MySQL 8.0 新特性
一、账号与安全
1、用户创建于授权
MySQL 8.0 创建用户和用户授权命令需要分开执行,MySQL 5.7之前直接直接使用 grant 命令实现两步操作。
[5.7.37-log]>grant all privileges on *.* to lzy@'%' identified by '123456'; Query OK, 0 rows affected, 1 warning (0.00 sec)
[8.0.27]>grant all privileges on *.* to lzy@'%' identified by '123456'; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'identified by '123456'' at line 1 [8.0.27]>create user lzy@'%' identified by '123456'; Query OK, 0 rows affected (0.03 sec) [8.0.27]>grant all privileges on *.* to lzy@'%'; Query OK, 0 rows affected (0.02 sec) [8.0.27]>flush privileges; Query OK, 0 rows affected (0.01 s
2、认证插件更新
MySQL 5.7 的插件为:mysql_native_password
MySQL 8.0 认证插件更新为:caching_sha2_password
插件升级后,破解密码难度增大,安全性大大增强,但是,在远程访问时,需要指定目标服务器mysql的RSA公钥,否则,使用明文密码进行访问,会报错。可以想象到,在远程管理大量的服务器时,这明显会降低办事效率,所以目前还是建议使用mysql_native_password插件。
远程明文访问报错信息:Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connection
[5.7.37-log]>show variables like 'default_authentication_plugin'; +-------------------------------+-----------------------+ | Variable_name | Value | +-------------------------------+-----------------------+ | default_authentication_plugin | mysql_native_password | +-------------------------------+-----------------------+ 1 row in set (0.00 sec) [5.7.37-log]>select user,host,plugin from mysql.user; +---------------+-----------+-----------------------+ | user | host | plugin | +---------------+-----------+-----------------------+ | root | localhost | mysql_native_password | | mysql.session | localhost | mysql_native_password | | mysql.sys | localhost | mysql_native_password | | lzy | % | mysql_native_password | +---------------+-----------+-----------------------+ 4 rows in set (0.00 sec
[8.0.27]>show variables like 'default_authentication_plugin'; +-------------------------------+-----------------------+ | Variable_name | Value | +-------------------------------+-----------------------+ | default_authentication_plugin | caching_sha2_password | +-------------------------------+-----------------------+ 1 row in set (0.03 sec) --指定插件 [8.0.27]>create user test_user@'%' identified with mysql_native_password by '123456'; Query OK, 0 rows affected (0.02 sec) [8.0.27]>select user,host,plugin from mysql.user; +------------------+-----------+-----------------------+ | user | host | plugin | +------------------+-----------+-----------------------+ | lzy | % | caching_sha2_password | | test_user | % | mysql_native_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+ 6 rows in set (0.00 se
3、密码重用策略
新增3个参数用于控制密码重复使用策略
- password_history:限制修改的密码必须是多少次内不重复,修改的密码信息会记录在mysql.password_history中,修改密码时会与表中的信息对比,默认值为0,即不限制。
[8.0.27]>set persist password_history = 2; Query OK, 0 rows affected (0.00 sec) [8.0.27]>alter user test_user@'%' identified by '123456'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>alter user test_user@'%' identified by '123456'; ERROR 3638 (HY000): Cannot use these credentials for 'test_user@%' because they contradict the password history policy [8.0.27]>alter user test_user@'%' identified by '123457'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>alter user test_user@'%' identified by '123458'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>alter user test_user@'%' identified by '123456'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>select * from mysql.password_history; +------+-----------+----------------------------+-------------------------------------------+ | Host | User | Password_timestamp | Password | +------+-----------+----------------------------+-------------------------------------------+ | % | test_user | 2022-04-25 15:23:15.012121 | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 | | % | test_user | 2022-04-25 15:23:10.886168 | *2727EA229A9F2F2D696375270574BF7E658136DD | +------+-----------+----------------------------+-------------------------------------------+ 2 rows in set (0.0
- password_reuse_interval:密码重用间隔时间,单位:天;默认值为0,即不限制。
- password_require_current:修改密码时必须要提供当前密码,默认关闭;超级用户进行操作时不受限制。
[8.0.27]>set persist password_require_current = 1; Query OK, 0 rows affected (0.00 sec) [8.0.27]>select user(); +---------------------+ | user() | +---------------------+ | test_user@localhost | +---------------------+ 1 row in set (0.00 sec) [8.0.27]>alter user test_user@'%' identified by '123451'; ERROR 3892 (HY000): Current password needs to be specified in the REPLACE clause in order to change it. [8.0.27]>alter user test_user@'%' identified by '123451' replace '123456'; Query OK, 0 rows affected (0.00 s
4、新增角色管理
[8.0.27]>create role dba; Query OK, 0 rows affected (0.01 sec) [8.0.27]>select host,user from mysql.user; +-----------+------------------+ | host | user | +-----------+------------------+ | % | dba | | % | jack | | % | lzy | | % | test_user | | localhost | mysql.infoschema | | localhost | mysql.session | | localhost | mysql.sys | | localhost | root | +-----------+------------------+ 8 rows in set (0.01 sec) [8.0.27]>grant all privileges on test.* to dba; Query OK, 0 rows affected (0.02 sec) [8.0.27]>show grants for dba; +-----------------------------------------------+ | Grants for dba@% | +-----------------------------------------------+ | GRANT USAGE ON *.* TO `dba`@`%` | | GRANT ALL PRIVILEGES ON `test`.* TO `dba`@`%` | +-----------------------------------------------+ 2 rows in set (0.00 sec) [8.0.27]>create user jack@'%' identified by '123456'; Query OK, 0 rows affected (0.03 sec) [8.0.27]>grant dba to jack@'%'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>show grants for jack@'%'; +----------------------------------+ | Grants for jack@% | +----------------------------------+ | GRANT USAGE ON *.* TO `jack`@`%` | | GRANT `dba`@`%` TO `jack`@`%` | +----------------------------------+ 2 rows in set (0.00 sec) [8.0.27]>show grants for jack@'%' using dba; +------------------------------------------------+ | Grants for jack@% | +------------------------------------------------+ | GRANT USAGE ON *.* TO `jack`@`%` | | GRANT ALL PRIVILEGES ON `test`.* TO `jack`@`%` | | GRANT `dba`@`%` TO `jack`@`%` | +------------------------------------------------+ 3 rows in set (0.00 sec) [8.0.27]>set default role all to jack@'%'; Query OK, 0 rows affected (0.02 sec) [8.0.27]>select * from mysql.default_roles; +------+------+-------------------+-------------------+ | HOST | USER | DEFAULT_ROLE_HOST | DEFAULT_ROLE_USER | +------+------+-------------------+-------------------+ | % | jack | % | dba | +------+------+-------------------+-------------------+ 1 row in set (0.00 sec) [8.0.27]>select * from mysql.role_edges; +-----------+-----------+---------+---------+-------------------+ | FROM_HOST | FROM_USER | TO_HOST | TO_USER | WITH_ADMIN_OPTION | +-----------+-----------+---------+---------+-------------------+ | % | dba | % | jack | N | +-----------+-----------+---------+---------+-------------------+ 1 row in set
不给用户设置默认角色时,访问对应数据库会报错。
[8.0.27]>select user(); +----------------+ | user() | +----------------+ | jack@localhost | +----------------+ 1 row in set (0.00 sec) [8.0.27]>use test; ERROR 1044 (42000): Access denied for user 'jack'@'%' to database 'test' [8.0.27]>select current_role(); +----------------+ | current_role() | +----------------+ | NONE | +----------------+ 1 row in set (0.00 sec) [8.0.27]>set role dba; Query OK, 0 rows affected (0.01 sec) [8.0.27]>use test; Database changed [8.0.27]>select * from test.tb; Empty set (0.00
二、索引
1、隐藏索引
隐藏索引只对优化器隐藏,而且仍需维护成本;主键不可设置为隐藏;
使用场景:灰度发布
[8.0.27]>alter table tb add index idx_a(a) invisible;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>show index from tb\G
*************************** 1. row ***************************
Table: tb
Non_unique: 1
Key_name: idx_a
Seq_in_index: 1
Column_name: a
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: NO
Expression: NULL
1 row in set (0.00 sec)
[8.0.27]>explain select * from tb where a=1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
[8.0.27]>set session optimizer_switch = "use_invisible_indexes=on";
Query OK, 0 rows affected (0.00 sec)
[8.0.27]>explain select * from tb where a=1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: ref
possible_keys: idx_a
key: idx_a
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 sec)
[8.0.27]>alter table tb alter index idx_a visible;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnin
2、降序索引
- MySQL 5.7 创建降序索引时,实际上还是按升序创建,8.0 则会创建真正的降序索引
- MySQL 8.0 只有innodb存储引擎支持降序索引,且同时只有btree索引支持降序
- 使用MySQL 8.0 降序索引时,还支持反向查找降序索引
- MySQL 5.7 执行group by操作时会进行隐式排序,8.0则是随机返回
[5.7.37-log]>alter table tb add index idx_a_b(a asc,b desc);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
[5.7.37-log]>show create table tb\G
*************************** 1. row ***************************
Table: tb
Create Table: CREATE TABLE `tb` (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
KEY `idx_a_b` (`a`,`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
[8.0.27]>alter table tb add index idx_a_b(a asc,b desc);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>show create table tb\G
*************************** 1. row ***************************
Table: tb
Create Table: CREATE TABLE `tb` (
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
KEY `idx_a_b` (`a`,`b` DESC)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00
真假降序索引验证
[5.7.37-log]>insert into tb(a,b) values(1,100),(1,200),(2,300),(2,50);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
[5.7.37-log]>explain select * from tb order by a asc,b desc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: index
possible_keys: NULL
key: idx_a_b
key_len: 10
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index; Using filesort
1 row in set, 1 warning (0.00 sec)
[8.0.27]>insert into tb(a,b) values(1,100),(1,200),(2,300),(2,50);
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0
[8.0.27]>explain select * from tb order by a asc,b desc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: index
possible_keys: NULL
key: idx_a_b
key_len: 10
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.01
group by是否隐式排序
[5.7.37-log]>select b,count(1) from tb group by b;
+------+----------+
| b | count(1) |
+------+----------+
| 50 | 1 |
| 100 | 1 |
| 200 | 1 |
| 300 | 1 |
+------+----------+
4 rows in set (0.00 sec)
[5.7.37-log]>explain select b,count(1) from tb group by b\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: index
possible_keys: idx_a_b
key: idx_a_b
key_len: 10
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index; Using temporary; Using filesort
1 row in set, 1 warning (0.00 sec)
[8.0.27]>select b,count(1) from tb group by b;
+------+----------+
| b | count(1) |
+------+----------+
| 200 | 1 |
| 100 | 1 |
| 300 | 1 |
| 50 | 1 |
+------+----------+
4 rows in set (0.00 sec)
[8.0.27]>explain select b,count(1) from tb group by b\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: index
possible_keys: idx_a_b
key: idx_a_b
key_len: 10
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index; Using temporary
1 row in set, 1 warning (0.01
降序索引反向查找
[8.0.27]>explain select * from tb order by a desc,b asc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: tb
partitions: NULL
type: index
possible_keys: NULL
key: idx_a_b
key_len: 10
ref: NULL
rows: 4
filtered: 100.00
Extra: Backward index scan; Using index
1 row in set, 1 warning (0.00 sec)
3、函数索引
- 从MySQL 8.0.13版本开始支持函数,函数索引同时支持降序及json
- 函数索引本质是基于虚拟列功能实现的,所以也可以手动创建虚拟列,并在上面建立索引实现相同功能
[8.0.27]>create table t1(a varchar(100) null,b varchar(100) null);
Query OK, 0 rows affected (0.05 sec)
[8.0.27]>alter table t1 add index idx_a(a),add index func_idx_b( (upper(b)) );
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>show index from t1\G
*************************** 1. row ***************************
Table: t1
Non_unique: 1
Key_name: idx_a
Seq_in_index: 1
Column_name: a
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: t1
Non_unique: 1
Key_name: func_idx_b
Seq_in_index: 1
Column_name: NULL
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: upper(`b`)
2 rows in set (0.02 se
测试函数索引
[8.0.27]>explain select * from t1 where upper(a) = 'ABC'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.01 sec)
[8.0.27]>explain select * from t1 where upper(b) = 'ABC'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ref
possible_keys: func_idx_b
key: func_idx_b
key_len: 403
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec
通过计算列实现函数索引
[8.0.27]>alter table t1 add column c varchar(100) generated always as (upper(a));
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>alter table t1 add index idx_c(c);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>explain select * from t1 where upper(a) = 'ABC'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ref
possible_keys: idx_c
key: idx_c
key_len: 403
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 se
支持json
[8.0.27]>create table userinfo(data json, index( (cast(data ->> '$.name' as char(100))) ));
Query OK, 0 rows affected (0.06 sec)
[8.0.27]>show index from userinfo\G
*************************** 1. row ***************************
Table: userinfo
Non_unique: 1
Key_name: functional_index
Seq_in_index: 1
Column_name: NULL
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: cast(json_unquote(json_extract(`data`,_utf8mb4\'$.name\')) as char(100) charset utf8mb4)
1 row in set (0.02 sec)
[8.0.27]>explain select * from userinfo where cast(data ->> '$.name' as char(100)) = 'lili'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: userinfo
partitions: NULL
type: ref
possible_keys: functional_index
key: functional_index
key_len: 403
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 se
三、SQL增强
1、CTE公用表表达式
- 支持递归,可通过cte_max_recursion_depth限制递归次数,默认1000;也可通过max_execution_time限制执行时长(单位毫秒),执行时长默认不限制
- 其本身类似于临时表、视图
- 官方文档显示支持对CTE直接进行select、update、delete操作,但实测只支持select,其他的会报语法错误
非递归
[8.0.27]>with
-> ct1(a) as (select 1 num),
-> ct2(b) as (select a+10 from ct1)
-> select * from ct1,ct2;
+---+----+
| a | b |
+---+----+
| 1 | 11 |
+---+----+
1 row in set (0.01 sec)
递归
[8.0.27]>with recursive
-> ct1(n) as (
-> select 1
-> union all
-> select n+1 from ct1 where n<5
-> )
-> select * from ct1;
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+------+
5 rows in set (0.00 sec)
2、窗口函数
2.1、语法
WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...
window_function_name(window_name/expression)
OVER (
[partition_definition]
[order_definition]
[frame_definition]
FRAME字句:
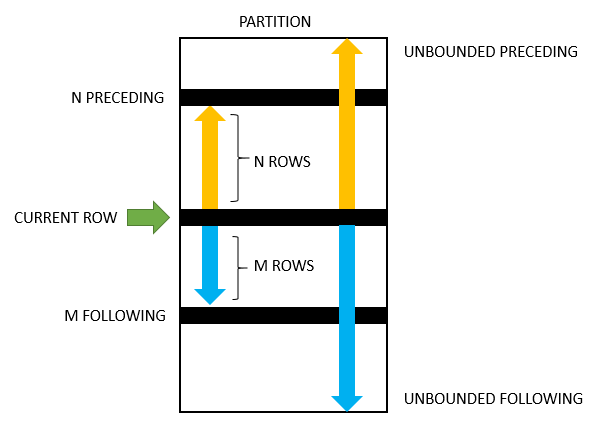
- 框架单元(frame_units):
- ROWS:BETWEEN的范围是行号
- RANGE:BETWEEN的范围是行的值
- 框架内容(frame_extent):
CURRENT ROW:边界是当前行,一般和其他范围关键字一起使用
UNBOUNDED PRECEDING:边界是分区中的第一行
UNBOUNDED FOLLOWING:边界是分区中的最后一行
N PRECEDING:ROWS时表示当前行的前N行,RANGE时表示当前行的值减去N
M FOLLOWING:ROWS时表示当前行的后M行,RANGE时表示当前行的值加上M
用法:
ORDER BY 字段名 ROWS | RANGE BETWEEN 边界规则1 AND 边界规则2
在over子句中未指定frame字句时,默认值是:
有order by子句:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
无order by子句:RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
动态求和:
[8.0.27]>select *,sum(score) over(
-> partition by class_id order by score rows between 1 preceding and 1 following
-> ) as running_range_s
-> from scorelist
-> order by class_id,score;
+----------+-------+-----------------+
| class_id | score | running_range_s |
+----------+-------+-----------------+
| 1 | 80 | 166 |
| 1 | 86 | 256 |
| 1 | 90 | 266 |
| 1 | 90 | 280 |
| 1 | 100 | 290 |
| 1 | 100 | 300 |
| 1 | 100 | 200 |
| 2 | 70 | 165 |
| 2 | 95 | 260 |
| 2 | 95 | 190 |
+----------+-------+-----------------+
10 rows in set (0.00 sec)
[8.0.27]>select *,sum(score) over(
-> partition by class_id order by score range between 5 preceding and 5 following
-> ) as running_range_s
-> from scorelist
-> order by class_id,score;
+----------+-------+-----------------+
| class_id | score | running_range_s |
+----------+-------+-----------------+
| 1 | 80 | 80 |
| 1 | 86 | 266 |
| 1 | 90 | 266 |
| 1 | 90 | 266 |
| 1 | 100 | 300 |
| 1 | 100 | 300 |
| 1 | 100 | 300 |
| 2 | 70 | 70 |
| 2 | 95 | 190 |
| 2 | 95 | 190 |
+----------+-------+-----------------+
10 rows in set (0.00 sec
2.2、普通窗口函数
适用于所有聚合函数
[8.0.27]>select *,sum(profit) over(partition by country) s
-> from sales order by country,year;
+------+---------+------------+--------+------+
| year | country | product | profit | s |
+------+---------+------------+--------+------+
| 2000 | Finland | Computer | 1500 | 1610 |
| 2000 | Finland | Phone | 100 | 1610 |
| 2001 | Finland | Phone | 10 | 1610 |
| 2000 | India | Calculator | 150 | 1350 |
| 2000 | India | Computer | 1200 | 1350 |
| 2000 | USA | Calculator | 75 | 4575 |
| 2000 | USA | Computer | 1500 | 4575 |
| 2001 | USA | Calculator | 50 | 4575 |
| 2001 | USA | Computer | 2700 | 4575 |
| 2001 | USA | TV | 250 | 4575 |
+------+---------+------------+--------+------+
10 rows in set (0.01 sec)
2.3、专用窗口函数
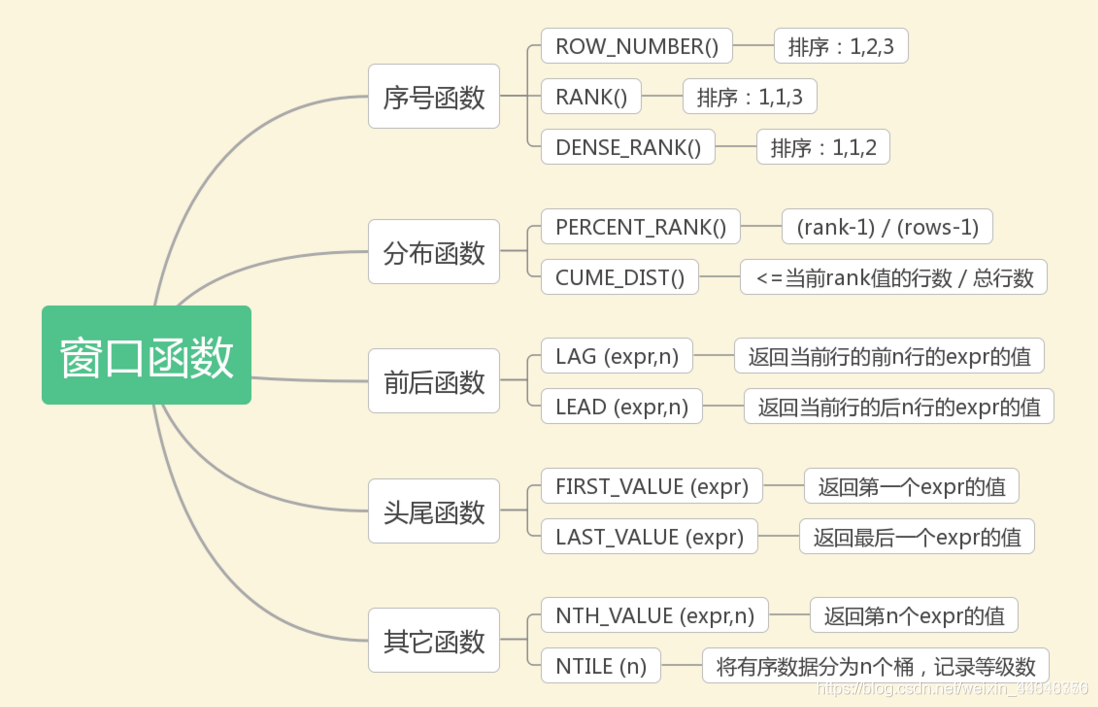
- 序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- ROW_NUMBER():顺序排序,如1、2、3
- RANK():并列排序,跳过重复序号,如1、1、3
- DENSE_RANK():并列排序,不跳过重复号,如1、1、2
- 分布函数:PERCENT_RANK()、CUME_DIST()
- PERCENT_RANK():每行按照公式(rank-1) / (rows-1)进行计算
- CUME_DIST():分组内小于、等于当前rank值的行数 / 分组内总行数
- 前后函数:LAG()、LEAD()
- LAG():以当前行为准,前第N行的值
- LEAD():以当前行为准,后第N行的值
- 头尾函数:FIRST_VALUE()、LAST_VALUE()
- FIRST_VALUE():返回排行第一的值
- LAST_VALUE():返回排名最后的值
- 其它函数:NTH_VALUE()、NTILE()
- NTH_VALUE():返回当前排序规则第N行的值
- NTILE():按排名分成N个分区,并记录当前行属于第几分区
[8.0.27]>select *,
-> row_number() over(partition by class_id order by score desc) row_num,
-> first_value(score) over(partition by class_id order by score desc) fv,
-> lag(score,1) over(partition by class_id order by score desc) lg,
-> lead(score,2) over(partition by class_id order by score desc) ld,
-> ntile(4) over(partition by class_id order by score desc) nt
-> from scorelist order by class_id,score desc;
+----------+-------+---------+------+------+------+----+
| class_id | score | row_num | fv | lg | ld | nt |
+----------+-------+---------+------+------+------+----+
| 1 | 100 | 1 | 100 | NULL | 100 | 1 |
| 1 | 100 | 2 | 100 | 100 | 90 | 1 |
| 1 | 100 | 3 | 100 | 100 | 90 | 2 |
| 1 | 90 | 4 | 100 | 100 | 80 | 2 |
| 1 | 90 | 5 | 100 | 90 | NULL | 3 |
| 1 | 80 | 6 | 100 | 90 | NULL | 4 |
| 2 | 95 | 1 | 95 | NULL | 70 | 1 |
| 2 | 95 | 2 | 95 | 95 | NULL | 2 |
| 2 | 70 | 3 | 95 | 95 | NULL | 3 |
+----------+-------+---------+------+------+------+----+
9 rows in set (0.01 sec)
简便写法
[8.0.27]>select *,
-> row_number() over w row_num,
-> first_value(score) over w fv,
-> lag(score,1) over w lg,
-> lead(score,2) over w ld,
-> ntile(4) over w nt
-> from scorelist
-> where class_id < 10
-> window w as (partition by class_id order by score desc)
-> order by class_id,score desc;
+----------+-------+---------+------+------+------+----+
| class_id | score | row_num | fv | lg | ld | nt |
+----------+-------+---------+------+------+------+----+
| 1 | 100 | 1 | 100 | NULL | 100 | 1 |
| 1 | 100 | 2 | 100 | 100 | 90 | 1 |
| 1 | 100 | 3 | 100 | 100 | 90 | 2 |
| 1 | 90 | 4 | 100 | 100 | 80 | 2 |
| 1 | 90 | 5 | 100 | 90 | NULL | 3 |
| 1 | 80 | 6 | 100 | 90 | NULL | 4 |
| 2 | 95 | 1 | 95 | NULL | 70 | 1 |
| 2 | 95 | 2 | 95 | 95 | NULL | 2 |
| 2 | 70 | 3 | 95 | 95 | NULL | 3 |
+----------+-------+---------+------+------+------+----+
9 rows in set (0.00 sec)
3、JSON增强
其实从MySQL 5.7的高版本开始,就对JSON数据类型进行了各种加强,8.0 则属于进一步加强,因相关函数实在太多,这里就不做展开讨论,具体见后面的附图。
如果要存储的字符串内容,符合JSON格式标准的(类似于python中的列表和字典),老版本通常会存储到text中,而如果存储到JSON中,则通过相关函数操作(甚至可以通过增加虚拟列建立索引),在读取方面会有天然的速度优势,这是官方在极力推荐的一个功能。
下面简单列举例一个8.0的增强点,其他可自行查询官方文档:
--支持切片操作 [8.0.27]>create table test_json_list(id int,data json); Query OK, 0 rows affected (0.06 sec) [8.0.27]>insert into test_json_list values(1,'["a","b","c","d"]'); Query OK, 1 row affected (0.01 sec) [8.0.27]>select *,data->>'$[last-2 to last]' from test_json_list; +------+----------------------+----------------------------+ | id | data | data->>'$[last-2 to last]' | +------+----------------------+----------------------------+ | 1 | ["a", "b", "c", "d"] | ["b", "c", "d"] | +------+----------------------+----------------------------+ 1 row in set (0.00 sec) --老版本不支持切片 [5.7.37-log]>select *,data->>'$[1 to 3]' from test_json_list; ERROR 3143 (42000): Invalid JSON path expression. The error is around character position
JSON相关操作函数

四、Innodb增强
1、数据字典
- MySQL 8.0 将数据库元信息都存放于InnoDB存储引擎表中
- MySQL 8.0将所有原先存放于数据字典文件中的信息,全部存放到数据库系统表中,即将之前版本的frm、opt、trn、trg等文件都移除了,不再通过文件的方式存储数据字典信息。
- 对INFORMATION_SCHEM,mysql,sys系统库中的存储引擎做了改进,原先使用MyISAM存储引擎的数据字典表都改为使用InnoDB存储引擎存放。
- 既然所有系统表都使用InnoDB存储引擎,且InnoDB支持事务,那么就延伸出一个新特性:原子DDL操作。
- INFORMATION_SCHEMA性能提升:在之前版本中,数据字典信息不一定是存放于表中,所以在获取数据字典信息时候,不仅仅是查表操作。例如读取数据库表结构信息,底层其实是读取.frm文件来获得,是一个文件打开读取的操作。而在新版本中,数据字典信息都可以通过直接查表的方式获取。
2、原子DDL操作
MySQL 8.0 开始支持原子 DDL 操作,其中与表相关的原子 DDL 只支持 InnoDB 存储引擎。一个原子 DDL 操作内容包括:更新数据字典,存储引擎层的操作,在 binlog 中记录 DDL 操作。支持与表相关的 DDL:数据库、表空间、表、索引的 CREATE、ALTER、DROP 以及 TRUNCATE TABLE。支持的其他 DDL :存储程序、触发器、视图、UDF 的 CREATE、DROP 以及ALTER 语句。支持账户管理相关的 DDL。
8.0执行DDL语句时,DDL⽇志会写入 mysql.innodb_ddl_log表中(innodb_ddl_log字典表隐藏在mysql.ibd 数据字典表空间⾥)。通过设置以下两个参数可以在error.log中看到相关记录。
set global log_error_verbosity=3;
set global innodb_print_ddl_logs=1;
[5.7.37-log]>create table td1(id int); Query OK, 0 rows affected (0.01 sec) [5.7.37-log]>show tables like 'td%'; +----------------------+ | Tables_in_test (td%) | +----------------------+ | td1 | +----------------------+ 1 row in set (0.00 sec) [5.7.37-log]>drop table td1,td2; ERROR 1051 (42S02): Unknown table 'test.td2' [5.7.37-log]>show tables like 'td%'; Empty set (0.00 s
[8.0.27]>create table td1(id int); Query OK, 0 rows affected (0.04 sec) [8.0.27]>show tables like 'td%'; +----------------------+ | Tables_in_test (td%) | +----------------------+ | td1 | +----------------------+ 1 row in set (0.01 sec) [8.0.27]>drop table td1,td2; ERROR 1051 (42S02): Unknown table 'test.td2' [8.0.27]>show tables like 'td%'; +----------------------+ | Tables_in_test (td%) | +----------------------+ | td1 | +----------------------+ 1 row in set (0.00 sec) [8.0.27]>drop table if exists td1,td2; Query OK, 0 rows affected, 1 warning (0.02 sec) [8.0.27]>show tables like 'td%'; Empty set (0.01
3、自增列持久化
AUTO_INCREMENT自增列,当最大值的行被删除后,数据库进行了重启:
- MySQL 5.7之前:自增列计数器值只存储在内存中,重启后,计数器值重新设置为:select max(key)+1 from tb; 即自增列key值会出现回溯现象
- MySQL 8.0:自增列值每次变化时,都将自增计数器的最大值写入 redo log,同时在每次检查点将其写入引擎的私有系统表,解决回溯BUG
[5.7.37-log]>create table t4(
-> id int not null auto_increment primary key,
-> number int);
Query OK, 0 rows affected (0.01 sec)
[5.7.37-log]>insert into t4(number) values(10),(20),(30);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
[5.7.37-log]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
+----+--------+
3 rows in set (0.00 sec)
[5.7.37-log]>delete from t4 where id>=2;
Query OK, 2 rows affected (0.01 sec)
[5.7.37-log]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
+----+--------+
1 row in set (0.01 sec)
--重启数据库后
[5.7.37-log]>show create table t4\G
*************************** 1. row ***************************
Table: t4
Create Table: CREATE TABLE `t4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`number` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
[5.7.37-log]>insert into t4(number) values(100);
Query OK, 1 row affected (0.00 sec)
[5.7.37-log]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
| 2 | 100 |
+----+--------+
2 rows in set (0.01 sec)
[5.7.37-log]>update t4 set id=20 where number=100;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
[5.7.37-log]>show create table t4\G
*************************** 1. row ***************************
Table: t4
Create Table: CREATE TABLE `t4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`number` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
[5.7.37-log]>insert into t4(number) values(200);
Query OK, 1 row affected (0.00 sec)
[5.7.37-log]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
| 3 | 200 |
| 20 | 100 |
+----+--------+
3 rows in set
--删除数据,且重启后
[8.0.27]>show create table t4\G
*************************** 1. row ***************************
Table: t4
Create Table: CREATE TABLE `t4` (
`id` int NOT NULL AUTO_INCREMENT,
`number` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
[8.0.27]>insert into t4(number) values(100);
Query OK, 1 row affected (0.01 sec)
[8.0.27]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
| 4 | 100 |
+----+--------+
2 rows in set (0.01 sec)
[8.0.27]>update t4 set id=20 where number=100;
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
[8.0.27]>show create table t4\G
*************************** 1. row ***************************
Table: t4
Create Table: CREATE TABLE `t4` (
`id` int NOT NULL AUTO_INCREMENT,
`number` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
[8.0.27]>insert into t4(number) values(200);
Query OK, 1 row affected (0.01 sec)
[8.0.27]>select * from t4;
+----+--------+
| id | number |
+----+--------+
| 1 | 10 |
| 20 | 100 |
| 21 | 200 |
+----+--------+
3 rows in set (0.0
4、锁定语句选项
新增选项语句:nowait、skip locked
- nowait:获取不到锁就直接报错,执行失败
- skip locked:跳过被锁定的行
--session 1 [8.0.27]>select * from t4; +----+--------+ | id | number | +----+--------+ | 1 | 10 | | 20 | 100 | | 21 | 200 | +----+--------+ 3 rows in set (0.00 sec) [8.0.27]>start transaction; Query OK, 0 rows affected (0.00 sec) [8.0.27]>update t4 set number = 101 where id = 20; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 --session 2 [8.0.27]>select * from t4 for update nowait; ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set. [8.0.27]>select * from t4 for share skip locked; +----+--------+ | id | number | +----+--------+ | 1 | 10 | | 21 | 200 | +----+--------+ 2 rows in set (0.00 sec) [8.0.27]>select * from t4 for update skip locked; +----+--------+ | id | number | +----+--------+ | 1 | 10 | | 21 | 200 | +----+--------+ 2 rows in set (0.00
五、实例克隆
实例克隆功能会在目标服务器克隆一份与源服务器一样的物理文件。
- 克隆时,如果指定了data directory参数,会将数据文件克隆到该目录下,但是不会自动启动,如果想按指定的data directory启动数据库,需要自己修改my.cnf中对应的参数后进行启动
- 克隆时,如果未指定data directory参数,则会删除当前实例datadir下的文件,全部克隆完毕后,自动重启数据库实例(慎重,如果登陆错服务器,执行了该命令,就真的是删库跑路了)。
实例克隆可以本地克隆,也可以远程克隆,两者原理一样。另外,克隆功能对主从实例有着极其苛刻的要求:
- 操作系统版本必须一致
- mysql主版本号、发行级别、发行系列版本号都必须一致,mysql8.0.19->mysql8.0.20 这种不支持
- 目前仅支持InnoDB引擎,其他引擎不支持,如果有非InnoDB引擎信息会在日志里面显示
- 支持压缩表clone操作,但文件系统的block size需要保持一致
- 在8.0.27之前不支持DDL操作(因为有backup lock),在8.0.27版本及以后,允许DDL操作,但不允许table space的操作(比如import、export)
优势:
- 相比较于Xtrabackup而言,备份速度很快,效率几乎可以翻倍。
- 可以远程备份。虽然Xtrabackup也可以实现流式物理备份到远程服务器,但需要解决SSH的问题,这在生产环境中,大部分情况下可能是不允许的;相比较而已,克隆功能在这方面则完全不需要考虑。
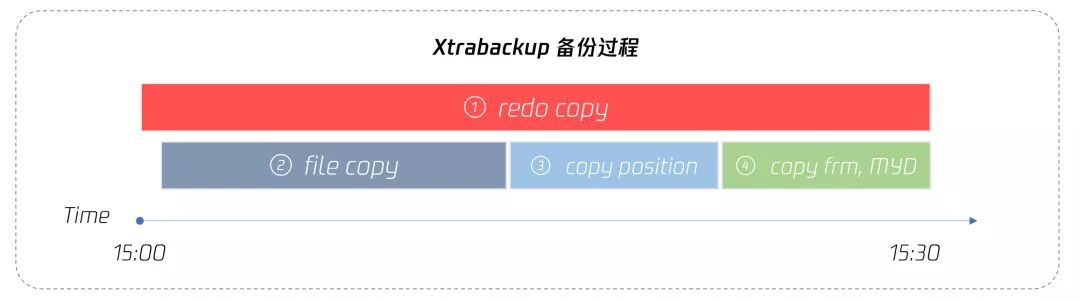
Xtrabackup物理备份过程:
- 拷贝重做日志文件(持续整个备份周期)
- 拷贝InnoDB 文件
- 保存binlog位点(加全局锁)
- 拷贝其他非InnoDB 文件
Clone物理备份过程:
- 拷贝InnoDB 文件(不支持非Innodb引擎)
- 对buffer pool中的脏页按(space,page_no)顺序进行备份,同时启用 page tracking 的机制,记录当前已经 check point 完成的 LSN,减少需要拷贝的重做日志。
- 拷贝check point之后的重做日志即可
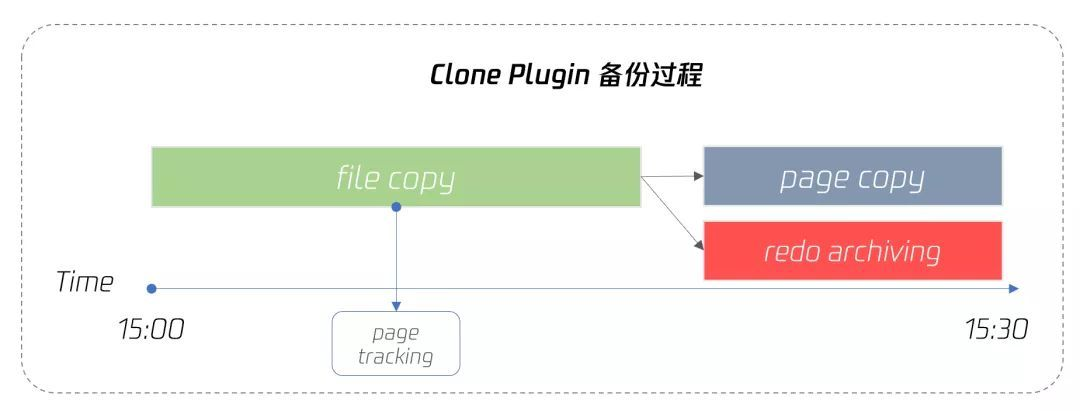
从上述备份过程的对比中,不难看出,还原完物理文件后,恢复的数据库位点就不一样,那同样的,后续需要恢复binlog的量肯定也不一样。可以猜想,如果源实例足够大,备份和还原的时间足够长,后续日志重放以及追数所需时间等,总结起来就是,clone都能完胜xtrabackup。
操作过程:
--master,创建clone插件,以及源端克隆用户,用户需要backup_admin权限 [8.0.27]>install plugin clone soname 'mysql_clone.so'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>create user clone_src@'%' identified by 'abc123'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>grant backup_admin on *.* to clone_src@'%'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>create user replicater@'%' identified by 'abc123'; Query OK, 0 rows affected (0.01 sec) [8.0.27]>grant replication slave,replication client on *.* to replicater@'%'; Query OK, 0 rows affected (0.00 sec) [8.0.27]>flush privileges; Query OK, 0 rows affected (0.00
--slave,创建clone插件,目标端数据库用户需要有clone_admin权限,比如root
[8.0.27]>install plugin clone soname 'mysql_clone.so';
Query OK, 0 rows affected (0.02 sec)
--设置源服务器信息,开始克隆
[8.0.27]>set global clone_valid_donor_list = '172.31.255.141:3380';
Query OK, 0 rows affected (0.00 sec)
--IP是指源服务器的IP,而非mysql用户clone_src的IP
[8.0.27]>clone instance from 'clone_src'@'172.31.255.141':3380 identified by 'abc123';
Query OK, 0 rows affected (1 min 47.63 sec)
--搭建复制
[8.0.27]>change master to
-> master_host='172.31.255.141',
-> master_port=3380,
-> master_user='replicater',
-> master_password='abc123',
-> master_auto_position=1;
Query OK, 0 rows affected, 8 warnings (0.04 sec)
[8.0.27]>start slave;
Query OK, 0 rows affected, 1 warning (0.03
六、MySQL复制改进
1、二进制日志压缩
日志压缩通过以下两个参数控制,只支持ROW模式:
binlog_transaction_compression:OFF/ON,默认值OFF,很容易理解,就是是否开启日志压缩
binlog_transaction_compression_level_zstd:1-22,默认值3,调高压缩级别未看到有明显区别,详情未知。
压缩效果:测试效果很明显,压缩率40%出头,同样的操作,压缩前205M,压缩后85M。
在主从复制中,开启压缩,能缓解因网络带宽所带来的主从延迟现象;另外,从库接受到日志后,依然是以压缩状态存放到中继日志里,SQL线程会在回放日志是进行解码和解压操作。
2、日志中保存元数据表信息
通过设置参数binlog_row_metadata=FULL,将表的主键和列信息记录到binlog中,参数为关闭状态(参数值为:MINIMAL);显而易见的是,开启这个特性,保存元数据信息会增加一定额外的开销。
七、其他改进功能
1、全局变量持久化
- MySQL 5.7及以前的版本,修改参数只有session和global两种,重启MySQL后都会以配置文件重新初始化。
- MySQL 8.0可通过persist及persist_only来进行参数持久化,参数信息保存到datadir的mysqld-auto.cnf文件中,他们的设置范围都是global级别。
- persist:修改当前内存值,同时持久化,如 set persist long_query_time=3;
- persist_only:不修改当前内存值,只对参数进行持久化,如 set persist_only long_query_time=3;
- 参数持久化需要用有 system_variables_admin 和 persist_ro_variables_admin 权限。
- 持久化文件mysqld-auto.cnf是以json格式保存参数信息,也可以通过查询performance_schema.persisted_variables来获取持久化信息。
- 数据库启动时,会先读取my.cnf配置文件,再读取mysqld-auto.cnf文件,这意味着,同一个参数,持久化文件的值会将my.cnf的覆盖掉。
- 执行reset persist命令,或者删除mysqld-auto.cnf文件(需要重启)都可以清空持久化信息。
mysqld-auto.cnf 文件:
{
"Version": 1,
"mysql_server": {
"long_query_time": {
"Value": "3.000000",
"Metadata": {
"Timestamp": 1650809692554275,
"User": "root",
"Host": "localhost"
}
}
}
}
[8.0.27]>select * from performance_schema.persisted_variables; +-----------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-----------------+----------------+ | long_query_time | 3.000000 | +-----------------+----------------+ 1 row in set (0.00 sec)
2、秒级加列
从MySQL 8.0.12版本开始引入快速加列功能,采用的算法为instant:
- 在 ALTER 语句后增加 ALGORITHM=INSTANT 即代表使用 INSTANT 算法, 如果未明确指定,则支持 INSTANT 算法的操作会默认使用。如果指定 ALGORITHM=INSTANT 但不支持,则操作立即失败并显示错误。
- 使用INSTANT算法后,添加列时不再rebuild整个表,只在表的 metadata 中记录新增列的基本信息即可。
从后面的表格中可以看到,INSTANT算法的应用场景有限,用的最多的应该算是添加列了,同时,他还有以下其他的限制条件:
- 添加列的ALTER语句,如果还包含其他不支持INSTANT算法的操作,那么ALTER语句会报错,且整个语句所有操作都不会执行。
- 只能顺序加列, 仅支持在最后添加列,而不支持在现有列的中间添加列。
- 不支持压缩表,即该表行格式不能是 COMPRESSED。
- 不支持包含全文索引的表。
- 不支持临时表。
- 不支持那些在数据字典表空间中创建的表。
以下为INSTANT和IN PLACE算法的对比,*表示不全部支持:
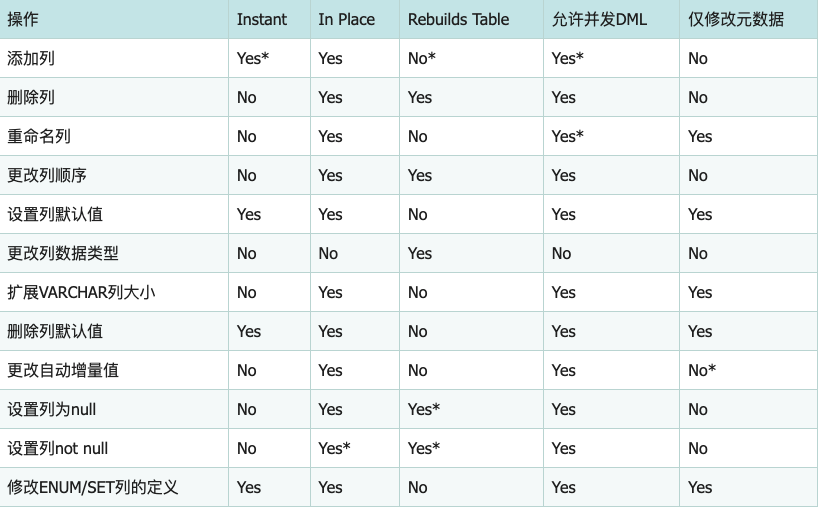
[8.0.27]>select TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS,
-> (DATA_LENGTH+DATA_FREE+INDEX_LENGTH)/1024/1024 tb_size
-> from information_schema.tables where table_name='salaries_test';
+--------------+---------------+------------+---------------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_ROWS | tb_size |
+--------------+---------------+------------+---------------+
| emp | salaries_test | 30500061 | 1136.00000000 |
+--------------+---------------+------------+---------------+
1 row in set (0.01 sec)
[8.0.27]>alter table salaries_test add column num int,algorithm=inplace;
Query OK, 0 rows affected (56.26 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>alter table salaries_test add column a varchar(100),algorithm=instant;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
[8.0.27]>alter table salaries_test add column b varchar(100),
-> add column c varchar(100) after num,algorithm=instant;
ERROR 1845 (0A000): ALGORITHM=INSTANT is not supported for this operation. Try ALGORITHM=COPY/INPLACE.
[8.0.27]>alter table salaries_test add column b varchar(100);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warning
3、默认字符集
utf8mb4
八、升级MySQL 8.0
MySQL本身支持跨版本升级到8.0,升级过程非常简单,获取一个已编译好的安装包,解压后,用8.0的server路径替换老版本的server路径,然后直接启动数据库就可以。启动过程中,MySQL 8.0会自动升级系统表,而不需要用户手动执行mysql_upgrade,启动完毕后即可访问8.0数据库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号