password
//列出所有用户:
rabbitmqctl list_users
//列出所以虚拟主机:
rabbitmqctl list_vhosts
//删除虚拟主机:
rabbitmqctl delete_vhost vhost vhostpath
2.5 工作流程
生产者发送消息的流程:1. 生产者连接RabbitMQ,建立TCP连接( Connection),开启信道(Channel)。2. 生产者声明一个Exchange(交换器),并设置相关属性,比如交换器类型、是否持久化等。3. 生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等。4. 生产者通过bindingKey (绑定Key)将交换器和队列绑定( binding )起来。5. 生产者发送消息至RabbitMQ Broker,其中包含routingKey (路由键)、交换器等信息。6. 相应的交换器根据接收到的routingKey 查找相匹配的队列。7. 如果找到,则将从生产者发送过来的消息存入相应的队列中。8. 如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者9. 关闭信道。10. 关闭连接。
消费者接收消息的过程:1. 消费者连接到RabbitMQ Broker ,建立一个连接(Connection ) ,开启一个信道(Channel) 。2. 消费者向RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数, 以及
做一些准备工作。3. 等待RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息。4. 消费者确认( ack) 接收到的消息。5. RabbitMQ 从队列中删除相应己经被确认的消息。6. 关闭信道。7. 关闭连接。
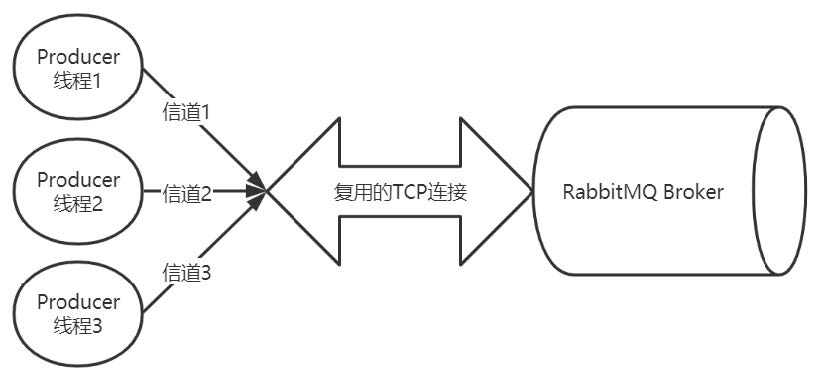
Channel:生产者和消费者,需要与RabbitMQ Broker 建立TCP连接,也就是Connection 。一旦TCP 连接建立起来,客户端紧接着创建一个AMQP 信道(Channel),每个信道都会被指派一个唯一的ID。信道是建立在Connection 之上的虚拟连接, RabbitMQ 处理的每条AMQP 指令都是通过信道完成的。为什么不直接使用TCP连接,而是使用信道?RabbitMQ 采用类似NIO的做法,复用TCP 连接,减少性能开销,便于管理。
三、Rabbitmq高级特性
3.1 消息可靠性
1. 分布式锁
在操作某条数据时先锁定,可以用redis或zookeeper等常用框架来实现。 比如我们在修改账单时,先锁定该账单,如果该账单有并发操作,后面的操作只能等待上一个操作的锁释放后再依次执行。
优点:能够保证数据强一致性。 缺点:高并发场景下可能有性能问题。
2. 消息队列是为了保证最终一致性,我们需要确保消息队列有ack机制,客户端收到消息并消费处理完成后,客户端发送ack消息给消息中间件 如果消息中间件超过指定时间还没收到ack消息,则定时去重发消息。
优点:异步、高并发 缺点:有一定延时、数据弱一致性,并且必须能够确保该业务操作肯定能够成功完成,不可能失败。
我们还可以从以下几方面来保证消息的可靠性:
1. 客户端代码中的异常捕获,包括生产者和消费者。 如果有异常则执行回滚业务操作或者执行重发操作等。
2. AMQP/RabbitMQ的事务机制。 channel可以设置为事务模式,channel.txSelect(); channel.basicPubish(); channel.txCommit();这种方式性能开销较大,一般不采用。
3. 发送端确认机制:生产者将信道设置成confirm(确认)模式,一旦信道进入confirm 模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1 开始),一旦消息被投递到所有匹配的队列之后(如果消息和队列是持久化的,那么确认消息会在消息持久化后发出),RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这样生产者就知道消息已经正确送达了。
4. 消息持久化机制:Exchange的持久化。通过定义时设置durable参数为ture来保证Exchange相关的元数据不丢失;Queue的持久化也是通过定义时设置durable参数为ture来保证Queue相关的元数据不丢失;消息的持久化通过将消息的投递模式 (BasicProperties中的deliveryMode属性)设置为2即可实现消息的持久化,保证消息自身不丢失
5. 消费者确认机制:ackMode为NONE自行捕获异常并维护到异常记录表,定时扫描处理。 AUTO不捕获异常把消息放到其它节点,默认一直重发直到消费完成返回ack或者消息过期。MANUAL手动调用channel的相关方法返回ack。
6. 消费端限流:RabbitMQ可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞; RabbitMQ中有一种QoS保证机制,可以限制Channel上接收到的未被Ack的消息数量,如果超过这个数量限制RabbitMQ将不会再往消费端推送消息; 提升下游吞吐量和缩短消费过程的耗时(1. 优化应用程序的性能,缩短响应时间 2. 增加消费者节点实例 3. 调整并发消费的线程数,并非越大越好,需要大量压测调优至合理值)
7. 消息幂等性:借助数据库唯一索引,重复插入直接报错,事务回滚; 前置检查,如先查看是否有记录,没有再插入。或者用乐观锁、CAS机制。唯一Id机制,比较通用的方式。对于每条消息我们都可以生成唯一Id,消费前判断Tair中是否存在(MsgId做Tair排他锁的key),消费成功后将状态写入Tair中,这样就可以防止重复消费了
8. 可以开启重试,设置重试次数,重试间隔。
传输保证分为三个层级1. 最多一次。消息可能会丢失,但绝不会重复传输 2. 最少一次。消息绝不会丢失,但可能会重复传输 3. 恰好一次。每条消息肯定会被传输一次且仅传输一次。RabbitMQ 支持其中的“最多一次”和“最少一次”。
3.2 TTL机制、死信队列
京东订单超过30分钟未支付,则会自动取消订单,可以用TTL机制来实现。俩种方法可以设置TTL:1. 通过Queue属性设置,队列中所有消息都有相同的过期时间。2. 对消息自身进行单独设置,每条消息的TTL可以不同。消息在队列中的生存时间一旦超过设置的TTL值时,就会变成“死信”(Dead Message),会存入死信队列。以下几种情况都可能导致消息进入死信队列1. 消息被拒绝;2. 消息过期;3. 队列达到最大长度。
3.3 延迟队列
延迟消息是指的消息发送出去后并不想立即就被消费,而是需要等(指定的)一段时间后才触发消费。
例如在支付宝上面买电影票,锁定了一个座位后系统默认会帮你保留15分钟时间,如果15分钟后还没付款那么不好意思系统会自动把座位释放掉。怎么实现类似的功能呢?
1. 可以用定时任务每分钟扫一次,发现有占座超过15分钟还没付款的就释放掉。但是这样做很低效,很多时候做的都是些无用功;
2. 可以用分布式锁、分布式缓存的被动过期时间,15分钟过期后锁也释放了,缓存key也不存在了;
3. 还可以用延迟队列,锁座成功后会发送1条延迟消息,这条消息15分钟后才会被消费,消费的过程就是检查这个座位是否已经是“已付款”状态;
四、RabbitMQ集群和运维
目前集群主要有以下几种模式:
主备模式:只有一个节点在工作,只是在主节点发生故障时,请求切换到备份节点,实现故障转移。使用独立存储时需要借助复制、镜像同步等技术,数据会有延迟、不一致等问题(CAP定律),使用共享存储时就不会有状态同步这个问题。
主从模式:一定程度的双活,容量对等,最常见的是读写分离。通常也需要借助复制技术,或者要求上游实现双写来保证节点数据一致。
主主模式:两边都可以读写,互为主备。如果两边同时写入很容易冲突,所以通常实现的都是“伪主主模式”,或者说就是主从模式的升级版,只是新增了主从节点的选举和切换。
分片集群:不同节点保存不同的数据,上游应用或者代理节点做路由,突破存储容量限制,分摊读写负载;典型的如MongoDB的分片、MySQL的分库分表、Redis集群。
异地多活:“两地三中心”是金融行业经典的容灾模式(有资源闲置的问题),“异地多活”才是王道。
RabbitMQ集群
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,并可以通过添加更多的节点来线性扩展消息通信的吞吐量。当失去一个RabbitMQ节点时,客户端能够重新连接到集群中的任何其他节点并继续生产和消费。RabbitMQ集群中的所有节点都会备份所有的元数据信息,包括:1. 队列元数据:队列的名称及属性;2. 交换器:交换器的名称及属性;3. 绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;4. vhost元数据:为vhost内的队列、交换器和绑定提供命名空间及安全属性。
基于存储空间和性能的考虑,RabbitMQ集群中的各节点存储的消息是不同的(有点儿类似分片集群,各节点数据并不是全量对等的),各节点之间同步备份的仅仅是上述元数据以及QueueOwner(队列所有者,就是实际创建Queue并保存消息数据的节点)的指针。当集群中某个节点崩溃后,该节点的队列进程和关联的绑定都会消失,关联的消费者也会丢失订阅信息,节点恢复后(前提是消息有持久化)消息可以重新被消费。虽然消息本身也会持久化,但如果节点磁盘存储设备发生故障那同样会导致消息丢失。总的来说,该集群模式只能保证集群中的某个Node挂掉后应用程序还可以切换到其他Node上继续地发送和消费消息,但并无法保证原有的消息不丢失,所以并不是一个真正意义的高可用集群。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号